
1、Flask框架简介
Flask是一个使用Python编写的轻量级Web应用框架,可扩展性很强,相较于Django框架,灵活度很高,开发成本底。它仅仅实现了Web应用的核心功能,Flask由两个主要依赖组成,提供路由、调试、Web服务器网关接口的Werkzeug 实现的和模板语言依赖的jinja2,其他的一切都可以由第三方库来完成。

2、Flask框架安装
在使用Flask之前需要安装一下,安装Flask非常简单只需要在在命令行输入
pip install flask即可
3、Flask实现 Hello World案例
# 导入 Flask 类
from flask import Flask
# 创建了这个类的实例。第一个参数是应用模块或者包的名称。
app = Flask(__name__)
# 使用 route() 装饰器来告诉 Flask 触发函数的 URL
@app.route("/")
def hello():
return "Hello World!"
if __name__ == "__main__":
# 使用 run() 函数来运行本地服务器和我们的应用
app.run()

4、Flask深度学习模型部署
本文通过使用轻量级的WEB框架Flask来实现Python在服务端的部署CIFAR-10的图像分类。效果如下:

CIFAR-10是一个小型图像分类数据集,数据格式类似于MNIST手写数字数据集,在CIFAR-10数据中图片共有10个类别,分别为airplane、automobile、bird、cat、deer、dog、frog、horse、ship、truck。

