
目录
前言
hive尚硅谷面试刷题网站
hive日志位置(root用户下):
/tmp/root/hive.log
一、Hive入门
Hive入门官方文档点此👉前往
🍉Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
统计单词出现个数
- 在 Hadoop 课程中我们用 MapReduce程序实现的,当时需要写Mapper、Reducer和 Driver三个类,并实现对应逻辑,相对繁琐。
- 如果通过Hive SQL 实现,一行就搞定了,简单方便,容易理解
select count(*) from test group by id
1.1. Hive本质
🍉是一个 Hadoop客户端,用于将HQL (Hive SQL)转化成MapReduce程序
- Hive中每张表的数据存储在HDFS中
- Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez)
- 执行程序运行在 Yarn 上
1.2. Hive架构原理

Hive内部执行流程:解析器(解析SQL语句)、编译器(把SQL语句编译成MapReduce程序)、优化器(优化MapReduce程序)、执行器(将MapReduce程序运行的结果提交到HDFS)
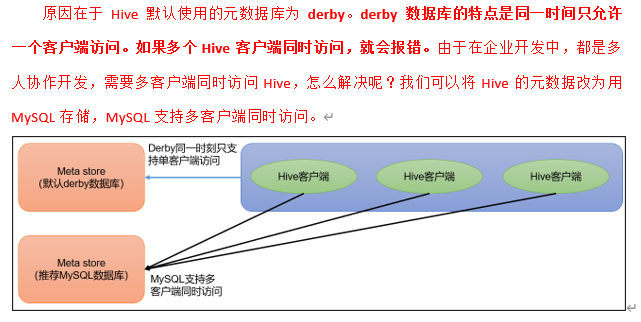
🍉元数据(Metastore):元数据包括数据库(默认是default)、表名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。默认存储在自带的 derby 数据库中,由于 derby数据库只支持单客户端访问,生产环中为了多人开发,推荐使手MySQL存储 Metastore
🍉驱动器(Driver):
- 解析器(SQLParser):将SQL字符串转换成抽象语法树(AST)
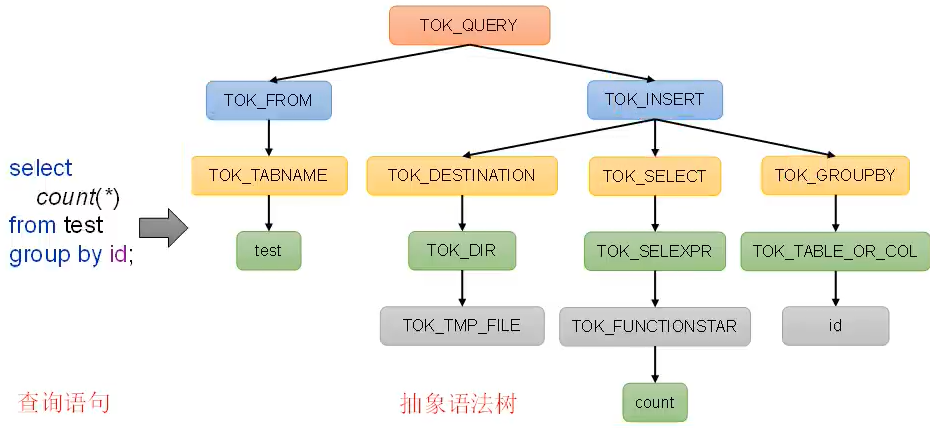
- 语义分析(Semantic Analyzer):将AST进一步划分为
QeuryBlock - 逻辑计划生成器(Logical Plan Gen):将语法树生成逻辑计划
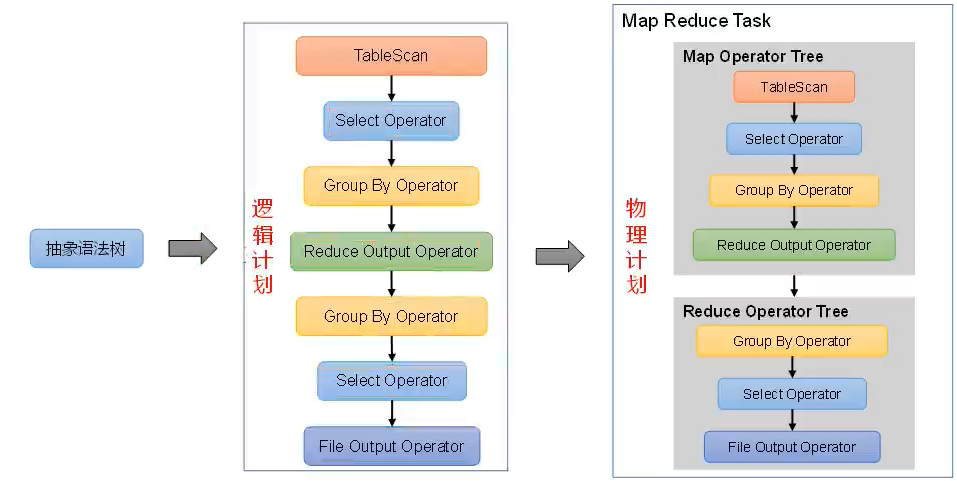
- 逻辑优化器(Logical Optimizer):对逻辑计划进行优化
在Hive架构中,逻辑优化器是负责对HiveQL查询进行逻辑优化的重要组件。逻辑优化器主要针对查询的逻辑结构进行优化,以提高查询性能和效率。下面是逻辑优化器的一些常见优化技术:
- 列剪裁(Column Pruning):逻辑优化器通过分析查询语句中涉及的列,剪裁掉不必要的列,从而减少数据传输和处理的开销。
- 谓词下推(Predicate Pushdown):逻辑优化器将查询语句中的谓词(过滤条件)下推到数据源,以减少数据的读取量和计算量。
