
简介
Web Fuzzer 序列就是将多个 Web Fuzzer 节点串联起来,实现更复杂的逻辑与功能。例如我们需要先进行登录,然后再进行其他操作,这时候我们就可以使用 Web Fuzzer 序列功能。或者是我们在一次渗透测试中需要好几个步骤才能验证是否有漏洞这种场景。
像这种如果使用burp来操作这种需要好几个步骤这种场景,往往很难实现。在Yakit里面实现起来相对来说就比较容易了。接下来我们一起来看看在文件上传的时候,我们怎么利用序列来完成上传并验证的。
前置知识
在使用序列之前需要我们了解几个高级配置:匹配器,数据提取器,变量。
匹配器
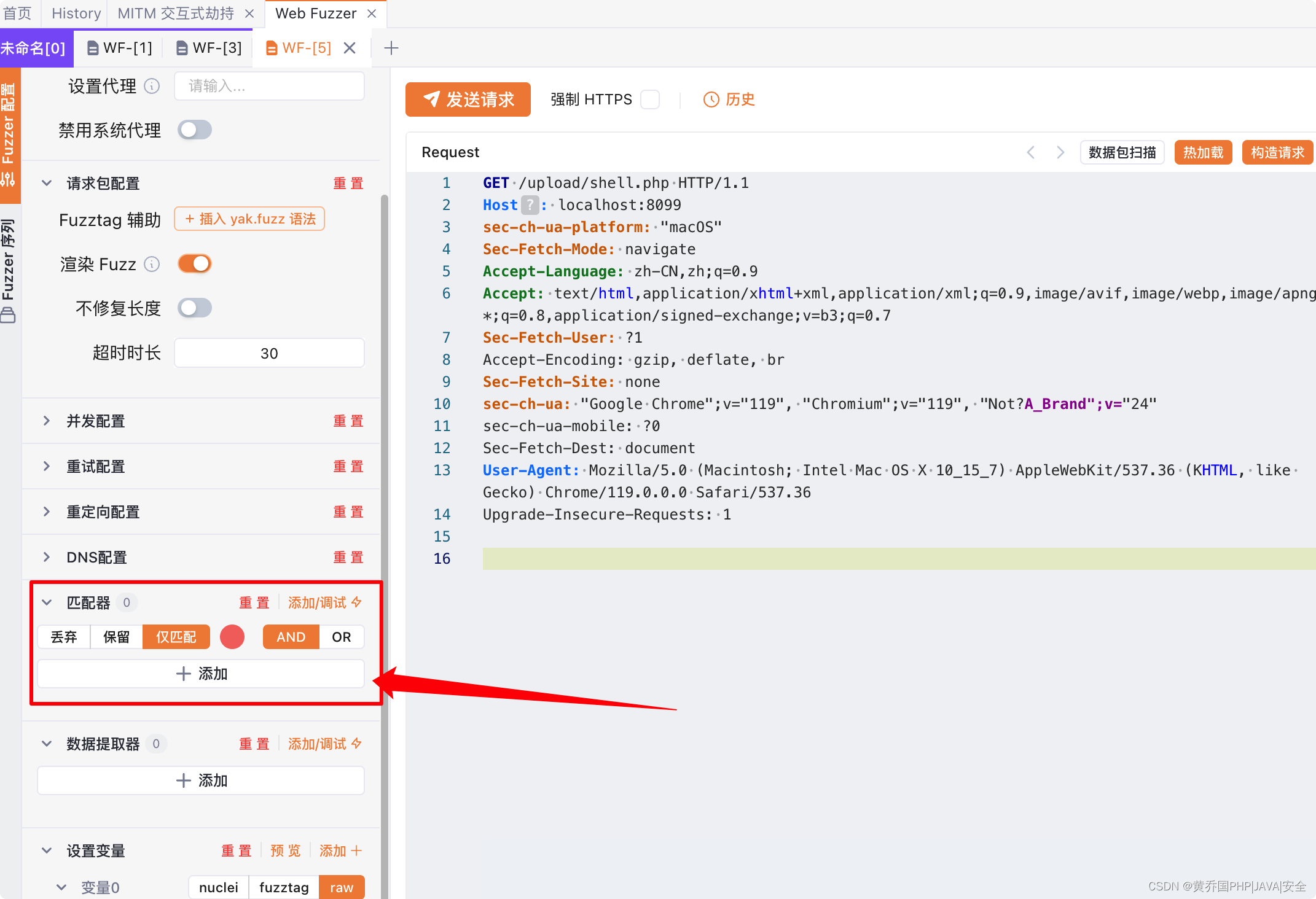
我们先看一共有三种匹配模式:丢弃,保留,仅匹配。这三个模式很好理解:
- 丢弃:丢弃模式会在符合匹配器时下丢弃返回包。
- 保留:保留模式会在符合匹配器时保留返回包,剩余的返回包则直接丢弃。
