
🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python实战项目案例
💕💕文末获取源码
文章目录
本次文章主要是介绍基于python的房价数据可视化分析系统
系统前言
- 当今社会,随着信息技术的不断发展和普及,大数据分析和数据挖掘正成为各个领域的热门话题。在房地产领域,房价数据一直以来都是备受关注的焦点,对购房者、开发商等各方都具有重要意义。因此,本项目旨在设计和实现一个基于大数据、Python编程和网络爬虫技术的房价数据分析系统,以满足对房价数据进行深入分析和洞察的需求。
- 房价数据是房地产市场的关键信息之一,对于购房决策、市场趋势的了解以及政府政策的制定都至关重要。然而,要获取并分析这些数据通常是一项复杂的任务。网络爬虫技术能够帮助我们从互联网上采集大量的房价数据,而大数据分析技术则可以帮助我们处理和分析这些庞大的数据集,从中提取有价值的信息。Python编程语言因其强大的数据分析库和工具而成为这个项目的首选工具。
- 使用网络爬虫技术,定期从多个房地产网站收集房价数据,确保数据的及时性和全面性。对采集到的数据进行清洗、去重、处理缺失值等操作,以确保数据的质量和可用性。将处理后的数据存储在数据库中,实现高效的数据管理和查询。数据分析与可视化:利用Python的数据分析库,对房价数据进行统计分析、趋势预测和相关性分析,并通过可视化工具呈现分析结果。本系统的设计与实现不仅将帮助购房者做出明智的购房决策,还将为房地产市场的参与者提供有关市场趋势和竞争情况的重要见解。
开发技术与环境
- 开发技术:Python+爬虫+Django框架+Echarts可视化分析+Mysql
