
前言
近期,除了研究ChatGPT背后的各种技术细节 不断看论文(至少100篇,100篇目录见此:ChatGPT相关技术必读论文100篇),还开始研究一系列开源模型(包括各自对应的模型架构、训练方法、训练数据、本地私有化部署、硬件配置要求、微调等细节)
本文一开始是作为此文《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》的第4部分,但随着研究深入 为避免该文篇幅又过长,将把『第4部分 开源项目』抽取出来 独立成本文,然后不断续写本文直至成了一个系列
毕竟我上半年的目标之一,便是把ChatGPT涉及的所有一切关键技术细节,以及相关的开源项目都研究的透透的,故过程中会不断产出一篇篇新文章出来
第一部分 Colossal-AI、PaLM-rlhf-pytorch、Open-Assistant等
虽说GPT3在2020年就出来了,但OpenAI并未开源,所以直到一年半后以后才有国内外各个团队比如DeepMind等陆续复现出来,这些大厂的复现代码我们自然无法窥知一二,毕竟人家也未开源出来
再到后来基于GPT3的InstructGPT、基于GPT3.5ChatGPT初版(GPT3.5的参数规模也尚无准确定论)、GPT4均未开源,OpenAI不再open,好在Meta等公司或研究者开源出了一系列类ChatGPT项目,本部分针对其中部分做下简要推荐(根据发布顺序排序)
1.1 基于Colossal-AI低成本实现类ChatGPT迷你版的训练过程
2.15,很多朋友在GitHub上发现了一个基于Colossal-AI低成本实现类ChatGPT迷你版训练过程的开源项目(基于OPT + RLHF + PPO),虽是类似GPT3的开源项目OPT与RLHF的结合,但可以增进我们对ChatGPT的理解,该项目有几个不错的特点
- 很多同学一看到DL,便会想到大数据,而数据量一大,还用CPU处理的话很可能训练一个小任务都得半天,而如果用GPU跑,可能一两分钟就出来了。于此,在深度学习大火的那几年,特别是AlphaGo出来的16年起,我司七月在线便分别为VIP、AI系统大课、在职提升大课、求职/论文/申博/留学1V1辅导提供GPU云平台进行实战训练 但如果想训练那种千亿参数规模的开源模型,就不只是有GPU就完事了,比如1750亿参数规模这种得用64张AI 100(即便经过一系列内存开销上的优化,也得至少32张AI 100,单张AI 100售价10万以上,且现在还经常没货),这样的硬件要求是大部分个人是无法具备的,所以该开源项目提供了单GPU、独立4/8-GPUs 的版本
- 如下代码所示,启动简单
from chatgpt.nn import GPTActor, GPTCritic, RewardModelfrom chatgpt.trainer import PPOTrainerfrom chatgpt.trainer.strategies import ColossalAIStrategystrategy = ColossalAIStrategy(stage=3, placement_policy='cuda')with strategy.model_init_context(): actor = GPTActor().cuda() critic = GPTCritic().cuda() initial_model = deepcopy(actor).cuda() reward_model = RewardModel(deepcopy(critic.model)).cuda()trainer = PPOTrainer(strategy, actor, critic, reward_model, initial_model, ...)trainer.fit(prompts) - 训练过程明确清晰,如下图(由于此文已经详细介绍过ChatGPT的训练步骤,故不再赘述)
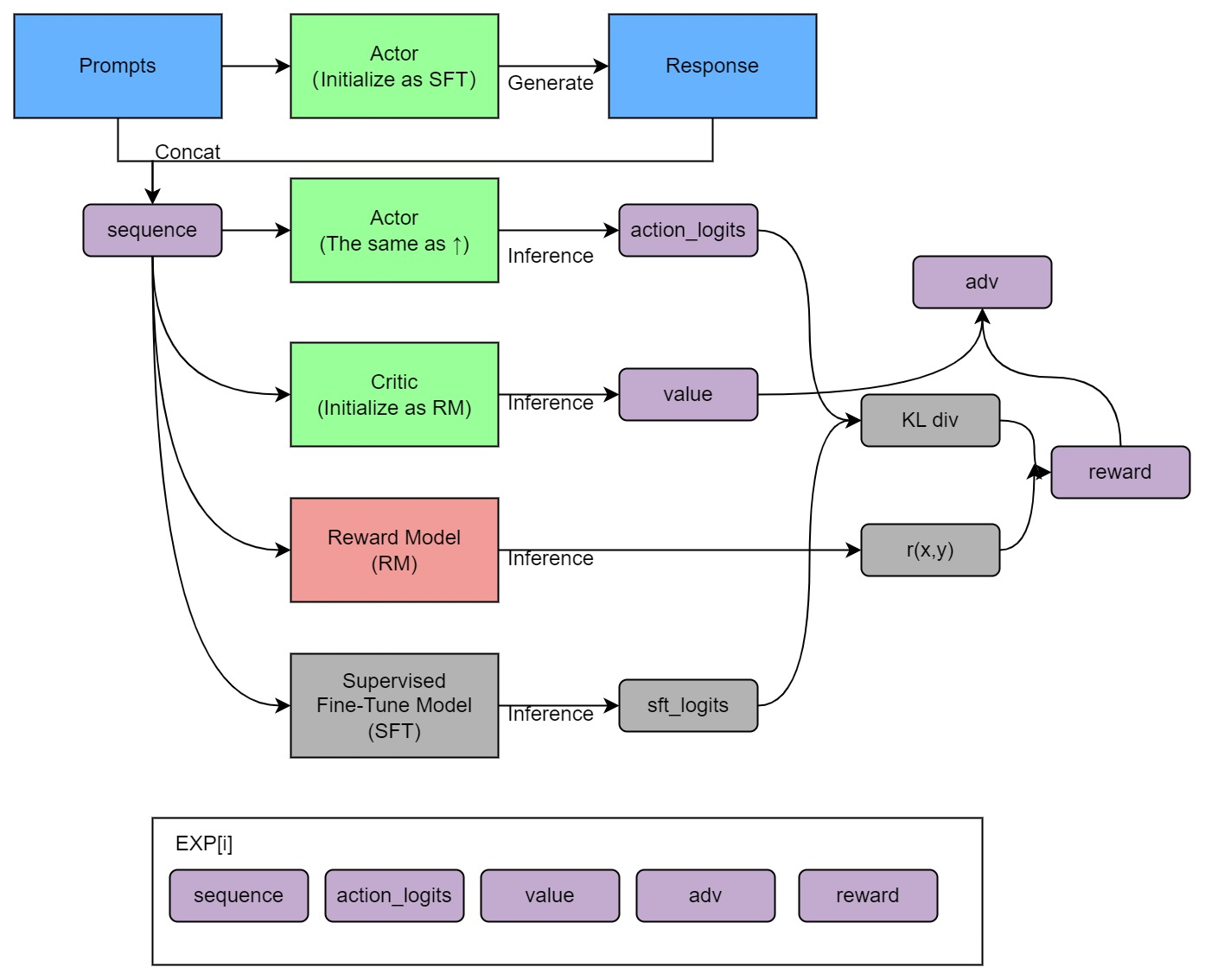 此外,据钟博士在我所维护的『Machine Learning读书会群』里所说,Colossal-AI的并行效率确实不错,是新加坡的一个初创团队推出的,但目前尚没有团队采用Colossal-AI框架来做主训练框架训练175b级别的超大模型,可以再了解下Meta家训练OPT用的Metaseq
此外,据钟博士在我所维护的『Machine Learning读书会群』里所说,Colossal-AI的并行效率确实不错,是新加坡的一个初创团队推出的,但目前尚没有团队采用Colossal-AI框架来做主训练框架训练175b级别的超大模型,可以再了解下Meta家训练OPT用的Metaseq
1.2 TRL包:类似ChatGPT训练阶段三的PPO方式微调语言模型
通过《ChatGPT技术原理解析》一文,我们已经知道了ChatGPT的三阶段训练过程,其中,阶段三的本质其实就是通过PPO的方式去微调LM
GitHub上有个TRL(Transformer Reinforcement Learning,基于『Hugging Face开发的Transformer库』),便是通过PPO的方式去微调LM,需要的数据便是三元组「query, response, reward」,具体如下图所示
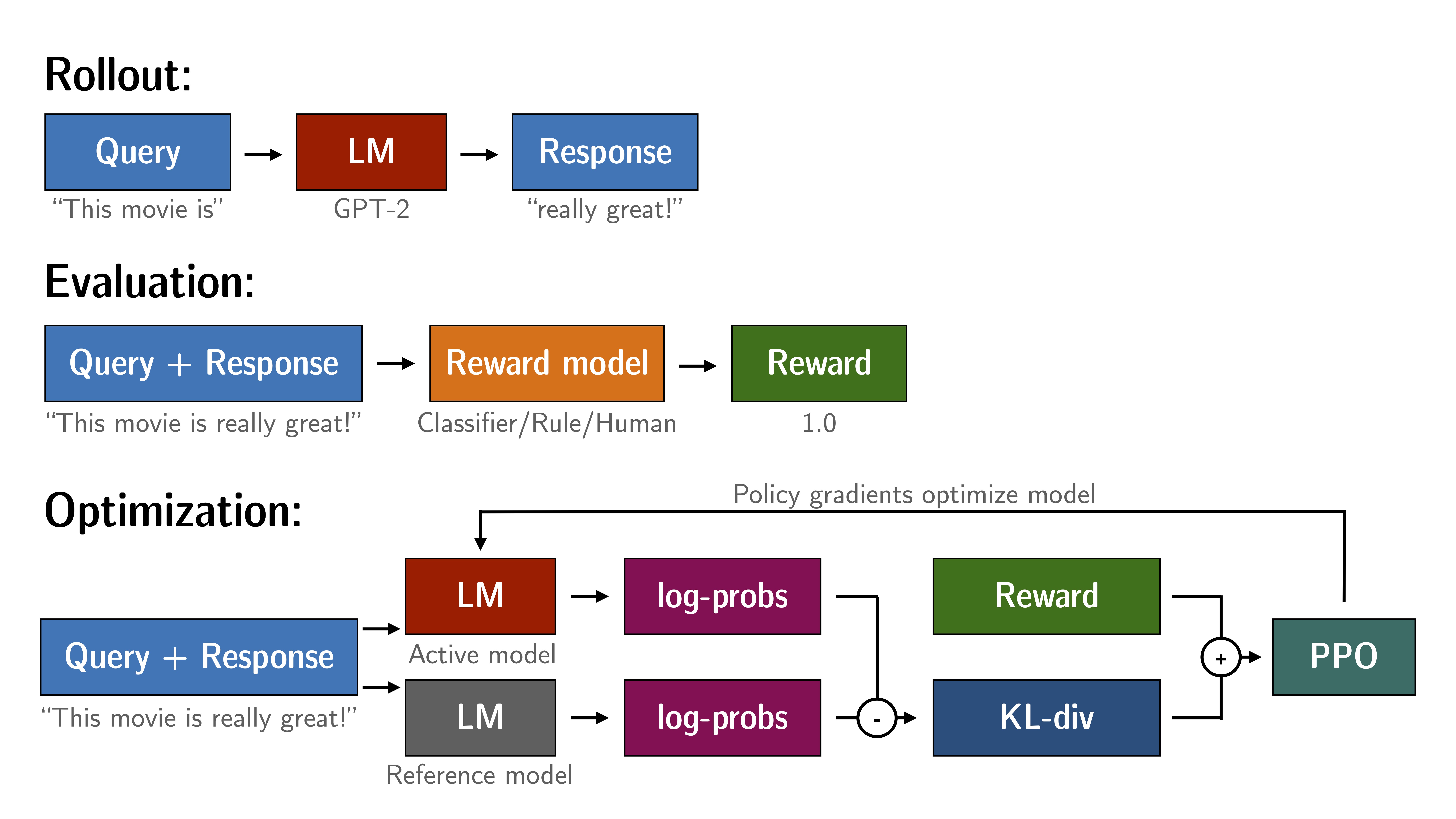
- Rollout:语言模型根据query生成response
- 评估:怎么评估模型针对特定query生成response的质量呢,我们可以使用a function、model、human feedback或它们的某种组合进行评估,然后为每个query/response对产生一个标量值,说白了 就是奖励模型有了,那就直接打分
- 优化:在优化步骤中,「query/response pairs」用于计算序列中标记的对数概率,且比较下面这两个模型输出之间的 KL 散度用作额外的奖励信号
经过训练的模型(即上图中的Active model)
示例代码如下
# imports
import torch
from transformers import AutoTokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
from trl.core import respond_to_batch
# get models
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
model_ref = create_reference_model(model)
tokenizer = AutoTokenizer.from_pretrained('gpt2')
# initialize trainer
ppo_config = PPOConfig(
batch_size=1,
)
# encode a query
query_txt = "This morning I went to the "
query_tensor = tokenizer.encode(query_txt, return_tensors="pt")
# get model response
response_tensor = respond_to_batch(model_ref, query_tensor)
# create a ppo trainer
ppo_trainer = PPOTrainer(ppo_config, model, model_ref, tokenizer)
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0)]
# train model for one step with ppo
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