- 仅匹配:仅匹配模式会在符合匹配器时将对应的返回包染色,而不做其他操作。 在匹配模式的旁边,有一个红色的圈,这里实际上是颜色按钮,用于设置在仅匹配模式下的染色颜色。
再往右看,有两个二选一按钮:AND和OR。这两个按钮用于设置多个数据提取器的匹配逻辑,AND表示所有匹配器的条件都需要匹配,OR表示只需要有其中一个条件匹配即可。
接下来我们来讲解一下如何添加匹配器,我们点击下方的添加按钮或者图中右上角的添加/调试按钮,就可以添加匹配器了。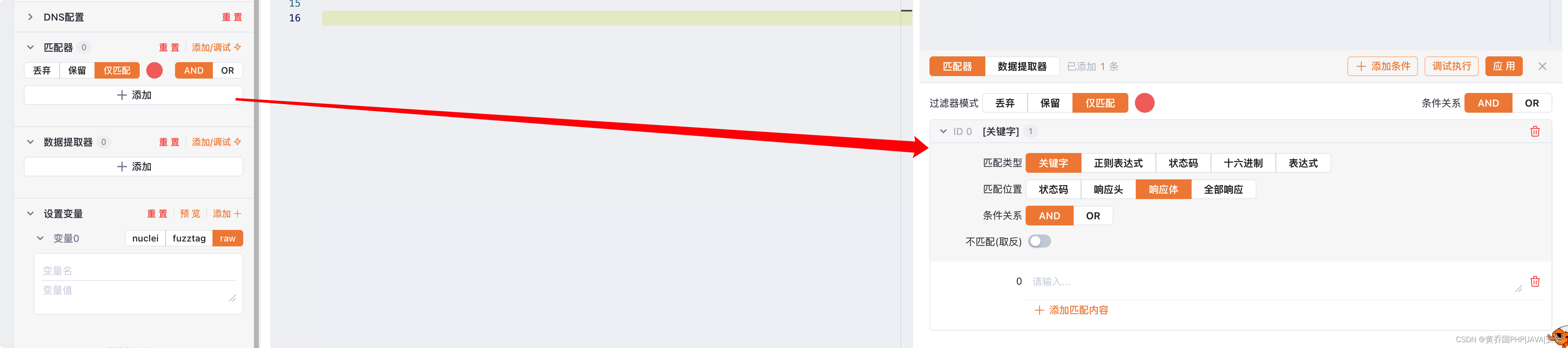
匹配器给我们提供了多种匹配类型与匹配位置,方便我们编写复杂的匹配器。
首先我们来介绍匹配类型:
- 关键字:关键字就是在匹配位置中匹配输入的关键字。
- 正则表达式:正则表达式就是在匹配位置中匹配输入的正则表达式。
- 状态码:(忽略匹配位置)状态码就是匹配响应的状态码,我们只需要填写希望匹配到的状态码即可。
