

点击蓝字关注我们
关注并星标
从此不迷路
计算机视觉研究院


学习群|扫码在主页获取加入方式

论文地址: https://arxiv.org/pdf/2208.09686.pdf
代码地址: https://github.com/YuHengsss/YOLOV
01
概述
视频目标检测(VID)具有挑战性,因为目标外观的高度变化以及某些帧中的各种劣化。积极的一面是,与静止图像相比,在视频的某一帧中进行检测可以得到其他帧的支持。因此,如何跨不同帧聚合特征是VID问题的关键。
大多数现有的聚合算法都是为两阶段检测器定制的。但是,由于两阶段的性质,此类检测器通常在计算上很耗时。今天分享的研究者提出了一种简单而有效的策略来解决上述问题,该策略花费了边际开销,并显著提高了准确性。具体来说,与传统的两阶段流水线不同,研究者主张将区域级候选放在一阶段检测之后,以避免处理大量低质量候选。此外,构建了一个新的模块来评估目标框架与其参考框架之间的关系,并指导聚合。
进行了广泛的实验和消融研究以验证新提出设计的有效性,并揭示其在有效性和效率方面优于其他最先进的VID方法。基于YOLOX的模型可以实现可观的性能(例如,在单个2080Ti GPU上的ImageNet VID数据集上以超过30 FPS的速度达到87.5% AP50),使其对大规模或实时应用程序具有吸引力。
02
背景