- 连接重排(Join Reordering):逻辑优化器根据查询语句中的连接操作,尝试重新排列连接的顺序,选择更优的连接顺序,以减少中间结果的大小和计算量。
- 子查询优化(Subquery Optimization):逻辑优化器对查询语句中的子查询进行优化,如转化为连接操作、使用嵌套循环连接等,以减少子查询的计算量。
- 聚合推导(Aggregate Deduction):逻辑优化器根据查询语句中的聚合操作,尝试推导出部分聚合结果,以减少计算量和数据传输开销。
- 条件推断(Predicate Inference):逻辑优化器根据查询语句中的条件和约束,推断出更多的条件,以进一步减少数据的读取量和计算量。
逻辑优化器通过这些优化技术,对查询进行重写和重组,以减少不必要的计算和数据传输,提高查询的性能和效率。这些优化技术可以根据查询的特点和数据的分布情况,自动应用于查询执行计划的生成过程中。
- 物理计划生成器(Physical Plan Gen):根据优化后的逻辑计划生成物理计划
- 物理优化器(Physical Optimizer):对物理计划进行优化(map join详见👉点击)
- 执行器(Execution):执行该计划,得到查询结果并返回给客户端
🍉Hive的架构原理可以概括如下:
- 元数据存储:Hive的元数据存储在关系型数据库(如MySQL)中,包括表的模式、列的类型、分区信息等。元数据存储描述了数据的结构和位置。
- 查询编译和优化:当用户提交一个HiveQL查询时,Hive首先将查询语句进行解析和语法分析,然后进行查询优化。查询优化包括列剪裁、谓词下推、连接重排等技术,以提高查询性能。
- 查询执行计划:在查询优化后,Hive生成一个逻辑查询计划,描述了查询的执行流程和操作顺序。然后,逻辑查询计划被转化为物理查询计划,根据底层存储引擎(如MapReduce、Tez、Spark等)的特点进行优化。
- 数据存储和处理:Hive中的数据存储在Hadoop分布式文件系统(HDFS)中,以文件的形式进行存储。数据可以按照表的分区进行划分,以提高查询效率。Hive使用Hadoop生态系统的计算框架(如MapReduce、Tez、Spark)进行数据处理。
- 用户接口(Client):Hive提供了多种用户接口,包括命令行接口(CLI)、Web界面(Hive WebUI)和编程接口(如Java、Python、JDBC、ODBC等),用于用户与Hive进行交互。
总的来说,Hive的架构原理是将用户提交的查询语句进行编译、优化和执行计划生成,然后通过底层的存储和计算引擎进行数据的存储和处理。通过Hive的元数据存储和查询优化技术,用户可以使用类似于SQL的语言对大规模的结构化数据进行分析和处理。
JDBC和ODBC的区别:
