
用户不仅能通过命令行的形式操作Kafka服务,Kafka还提供了许多编程语言的客户端工具,用户在开发独立项目时,通过调用Kafka API 来操作Kafka集群,其核心API主要有以下5种。
(1)Producer API:构建应用程序发送数据流到Kafka集群中的主题。(2)Consumer API:构建应用程序从Kafka集群中的主题读取数据流。(3)StreamsAPI:构建流处理程序的库,能够处理流式数据。
(4)Connect API:实现连接器,用于在Kafka和其他系统之间可扩展的、可靠的流式传输数据的工具。
(5)AdminClientAPI:构建集群管理工具,查看Kafka集群组件信息。
Kafka作为流数据处理平台,本身功能强大,技术难度较高,有兴趣的读者可以通过官网深入学习。本章将介绍常用 Producer API 以及 Consumer API 来辅助学习 Spark实时计算框架。
在开发生产者客户端时,ProducerAPI提供了KafkaProducer类,该类的实例化对象用来代表一个生产者进程,生产者发送消息时,并不是直接发送给服务端,而是先在客户端中把消息存入队列中,然后由一个发送线程从队列中消费消息,并以批量的方式发送消息给服务端,关于KafkaProducer类常用的方法如下图所示。
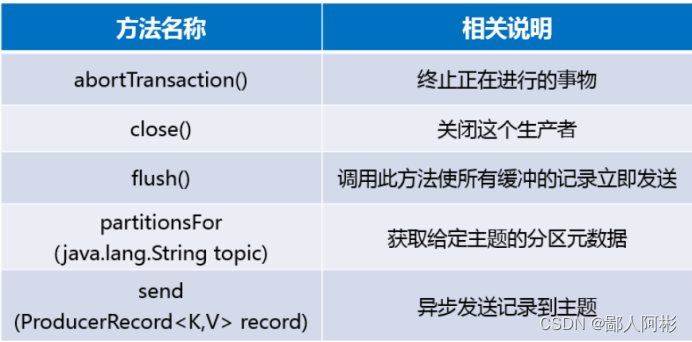
生产者客户端用来向Kafka集群中发送消息,消费者客户端则是从Kafka集群中消费消息。作为分布式消息系统,Kafka支支持多个生产者和多个消费者,生产者可以将消息发布到集群中不同节点的不同分区上,消费费者也可以消费集群中多个节点的多个分区上的消息,
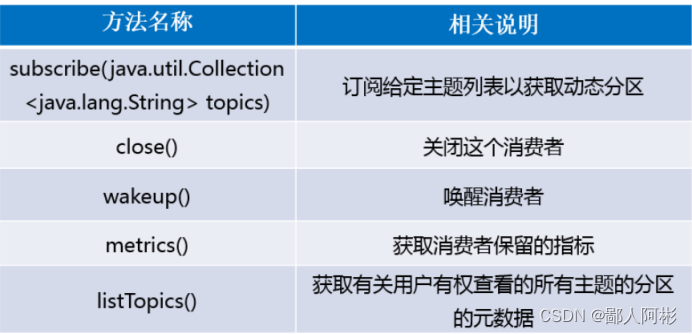
消费者应用程序是由KafkaConsumer 对象代表的一个消费者客户端进程,KafkaConsumer
类常用的方法如下图所示。
接下来,以实例演示的分式介绍Kafka的Java API操作方式。
1、创建工程,添加以下依赖:
创建一个Maven工程,在pom.xml文件中添加Kafka依赖包。
<dependencies><dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
2、编写生产者客户端,代码如下:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class KafkaProduceTest {
public static void main(String[] args) {
Properties props = new Properties();
//指定Kafka集群的IP地址和端口号
props.put("bootstrap.servers",
"master:9092,slave1:9092,slave2:9092");
//指定等待所有副本节点的应答
props.put("acks","all");
//指定消息发送最大尝试次数
props.put("retries",0);
//指定一批消息处理大小
props.put("batch.size",16384);
//指定请求延时
props.put("linger.ms",1);
//指定缓存区内存大小
props.put("buffer.memory",33554432);
//设置key序列化
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
//设置value序列化
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
//生产数据
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(props);
for (int i =0; i < 50; i++){
producer.send(new ProducerRecord<String, String>