第二部分 LLaMA的代码级解读:RMSNorm/SwiGLU/RoPE/Transformer
2.1 Meta发布LLaMA((7B 13B 33B 65B):参数少但多数任务的效果好于GPT3
一直致力于LLM模型研究的国外TOP 3大厂除了OpenAI、Google,便是Meta(原来的Facebook)
Meta曾第一个发布了基于LLM的聊天机器人——BlenderBot 3,但输出不够安全,很快下线;再后来,Meta发布一个专门为科学研究设计的模型Galactica,但用户期望过高,发布三天后又下线
23年2.24日,Meta通过论文《LLaMA: Open and Efficient Foundation Language Models》发布了自家的大型语言模型LLaMA(这是解读之一),有多个参数规模的版本(7B 13B 33B 65B)
LLaMA只使用公开的数据(总计1.4T即1,400GB的token,其中CommonCrawl的数据占比67%,C4数据占比15%,Github Wikipedia Books这三项数据均各自占比4.5%,ArXiv占比2.5%,StackExchange占比2%),论文中提到
When training a 65B-parameter model, our code processes around 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM.
This means that training over our dataset containing 1.4T tokens takes approximately 21 days
且试图证明小模型在足够多的的数据上训练后,也能达到甚至超过大模型的效果
- 比如13B参数的版本在多项基准上测试的效果好于2020年的参数规模达175B的GPT-3
- 而对于65B参数的LLaMA,则可与DeepMind的Chinchilla(70B参数)和谷歌的PaLM(540B参数)旗鼓相当
- 且Meta还尝试使用了论文「Scaling Instruction-Finetuned Language Models」中介绍的指令微调方法,由此产生的模型LLaMA-I,在MMLU(Massive Multitask Language Understanding,大型多任务语言理解)上要优于Google的指令微调模型Flan-PaLM-cont(62B)
2.2 代码级解读:LLaMA的模型架构——RMSNorm/SwiGLU/RoPE/Transformer
2.2.1 项目环境依赖:torch、fairscale、fire、sentencepiece
此项目给出的环境依赖有4个:
- torch
- fairscale,fairscale是用来做GPU分布的,一般是当使用DDP仍然遇到超显存的问题时使用fairscale
- fire,fire是一个命令行工具,用或者不用他都可以
- sentencepiece,sentencepiece是用于tokenizer的工具包
from sentencepiece import SentencePieceProcessorfrom logging import getLoggerfrom typing import Listimport oslogger = getLogger()class Tokenizer: def __init__(self, model_path: str): # reload tokenizer assert os.path.isfile(model_path), model_path self.sp_model = SentencePieceProcessor(model_file=model_path) logger.info(f"Reloaded SentencePiece model from {model_path}") # BOS / EOS token IDs self.n_words: int = self.sp_model.vocab_size() self.bos_id: int = self.sp_model.bos_id() self.eos_id: int = self.sp_model.eos_id() self.pad_id: int = self.sp_model.pad_id() logger.info( f"#words: {self.n_words} - BOS ID: {self.bos_id} - EOS ID: {self.eos_id}" ) assert self.sp_model.vocab_size() == self.sp_model.get_piece_size() def encode(self, s: str, bos: bool, eos: bool) -> List[int]: assert type(s) is str t = self.sp_model.encode(s) if bos: t = [self.bos_id] + t if eos: t = t + [self.eos_id] return t def decode(self, t: List[int]) -> str: return self.sp_model.decode(t)
2.2.2 RMSNorm:对每个Transformer子层的输入进行归一化
为了提高训练的稳定性,对每个transformer子层的输入进行归一化,而不是对输出进行归一化,且使用由Zhang和Sennrich(2019)提出的RMSNorm(Root Mean Square Layer Normalization)
RMS Norm是一般LayerNorm的一种变体,可以在梯度下降时令损失更加平滑
与layerNorm相比,RMS Norm的主要区别在于去掉了减去均值的部分(re-centering),只保留方差部分(re-scaling)
为一目了然,我们看下它们各自的归一化的表达式
- 一般的LN:
其中
- RMS Norm:
其中
至于RMS Norm为什么有用,需要求梯度进行分析,感兴趣的同学可以阅读RMS Norm的论文
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
// eps防止取倒数之后分母为0
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
// x是输入
def _norm(self, x):
// torch.rsqrt是开平方并取倒数
// x.pow(2)是平方
/ mean(-1)是在最后一个维度(即hidden特征维度)上取平均
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
// weight是末尾乘的可训练参数,即gi
return output * self.weight
2.2.3 SwiGLU替代ReLU
用Shazeer(2020)提出的SwiGLU替代ReLU,在维度上使用的维度是2/3*4d,而不是PaLM中的4d
LLaMA采用SwiGLU替换了原有的ReLU,具体是采用SwiGLU的FNN,在论文中以如下公式进行表述:
其中
对应论文见:Ramachandran et al., 2017
代码实现上:可以通过调用torch内置方法F.silu()实现,会在下文的FFN部分介绍
2.2.4 位置编码:旋转位置嵌入(RoPE)
在位置编码上,删除了绝对位置嵌入,而在网络的每一层增加了苏剑林等人(2021)提出的旋转位置嵌入(RoPE),其思想是采用绝对位置编码的形式,实现相对位置编码