- JDBC的移植性比 ODBC 好(通常情况下,安装完ODBC 驱动程序之后,还需要经过确定的配置才能够应用。而不相同的配置在不相同数据库服务器之间不能够通用。所以,安装一次就需要再配置一次。JDBC只需要选取适当的JDBC 数据库驱动程序,就不需要额外的配置。在安装过程中,JDBC 数据库驱动程序会自己完成有关的配置)
- 两者使用的语言不同,JDBC 在Java编程时使用,ODBC一般在C/C++编程时使用
二、Hive3.1.3安装
1. 最小化安装部署(仅适合学习测试)
把元数据存储在客户端进程内嵌的一个derby数据库,这个数据库是这个进程专有独享的,其他客户端无法使用
🍉准备工作
# 启动集群
myhadoop.sh start
# 查看集群启动情况
jpsall
🍉下载解压(均在Hadoop102上)
如遇过期👉请到这里点击下载bin.tar.ge文件然后复制下载链接(阿里镜像站,下载失败就找他)
# 下载在/opt/software/wget https://mirrors.aliyun.com/apache/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz?spm=a2c6h.25603864.0.0.3462158fKLAMVw
# 解压tar-zxvf /opt/software/apache-hive-3.1.3-bin.tar.gz -C /opt/module
# 改名mv apache-hive-3.1.3-bin/ hive
🍉在
/etc/profile.d/my_env.sh
添加环境变量
#HIVE_HOMEexportHIVE_HOME=/opt/module/hive
exportPATH=$PATH:$HIVE_HOME/bin
🍉刷新一下环境
source /etc/profile.d/my_env.sh
🍉初始化元数据库(默认是derby数据库)
cd /opt/module/hive;bin/schematool -dbType derby -initSchema
🤯出Bug了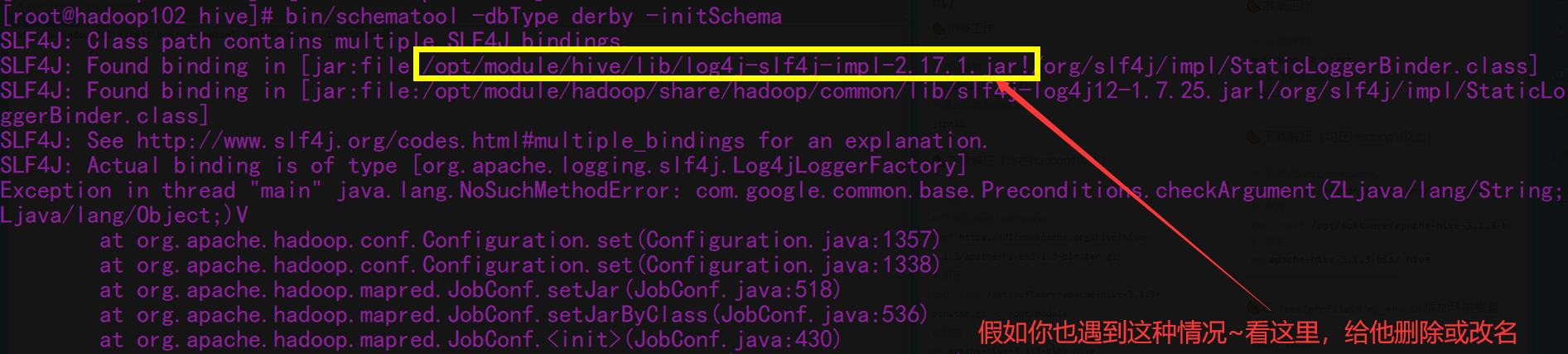
💡解决方案:jar包,动手!
cd /opt/module/hive/lib
mv log4j-slf4j-impl-2.17.1.jar log4j-slf4j-impl-2.17.1.jar.bak
🤯又出Bug了(执行初始化命令时发生报错是因为hadoop和hive的两个
guava.jar
版本不一致)
💡解决方案:删除+复制
rm-rf /opt/module/hive/lib/guava-19.0.jar;cp-r /opt/module/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/hive/lib/
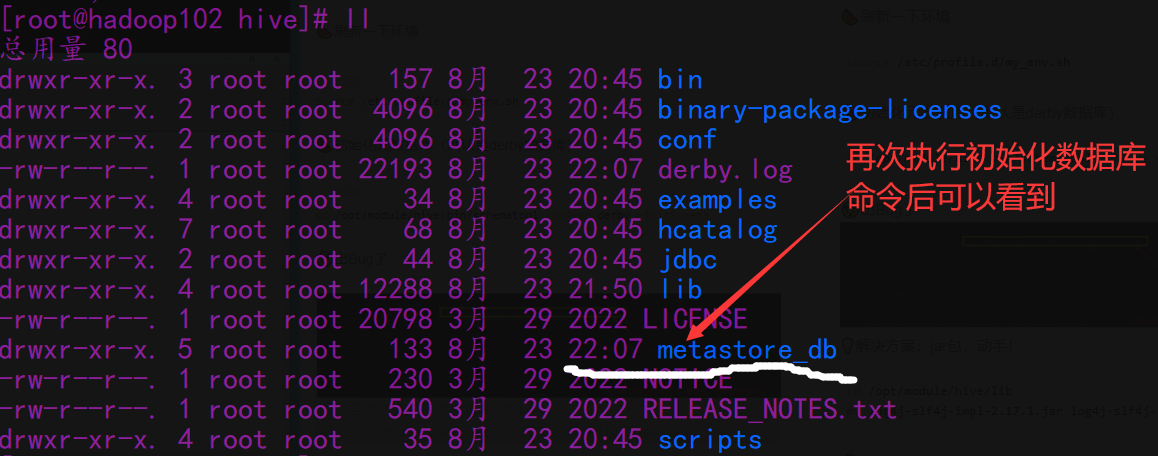
🍉hive,启动!