视频目标检测可以看作是静止图像目标检测的高级版本。直观地说,可以通过将帧一一输入静止图像目标检测器来处理视频序列。但是,通过这种方式,跨帧的时间信息将被浪费,这可能是消除/减少单个图像中发生的歧义的关键。
如上图所示,视频帧中经常出现运动模糊、相机散焦和遮挡等退化,显着增加了检测的难度。例如,仅通过查看上图中的最后一帧,人类很难甚至不可能分辨出物体在哪里和是什么。另一方面,视频序列可以提供比单个静止图像更丰富的信息。换言之,同一序列中的其他帧可能支持对某一帧的预测。因此,如何有效地聚合来自不同帧的时间消息对于准确性至关重要。从上图可以看出,研究者提出的方法给出了正确的答案。
03
新框架
考虑到视频的特性(各种退化与丰富的时间信息),而不是单独处理帧,如何从其他帧中为目标帧(关键帧)寻求支持信息对于提高视频检测的准确性起着关键作用。最近的尝试是在准确性上的显着提高证实了时间聚合对问题的重要性。然而,大多数现有方法都是基于两阶段的技术。
如前所述,与一级基础相比,它们的主要缺点是推理速度相对较慢。为了减轻这种限制,研究者将区域/特征选择放在单级检测器的预测头之后。
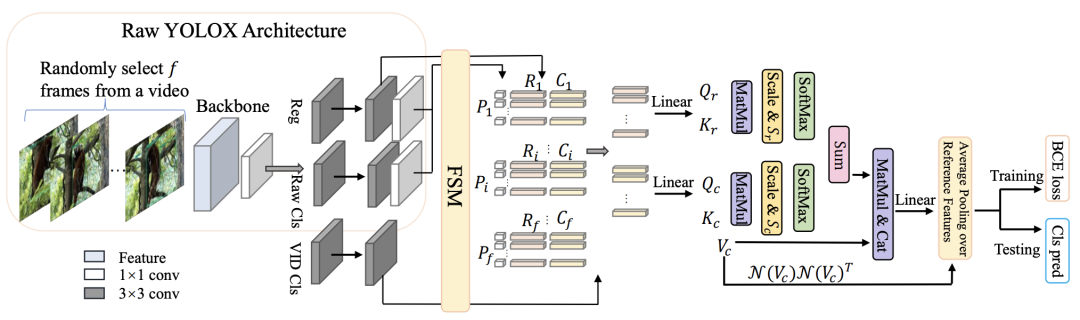
研究者选择YOLOX作为基础来展示研究者的主要主张。提出的框架如上图所示。
让我们回顾一下传统的两阶段管道:
1)首先“选择”大量候选区域作为提议;
2)确定每个提议是否是一个目标以及它属于哪个类。计算瓶颈主要来自于处理大量的低置信区域候选。
从上图可以看出,提出的框架也包含两个阶段。不同的是,它的第一阶段是预测(丢弃大量低置信度的区域),而第二阶段可以被视为区域级细化(通过聚合利用其他帧)。
通过这一原则,新的设计可以同时受益于一级检测器的效率和从时间聚合中获得的准确性。值得强调的是,如此微小的设计差异会导致性能上的巨大差异。所提出的策略可以推广到许多基础检测器,例如YOLOX、FCOS和PPYOLOE。
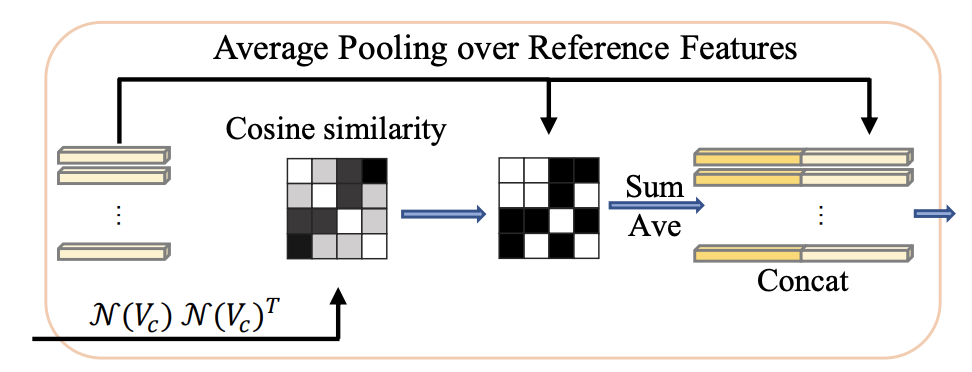
此外,考虑到softmax的特性,可能一小部分参考特征持有大部分权重。换句话说,它经常忽略低权重的特征,这限制了可能后续使用的参考特征的多样性。
为了避免这种风险,研究者引入了平均池化参考特征(A.P.)。具体来说,选择相似度得分高于阈值τ的所有参考,并将平均池化应用于这些。请注意,这项工作中的相似性是通过N (Vc)N(Vc)T计算的。算子N(·)表示层归一化,保证值在一定范围内,从而消除尺度差异的影响。通过这样做,可以维护来自相关特征的更多信息。然后将平均池化特征和关键特征传输到一个线性投影层中进行最终分类。该过程如是上图所示。
有人可能会问,N(Qc)N(Kc)T或N(Qr)N(Kr)T是否可以作为相似度执行。事实上,这是另一种选择。但是,在实践中,由于Q和K之间的差异,它不像我们在训练期间的选择那样稳定。
04
实验及可视化
对于给定的关键候选,通过三种不同方法选择的参考候选之间的视觉比较。展示了4个在聚合中贡献最大的参考候选。