- RoPE主要借助了复数的思想,为了引入复数,首先假设了在加入位置信息之前,原有的编码向量是二维行向量
和
,其中
和
是绝对位置,现在需要构造一个变换,将
考虑到Attention的核心计算是内积:
所以,寻求的这个
变换,应该具有特性:
- 这里直接说结论,寻求的变换就是
,也就是给
,相应地,
做了这样一个变换之后,根据复数的特性,有:
也就是,如果把二维向量看做复数,那么它们的内积,等于一个复数乘以另一个复数的共轭,得到的结果再取实部,代入上面的变换,也就有:
这样一来,内积的结果就只依赖于
,也就是相对位置了 换言之,经过这样一番操作,通过给Embedding添加绝对位置信息,可以使得两个token的编码,经过内积变换(self-attn)之后,得到结果是受它们位置的差值,即相对位置影响的
- 于是对于任意的位置为
,把它看做复数,乘以
于是上述的相乘变换也就变成了:
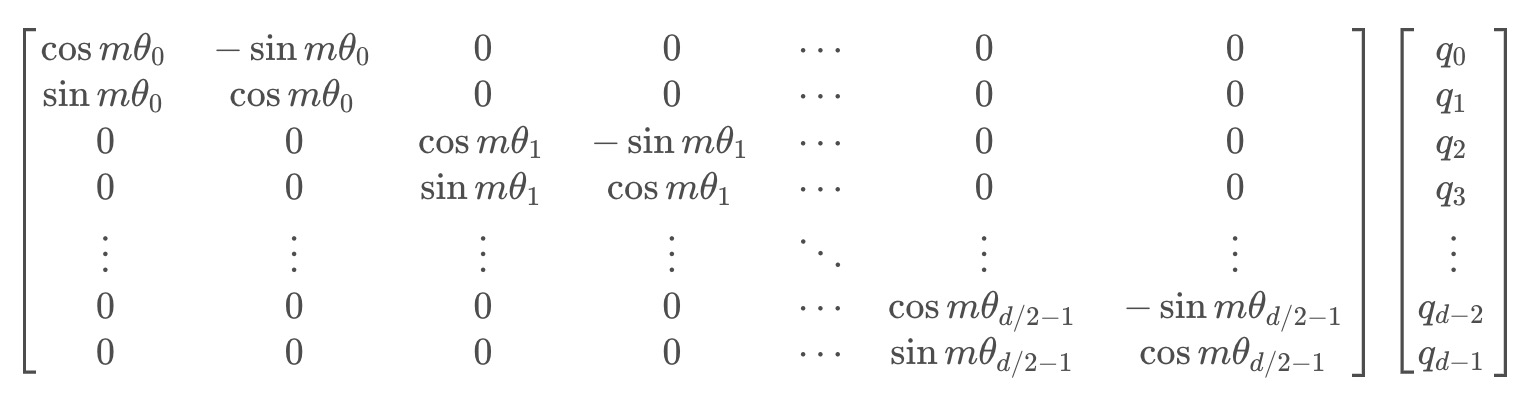
把上述式子写成矩阵形式:
 而这个变换的几何意义,就是在二维坐标系下,对向量
而这个变换的几何意义,就是在二维坐标系下,对向量进行了旋转,因而这种位置编码方法,被称为旋转位置编码
- 根据刚才的结论,结合内积的线性叠加性,可以将结论推广到高维的情形。可以理解为,每两个维度一组,进行了上述的“旋转”操作,然后再拼接在一起:
 由于矩阵的稀疏性,会造成计算上的浪费,所以在计算时采用逐位相乘再相加的方式进行:
由于矩阵的稀疏性,会造成计算上的浪费,所以在计算时采用逐位相乘再相加的方式进行: 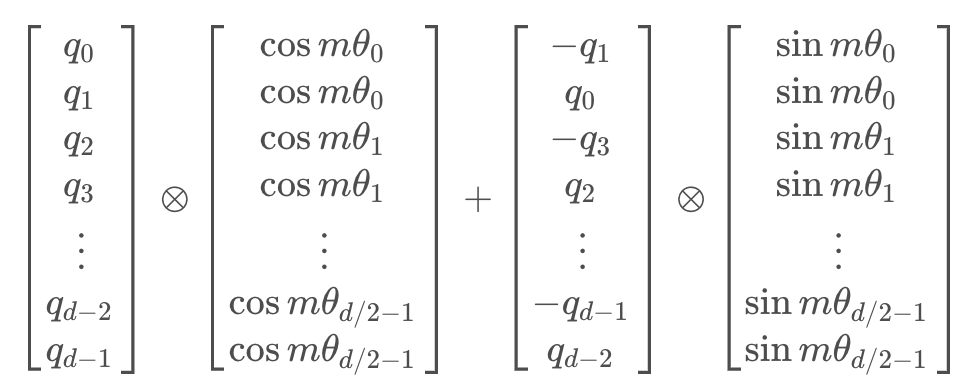 其中
其中为矩阵逐位相乘操作
原理理解了,接下来可以代码实现旋转位置编码
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
// 首先torch.arange创建了一个tensor,[ 0 , 2 , 4 , . . . , 60 , 62 ] [0, 2, 4, ..., 60, 62][0,2,4,...,60,62]
// 然后统一除以64,把它变成分数,然后整体作为基础角度的指数,它的shape是(32)
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
// t比较容易理解,也就是绝对位置信息,它的shape是(1024)
t = torch.arange(end, device=freqs.device)
// torch.outer是把一个向量的转置乘以另一个向量:torch.outer(a, b) = a^T * b
// 于是根据torch.outer运算,我们得到了一个shape为(1024, 32)的tensor。其意义也就是将每一个绝对位置,分配到对应的角度,相乘
// 直观理解一下,就是每一个绝对位置上,都有32个角度
// 为什么是这样的呢,回顾计算的公式,对于旋转矩阵,每两个元素为一组,它们乘以的角度是同一个θ,所以这个(1024, 32)
// 在后续的过程中,就可以reshape成(512, 64),并且在64的那个维度上,每两个是相同的
freqs = torch.outer(t, freqs).float()
// torch.polar(abs, angle)利用一个绝对数值和一个角度值,从而在极坐标下构造一个复数张量
// 即abs∗cos(angle)+abs∗sin(angle)j
// torch.polar(torch.tensor([1], dtype=torch.float64), torch.tensor([np.pi / 2], dtype=torch.float64))
// # tensor([6.1232e-17+1.j], dtype=torch.complex128)
// freqs_cis其实就是需要计算出来的mθ,也就是跟绝对位置相关的旋转的角度,在极坐标下对应的复数tensor
// 这一步就是在生成我们需要的位置信息
// 直观理解一下,像是在复平面内,以原点为中心,转了1024组,每一组64个的单位向量,它的shape是(1024, 64)
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64
return freqs_cis
// 第二个函数reshape_for_broadcast,是把freqs_cis变成和输入的tensor相同的形状
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
ndim = x.ndim
assert 0 <= 1 < ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
// 这个方法的作用是为了把freqs_cis变成和输入的tensor相同的形状
// 需要注意的是,这里的freqs_cis并不是precompute_freqs_cis生成的形状为(1024, 64)的那个tensor
// 而是根据输入的绝对位置,在(1024, 64)的tensor中,截取了长度为当前seq_len的一部分
// 代码在Transformer类的forward方法中freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
// 也就是说,假如当前输入的序列长度是512,那么截取出来的这个新的freqs_cis,形状就是(512, 64)
// reshape之后,形状就变成了(1, 512, 1, 32),也就是在每一个位置上,都对应有32个角度
// 根据上面torch.polar的介绍,当我们固定绝对值(也就是向量的模长)时,角度就可以在笛卡尔坐标系下唯一确定一个复数
// 这样一来也就是32个复数,即64个特征维度,所以就可以对应的将它融合到每个attention head的64个特征中去了
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(*shape)
// apply_rotary_emb方法,这个方法其实就是把位置信息添加到原有的编码结果上,在multi-head attention阶段调用
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
// torch.view_as_complex是把一个tensor转为复数形式
// 比如torch.view_as_complex(torch.Tensor([[1, 2], [3, 4], [5, 6]]))
// # tensor([1.+2.j, 3.+4.j, 5.+6.j])
// 假设输入x_q的尺寸就是(2, 512, 12, 64)
// 那么这一句操作的reshape,就是把它变成(2, 512, 12, -1, 2),也就是(2, 512, 12, 32, 2)。x_k同理,略
// 紧接着把它变成复数形式,也就是变成了(2, 512, 12, 32)的形状。
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
// 然后进入到上面的第二个函数reshape_for_broadcast
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
// torch.view_as_real是把复数tensor变回实数
// torch.view_as_real(torch.view_as_complex(torch.Tensor([[1, 2], [3, 4], [5, 6]])))
// # tensor([[1., 2.],
// # [3., 4.],
// # [5., 6.]])
