
一、区别:
三者通常都会配合窗口函数over(),并结合partition by order by xxx来分组排序,即形式使用:function_name over(partition by xxx order by xxx)。首先三者都是产生一个自增序列,不同的是
row_number() 排序的字段值相同时序列号不会重复,如:1、2、(2)3、4、5(出现两个2,第二个2继续编号3)
rank() 排序的字段值相同时序列号会重复且下一个序列号跳过重复位,如:1、2、2、4、5(出现两个2,跳过序号3,继续编号4)
dense_rank() 排序的字段值相同时序列号会重复且下一个序列号继续序号自增,如:1、2、2、3、4(出现两个2,继续按照3编号)
二、举例介绍
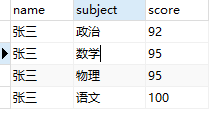
有如下学生成绩表:student_score(假设只有一个学生多门课程)
统计每个学生各科成绩由高到低排序,语句如下:
SELECT
row_number() over(partition by name order by score DESC) AS row_number,
rank() over(partition by name order by score DESC) AS rank,
dense_rank() over(partition by name order by score DESC) AS dense_rank,
name,
subject,
score
FROM
统计结果如下图所示:
从上图结果可以看出区别
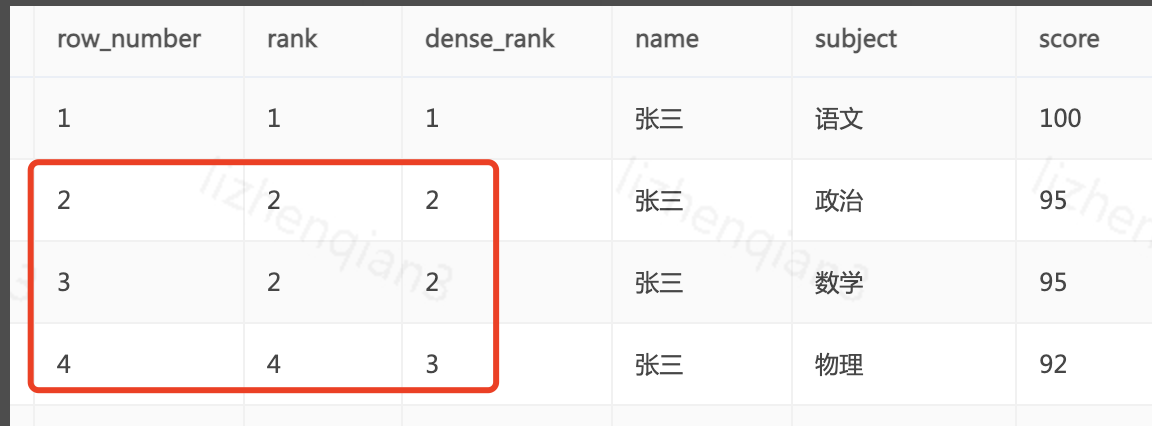
row_number 排序字段值相同时,序号不同,下一个序号顺序自增
rank 排序字段值相同时,序号相同,下一个序号跳跃自增
dense_rank 排序字段值相同时,序号相同,下一个序号顺序自增
本文转载自: https://blog.csdn.net/h18208975507/article/details/128837147
版权归原作者 西奥斯 所有, 如有侵权,请联系我们删除。
版权归原作者 西奥斯 所有, 如有侵权,请联系我们删除。