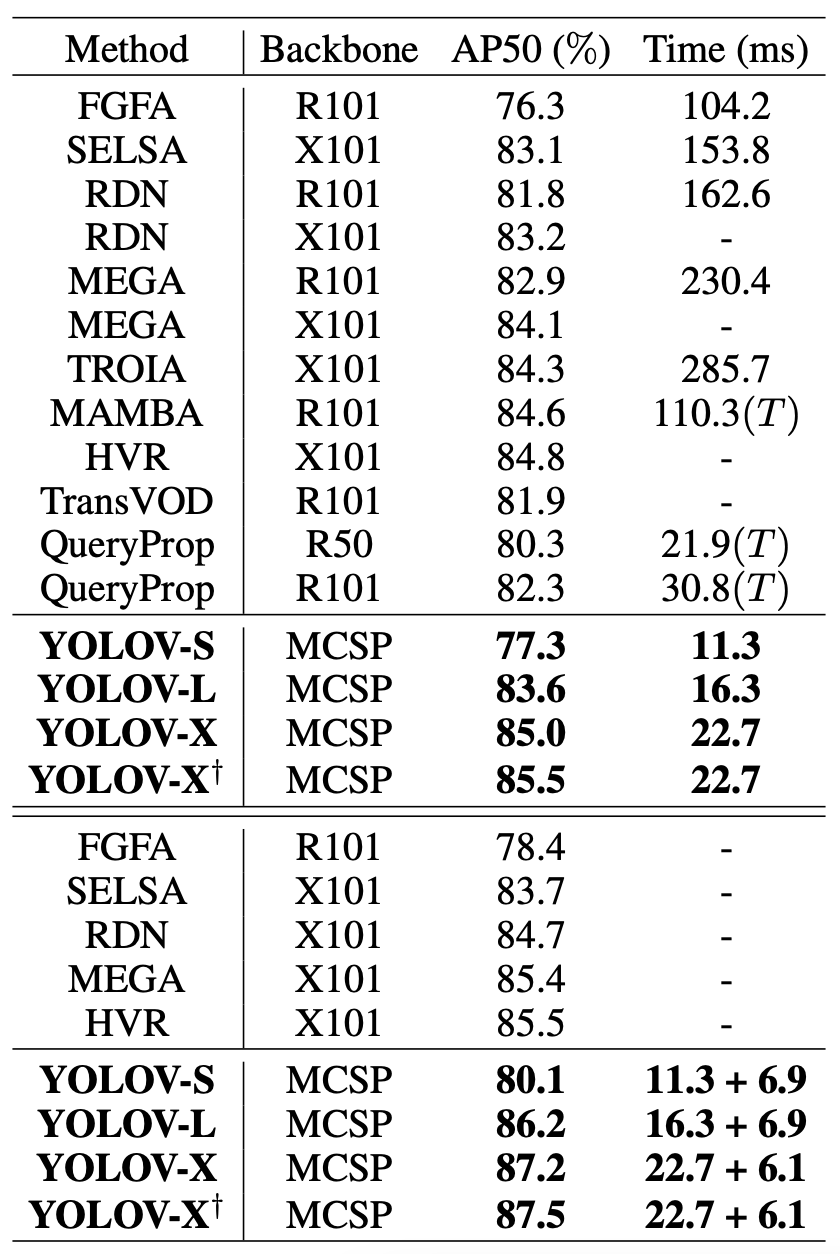
具体来说,在下表的上半部分,研究者报告了所涉及的竞争模型的性能,而没有采用任何后处理。由于一级检测器的特性和研究者的策略的有效性,YOLOV可以显著利用检测精度和推理效率。为了公平比较,下表中列出的所有模型都在相同的硬件环境下进行了测试,除了MAMBA和查询属性。下表的下半部分报告了YOLOV和其他带有后处理的SOTA模型的结果。在i7-8700K CPU上测试后处理的时间成本。

上排是基础的检测结果,下排是YoloV的结果
**© THE END **
转载请联系本公众号获得授权
计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、图像分割、模型量化、模型部署等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606

往期推荐
01
● Yolov7:最新最快的实时检测框架,最详细分析解释(附源代码)
► 点击阅读
02
● ECCV2022:在Transformer上进行递归,不增参数,计算量还少!
► 点击阅读
03
● 改进的YOLO:AF-FPN替换金字塔模块提升目标检测精度
► 点击阅读
04
● QueryDet:级联稀疏query加速高分辨率下的小目标检测(代码已开源)
► 点击阅读
版权归原作者 计算机视觉研究院 所有, 如有侵权,请联系我们删除。