// reshape之后,就是将位置信息融入query和key中
// 这一步将二者相乘得到的复数tensor,重新转换为实数形式,得到的shape为(2, 512, 12, 32, 2)
// 然后再flatten成(2, 512, 12, 64),这样一来,就变回了和最开始x_q相同的形状,也就完成了将位置信息融入到x_q的这一操作,x_k同理
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
引用此文的介绍,再着重解释下precompute_freqs_cis的作用
- 假设 batch_size为2 seq_len固定为512 attention_head的数量为12 每个attention_head的维度为64,那么,对于输入到multi-head attn中的输入
的尺寸就是 (2, 512, 12, 64)
- 而freqs_cis其实就是需要计算出来的
也就是跟绝对位置相关的旋转的角度,在极坐标下对应的复数tensor
而precompute_freqs_cis就是提前将这些旋转角度对应的tensor给创建出来,并可以重复利用。因为确定了序列的最大长度,所以这个tensor是固定死的。根据后续的数据流我们可以发现,在调用该函数时,传入的两个参数分别是attention_head的维度,以及最大长度的两倍,具象地,也就是64和1024
2.2.4 Transform架构的实现:Attention计算、SA、FFN
LLaMA和GPT一样,都是基于Transformer这个架构,通常,我们在构建transformer时,是按Block构建的,每个transformer Block包含SA和FFN两部分,然后再通过堆叠block的形式,构建起整个transformer网络,LLaMA也是这样做的
回顾一下Attention计算的总体过程是:
- 输入
,分别经过三个Linear得到
- 在
中加入旋转位置编码
- 缓存
- 计算
其中有一个细节就是缓存机制,它设计的目的是在generate时减少token的重复计算。简单解释一下,就是在计算第n个token特征的时候,需要用到第个token,即每次生成时,需要知道前面所有的过往信息,如果每次都从头算的话,那就会造成极大的浪费,所以就没算一个位置的信息,就把它缓存下来
接下来,我们来看下代码实现,首先是SA部分:
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_local_heads = args.n_heads // fs_init.get_model_parallel_world_size()
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
self.cache_k = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
self.cache_v = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
xq = xq.transpose(1, 2)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, slen, cache_len + slen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, slen, head_dim)
output = output.transpose(
1, 2
).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
然后是FFN部分,需要注意的点就是采用的激活函数,以及激活函数的位置
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
):
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
)
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
这里与常见模型中的FFN做一下简单的对比
- BART中的FFN,用的是fc->act->fc,用了两层全连接
- GPT中的FFN,用的是conv1D->act->conv1D,也是只用了两层
- 而LLaMA中的FFN采用了三个全连接层以实现FFNSwiGLU,即
然后将SA和FFN这两部分拼在一起就是一个transformer block
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim, hidden_dim=4 * args.dim, multiple_of=args.multiple_of
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
最后利用torch的module list将transformer block进行堆叠,拼上最前头的embedding部分,就是一个完整的transformer decoder结构了
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
self.freqs_cis = precompute_freqs_cis(
self.params.dim // self.params.n_heads, self.params.max_seq_len * 2
)
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape
// 输入是token,先做token embedding,然后添加位置信息
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
// 对于decoder模型,为了防止标签泄漏,需要mask,所以做了一个上三角的mask矩阵
mask = None
if seqlen > 1:
mask = torch.full((1, 1, seqlen, seqlen), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=start_pos + 1).type_as(h)
// 接下来就是逐层的计算transformer
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h[:, -1, :]) # only compute last logits
return output.float()
接着看下生成过程,如下:
- 对prompts进行tokenize,得到token ids;
- 计算当前batch的最大长度total_len,用来创建输入的token tensor,最大长度不能超过前文所述缓存的大小;
- 从当前batch中,最短的一个prompt的位置,作为生成的开始位置,开始生成;
- 输入的token tensor传入transformer模型,计算logits,得到形状为(batch_size, hidden_size)的logits(transformer最后一层的输出);
- softmax+top_p采样,得到当前预测的token,并更新当前位置,准备预测下一个token;
- 解码得到生成的文本
代码如下
class LLaMA:
def __init__(self, model: Transformer, tokenizer: Tokenizer):
self.model = model
self.tokenizer = tokenizer
def generate(
self,
prompts: List[str],
max_gen_len: int,
temperature: float = 0.8,
top_p: float = 0.95,
) -> List[str]:
bsz = len(prompts)
params = self.model.params
assert bsz <= params.max_batch_size, (bsz, params.max_batch_size)
prompt_tokens = [self.tokenizer.encode(x, bos=True, eos=False) for x in prompts]
min_prompt_size = min([len(t) for t in prompt_tokens])
max_prompt_size = max([len(t) for t in prompt_tokens])
total_len = min(params.max_seq_len, max_gen_len + max_prompt_size)
tokens = torch.full((bsz, total_len), self.tokenizer.pad_id).cuda().long()
for k, t in enumerate(prompt_tokens):
tokens[k, : len(t)] = torch.tensor(t).long()
input_text_mask = tokens != self.tokenizer.pad_id
start_pos = min_prompt_size
prev_pos = 0
for cur_pos in range(start_pos, total_len):
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
if temperature > 0:
probs = torch.softmax(logits / temperature, dim=-1)
next_token = sample_top_p(probs, top_p)
else:
next_token = torch.argmax(logits, dim=-1)
next_token = next_token.reshape(-1)
# only replace token if prompt has already been generated
next_token = torch.where(
input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token