hive
# 测试一下
show databases;
🤯又双出Bug了
💡解决方案:不知道怎么解决,大佬帮帮~
# 卸载重装rm-rf hive
tar-zxvf /opt/software/apache-hive-3.1.3-bin.tar.gz -C /opt/module
🍉接着测试:
hive>showtables;
hive>createtable stu(id int, name string);
hive>insertinto stu values(1,"ss");
hive>select*from stu;
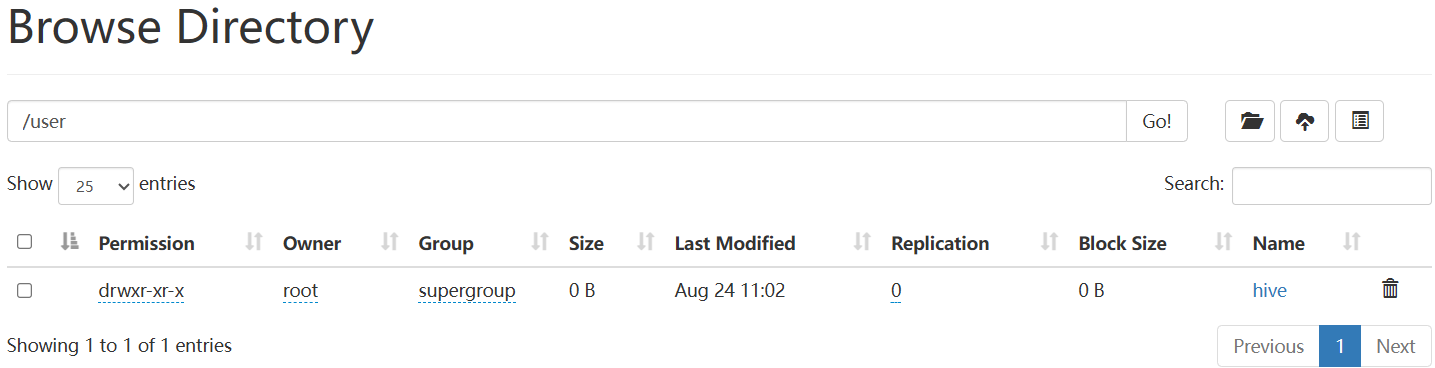
🌰通过HDFS网页端Hadoop102上查看建表情况点击👉前往,在mapreduce中也能看到点击👉前往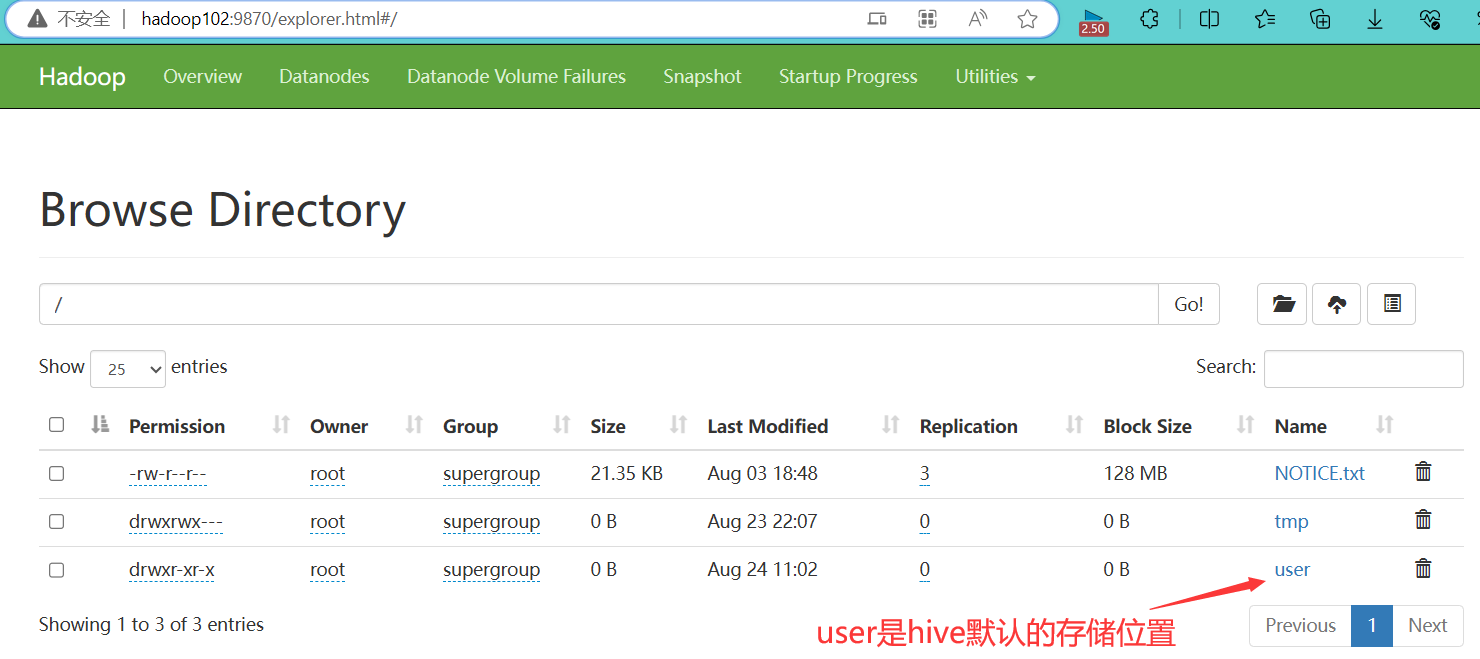

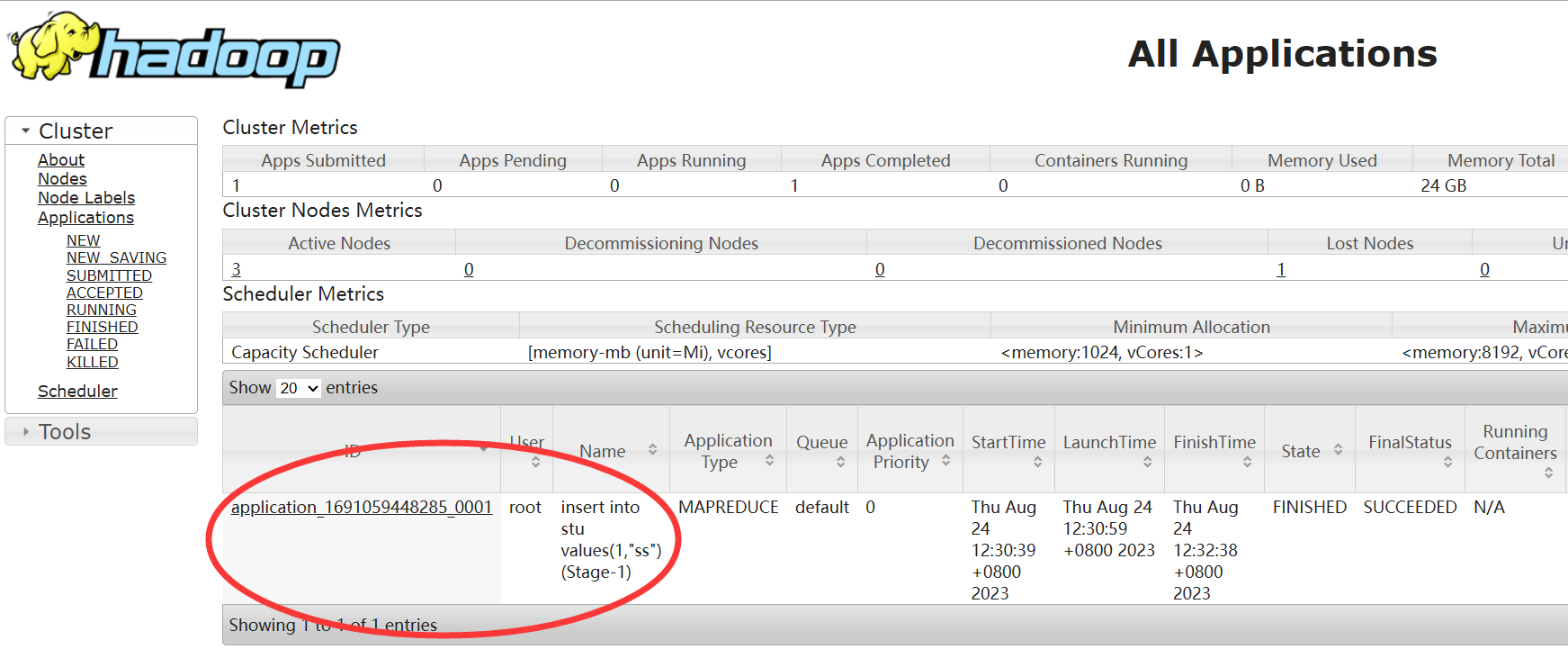
没有Yarn上提交任务,因为对于简单的查询语句(无需计算)hive进行了优化
Hive中的表在 Hadoop中是目录;Hive中的数据在Hadoop中是文件
🍉尝试:另一个窗口开启Hive,在
/tmp/root
目录下监控
hive.log
文件,发现不行!
# 首先退出hive客户端。然后在Hive的安装目录下将derby.log和metastore_db删除,顺便将HDFS上目录删除
hive> quit;rm-rf /root/derby.log /opt/module/hive/metastore_db
2. 安装MySQL
🍉离线安装MySQL详见MySQL安装指南点击👉前往
# 在/usr/local/mysql目录下再安装一个包rpm-ivh mysql-community-libs-compat-8.0.34-1.el7.x86_64.rpm
如果报错提示有依赖包没有下载,则前往Packages for Linux and Unix点击👉前往
🍉MySQL,启动!
systemctl start mysqld ; systemctl status mysqld
🍉配置MySQL
