
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于卷积神经网络的车辆实时检测与跟踪系统
课题背景和意义
随着人工智能的快速崛起,机器视觉、机器学习不断推进,物体检测的需求越来越强烈。计算机技术的发展使得物体检测、目标跟踪等人工智能技术不断迭代更新,也更贴近人们的实际生活。针对目前车辆检测不能兼顾检测速度与检测准确率的问题,我们设计了一种基于改进YOLOv5s的车辆检测方法。在保证车辆识别检测速度的同时提高了检测的准确性,增加的车辆跟踪模块可以实时监测驾驶员前方车辆的行驶情况,并做出预警,以便驾驶员及时调整,降低发生追尾的可能性。
实现技术思路
一、YOLOv5算法
1.1 YOLOv5s的损失函数
损失函数的作用为度量神经网络预测信息与期望信息(标签)的距离,预测信息越接近期望信息,损失函数值越小。
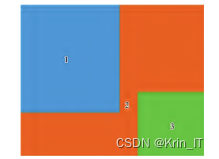
定位损失:目标检测想要框出检测到的目标,就需要通过对边界框所在的位置数据进行预测,YOLOv5s采用GIoU作为定位损失:橙色2部分(包括蓝色1和绿色3)即为最小方框C。C的面积减去预测框与真实框的面积,再比上C的面积,即可反映出真实框与预测框距离。
置信度损失:每个预测框的置信度表示这个框的可信度,置信度越大,表示预测框越靠谱,反之,则预测框越不接近真实框。用Sigmiod函数代替Sostmax来计算概率分布,损失函数采用BCEloss。
1.2 注意力机制
YOLOv5s注意力机制是模仿人在观察事物时,会将注意力集中在感兴趣的区域,把位置注意力引入到YOLOv5s网络中。位置注意力将通道注意力分解为两个一维特征编码过程,分别沿2个空间方向聚合特征。这样可以沿一个空间方向保留精确的位置信息。将生成的特征图分别编码为一对方向感知和位置敏感的注意力特征图,将其互补地应用于输入特征图,以增强关注对象的表示。
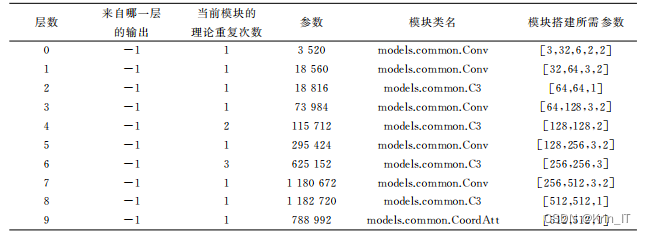
二、数据集建立和模型训练
对生活中常见的车辆拍照获取原始数据集2025张,如今生活中常见的车辆大小和样式越来越多,大致可以分为出行代步的小型车、短途载人车辆、中长途载人车辆、小型运输车辆、大型运输车辆、油罐车和一些社会中的特殊车辆,将车辆分为这7类可以在实际车辆检测跟踪过程中对不同车型在不同的距离设置不同的提示语,如果前方是社会中的特殊车辆(如警车、救护车),驾驶系统持续向驾驶员预警保持车距,注意避让,给驾驶员更加舒适更加文明的驾驶体验。车辆类别如下所示:

2.1 模型训练
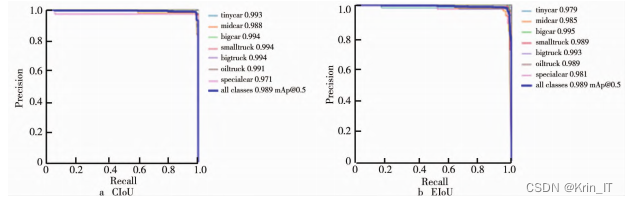
引入注意力机制的YOLOv5s训练300轮分别得到的PR曲线如下图所示,P表示精度,R表示召回率,PR曲线与坐标轴围成的面积越大,表示该模型对该数据集效果越好。当损失函数为CIoU时,训练的结果稍微优于EIoU。
部分代码如下所示:
# 创建模型
backbone = resnet_fpn_backbone('resnet50', pretrained=True)
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),), aspect_ratios=((0.5, 1.0, 2.0),))
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0', '1', '2', '3'], output_size=7, sampling_ratio=2)
attention_module = AttentionModule(256)
rpn_head = RPNHead(256, anchor_generator.num_anchors_per_location()[0])
roi_heads = RoIHeads(box_roi_pool=roi_pooler, box_head=None, box_predictor=None, mask_roi_pool=None, mask_head=None, keypoint_roi_pool=None, keypoint_head=None, keypoint_predictor=None, attention_module=attention_module)
model = FasterRCNN(backbone, rpn_head, roi_heads)
model.load_state_dict(torch.load('path/to/pretrained_weights.pth'))
model.eval()
data_loader = DataLoader(dataset, batch_size=1, shuffle=False)
predictions = []
targets = []
# 进行预测
with torch.no_grad():
for images, targets in data_loader:
images = list(image for image in images)