)
tokens[:, cur_pos] = next_token
prev_pos = cur_pos
decoded = []
for i, t in enumerate(tokens.tolist()):
# cut to max gen len
t = t[: len(prompt_tokens[i]) + max_gen_len]
# cut to eos tok if any
try:
t = t[: t.index(self.tokenizer.eos_id)]
except ValueError:
pass
decoded.append(self.tokenizer.decode(t))
return decoded
def sample_top_p(probs, p):
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
next_token = torch.multinomial(probs_sort, num_samples=1)
next_token = torch.gather(probs_idx, -1, next_token)
return next_token
2.3 LLaMA的Optimizer设计、模型加速优化与微型版本
在Optimizer设计上
- 该模型使用AdamW优化器(Loshchilov和Hutter,2017)进行训练,超参数设置为β1=0.9,β2=0.95 此外,使用余弦学习率方式,使最终学习率等于最大学习率的10%,以及使用0.1的权重衰减和1.0的梯度剪裁,和2000个warm up策略,使得可以根据模型的大小改变学习率和批次大小
在模型的加速优化方面
- 首先,使用一个高效的因果多头注意力方式的实现,灵感来自Rabe和Staats(2021)以及Dao等人(2022),这个实现可在xformers库中找到,可以有效减少内存的使用和计算 具体原理为通过不存储注意力权重和不计算由于语言建模任务的因果性质而被掩盖的键/查询分数来实现的
- 其次,为了进一步提高训练效率,减少了在check point的后向传递中重新计算的激活量,在实现上,通过手动实现trasnformer层的后向函数来进行操作 为了充分受益于这种优化,还通过如Korthikanti等人(2022)中采用的方法,进行使用模型和序列并行来减少模型的内存使用
- 最后,该工作还尽可能地重叠激活的计算和GPU之间在网络上的通信 最终的优化性能效果为:当训练一个65B参数的模型时,代码在2048A100的GPU上处理大约380个token/秒/GPU,并耗费80GB的内存,这意味着对包含1.4Ttoken的数据集进行训练大约花费了21天
LLaMA发布不久后,一些研究者基于它做了不少工作
- 一开始最小参数7B的模型也需要近30GB的GPU才能运行,但通过比特和字节库进行浮点优化,能够让模型在单个NVIDIA RTX 3060(显存一般12G)上运行
- 之后,GitHub 上的一名研究人员甚至能够在Ryzen 7900X CPU上运行LLM的7B 版本,每秒能推断出几个单词
- 再之后,有研究者推出了llama.cpp,无需 GPU,就能运行 LLaMA llama.cpp 项目实现了在MacBook上运行 LLaMA,还有开发者成功的在 4GB RAM 的树莓派上运行了 LLaMA 7B
第三部分 各种微调LLaMA:Alpaca(self-instruct)、Vicuna(shareGPT)、BELLE(self-instruct)
3.1 Stanford Alpaca:结合英文语料通过Self Instruct方式微调LLaMA 7B
3.1.1 什么是self-instruct方式:提示GPT3/GPT3.5/GPT4的API收集数据
3月中旬,斯坦福发布Alpaca(中文名:羊驼):号称只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型(即LLaMA 7B),具体做法是通过52k指令数据,然后在8个80GB A100上训练3个小时,使得Alpaca版的LLaMA 7B在单纯对话上的性能比肩GPT-3.5(text-davinci-003),这便是指令调优LLaMA的意义所在
- 论文《Alpaca: A Strong Open-Source Instruction-Following Model》
- 代码地址:https://github.com/tatsu-lab/stanford_alpaca
可能有读者有疑问,即52k数据都长啥样呢?这52K数据存在Alpaca项目的alpaca_data.json文件中,这个JSON文件是一个字典列表,每个字典包含以下字段:
- instruction: str,描述了模型应该执行的任务,52K 条指令中的每一条都是唯一的
- input: str,要么是上下文,要么直接输入(optional context or input for the task),例如,当指令是“总结以下文章”时,输入就是文章,大约 40% 的示例有输入
- output: str,由GPT3.5对应的API即 text-davinci-003生成的指令的答案
而斯坦福团队微调LLaMA 7B所用的52K指令数据,便是通过Self-Instruct『Self-Instruct是来自华盛顿大学Yizhong Wang等22年12月通过这篇论文《SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions》提出的』提示GPT3的API拿到的
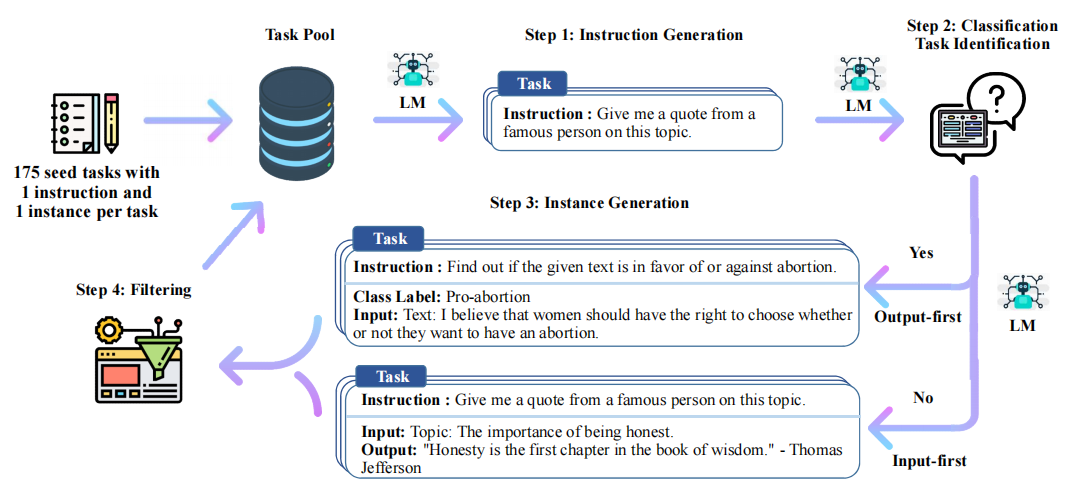
具体而言,论文中提出
- 人工设计175个任务,每个任务都有对应的{指令 输入 输出/实例}或{指令 输出/实例},将这175个任务数据作为种子集
- 然后提示模型比如GPT3对应的API即 text-davinci-001 (原论文中没用text-davinci-003,because their newer engines are trained with the latest user data and are likely to already see the SUPERNI evaluation set,但实际应用时比如斯坦福Alpaca指定的GPT3.5的API即 text-davinci-003生成指令,包括很快你将看到,23年4月还有微软的研究者指定GPT4的API生成指令),使用种子集作为上下文示例来生成更多新的指令
- 对该模型生成的指令判断是否分类任务
- 使用模型生成实例
- 对上述模型生成的数据{指令 输入 输出/实例}过滤掉低质量或相似度高的
- 将经过过滤和后处理的数据添加到种子池中 一直重复上述2-6步直到种子池有足够多的数据 关键代码如下:
def openai_completion( prompts: Union[str, Sequence[str], Sequence[dict[str, str]], dict[str, str]], decoding_args: OpenAIDecodingArguments, model_name="text-davinci-003", sleep_time=2, batch_size=1, max_instances=sys.maxsize, max_batches=sys.maxsize, return_text=False, **decoding_kwargs,) -> Union[Union[StrOrOpenAIObject], Sequence[StrOrOpenAIObject], Sequence[Sequence[StrOrOpenAIObject]],]: """ prompts:输入提示,可以是单个字符串、字符串列表、字典或字典列表 decoding_args:解码参数,用于指定如何生成文本 model_name:要使用的模型名称,默认为"text-davinci-003" sleep_time:在达到速率限制时,程序暂停的时间(以秒为单位) batch_size:在单个请求中发送的prompts的数量 max_instances:要解码的prompts的最大数量 max_batches:要解码的批次的最大数量(此参数将在未来被弃用) return_text:如果为True,则返回文本而不是包含诸如logprob等信息的完整completion对象 decoding_kwargs:其他解码参数,例如best_of和logit_bias """ # 函数首先检查是否有单个prompt,如果是,则将其转换为列表 # 然后,根据最大实例数量截取prompts。接着,将prompts分成批次以便进行批处理 is_single_prompt = isinstance(prompts, (str, dict)) if is_single_prompt: prompts = [prompts] if max_batches < sys.maxsize: logging.warning( "`max_batches` will be deprecated in the future, please use `max_instances` instead." "Setting `max_instances` to `max_batches * batch_size` for now." ) max_instances = max_batches * batch_size prompts = prompts[:max_instances] num_prompts = len(prompts) prompt_batches = [ prompts[batch_id * batch_size : (batch_id + 1) * batch_size] for batch_id in range(int(math.ceil(num_prompts / batch_size))) ] ''' 函数遍历这些批次,并尝试与OpenAI API进行交互。当遇到OpenAIError时,会根据错误类型采取不同的措施 如果是因为速率限制,程序将暂停一段时间再重试。如果提示过长,程序将减小目标长度再重试。 ''' completions = [] for batch_id, prompt_batch in tqdm.tqdm( enumerate(prompt_batches), desc="prompt_batches", total=len(prompt_batches), ): batch_decoding_args = copy.deepcopy(decoding_args) # cloning the decoding_args while True: try: shared_kwargs = dict( model=model_name, **batch_decoding_args.__dict__, **decoding_kwargs, ) completion_batch = openai.Completion.create(prompt=prompt_batch, **shared_kwargs) choices = completion_batch.choices for choice in choices: choice["total_tokens"] = completion_batch.usage.total_tokens completions.extend(choices) break except openai.error.OpenAIError as e: logging.warning(f"OpenAIError: {e}.") if "Please reduce your prompt" in str(e): batch_decoding_args.max_tokens = int(batch_decoding_args.max_tokens * 0.8) logging.warning(f"Reducing target length to {batch_decoding_args.max_tokens}, Retrying...") else: logging.warning("Hit request rate limit; retrying...") time.sleep(sleep_time) # Annoying rate limit on requests. # 最后,函数根据return_text、decoding_args.n以及是否为单个prompt的情况返回不同类型的结果 if return_text: completions = [completion.text for completion in completions] if decoding_args.n > 1: # make completions a nested list, where each entry is a consecutive decoding_args.n of original entries. completions = [completions[i : i + decoding_args.n] for i in range(0, len(completions), decoding_args.n)] if is_single_prompt: # Return non-tuple if only 1 input and 1 generation. (completions,) = completions return completions
而斯坦福的Alpaca,就是花了不到500美元使用OpenAI API生成了5.2万个这样的示例微调LLaMA搞出来的,个人觉得可以取名为 instructLLaMA-7B,^_^
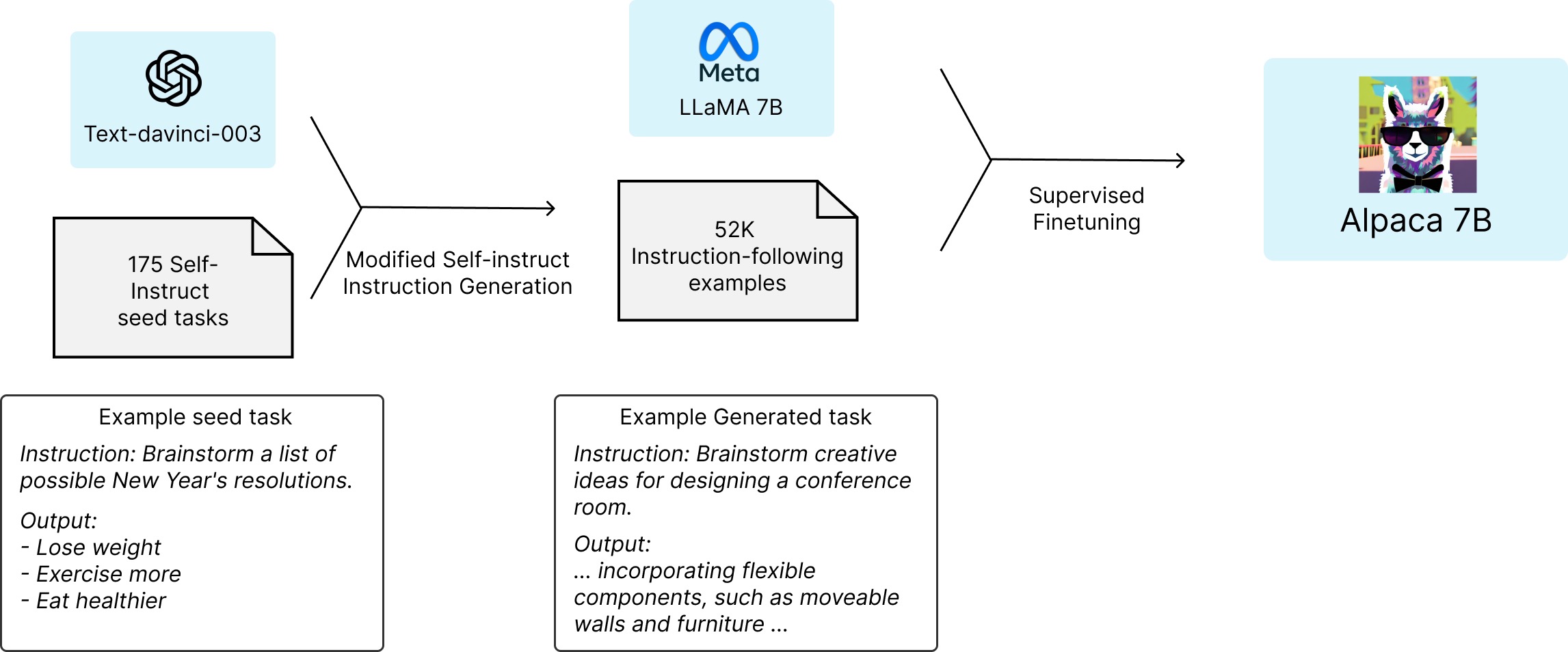
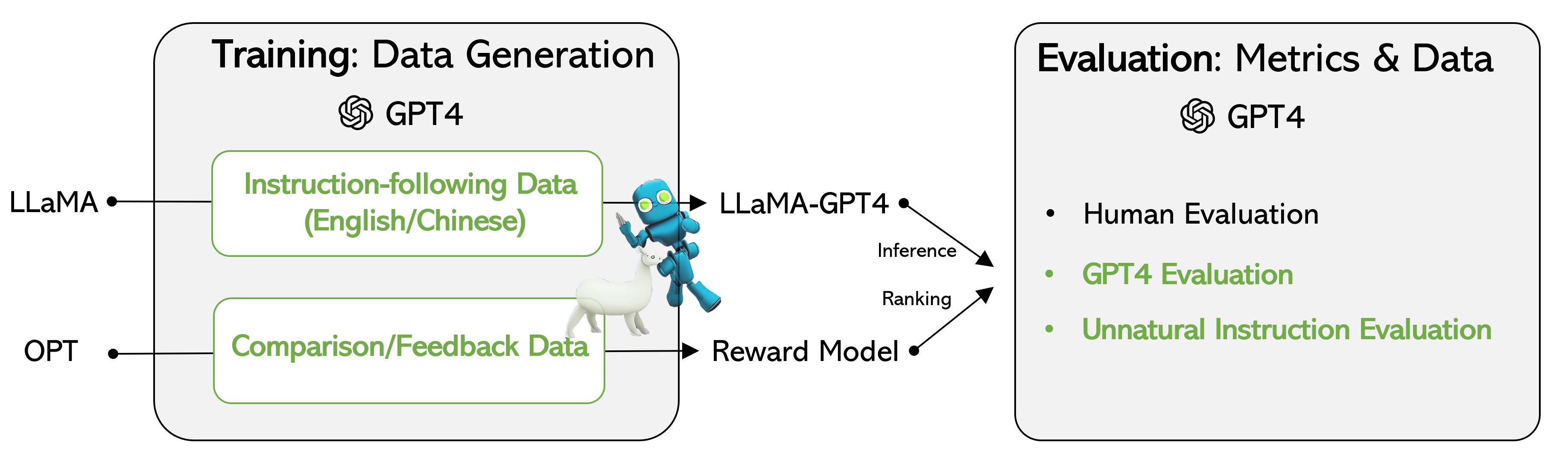
值得一提的是,后来23年4月有微软的研究者提示GPT4的API进行指令微调「论文地址:INSTRUCTION TUNING WITH GPT-4、GitHub地址:instruction-Tuning-with-GPT-4、项目地址:使用GPT4进行指令调优」,从而生成以下数据
- English Instruction-Following Data,generated by GPT-4 using Alpaca prompts 这部分数据在项目文件 *alpaca_gpt4_data.json *里,contains 52K instruction-following data generated by GPT-4 with prompts in Alpaca. This JSON file has the same format as Alpaca data, except the output is generated by GPT-4: instruction: str, describes the task the model should perform. Each of the 52K instructions is unique. input: str, optional context or input for the task. output: str, the answer to the instruction as generated by GPT-4.
- Chinese Instruction-Following Data,即上面英文数据的中文翻译,存储在项目文件alpaca_gpt4_data_zh.json 里
- Comparison Data ranked by GPT-4,好训练一个奖励模型 存储在 *comparision_data.json *文件里,ranked responses from three models, including GPT-4, GPT-3.5 and OPT-IML by asking GPT-4 to rate the quality. user_input: str, prompts used for quering LLMs. completion_a: str, a model completion which is ranked higher than completion_b. completion_b: str, a different model completion which has a lower quality score.
- Answers on Unnatural Instructions Data,该数据用于大规模量化 GPT-4 与我们的指令调整模型(即LLaMA by instruction tuning with GPT4)之间的差距,而缩小与GPT4的差距便是本次指令调优的目标
3.1.2 微调LLM时一般都会用到Hugging face实现的Transformers库的Trainer类
可能有读者疑问,那微调的代码长啥样呢?实际上,微调步骤大同小异,据代码:tatsu-lab/stanford_alpaca · GitHub,可得微调的步骤如下
- 导入所需的库:包括
torch,transformers等。 - 定义一些全局变量,如特殊字符、提示模板等。
- 定义用于处理模型、数据和训练参数的数据类。
- 定义辅助函数,如: -
safe_save_model_for_hf_trainer:安全地保存训练器中的模型;-smart_tokenizer_and_embedding_resize:调整分词器和词嵌入大小;-_tokenize_fn:将字符串序列进行分词;-preprocess:预处理数据,对源数据和目标数据进行分词。 - 定义
SupervisedDataset类,用于加载数据、格式化输入、进行分词等操作。 - 定义
DataCollatorForSupervisedDataset类,用于将数据集的实例整理为批次。 - 定义
make_supervised_data_module函数,用于创建监督学习任务的数据集和整理器。 - 定义
train函数,用于执行以下操作: a. 解析命令行参数:使用transformers.HfArgumentParser解析命令行参数,将它们分为模型参数、数据参数和训练参数 b. 加载预训练模型:使用transformers.AutoModelForCausalLM.from_pretrained从预训练的模型检查点加载一个用于因果语言建模的模型 c. 加载分词器:使用transformers.AutoTokenizer.from_pretrained从预训练的模型检查点加载分词器 d. 为分词器添加特殊字符:根据需要,将特殊字符添加到分词器中 e. 创建数据集和整理器:使用make_supervised_data_module函数为监督学习任务创建数据集和整理器 f. 实例化Trainer类:实例化transformers.Trainer类,并传入模型、分词器、训练参数以及数据集。Trainer类负责管理训练过程 g. 训练模型:调用Trainer类的train()方法对模型进行微调,相当于链路就是:transformers库Trainer.save_state()方法保存模型的状态 i. 将训练器的模型安全地保存到磁盘:使用safe_save_model_for_hf_trainer函数将训练器中的模型安全地保存到磁盘 - 如果这个脚本是主程序,则调用
train函数以开始训练过程
可能,很快便有同学疑问,怎么没有预想中的损失计算、梯度下降、参数更新呢,实际上这三步的具体实现都封装在了Hugging face社区实现的鼎鼎大名的transformers的Trainer类中:transformers/trainer.py at main · huggingface/transformers · GitHub
这个 *transformers/trainer.py *文件的主要部分如下
 导入:文件首先导入了一些必要的Python库,如os、sys、logging以及其他一些库。它还导入了Hugging Face库中的一些相关模块,如datasets、transformers等
 TrainerState:这个类用于保存训练器的状态,包括当前的epoch、迭代步数、最佳指标值等
 TrainOutput:这个类用于返回训练过程的结果,包括训练损失、训练步数等
 TrainerControl:这个类提供了一种用于控制训练循环的机制,例如,当用户想要在某个特定的迭代步数时停止训练
 Trainer:这是文件中的主要类,用于训练和评估Transformers模型,它包含许多方法,如train、evaluate、predict等