# 查看MySQL默认初始密码cat /var/log/mysqld.log |grep password
# 查询user表select user,host from user;# 修改user表,把Host表内容修改为%,使得任意节点均可访问
update user sethost="%" where user="root";# 刷新权限select user,host from user;
3. 卸载MySQL


4. 配置Hive元数据存储到MySQL中
🍉新建元数据库
createdatabase metastore;
🍉下载MySQL的JDBC驱动到Hive的lib目录下
# 由于上次mycat下载过相应版本的驱动jar包mysql-connector-j-8.1.0.jarcp /usr/local/mycat/lib/mysql-connector-j-8.1.0.jar /opt/module/hive/lib/
驱动jar包==>mysql-connector-j-8.1.0.jar下载👉详见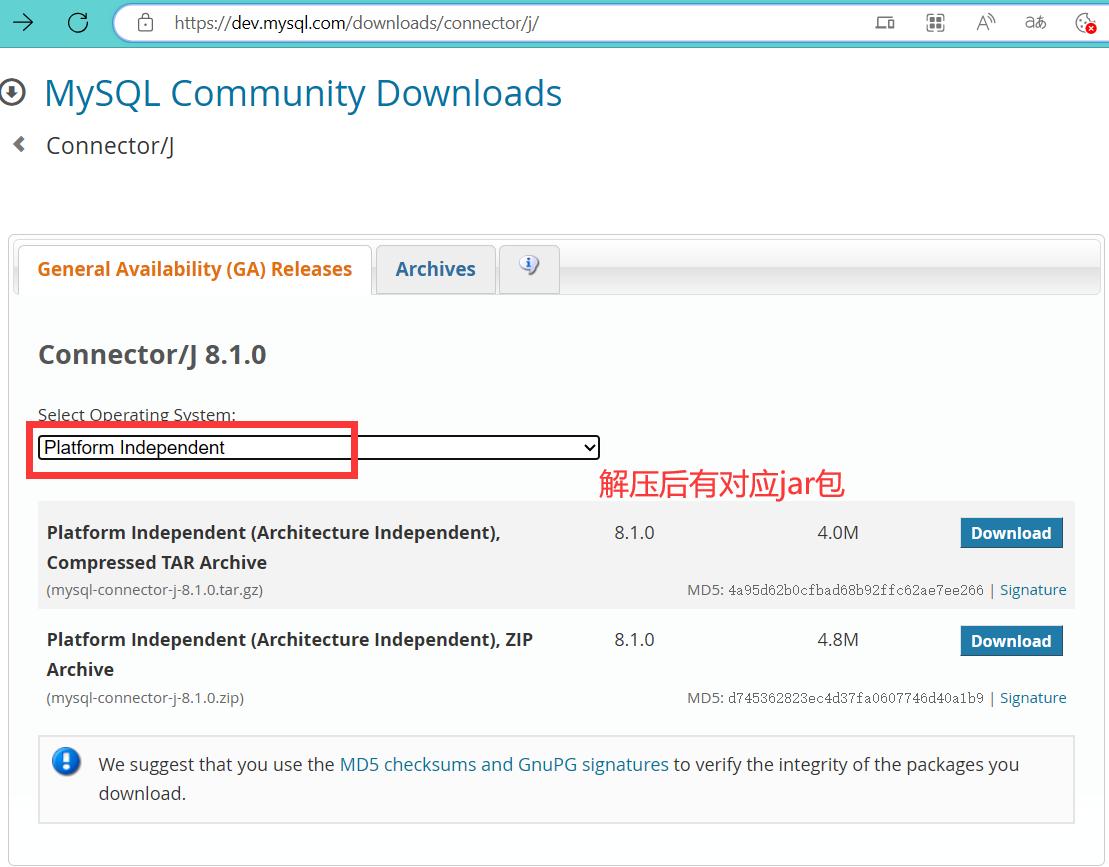
🍉在
/opt/module/hive/conf
目录下新建
hive-site.xml
文件:
vim /opt/module/hive/conf/hive-site.xml
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://192.168.150.103:3306/metastore?createDatabaseIfNotExist=true</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>lovexw999</value></property><!-- Hive默认在HDFS的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property></configuration>
🍉初始化Hive元数据库(修改为采用MySQL存储元数据)
cd /opt/module/hive/;bin/schematool -dbType mysql -initSchema-verbose
在三检查避免出Bug:
- jdbc连接的URL:要符合自己情况的!!
- jdbc连接的Driver:在Mysql 8及以上版本中,驱动类已经从com.mysql.jdbc.Driver改为com.mysql.cj.jdbc.Driver,在Mysql 8及以上版本中,虽然兼容老版本,但是推荐新的
- 驱动jar包:要找到对应当前MySQL版本的jar包
- jdbc连接的password:免密登录的要改过,详见👉这里
🍉验证元数据是否配置成功
hive>showdatabases;
hive>showtables;
hive>createtable stu(id int, name string);
hive>insertinto stu values(1,"ss");
hive>select*from stu;# 开启另一个窗口开启Hive(两个窗口都可以操作Hive,没有出现异常)
hive>showdatabases;
hive>showtables;
hive>select*from stu;
🍉查看元数据库中存储的库信息(打开DG)
- DBS表

- TBLS表

- SDS表

- 以上三图的关系
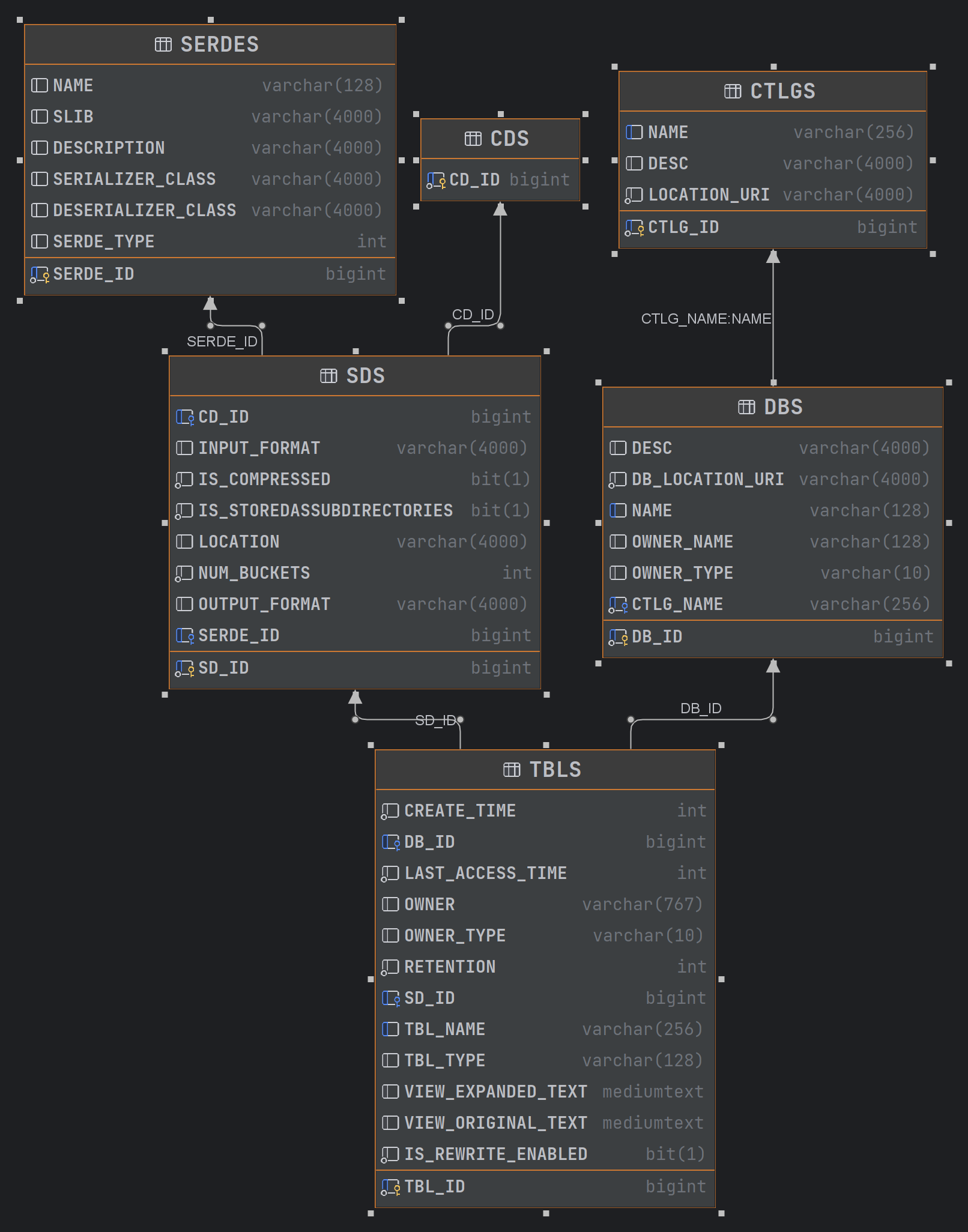
- COLUMNS_V2

- 元数据库表描述
表名说明BUCKETING_COLS存储bucket字段信息,通过SD_ID与其他表关联CDS表示该分区、表存储的字段信息。一个字段CD_ID,与SDS表关联COLUMNS_V2表示该分区、表存储的字段信息。存储字段信息,通过CD_ID与其他表关联DATABASE_PARAMS描述数据库的属性信息DBS存储hive的database信息DB_PRIVS描述数据库的权限信息FUNCS记录用户子集编写的函数信息,包括函数名、对应类名、创建者信息等FUNC_RU记录自定义函数所在文件的路径GLOBAL_PRIVS全局变量,与表无关IDXSHive中索引的信息PARTITIONS分区信息,SD_ID, TBL_ID关联PARTITION_KEYS存储分区字段列,TBL_ID关联PARTITION_KEY_VALS分区的值,通过PART_ID关联。与PARTITION_KEYS共用同一个字段INTEGER_IDX来标示不同的分区字段。