- 项目简介:本项目爬虫端和网站后台采用Python语言开发,其中爬虫利用的是Scrapy框架可以轻松实现网站数据的抓取,抓取到的兼职信息直接保存到mysql数据库中,前端采用Vue开发,实现了前后端分离的模式,前端请求Django后端接受到数据然后利用echarts画各种统计图。
需求分析-功能介绍
用户、管理员(亮点:爬虫、Echarts可视化统计)
1.用户:登录注册、系统首页、个人中心、房价数据。
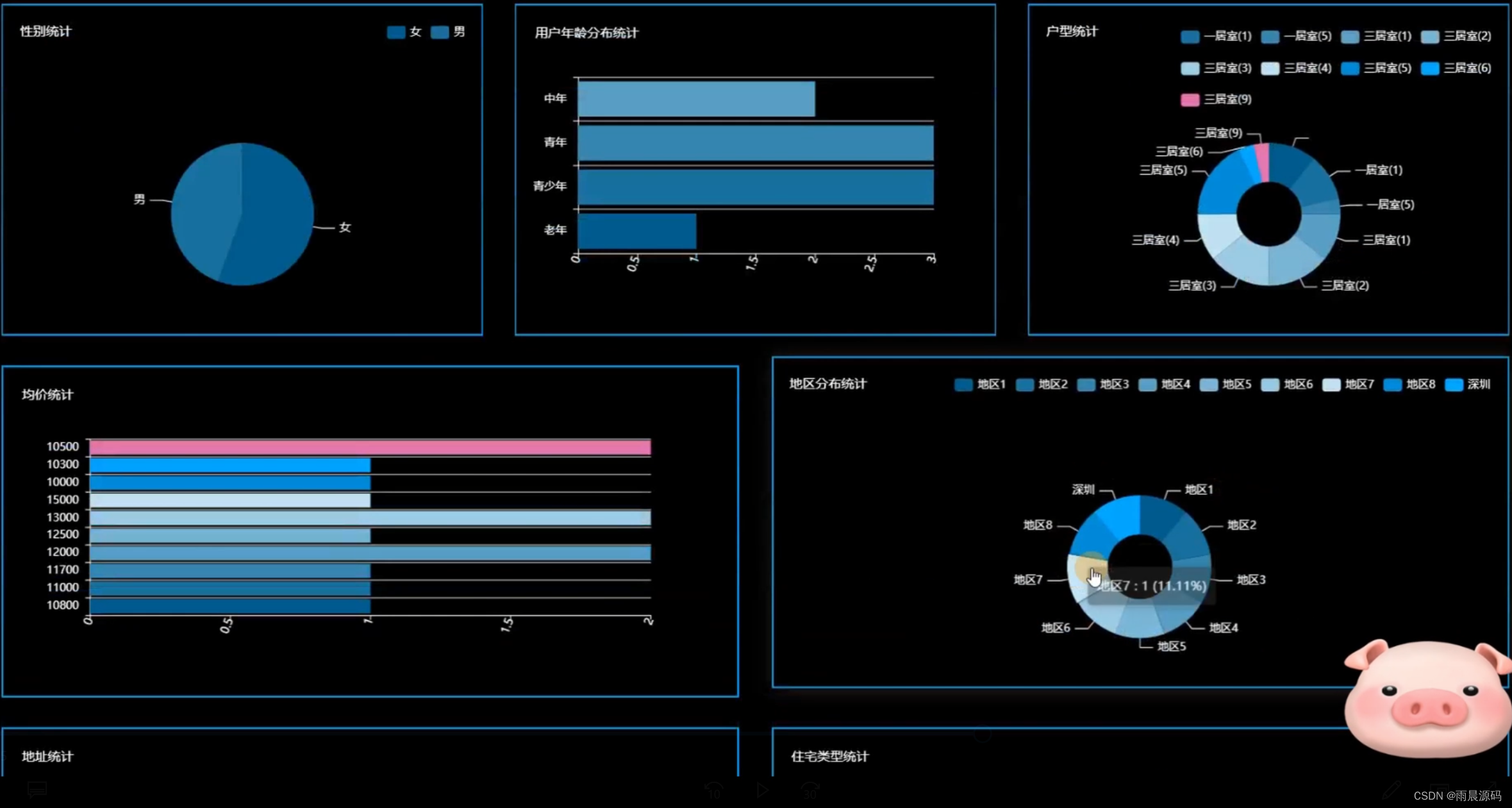
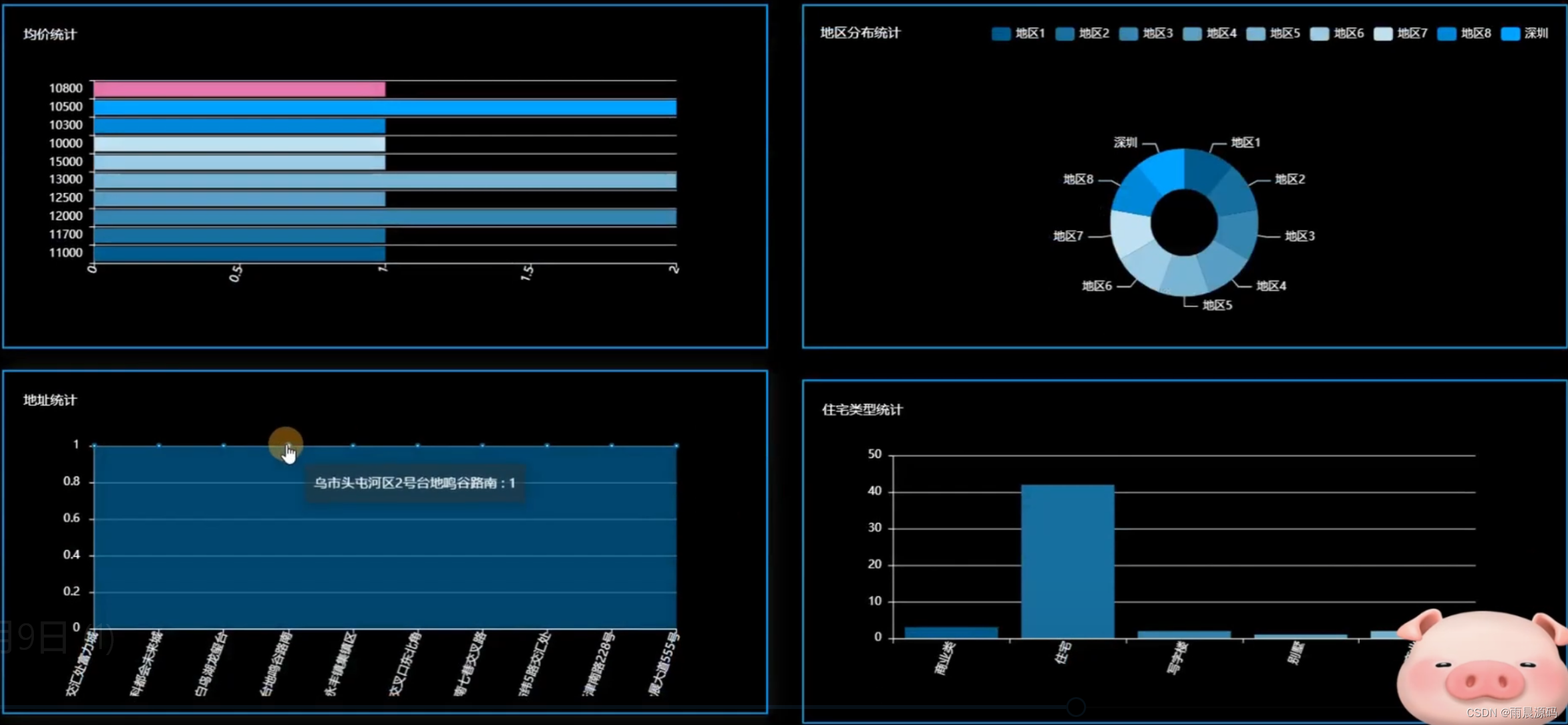
2.管理员:数据分析(房价数据Top10、性别统计、用户年龄分布统计、户型统计、均价统计、地区分布统计、地址统计、住宅类型统计)。
演示图片
1.页面:
☀️数据可视化分析(房价数据top10、户型统计、均价统计、地区分布统计等)☀️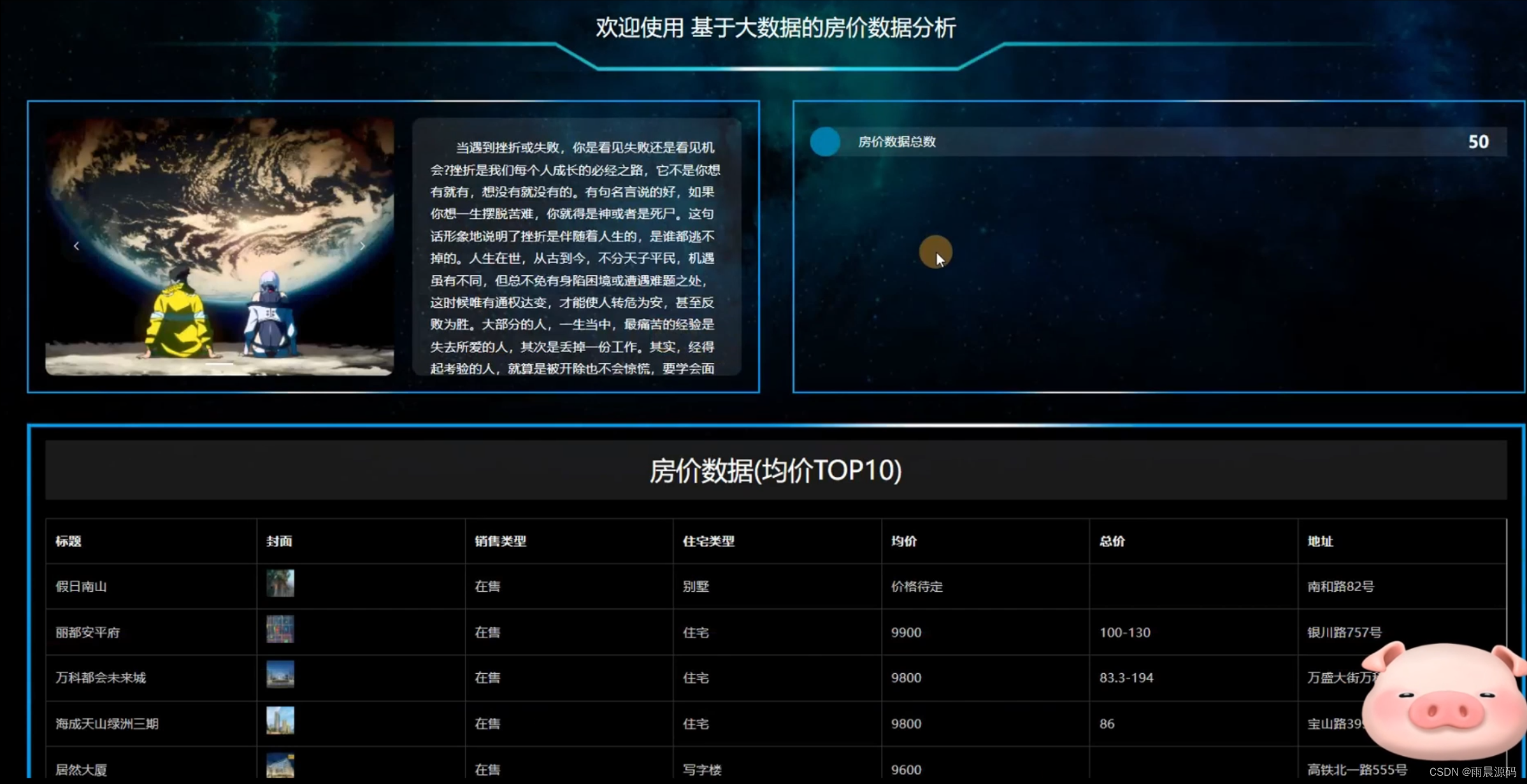
☀️用户首页☀️
☀️用户管理☀️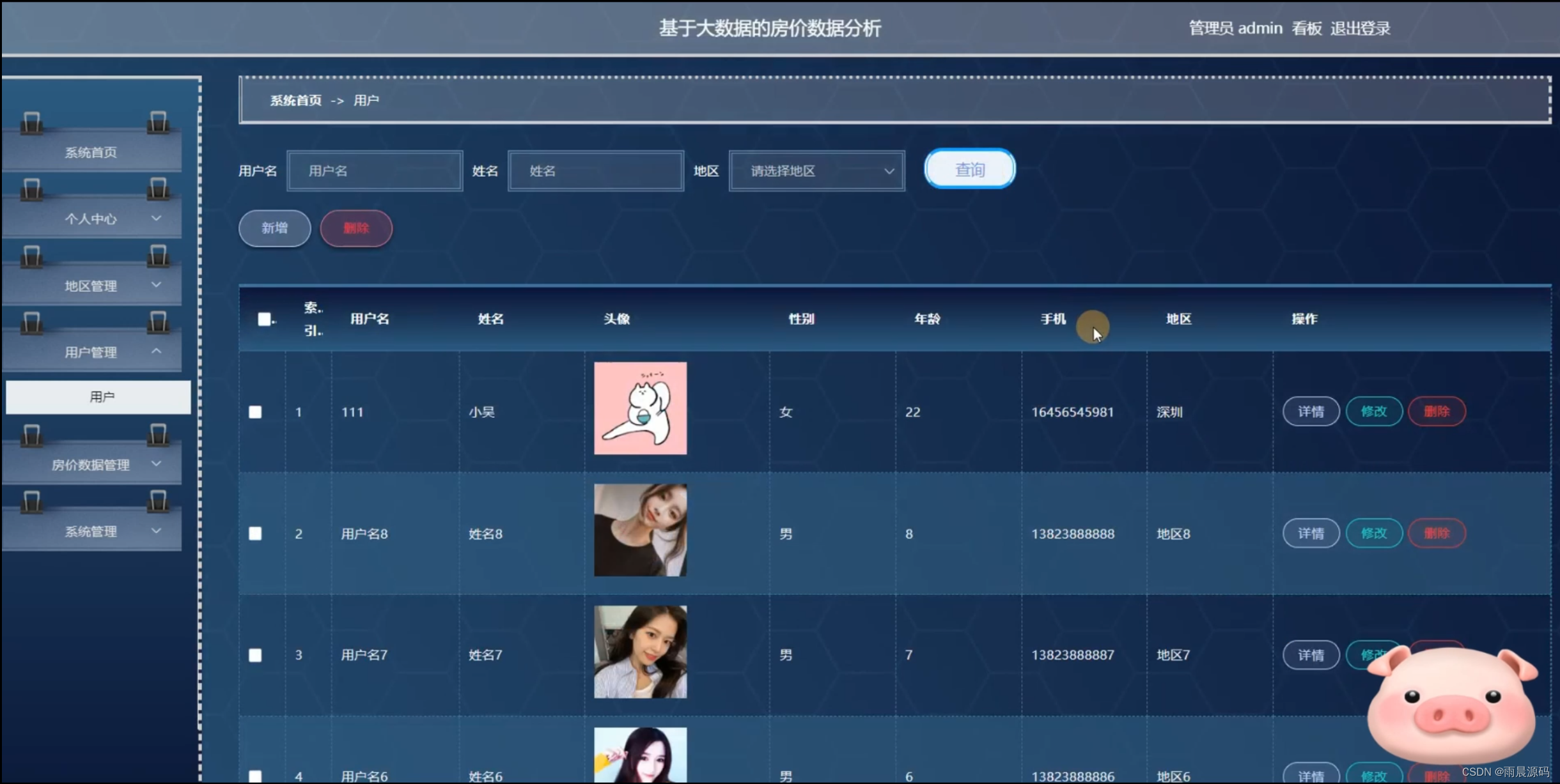
☀️房价管理:sunny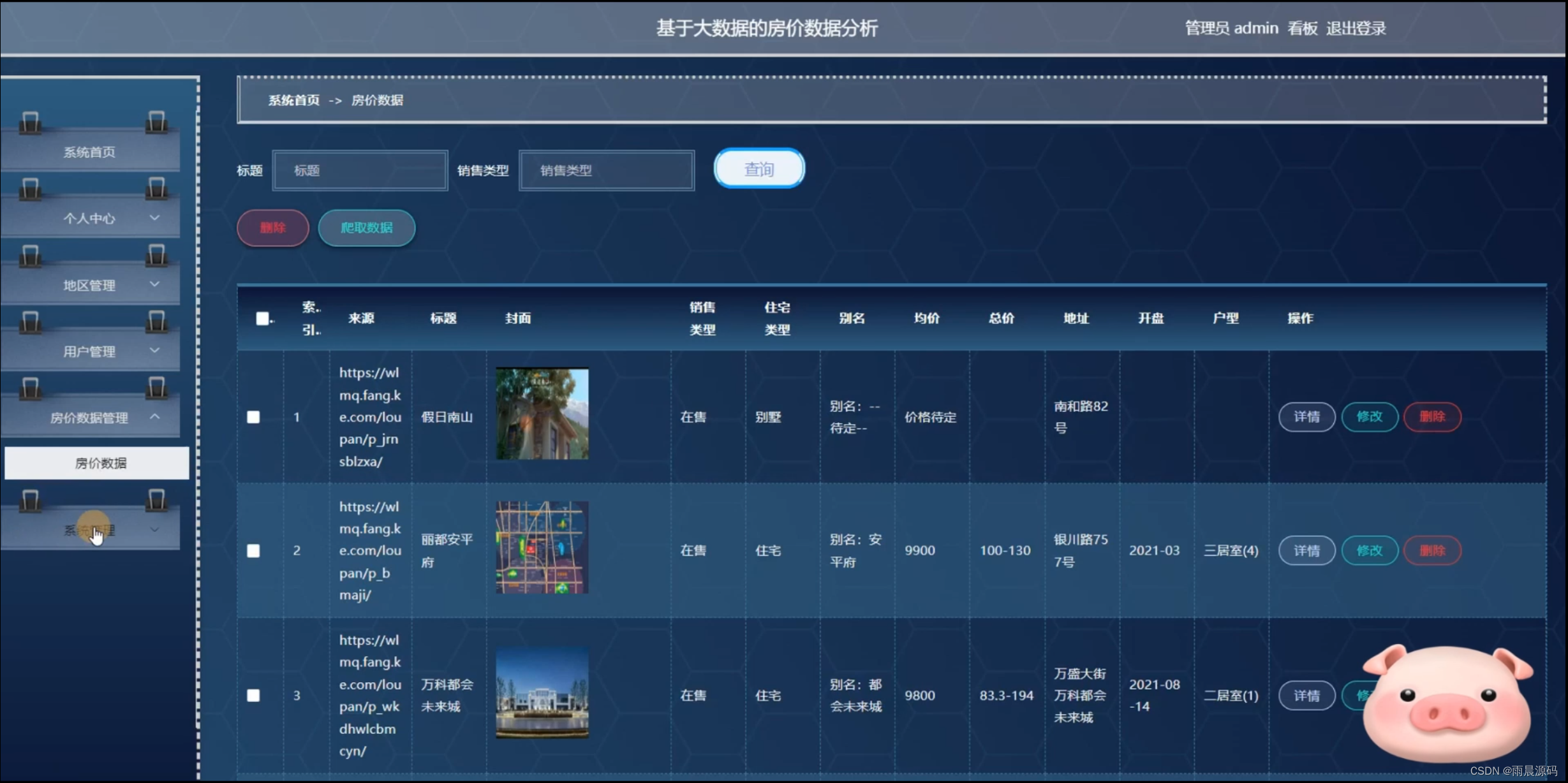
代码展示
1.爬虫解析代码如下(示例):
新房信息
class XinfangxinxiSpider(scrapy.Spider):
name ='xinfangxinxiSpider'
spiderUrl ='https://bj.fang.anjuke.com/loupan/all/p{}_w1/'