更具体的,Trainer类包括如下关键方法:
__init__:初始化方法,用于创建训练器对象。它接收模型、训练参数、数据集等作为输入,并设置相关属性
def __init__( self, model: PreTrainedModel, args: TrainingArguments, train_dataset: Optional[Dataset] = None, eval_dataset: Optional[Dataset] = None, tokenizer: Optional[PreTrainedTokenizerBase] = None, data_collator: Optional[DataCollator] = None, train_iterator: Optional[DataLoader] = None, eval_iterator: Optional[DataLoader] = None, ... ):train:这个方法负责整个训练过程,它包括遍历数据集、计算损失、计算梯度、更新模型参数以及日志记录等
遍历数据集:train方法通过使用dataloader来遍历训练数据集``````for step, inputs in enumerate(epoch_iterator):计算损失:损失计算在training_step方法中,接收输入数据并产生预测输出,然后,这个预测输出会与真实输出(标签)进行比较,以计算损失``````outputs = model(**inputs)``````上述代码行使用model(已经加载了预训练模型)和inputs(包含输入数据的字典)计算模型的预测输出。这个outputs变量包含模型预测的结果``````接下来,我们从outputs中获取预测结果,并与真实标签(即labels)进行比较,以计算损失``````loss = outputs.loss``````outputs.loss是模型预测输出和真实输出(标签)之间的损失。这个损失值将用于计算梯度并更新模型参数计算梯度:loss.backward()这行代码计算模型参数关于损失的梯度``````loss.backward()梯度累积:当gradient_accumulation_steps大于1时,梯度会被累积,而不是立即更新模型参数``````if (step + 1) % self.args.gradient_accumulation_steps == 0:更新模型参数:optimizer.step()这行代码根据计算出的梯度来更新模型参数``````self.optimizer.step()学习率调整:lr_scheduler.step()根据预定义的学习率调度策略更新学习率``````self.lr_scheduler.step()日志记录:log方法用于记录训练过程中的一些关键指标,例如损失、学习率等evaluate:这个方法用于评估模型在验证数据集上的性能,返回评估结果
def evaluate( self, eval_dataset: Optional[Dataset] = None, ignore_keys: Optional[List[str]] = None ) -> Dict[str, float]:predict:这个方法用于在给定的数据集上进行预测,返回预测结果
def predict( self, test_dataset: Dataset, ignore_keys: Optional[List[str]] = None ) -> PredictionOutput:save_model:这个方法用于将训练好的模型保存到指定的目录
def save_model(self, output_dir: Optional[str] = None):
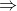 ShardedDDPOption:这是一个可选的类,用于支持使用混合精度和ZeRO进行分布式训练
3.1.3 Alpaca-LoRA:通过PEFT库在消费级GPU上微调「基于LLaMA的Alpaca」
在神经网络模型中,模型参数通常以矩阵的形式表示。对于一个预训练好的模型,其参数矩阵已经包含了很多有用的信息。为了使模型适应特定任务,我们需要对这些参数进行微调
LoRA的核心思想是用一种低秩的方式来调整这些参数矩阵。在数学上,低秩意味着一个矩阵可以用两个较小的矩阵相乘来近似,通过论文《LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》可知(这是解读之一)
- 选择目标层:首先,在预训练神经网络模型中选择要应用LoRA的目标层。这些层通常是与特定任务相关的,如自注意力机制中的查询Q和键K矩阵
- 初始化映射矩阵和逆映射矩阵:为目标层创建两个较小的矩阵A和B
- 参数变换:将目标层的原始参数矩阵W通过映射矩阵A和逆映射矩阵B进行变换。计算公式为:W' = W + A * B。这里W'是变换后的参数矩阵
- 微调模型:使用新的参数矩阵W'替换目标层的原始参数矩阵W,然后在特定任务的训练数据上对模型进行微调
- 梯度更新:在微调过程中,计算损失函数关于映射矩阵A和逆映射矩阵B的梯度,并使用优化算法(如Adam、SGD等)对A和B进行更新 注意,在更新过程中,原始参数矩阵W保持不变,说白了,训练的时候固定原始PLM的参数,只训练降维矩阵A与升维矩阵B
- 重复更新:在训练的每个批次中,重复步骤3-5,直到达到预定的训练轮次(epoch)或满足收敛条件
总之,LoRA的详细步骤包括选择目标层、初始化映射矩阵和逆映射矩阵、进行参数变换和模型微调。在微调过程中,模型会通过更新映射矩阵U和逆映射矩阵V来学习特定任务的知识,从而提高模型在该任务上的性能。
而Huggingface公司推出的PEFT(Parameter-Efficient Fine-Tuning)库便封装了LoRA这个方法,PEFT库可以使预训练语言模型高效适应各种下游任务,而无需微调模型的所有参数,即仅微调少量(额外)模型参数,从而大大降低了计算和存储成本
ModelFull FinetuningPEFT-LoRA PyTorchPEFT-LoRA DeepSpeed with CPU Offloadingbigscience/T0_3B (3B params)47.14GB GPU / 2.96GB CPU14.4GB GPU / 2.96GB CPU9.8GB GPU / 17.8GB CPUbigscience/mt0-xxl (12B params)OOM GPU56GB GPU / 3GB CPU22GB GPU / 52GB CPUbigscience/bloomz-7b1 (7B params)OOM GPU32GB GPU / 3.8GB CPU18.1GB GPU / 35GB CPU
且PEFT库支持以下流行的方法
- LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- P-Tuning: GPT Understands, Too
- Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
而Alpaca-LoRA则可以通过PEFT库实现的LoRA方法在消费级GPU微调「基于LLaMA的Alpaca」,比如项目中的这个文件finetune.py 包含了PEFT在LLaMA上的直接应用,以及一些与prompt construction和tokenization相关的代码,以下是用法示例:
python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' \
--output_dir './lora-alpaca'
我们还可以调整我们的超参数(为方便大家理解,我给每个参数都加了注释说明):
python finetune.py \ # 运行微调脚本
--base_model 'decapoda-research/llama-7b-hf' \ # 选择预训练的基础模型
--data_path 'yahma/alpaca-cleaned' \ # 用于微调的数据集路径
--output_dir './lora-alpaca' \ # 微调后模型的输出目录
--batch_size 128 \ # 设置每个批次的样本数量
--micro_batch_size 4 \ # 设置每个小批次的样本数量
--num_epochs 3 \ # 设置训练的轮次(epoch)
--learning_rate 1e-4 \ # 设置学习速率
--cutoff_len 512 \ # 设置截断长度
--val_set_size 2000 \ # 设置验证集的大小
--lora_r 8 \ # 设置LoRA方法中的秩
--lora_alpha 16 \ # 设置LoRA方法中的alpha值
--lora_dropout 0.05 \ # 设置LoRA方法中的dropout率
--lora_target_modules '[q_proj,v_proj]' \ # 设置使用LoRA进行微调的模型模块
--train_on_inputs # 指示模型在训练时使用输入文本
3.1.4 Alpaca所用的self-instruct的影响力:解决一大批模型的数据扩展问题
很快,通过下文你会发现
- self-instruct启发出很多「羊驼类模型」 羊驼率先带动的self-instruct,启发后续很多人/团队也用这个方式去采集『提示ChatGPT API』的数据,比如BELLE、ChatLLaMA、ColossalChat
- 很多「羊驼类模型」的数据被用于微调新一批模型 然后还有一批模型各种叠加组合比如『Alpaca/BELLE』,又用于微调一批批模型 比如ChatDoctor 有用到Alpaca的数据进行微调,再比如有人拿BELLE数据tuning去调chatglm

一下子出来这么新的模型 似乎有点懵,没事,请看下文及下一篇文章娓娓道来..
3.2 Vicuna-13B:通过ShareGPT.com的7万条对话数据微调LLaMA
23年3.31日,受 Meta LLaMA 和 Stanford Alpaca 项目的启发,加州大学伯克利分校(UC Berkeley)等大学的研究者根据从 ShareGPT.com (ShareGPT是一个用户可以分享他们的 ChatGPT 对话的网站)收集的用户共享对话微调 LLaMA 推出了Vicuna-13B(中文称小羊驼,代码地址:FastChat)。