4.1 数据加载
对于CIFAR-10分类任务,PyTorch里的torchvision库提供了专门数据处理函数torchvision.datasets.CIFAR10,构建DataLoader代码如下:
import torchvision
from torchvision import transforms
import torch
from config import data_folder, batch_size
def create_dataset(data_folder, transform_train=None, transform_test=None):
if transform_train is None:
transform_train = transforms.Compose(
[
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
(0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010)
)
]
)
if transform_test is None:
transform_test = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(
(0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010)
)
]
)
trainset = torchvision.datasets.CIFAR10(
root=data_folder, train=True, download=True, transform=transform_train
)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=batch_size, shuffle=True, num_workers=2
)
testset = torchvision.datasets.CIFAR10(
root=data_folder, train=False, download=True, transform=transform_test
)
testloader = torch.utils.data.DataLoader(
testset, batch_size=batch_size, shuffle=False, num_workers=2
)
return trainloader, testloader
4.2 构建模型resent18实现分类
from torch import nn
import torch.nn.functional as F
# 定义残差块ResBlock
class ResBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride=1):
super(ResBlock, self).__init__()
# 这里定义了残差块内连续的2个卷积层
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != outchannel:
# shortcut,这里为了跟2个卷积层的结果结构一致,要做处理
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
def forward(self, x):
out = self.left(x)
# 将2个卷积层的输出跟处理过的x相加,实现ResNet的基本结构
out = out + self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, ResBlock, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.inchannel = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.layer1 = self.make_layer(ResBlock, 64, num_blocks[0], stride=1)
self.layer2 = self.make_layer(ResBlock, 128, num_blocks[1], stride=2)
self.layer3 = self.make_layer(ResBlock, 256, num_blocks[2], stride=2)
self.layer4 = self.make_layer(ResBlock, 512, num_blocks[3], stride=2)
self.fc = nn.Linear(512, num_classes)
# 这个函数主要是用来,重复同一个残差块
def make_layer(self, block, channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.inchannel, channels, stride))
self.inchannel = channels
return nn.Sequential(*layers)
def forward(self, x):
# 在这里,整个ResNet18的结构就很清晰了
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
def resnet18():
return ResNet(ResBlock, [2, 2, 2, 2])
if __name__ == '__main__':
from torchsummary import summary
from config import device
# vggnet = vgg11().to(device)
resnet = resnet18().to(device)
# summary(vggnet, (3, 32, 32))
summary(resnet, (3, 32, 32))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 32, 32] 1,728
BatchNorm2d-2 [-1, 64, 32, 32] 128
ReLU-3 [-1, 64, 32, 32] 0
Conv2d-4 [-1, 64, 32, 32] 36,864
BatchNorm2d-5 [-1, 64, 32, 32] 128
ReLU-6 [-1, 64, 32, 32] 0
Conv2d-7 [-1, 64, 32, 32] 36,864
BatchNorm2d-8 [-1, 64, 32, 32] 128
ResBlock-9 [-1, 64, 32, 32] 0
Conv2d-10 [-1, 64, 32, 32] 36,864
BatchNorm2d-11 [-1, 64, 32, 32] 128
ReLU-12 [-1, 64, 32, 32] 0
Conv2d-13 [-1, 64, 32, 32] 36,864
BatchNorm2d-14 [-1, 64, 32, 32] 128
ResBlock-15 [-1, 64, 32, 32] 0
Conv2d-16 [-1, 128, 16, 16] 73,728
BatchNorm2d-17 [-1, 128, 16, 16] 256
ReLU-18 [-1, 128, 16, 16] 0
Conv2d-19 [-1, 128, 16, 16] 147,456
BatchNorm2d-20 [-1, 128, 16, 16] 256
Conv2d-21 [-1, 128, 16, 16] 8,192
BatchNorm2d-22 [-1, 128, 16, 16] 256
ResBlock-23 [-1, 128, 16, 16] 0
Conv2d-24 [-1, 128, 16, 16] 147,456
BatchNorm2d-25 [-1, 128, 16, 16] 256
ReLU-26 [-1, 128, 16, 16] 0
Conv2d-27 [-1, 128, 16, 16] 147,456
BatchNorm2d-28 [-1, 128, 16, 16] 256
ResBlock-29 [-1, 128, 16, 16] 0
Conv2d-30 [-1, 256, 8, 8] 294,912
BatchNorm2d-31 [-1, 256, 8, 8] 512
ReLU-32 [-1, 256, 8, 8] 0
Conv2d-33 [-1, 256, 8, 8] 589,824
BatchNorm2d-34 [-1, 256, 8, 8] 512
Conv2d-35 [-1, 256, 8, 8] 32,768
BatchNorm2d-36 [-1, 256, 8, 8] 512
ResBlock-37 [-1, 256, 8, 8] 0
Conv2d-38 [-1, 256, 8, 8] 589,824
BatchNorm2d-39 [-1, 256, 8, 8] 512
ReLU-40 [-1, 256, 8, 8] 0
Conv2d-41 [-1, 256, 8, 8] 589,824
BatchNorm2d-42 [-1, 256, 8, 8] 512
ResBlock-43 [-1, 256, 8, 8] 0
Conv2d-44 [-1, 512, 4, 4] 1,179,648
BatchNorm2d-45 [-1, 512, 4, 4] 1,024
ReLU-46 [-1, 512, 4, 4] 0
Conv2d-47 [-1, 512, 4, 4] 2,359,296
BatchNorm2d-48 [-1, 512, 4, 4] 1,024
Conv2d-49 [-1, 512, 4, 4] 131,072
BatchNorm2d-50 [-1, 512, 4, 4] 1,024
ResBlock-51 [-1, 512, 4, 4] 0
Conv2d-52 [-1, 512, 4, 4] 2,359,296
BatchNorm2d-53 [-1, 512, 4, 4] 1,024
ReLU-54 [-1, 512, 4, 4] 0
Conv2d-55 [-1, 512, 4, 4] 2,359,296
BatchNorm2d-56 [-1, 512, 4, 4] 1,024
ResBlock-57 [-1, 512, 4, 4] 0
Linear-58 [-1, 10] 5,130
================================================================
Total params: 11,173,962
Trainable params: 11,173,962
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 13.63
Params size (MB): 42.63
Estimated Total Size (MB): 56.26
----------------------------------------------------------------
4.3 模型训练
1)损失函数
criterion = nn.CrossEntropyLoss()
2)优化器
optimizer= optim.SGD(net.parameters(), lr=lr, weight_decay=5e-4, momentum=0.9)
3)学习率
一般来说使用SGD优化器时初始学习率一般设置为0.01~0.1,Adam优化器的初始学习率一般设置为0.001~0.01.
4)训练与验证
模型训练过程:
① 梯度清零- optimizer.zero_grad()