targets = [{k: v for k, v in t.items()} for t in targets]
output = model(images)
predictions.extend(output)
targets.extend(targets)
# 提取预测结果中的置信度和真实标签
scores = []
labels = []
for prediction in predictions:
scores.extend(prediction['scores'].cpu().numpy())
labels.extend(prediction['labels'].cpu().numpy())
# 计算PR曲线
precision, recall, _ = precision_recall_curve(targets, scores)
# 绘制PR曲线
plt.plot(recall, precision)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('PR Curve')
plt.show()
2.2 目标跟踪
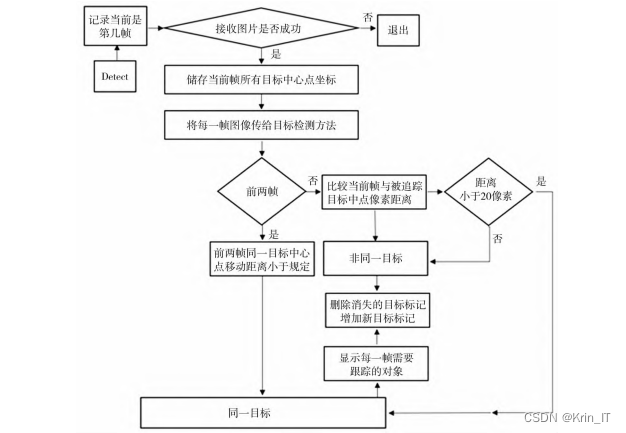
基于训练完成的YOLOv5s检测模型,开展了目标跟踪研究。在视频检测的过程中,增加帧数计数功能,将前一帧图片上的物体打上标注,得到物体的中心点坐标,然后比较当前帧图像与上一帧图像中物体的坐标。当前后两帧的同一目标的中心点移动距离小于规定值,认为是同一物体,对其进行追踪。遍历当前帧与前一帧物体的中心点坐标,计算距离。如果当前帧中出现新的目标,则给新出现的目标打上标记,然后遍历每一帧需要跟踪的目标,在跟踪目标的中心点画圈,并且显示出该目标的id。
部分代码如下所示:
# 设置模型为评估模式
model.eval()
# 加载目标类别标签
labels = ['car', 'truck', 'bus']
# 初始化目标跟踪器
tracker = cv2.TrackerCSRT_create()
# 打开摄像头
cap = cv2.VideoCapture(0)
# 循环读取视频帧
while True:
# 读取视频帧
ret, frame = cap.read()
# 将帧转换为PIL图像
pil_image = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
# 使用YOLOv5s进行目标检测
results = model(pil_image)
# 获取检测结果中的边界框、置信度和类别
boxes = results.xyxy[0][:, :4].cpu().numpy()
scores = results.xyxy[0][:, 4].cpu().numpy()
classes = results.xyxy[0][:, 5].cpu().numpy().astype(int)
# 遍历每个检测到的目标
for box, score, cls in zip(boxes, scores, classes):
# 如果检测到的目标是车辆类别
if labels[cls] in labels:
# 提取边界框的坐标
x, y, w, h = box
# 初始化目标跟踪器
tracker.init(frame, (x, y, w, h))
# 绘制边界框和类别标签
cv2.rectangle(frame, (int(x), int(y)), (int(x + w), int(y + h)), (0, 255, 0), 2)
cv2.putText(frame, labels[cls], (int(x), int(y) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 更新目标跟踪器
ret, bbox = tracker.update(frame)
# 如果目标跟踪成功
if ret:
# 提取目标跟踪器返回的边界框坐标
x, y, w, h = [int(i) for i in bbox]
# 绘制目标跟踪框
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 显示结果帧
cv2.imshow('Vehicle Tracking', frame)
# 按下 'q' 键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放摄像头和关闭窗口
cap.release()
cv2.destroyAllWindows()
三、实验效果

创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后
本文转载自: https://blog.csdn.net/2301_79555157/article/details/132739994
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。