("whhtopic",Integer.toString(i),"hello world-" + i));
}
producer.close();
}
}
(1)bootstrap.servers:设置Kafka集群的IP地址和端口号。
2)acks:消息确认机制,该值设置为all,这种策略会保证只要有一个备份存活就不会丢失数据,这种方案是最安全可靠的,但同时效率也会降低。
(3)retries:如果当前请求失败,则生产者可以自动重新连接,但是设置retries=0参数,则意味请求失败不会重复连接,这样可以避免消息重复发送的可能。
(4)batch.size:生产者为每个分区维护了未发送数据的内存缓冲区,该缓冲区设置的越大,吞吐量和效率就越高,但也会浪费更多的内存。
(5)linger.ms:指定请求延时,意味着如果在缓冲区没有被填满的情况下,会增加1ms的延迟,等待更多的数据进入缓冲区从而增加内存利用率。在默认情况下,即使缓冲区中有其他未使用的空间,也可以立即发送缓冲区。
(6)buffer.memory:指定缓冲区大小。
(7)key.serializer、value.serializer:数据在网络中传输需要进行序列化。
第27~32行代码,作用是模拟消息源,向名为itcasttopic的主题中发送消息数据。向 Kafka集群发送消息数据时,只需要调用KafkaProducer类的send(()方法,该方法是异步的,调用时,它会将消息数据添加到待处理消息数据发送的缓冲区中,最终以批处理的方式处理消息数据,从而提高效率。send()方法中有3个参数,第1个参数是指定发送主题,第2个参数是设置消息的Key,第3个参数是消息的Value。
3、编写消费者客户端
通过Kafka API 创建KafkaConsumer对象,用来消费Kafka集群中名为whhtopic主题的消息数据。在工程下创建KafkaConsumerTest.java文件,代码如下:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class KafkaProduceTest {
public static void main(String[] args) {
Properties props = new Properties();
//指定Kafka集群的IP地址和端口号
props.put("bootstrap.servers",
"master:9092,slave1:9092,slave2:9092");
//指定等待所有副本节点的应答
props.put("acks","all");
//指定消息发送最大尝试次数
props.put("retries",0);
//指定一批消息处理大小
props.put("batch.size",16384);
//指定请求延时
props.put("linger.ms",1);
//指定缓存区内存大小
props.put("buffer.memory",33554432);
//设置key序列化
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
//设置value序列化
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
//生产数据
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(props);
for (int i =0; i < 50; i++){
producer.send(new ProducerRecord<String, String>
("whhtopic",Integer.toString(i),"hello world-" + i));
}
producer.close();
}
}
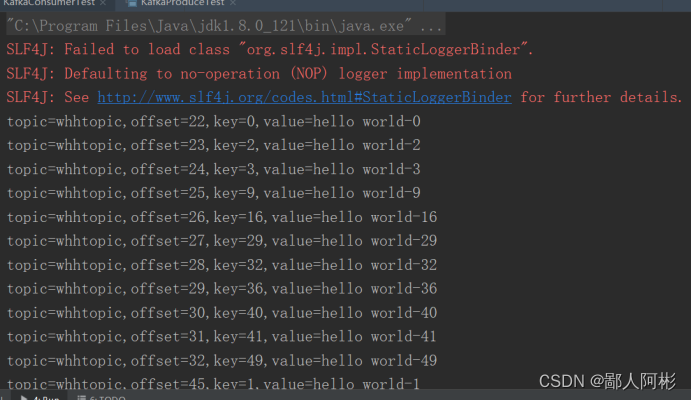
生产者客户端和消费者客户端编写完之后,就先运行生产者的代码,再运行消费者代码,此时消费者客户端并没有数据,需要再次运行生产者,运行结果如下:
版权归原作者 鄙人阿彬 所有, 如有侵权,请联系我们删除。