PARTITION_PARAMS存储某分区相关信息,包括文件数,文件大小,记录条数等。通过PART_ID关联PART_COL_PRIVS分区列的授权信息PART_COL_STATS分区中列的统计信息ROLES角色表,和GLOBAL_PRIVS配合,与表无关SDS存储输入输出format等信息,包括表的format和分区的format。关联字段CD_ID,SERDE_IDSEQUENCE_TABLE存储sqeuence相关信息,与表无关SERDES存储序列化反序列化使用的类SERDE_PARAMS序列化反序列化相关配置信息,通过SERDE_ID关联SKEWED_COL_NAMES保存表、分区由数据倾斜的列信息,包括列名SKEWED_STRING_LIST保存表,分区有数据倾斜的字符串列表和值的信息SKEWED_STRING_LIST_VALUES保存表,分区有数据倾斜的字符串列表和值的信息SKEWED_VALUES保存表、分区倾斜列对应的本地文件路径SORT_COLS排序字段,包括列名和排序方式。通过SD_ID关联TABLE_PARAMS表相关信息,是否外部表,通过TBL_ID关联TAB_COL_STATS表中列的统计信息,包括数值类型的最大和最小值TBLS存储表信息,关联字段DB_ID,SD_IDTBL_COL_PRIVS表或视图中列的授权信息,包括授权用户、被授权用户和授权的权限等TBL_PRIVS表赋权限相关信息,通过TBL_ID关联VERSION版本VERSION_copy版本,通过VER_ID关联5. Hive服务部署
5.1. hiveserver2服务(远程访问服务)
🍉提供
jdbc/odbc
接口,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到
Hiveserver2
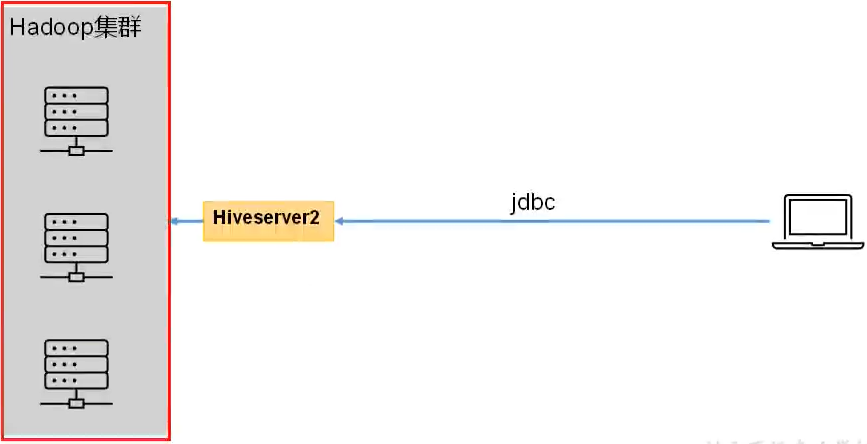
🍉访问hadoop集群身份说明
- 在远程访问Hive数据时,客户端并未直接访问Hadoop集群,而是由Hivesever2代理访问。由于Hadoop集群中的数据具备访问权限控制,所以此时需考虑一个问题:那就是访问Hadoop集群的用户身份是谁?是Hiveserver2的启动用户?还是客户端的登录用户?