- 十六进制:在某些情况下,希望匹配的字符串不是正常可见的ascii码,这时候你就可以使用十六进制这种匹配类型,输入十六进制字符串(例如字符串"302"对应十六进制字符串"333032")。
- 表达式:(忽略匹配位置)表达式可以更加灵活地编写我们所希望的匹配规则,它还能与后续要讲的 高级配置:变量 联动。表达式的语法与nuclei-dsl语法兼容,熟悉nuclei工具的师傅可以尝试在表达式中编写一些复杂的匹配规则。
然后我们再来介绍匹配位置,我们以下面这个响应包为例:
HTTP/1.1 302 Found
Connection: keep-alive
Content-Type: text/html; charset=utf-8
Location: https://www.baidu.com/
Content-Length: 154
<html><body>302 Found</body></html>
- 状态码:匹配范围仅有状态码。
- 响应头:匹配范围包含响应的第一行(在例子是HTTP/1.1 302 Found)以及响应头。
- 响应体:匹配范围包含响应正文(在例子里是302 Found)。
- 全部响应:匹配范围即整个响应包。
数据提取器
数据提取器的功能是将响应包中的某些数据提取出来。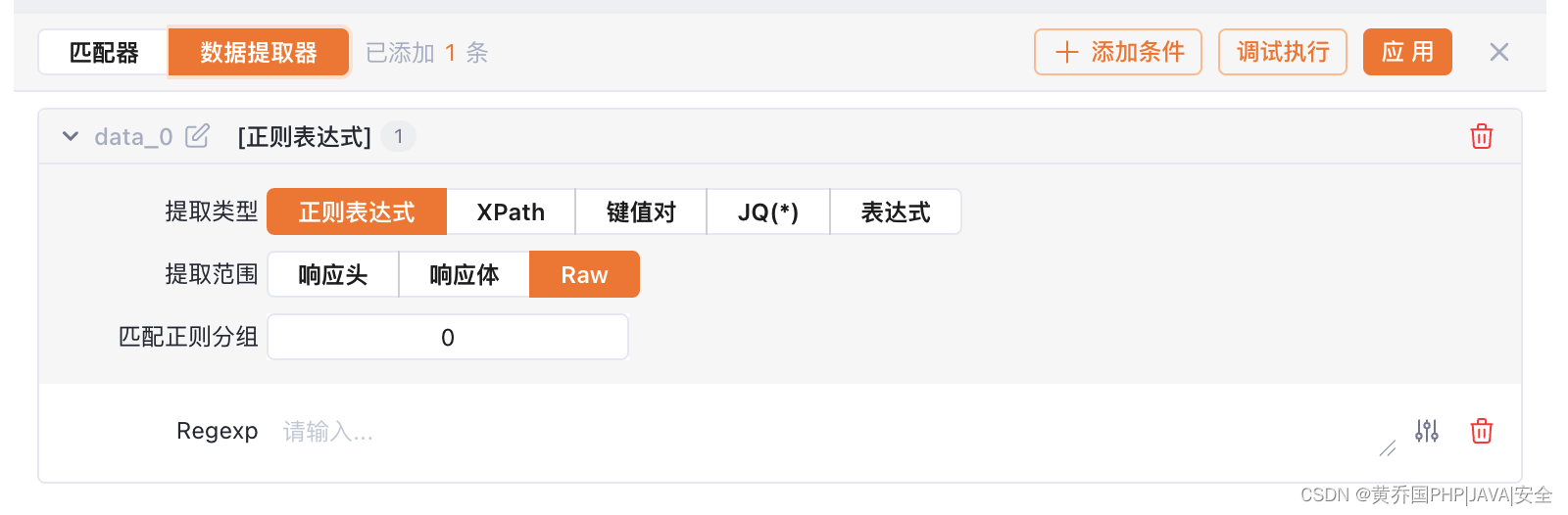
数据提取器同样给我们提供了多种提取类型与提取位置,方便我们编写复杂的数据提取器。我们可以看到在数据提取器的左上角(data_0)旁边存在一个编写按钮,这是用于修改提取器的名字,这个名字可以在后续变量和Web Fuzzer序列中使用。
首先我们来介绍提取类型:
- 正则表达式:正则表达式就是在提取位置中提取输入的正则表达式匹配到的内容。我们知道在正则表达式中可以使用小括号来分组,这时候我们可以在匹配正则分组中选择分组,这样就可以提取到想要的内容了。(在正则表达式中,0分组即为正则表达式匹配到的所有内容)