② 前向传播- output = net(img)
③ 计算损失- loss = criterion(output, label)
④ 反向传播- loss.backward()
⑤ 更新参数- optimizer.step()
⑥ 验证模型。with torch.no_grad():
net.eval()
from torch import optim, nn
import torch
import os.path as osp
from tqdm import tqdm
from torch.utils.tensorboard import SummaryWriter
from config import epochs, device, data_folder, checkpoint_folder
from data import create_dataset
from model import resnet18
def train(
net, trainloader, valloader,
criteron, epochs, device, model_name='cls'
):
best_acc = 0.0
best_loss = 1e9
writer = SummaryWriter('../CIFAR-10图像分类/log')
if osp.exists(osp.join(checkpoint_folder, model_name+'.pth')):
net.load_state_dict(
torch.load(osp.join(checkpoint_folder, model_name+'.pth'))
)
print('model loading')
for n, (num_epochs, lr) in enumerate(epochs):
optimizer = optim.SGD(
net.parameters(), lr=lr, weight_decay=5e-4, momentum=0.9
)
for epoch in range(num_epochs):
net.train()
epoch_loss = 0.0
epoch_acc = 0.0
for i, (img, label) in tqdm(
enumerate(trainloader), total=len(trainloader)
):
print(trainloader.shape, label.shape)
img, label = img.to(device), label.to(device)
output = net(img)
optimizer.zero_grad()
loss = criteron(output, label)
loss.backward()
optimizer.step()
if model_name == 'cls':
pred = torch.argmax(output, dim=1)
acc = torch.sum(pred == label)
epoch_acc += acc.item()
epoch_loss += loss.item() * img.shape[0]
epoch_loss /= len(trainloader.dataset)
if model_name == 'cls':
epoch_acc /= len(trainloader.dataset)
print('epoch loss: {:.2f} epoch accuracy: {:.2f}'.format(
epoch_loss, epoch_acc
))
writer.add_scalar(
'epoch_loss_{}'.format(model_name),
epoch_loss,
sum([e[0] for e in epochs[:n]]) + epoch
)
writer.add_scalar(
'epoch_acc_{}'.format(model_name),
epoch_acc,
sum([e[0] for e in epochs[:n]]) + epoch
)
else:
print('epoch loss: {:.2f}'.format(epoch_loss))
writer.add_scalar(
'epoch_loss_{}'.format(model_name),
epoch_loss,
sum([e[0] for e in epochs[:n]]) + epoch
)
with torch.no_grad():
net.eval()
val_loss = 0.0
val_acc = 0.0
for i, (img, label) in tqdm(
enumerate(valloader), total=len(valloader)
):
img, label = img.to(device), label.to(device)
output = net(img)
loss = criteron(output, label)
if model_name == 'cls':
pred = torch.argmax(
output, dim=1
)
acc = torch.sum(pred == label)
val_acc += acc.item()
val_loss += loss.item() * img.shape[0]
val_loss /= len(valloader.dataset)
val_acc /= len(valloader.dataset)
if model_name == 'cls':
if val_acc > best_acc:
best_acc = val_acc
torch.save(
net.state_dict(),
osp.join(checkpoint_folder, model_name + '.pth')
)
print('validation loss: {:.2f} validation acc: {:.2f}'.format(
val_loss, val_acc
))
writer.add_scalar(
'validation_loss_{}'.format(model_name),
val_loss,
sum([e[0] for e in epochs[:n]]) + epoch
)
writer.add_scalar(
'validation_acc_{}'.format(model_name),
val_acc,
sum([e[0] for e in epochs[:n]]) + epoch
)
writer.close()
if __name__ == '__main__':
trainloader, valloader = create_dataset(data_folder)
net = resnet18().to(device)
criteron = nn.CrossEntropyLoss()
train(net, trainloader, valloader, criteron, epochs, device)
模型训练完成在checkpoint文件夹下会生成分类模型文件cls.pth
4.4 使用Flask搭建服务接口
from flask import (Flask, render_template, request, flash, redirect, url_for, make_response, jsonify, send_from_directory)
from werkzeug.utils import secure_filename
import os
import time
from datetime import timedelta
from predict import pred
import json
ALLOWED_EXTENSIONS = set(["png","jpg","JPG","PNG", "bmp","jpeg"])
def is_allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = 'imgs/'
#设置编码
app.config['JSON_AS_ASCII'] = False
# 静态文件缓存过期时间
app.send_file_max_age_default = timedelta(seconds=1)
@app.route('/uploads/<filename>')
def uploaded_file(filename):
return send_from_directory(app.config['UPLOAD_FOLDER'],filename)
@app.route('/result/')
def show_json(filename,class_name):
return ({"name":filename, "class_name":class_name})
# @app.route("/uploads",methods = ['POST', 'GET'])
@app.route("/",methods = ['POST', 'GET'])
def uploads():
if request.method == "POST":
#file = request.files['file']
uploaded_files = request.files.getlist("file[]")
weight_path2 = os.path.join("static", "cls.pth")
filenames = {
"airplane":[],
"automobile":[],
"bird":[],
"cat":[],
"deer":[],
"dog":[],
"frog":[],
"horse":[],
"ship":[],
"truck":[],
}
for file in uploaded_files:
print(file)
if file and is_allowed_file(file.filename):
# basepath = os.path.dirname(__file__)
filename = secure_filename(file.filename)
file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
img_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
class_index,class_name = pred(img_path, weight_path2)
filenames[class_name].append(filename)
print(class_index,class_name)
result = show_json(filename,class_name)
print(result)
#data.append(result)
#res_json = json.dumps({"status": "200", "msg": "success","data":data})
return render_template('upload_more_ok.html',
filenames=filenames,
)
return render_template("upload_more.html", path="./images/test.jpg")
if __name__ == "__main__":
# 0.0.0.0表示你监听本机的所有IP地址上,通过任何一个IP地址都可以访问到.
# port为端口号
# debug=Fasle表示不开启调试模式
app.run(host='127.0.0.1', port=5000, debug=True)
通过访问以下地址进行图像识别