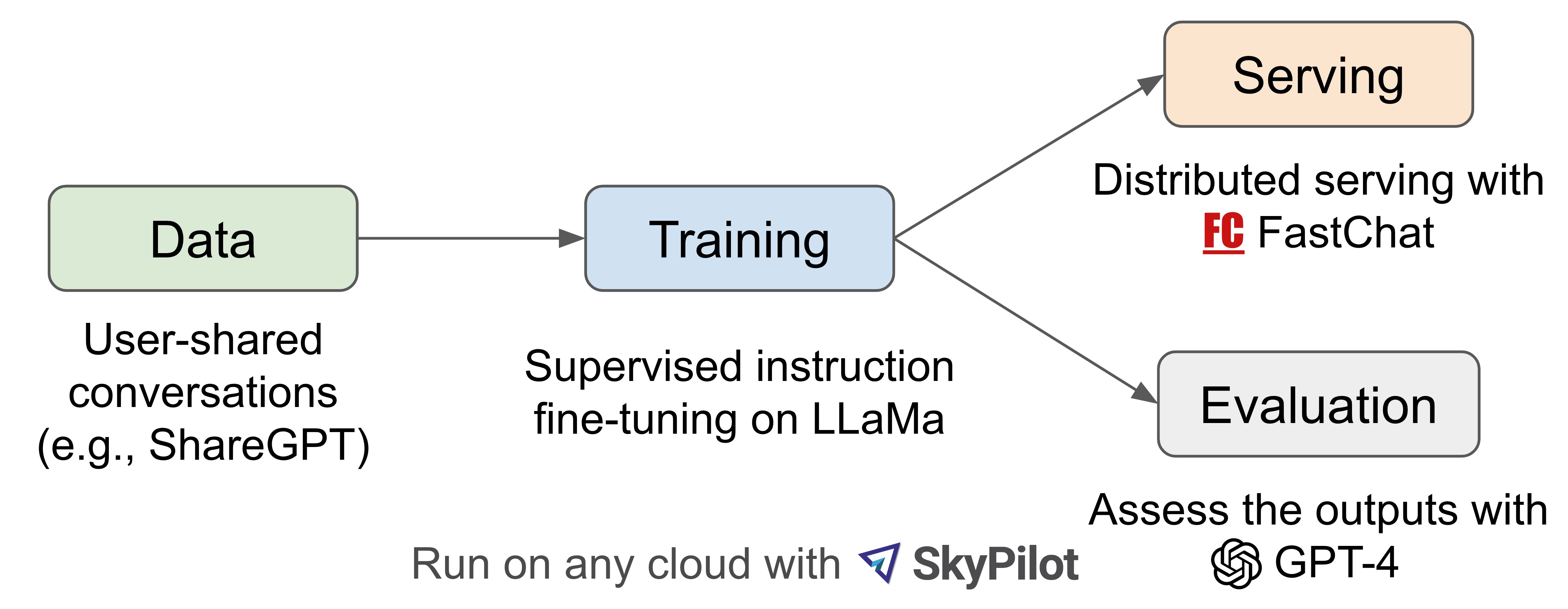
在数据规模上,Vicuna从ShareGPT.com 的公共 API 收集了大约 70K 用户共享对话,且为了确保数据质量,原作者们将 HTML 转换回 markdown 并过滤掉一些不合适或低质量的样本。此外,将冗长的对话分成更小的部分,以适应模型的最大上下文长度,并做了以下改进
- 内存优化:为了使 Vicuna 能够理解长上下文,将最大上下文长度从羊驼中的 512 扩展到 2048,这大大增加了 GPU 内存需求,对此通过利用梯度检查点和闪存注意力来解决内存压力
- 多轮对话:调整训练损失以考虑多轮对话,并仅根据聊天机器人的输出计算微调损失。
- 通过Spot Instance 降低成本:40 倍大的数据集和 4 倍的训练序列长度对训练费用提出了相当大的挑战。原作者们使用SkyPilot managed spot 来降低成本『SkyPilot是加州大学伯克利分校构建的一个框架,用于在各种云上轻松且经济高效地运行 ML 工作负载』,方法是利用更便宜的spot instances以及auto-recovery for preemptions and auto zone switch 该解决方案将 7B 模型的训练成本从 500 美元削减至 140 美元左右,将 13B 模型的训练成本从 1000 美元左右削减至 300 美元
有两点值得一提的是
- 对于个人开发者而言,Vicuna-13B 只需要大约 28GB 的GPU 显存,Vicuna-7B 大约需要14GB GPU显存,但对于机构而言,一般通过8个具有 80GB 显存的 A100 GPU 进行训练
- 且Vicuna使用了和Alpaca差不多的超参数 Hyperparameter全局批量大小Batch Size学习率Learning rateEpochsMax lengthWeight decayVicuna-13B1282e-5320480
最终通过直接使用GPT4评估之后,效果还不错
Model NameLLaMA(骆驼)Alpaca(羊驼)Vicuna(小羊驼)Bard/ChatGPTDatasetPublicly available datasets
(1.4T token)Self-instruct from davinci-003 API
(52K samples)User-shared conversations
(70K samples)N/ATraining codeN/AAvailableAvailableN/AEvaluation metricsAcademic benchmarkAuthor evaluationGPT-4 assessmentMixedTraining cost
(7B)82K GPU-hours$500 (data) + $100 (training)$140 (training)N/ATraining cost
(13B)135K GPU-hoursN/A$300 (training)N/A
3.3 BELLE:结合中文语料通过Self Instruct方式微调BLOOMZ-7B或LLaMA
Stanford Alpaca的种子任务都是英语,收集的数据也都是英文,因此训练出来的模型未对中文优化。为了提升对话模型在中文上的效果,70 亿参数的中文对话大模型 BELLE『Bloom-Enhanced Large Language model Engine』来了(这是项目地址)。
在数据方面,结合以下两方面的数据:
- Alpaca 的 5.2 万条英文数据
- 通过Alpaca的数据收集代码生成的约 100 万条中文数据『也仅使用由 GPT3.5 即模型text-davinci-003 生产的数据,不包含任何其他数据,如果想使用ChatGPT的API比如gpt-3.5-turbo模型,可通过参数控制』
模型训练上,有
- 基于BLOOMZ-7B1-mt优化后的模型:BELLE-7B-0.2M,BELLE-7B-0.6M,BELLE-7B-1M,BELLE-7B-2M
- 基于huggingface的LLaMA实例实现调优的模型:BELLE-LLAMA-7B-2M,BELLE-LLAMA-13B-2M
BLOOM是由HuggingFace于2022年3月中旬推出的大模型,规模最大版本的参数量达到176B(GPT-3是175B),基于从 Megatron-LM GPT-2修改而来的仅解码器 transformer 模型架构,对应的论文为《BLOOM: A 176B-Parameter Open-Access Multilingual Language Model》(翻译之一,解读之一)
至于HuggingFace是著名开源工具Transformers的开发公司,很多推理工具都会支持Transformers中的模型
截至23年3月中旬,超过100B参数量且能够支持中文的开源大模型只有BLOOM和GLM-130B
该项目主要包含以下三部分内容:
- 175 个中文种子任务,斯坦福Alpaca一样,每个任务都包含对应的指令/任务、prompt、输出
- 生成数据及其代码 沿用 Alpaca 的方式: pip install -r requirements.txt export OPENAI_API_KEY=YOUR_API_KEY python generate_instruction.py generate_instruction_following_data 默认使用 Completion API,模型 text-davinci-003。如果想使用 Chat API 并使用 gpt-3.5-turbo 模型,可通过参数控制: python generate_instruction.py generate_instruction_following_data \ --api=chat --model_name=gpt-3.5-turbo 输出文件在 Belle.train.json,可以人工筛选后再使用
- 基于 BLOOMZ-7B1-mt 模型和 Belle.train.json 训练模型
3.4 Chinese-LLaMA/Chinese-Alpaca:通过中文数据预训练/指令微调
Chinese LLaMA(也称中文LLaMA,有7B和13B两个版本,项目地址),相当于在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力,同时,在中文LLaMA的基础上,且用中文指令数据进行指令精调得**Chinese-Alpaca(**也称中文Alpaca,同样也有7B和13B两个版本)
具体而言,主要做了以下三方面的工作
- 词表扩充中文数据 在通用中文语料上训练了基于sentencepiece的20K中文词表并与原版LLaMA模型的32K词表进行合并 排除重复的token后,得到的最终中文LLaMA词表大小为49953 需要注意的是,在fine-tune阶段Alpaca比LLaMA多一个pad token,所以中文Alpaca的词表大小为49954 这么做的主要原因是原版LLaMA模型的词表大小是32K,其主要针对英语进行训练,对多语种支持不是特别理想(可以对比一下多语言经典模型XLM-R的词表大小为250K)。通过初步统计发现,LLaMA词表中仅包含很少的中文字符,所以在切词时会把中文切地更碎,需要多个byte token才能拼成一个完整的汉字,进而导致信息密度降低
- 加入中文数据的预训练 在预训练阶段,使用约20G左右的通用中文语料(与中文BERT-wwm、MacBERT、LERT、PERT中使用的语料一致)在原版LLaMA权重的基础上进一步进行预训练。该过程又分为两个阶段: 第一阶段:冻结transformer参数,仅训练embedding,在尽量不干扰原模型的情况下适配新增的中文词向量 第二阶段:使用LoRA技术,为模型添加LoRA权重(adapter),训练embedding的同时也更新LoRA参数
- 指令精调 指令精调阶段的任务形式基本与Stanford Alpaca相同,训练方案同样采用了LoRA进行高效精调,并进一步增加了可训练参数数量 在prompt设计上,精调以及预测时采用的都是原版Stanford Alpaca不带input的模版。对于包含input字段的数据,采用*
f"{instruction}+\n+{input}"*的形式进行拼接 且指令精调阶段使用了以下数据,其中7B模型约2M数据、13B模型约3M数据。基本构成如下:
数据量级来源说明中英翻译数据500K外部链接在原数据集的基础上进行了采样+规则筛选pCLUE数据300K外部链接在原数据集的基础上进行了采样+规则筛选Alpaca数据(英)50K外部链接斯坦福原版Alpaca训练数据Alpaca数据(中)50K本地链接本项目使用ChatGPT接口将英文版翻译为中文(筛掉一部分)Self-instruction数据1~2M(暂无)本项目使用ChatGPT接口进行爬取,提供了一个动态生成不同领域和指令类型的prompt爬取脚本script/crawl_prompt.py。
python script/crawl_prompt.py output-file
思路与Stanford Alpaca中的做法基本一致,一次批量生成20组数据(可自行修改模板),以降低爬取成本
生成的文件包含通过gpt-3.5-turbo爬取的数据(你必须拥有OpenAI API key才可以使用)
虽然指令模板中要求输出JSON,但系统并不总是会返回合法的JSON,需要自行对返回数据进行清洗
由于爬取时间比较长,建议后台运行该脚本,且多线程运行时注意OpenAI API的调用限制上限
当然,针对一些任务上效果不好!原作者也给出了几个可能的原因,
1)本身LLaMA对中文支持不是很好,大多数相关衍生工作是直接在原版上进行pretrain/finetune的,而我们采取了更大胆的策略——增加中文词表,可能进一步加剧中文训练不充分的问题,但从长远看是否有利于后续进一步预训练就得靠时间检验了;
2)指令数据的质量有待进一步提升;
3)训练时间、超参等方面还有很大调整空间;
4)没有RLHF;
5)4-bit量化后效果可能会下降,因此可以尝试加载FP16模型,效果相对更好一些(也更慢)
更多请查看下一篇:从ChatGLM-6b到ChatDoctor
版权归原作者 v_JULY_v 所有, 如有侵权,请联系我们删除。