- XPath:(提取范围只能是响应体)XPath就是在提取位置中提取输入的XPath匹配到的内容。XPath是一种用于在XML文档中选择节点的语言,我们也可以很轻易地使用浏览器开发工具来复制完整的Xpath。
- 键值对:键值对的提取规则稍微有点复杂。键值对会尝试提取所有可能存在的json的key对应的value,以及所有形似key=value中value的值。如果提取位置包含响应头(提取范围为响应头或Raw),则他还会尝试提取响应头中的value值。另外还有两个特殊的键值对,分别为proto,status_code,分别对应响应的HTTP协议版本和响应状态码。
- JQ(*):(提取范围只能是响应体)jq是一种用于在JSON文档中选择节点的工具,其对应的文档教程在此。
- 表达式:(忽略匹配位置)表达式与上面匹配器中的表达式相同,这里不再赘述。
变量

我们提到数据提取器的名字可以在变量中使用,实际上就相当于我们赋值了一个变量。同样地,我们也可以直接在变量这个地方上直接赋值变量。
在上图中,我们可以设置变量名和变量值,变量可以在后续变量,Web Fuzzer序列和当前Web Fuzzer中使用。我们可以通过使用fuzztag:{{params(变量名)}}或{{p(变量名)}}来使用变量。
变量同样存在三种模式:nuclei,fuzztag,raw。
- nuclei:nuclei模式下,其变量值实际上是nuclei的表达式,可以调用绝大部分nuclei-dsl中包含的函数。需要注意的是,当你引用其他变量时,其的值都是string类型,所以可能需要手动进行类型转换。一个简单的例子如下:{{int(a)+3}}。
- fuzztag:fuzzta模式下,其变量值实际上就是fuzztag,在值中使用fuzztag也会使得Web Fuzzer发送多个请求包。一个简单的例子如下:{{int(1-2)}}。