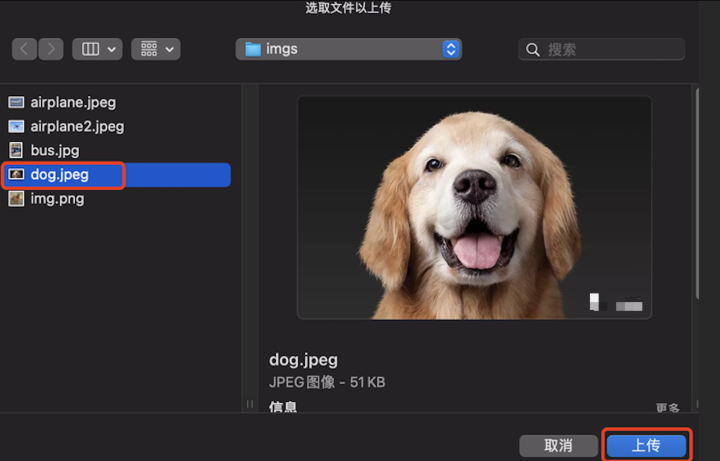
点击选取文件,dog.jpeg 进行上传

点击识别图片结果如下:

通过以上代码可以实现在服务端进行CIFAR-10图像识别了,也可以通过训练自己的数据集,修改识别的类别数,加载训练好的模型,即可完成指定任务的图像识别。
版权归原作者 笑傲NLP江湖 所有, 如有侵权,请联系我们删除。