
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
红豆生南国,春来发几枝。
大家好,我是Python进阶者。
一、前言
前几天在Python最强王者交流群【G.】问了一个Python网络爬虫的问题,问题如下:各位大佬好,我这遇到一个问题,用selenium爬网页的时候,切换页面后网页有时会出现10条数据,有时会出现6条数据,出现6条数据时显示的数据都是已经爬取过的数据,该怎么解决呢?
这里【郑煜哲·Xiaopang】问到:切换页面指的是?switch window?还是get?
粉丝回答:从1切换到2,应该是get。
【郑煜哲·Xiaopang】:代码看看,你是不是漏参数了
二、实现过程
这里【瑜亮老师】给了个思路如下:这个网站为啥要用selenium?requests不香么?
【G.】:因为不光要爬编号和名称,还要点进去把全文下载下来
【郑煜哲·Xiaopang 】:我扫了一眼,还有iframe。盲猜是逻辑有bug,卧槽,怎么写的这么复杂。我怀疑是这样的,第一页的bar是这种,然后第二页的bar就多了两个元素,震惊了。
【G.】:初学者
【瑜亮老师 】:其实也不用selenium,这个id在搜索结果页面就有,翻页用。
【郑煜哲·Xiaopang】:嗯,可以不用的,直接用pageno=参数就行了。sel适合入门。
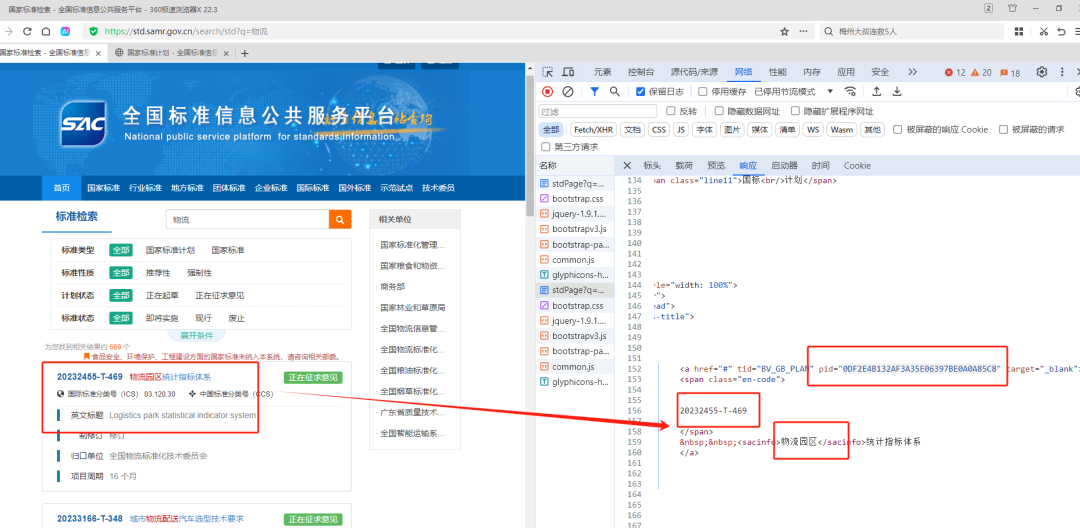
【G.】:哦哦那我试试requests
【郑煜哲·Xiaopang】:同目测大概率你pagebar的处理逻辑有问题
【G.】:不太清楚哎,那儿的处理逻辑感觉没啥问题。这个网页本身我自己在手动点的时候有时候也会出现这种情况
【瑜亮老师】:@G. 使用requests3步请求就可以下载pdf 1.请求搜索结果页,用pageNo参数获取翻页,正则拿到页面所有pid 2.用pid请求gbDetailed页面,正则拿到pdf下载地址file_path,截取后获得file_name 3.拼接pdf_url,请求后with open保存成pdf。
我试过了,非常顺畅。唯一需要注意的就是,某些gbDetailed页面中并没有pdf,需要加个if判断一下。
【G.】:@德善堂小儿推拿-瑜亮老师 有些标准第三步保存成pdf点那个在线预览之后有验证码怎么办呢
【瑜亮老师】:requests也不用点啊
【G.】:那怎么拿到pdf的下载地址啊
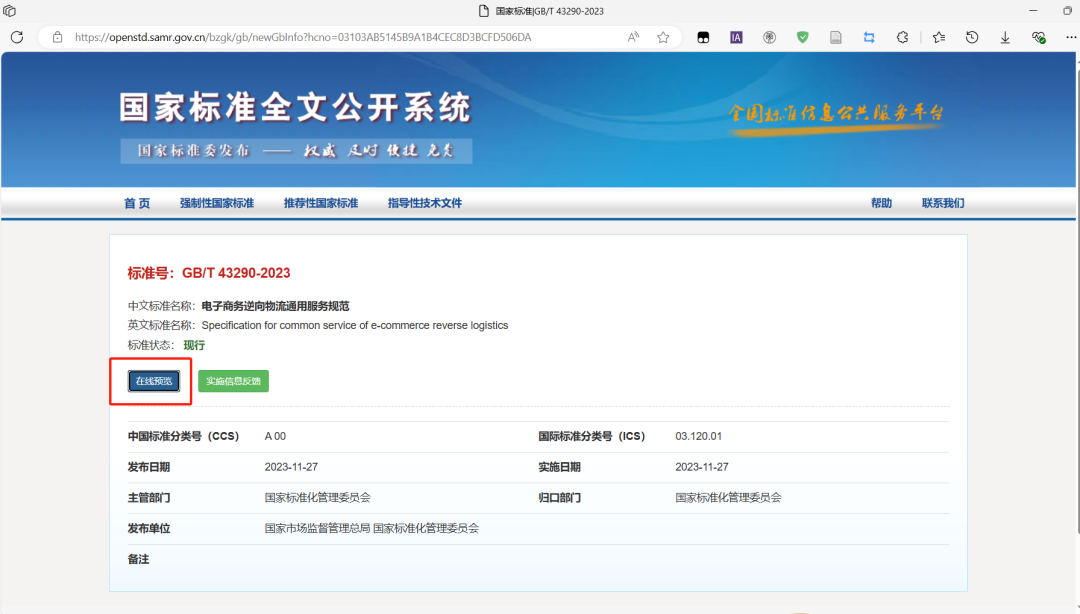
【瑜亮老师】:你看页面源码中是否有
【G.】:哦哦好
顺利地解决了粉丝的问题。
如果你也有类似这种Python相关的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python网络爬虫的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【G.】提出的问题,感谢【郑煜哲·Xiaopang】、【瑜亮老师】给出的思路,感谢【莫生气】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting1),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

****-----****------****--------**************************** End ****-----****--------****------****************************
往期精彩文章推荐:
- if a and b and c and d:这种代码有优雅的写法吗?
- Pycharm和Python到底啥关系?
- 都说chatGPT编程怎么怎么厉害,今天试了一下,有个静态网页,chatGPT居然没搞定?
- 站不住就准备加仓,这个pandas语句该咋写?

欢迎大家点赞,留言,转发,转载,****感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~
版权归原作者 Python进阶者 所有, 如有侵权,请联系我们删除。