- raw:raw模式下,变量值相当于你输入的字符串,不会被解析。
文件上传漏洞的上传与校验序列操作
这个地方利用uploadlabs的第一关来进行演示。
第一关主要是前端校验,所以我们将上传的数据包进行抓包,然后修改文件后缀即可。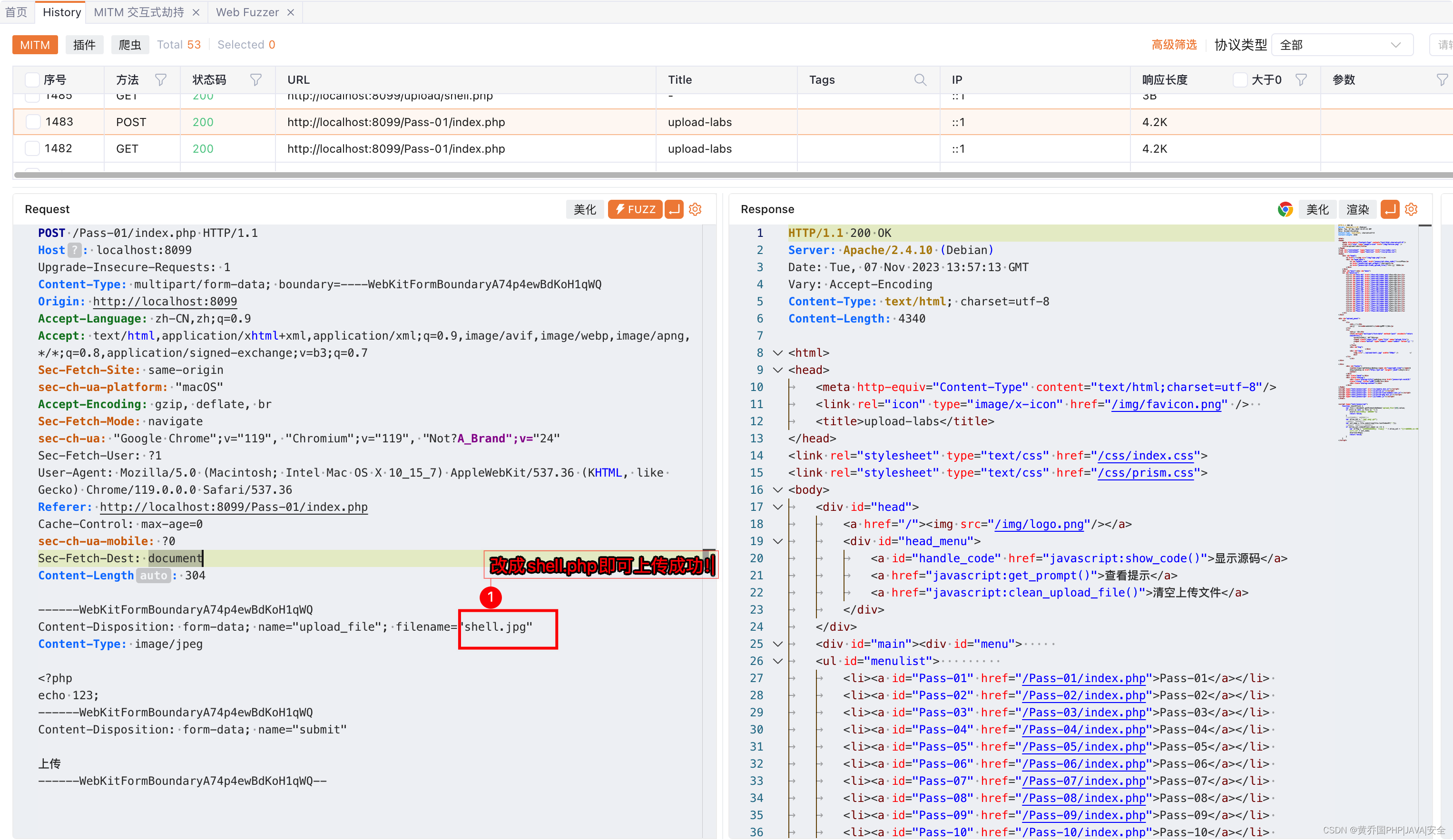
将对应的上传文件的请求,发送到webfuzzer,WF-[1],并且创建数据提取器:path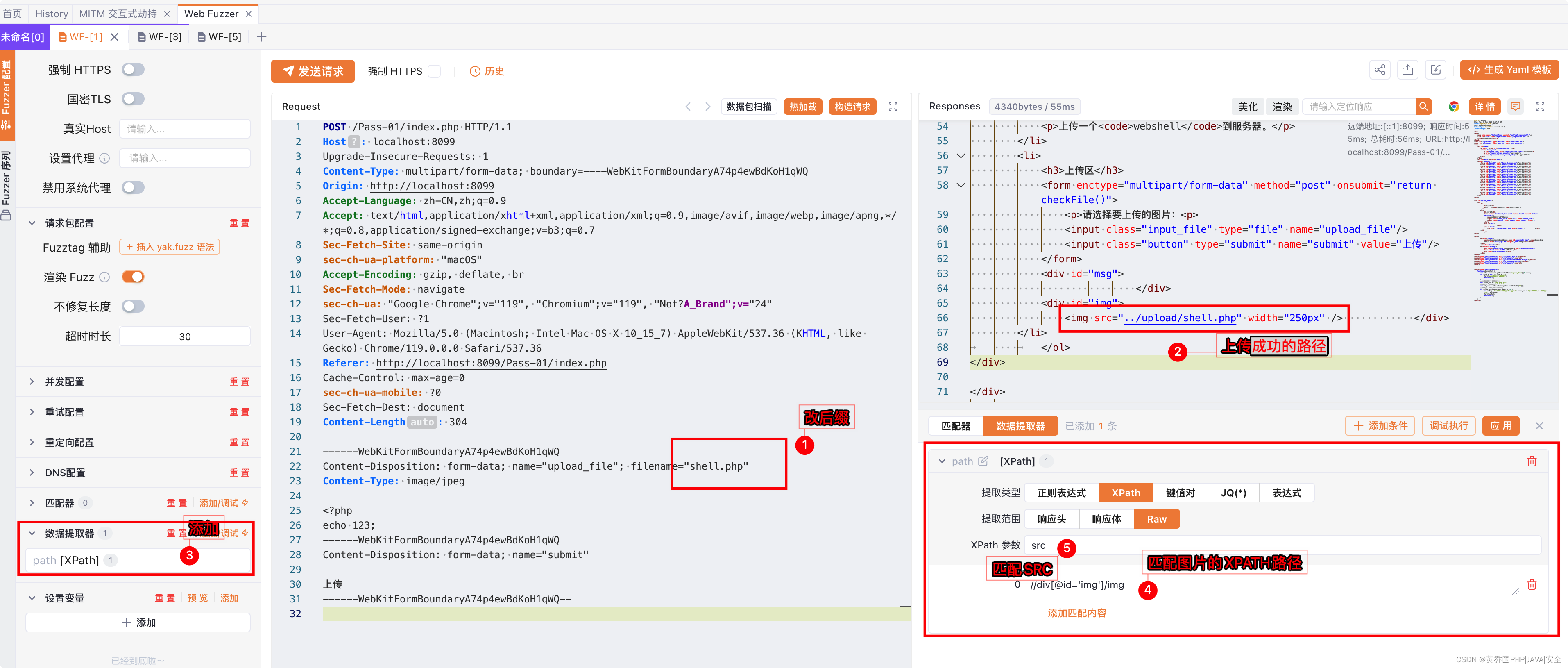
然后在将校验是否上传成功的请求发送到webfuzzer,WF-[3],并设置变量: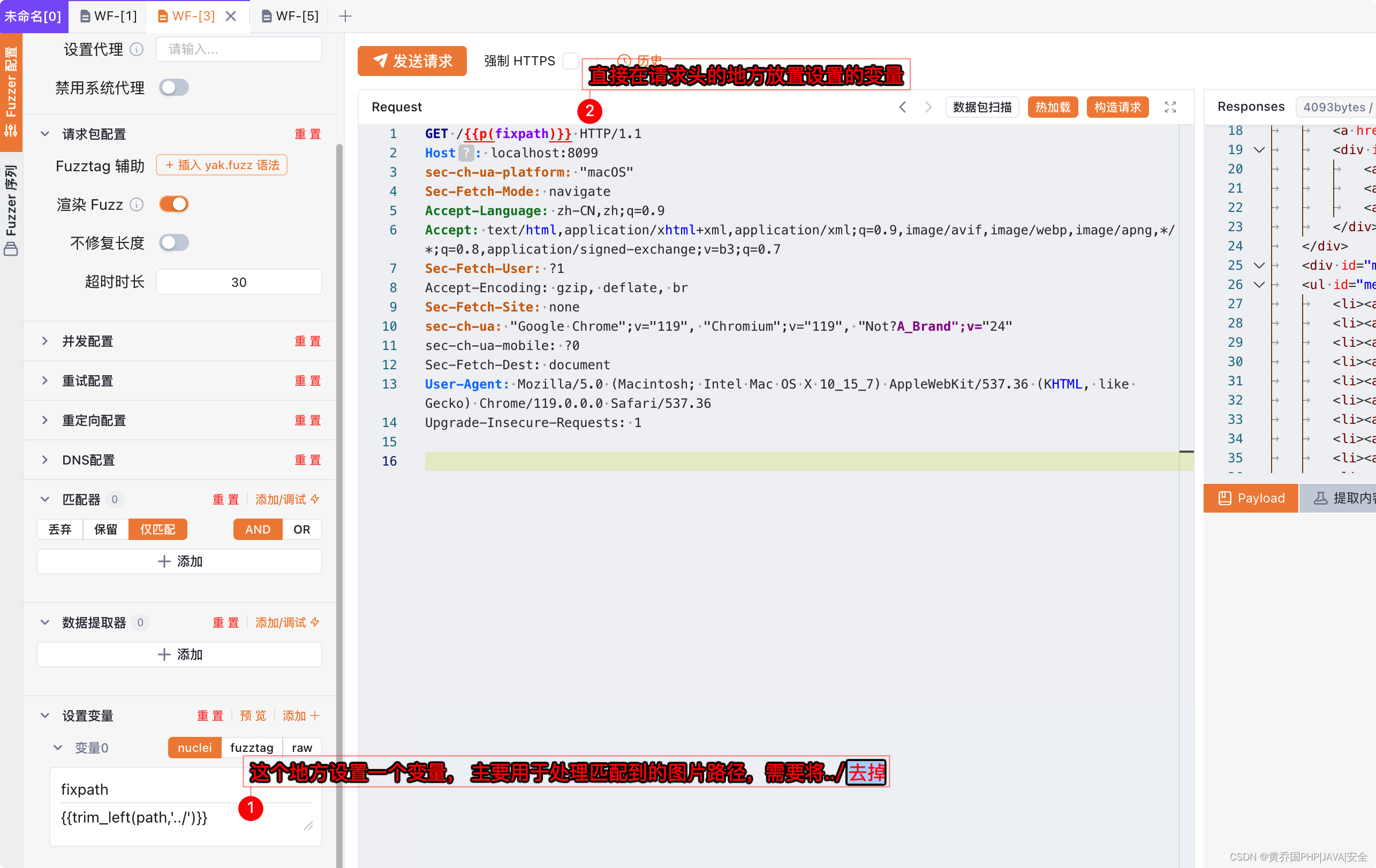
这个地方特别注意:
在WF-[1]中设置了数据提取器,名字为path, 这个path最终获取到的是图片路径, 这个图片路径签名有个../
所以我们需要将这个../去掉