start_urls = spiderUrl.split(";")
protocol =''hostname=''
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def start_requests(self):
plat = platform.system().lower()if plat =='linux' or plat =='windows':
connect = self.db_connect()
cursor = connect.cursor()if self.table_exists(cursor, 'p9f55_xinfangxinxi')==1:
cursor.close()
connect.close()
self.temp_data()return
pageNum =1 + 1forurlin self.start_urls:
if'{}'in url:
forpagein range(1, pageNum):
next_link = url.format(page)
yield scrapy.Request(url=next_link,
callback=self.parse
)
else:
yield scrapy.Request(url=url,
callback=self.parse
)# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()if plat =='windows_bak':
pass
elif plat =='linux' or plat =='windows':
connect = self.db_connect()
cursor = connect.cursor()if self.table_exists(cursor, 'p9f55_xinfangxinxi')==1:
cursor.close()
connect.close()
self.temp_data()return
list = response.css('div[class="key-list imglazyload"] div.item-mod ')foritemin list:
fields = XinfangxinxiItem()if'(.*?)'in'''a.pic::attr(href)''':
try:
fields["laiyuan"]= re.findall(r'''a.pic::attr(href)''', item.extract(), re.DOTALL)[0].strip()
except:
pass
else:
fields["laiyuan"]= self.remove_html(item.css('a.pic::attr(href)').extract_first())if'(.*?)'in'''a.lp-name span.items-name::text''':
try:
fields["biaoti"]= re.findall(r'''a.lp-name span.items-name::text''', item.extract(), re.DOTALL)[0].strip()
except:
pass
else:
fields["biaoti"]= self.remove_html(item.css('a.lp-name span.items-name::text').extract_first())if'(.*?)'in'''a.pic img::attr(src)''':
try:
fields["fengmian"]= re.findall(r'''a.pic img::attr(src)''', item.extract(), re.DOTALL)[0].strip()
2.房价信息代码如下(示例):
def xinfangxinxi_register(request):
if request.method in["POST", "GET"]:
msg ={'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
error = xinfangxinxi.createbyreq(xinfangxinxi, xinfangxinxi, req_dict)if error != None:
msg['code']= crud_error_code
msg['msg']="用户已存在,请勿重复注册!"return JsonResponse(msg)
def xinfangxinxi_login(request):
if request.method in["POST", "GET"]:
msg ={'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
datas = xinfangxinxi.getbyparams(xinfangxinxi, xinfangxinxi, req_dict)if not datas:
msg['code']= password_error_code
msg['msg']= mes.password_error_code
return JsonResponse(msg)
try:
__sfsh__= xinfangxinxi.__sfsh__
except:
__sfsh__=None
if__sfsh__=='是':if datas[0].get('sfsh')!='是':
msg['code']=other_code
msg['msg']="账号已锁定,请联系管理员审核!"return JsonResponse(msg)
req_dict['id']= datas[0].get('id')return Auth.authenticate(Auth, xinfangxinxi, req_dict)
def xinfangxinxi_logout(request):
if request.method in["POST", "GET"]:
msg ={"msg":"登出成功",
"code":0}return JsonResponse(msg)
结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python实战项目集
💟💟如果大家有任何疑虑,欢迎在下方位置详细交流。
本文转载自: https://blog.csdn.net/qq_1445749146/article/details/132974119
版权归原作者 雨晨源码 所有, 如有侵权,请联系我们删除。
版权归原作者 雨晨源码 所有, 如有侵权,请联系我们删除。