那么就在WF-[3]中去设置了一个变量:fixpath, 值为{{trim_left(path, '../')}}
trim_left:是内置的nuclei函数
path:是WF-[1]的数据提取器的名字,设置序列之后会自动继承过来
然后设置序列: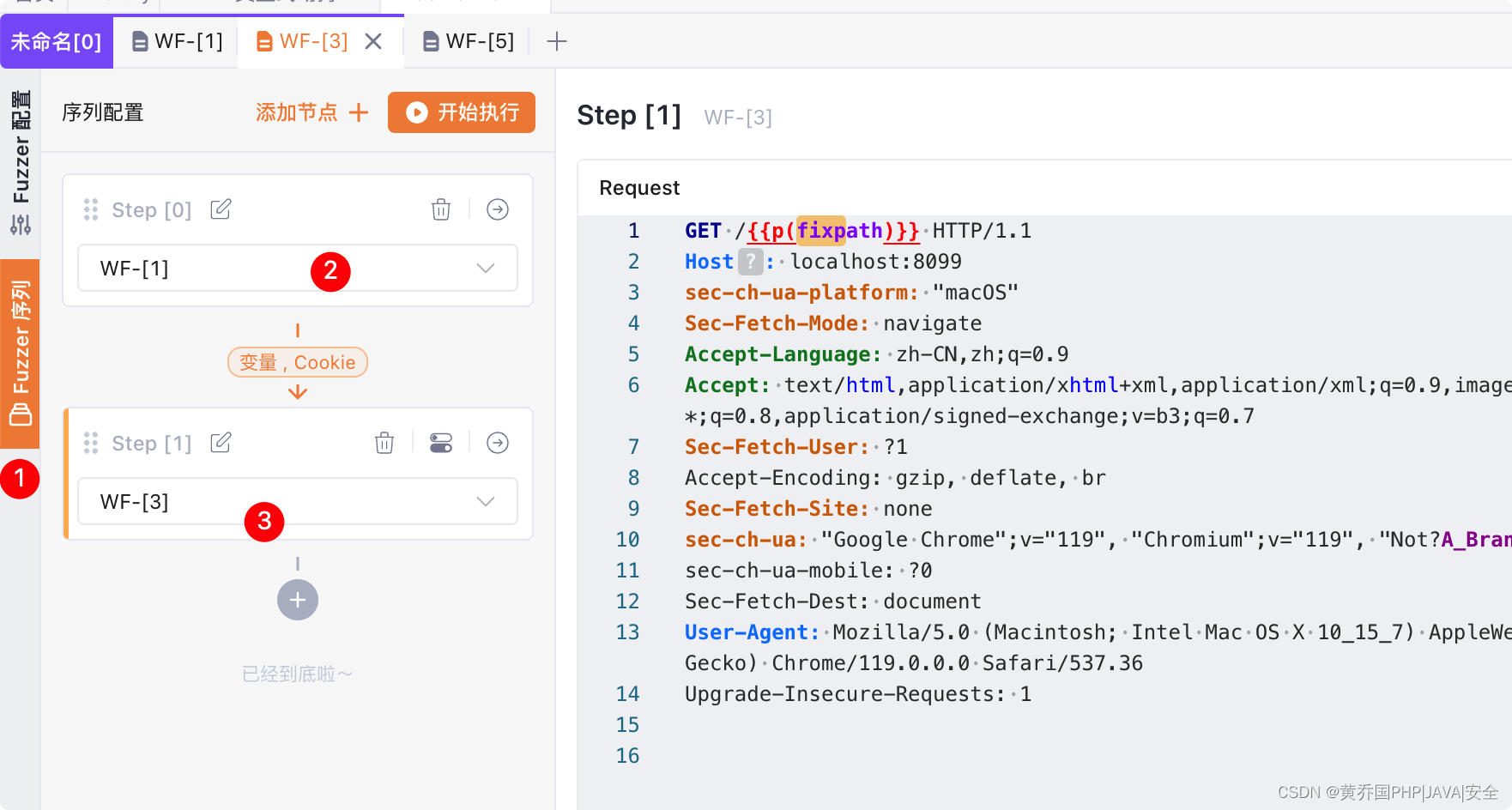
在序列中的WF会默认继承上个WF的cookie和变量: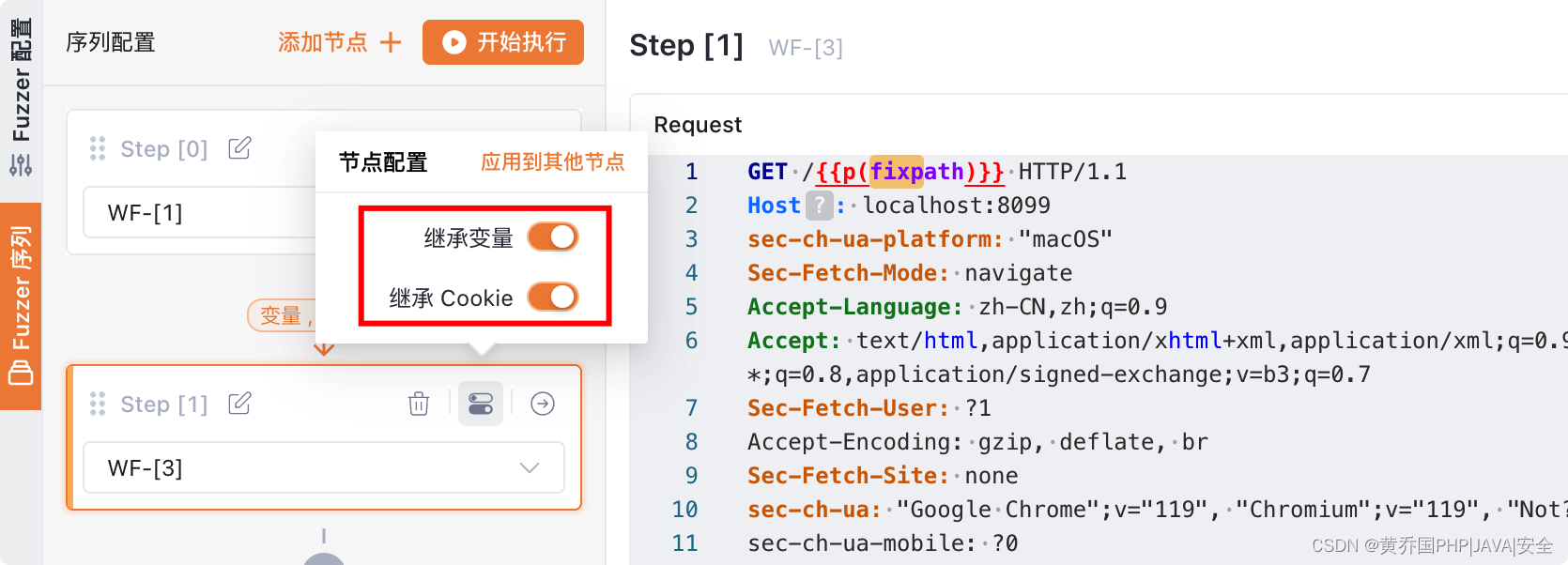
点击开始执行: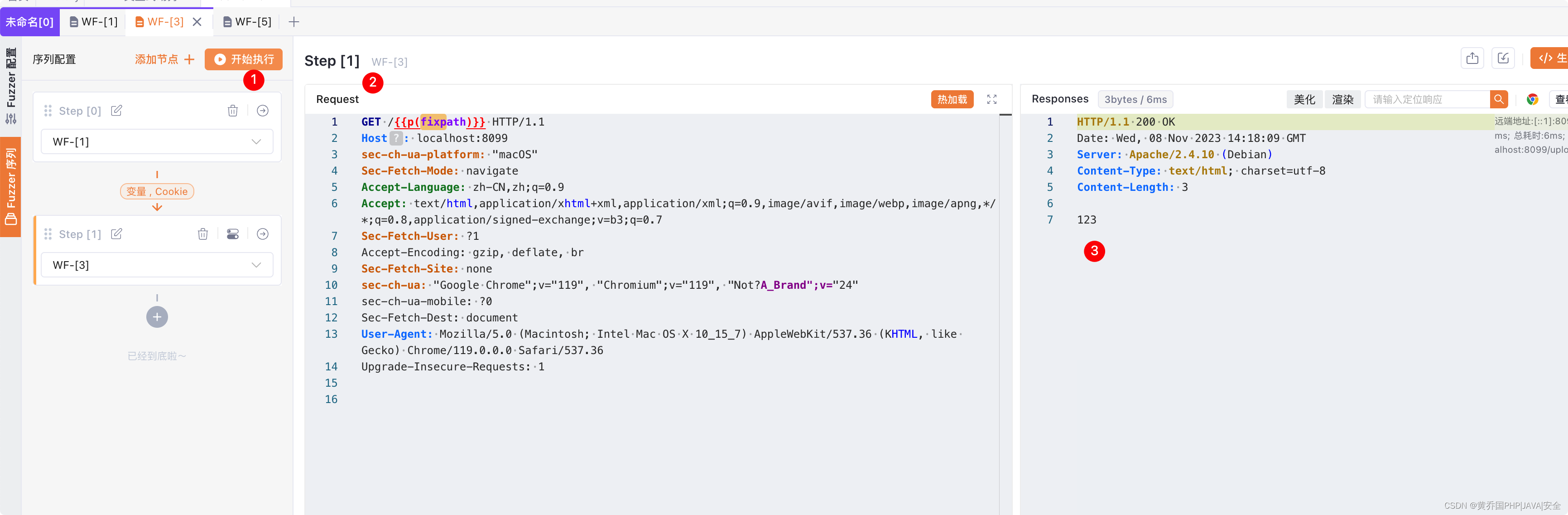
会发现先之下step0再执行step1.
并且最终的结果123也出来了,这个123是shell.php文件中输出的内容。
序列操作就介绍到这里吧,有不清楚的可以看看官方文档
版权归原作者 Miracle_PHP|JAVA|安全 所有, 如有侵权,请联系我们删除。