- 答案是都有可能,具体是谁,由Hiveserver2的
hive.server2.enable.doAs参数决定(默认开启),该参数的含义是是否启用Hiveserver2用户模拟的功能。若启用,则Hiveserver2会模拟成客户端的登录用户去访问Hadoop集群的数据,不启用,则Hivesever2会直接使用启动用户访问Hadoop集群数据。模拟用户的功能,默认是开启的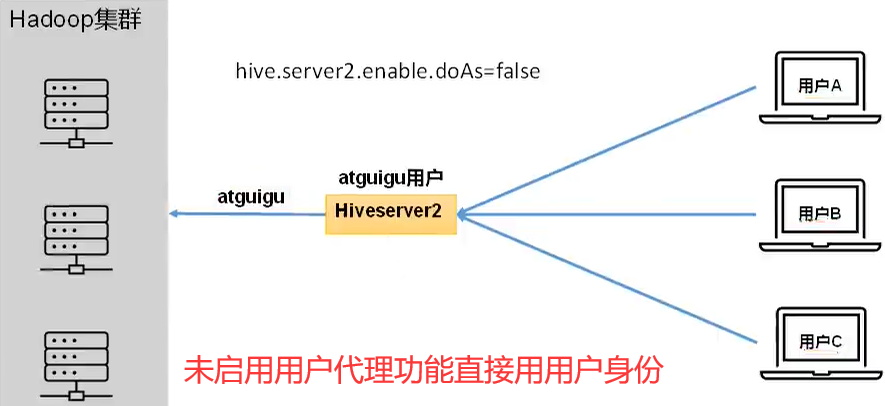
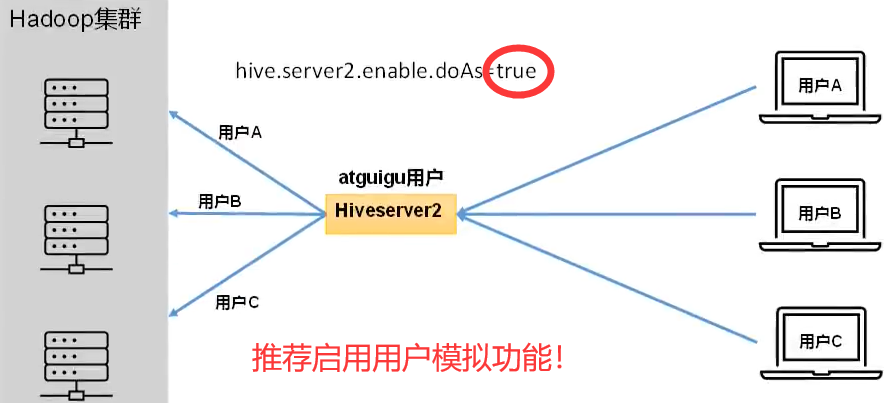
生产环境,推荐开启用户模拟功能,因为开启后才能保证各用户之间的权限隔离
🍉hiveserver2部署:hivesever2的模拟用户功能,依赖于Hadoop提供的
proxy user
(代理用户功能),只有Hadoop中的代理用户才能模拟其他用户的身份访问Hadoop集群。因此,需要将hiveserver2的启动用户设置为Hadoop的代理用户,配置方式如下:
1️⃣hadoop102中
/opt/module/hadoop/etc/hadoop/core-site.xml
<!--配置所有节点的root用户都可作为代理用户--><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><!--配置root用户能够代理的用户组为任意组--><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property><!--配置root用户能够代理的用户为任意用户--><property><name>hadoop.proxyuser.root.users</name><value>*</value></property>
分发
core-site.xml
文件
xsync core-site.xml
并重启集群
myhadoop.sh stop/start
2️⃣Hive端配置:
hive-site.xml
文件中添加如下配置信息
<!-- 指定hiveserver2连接的host --><property><name>hive.server2.thrift.bind.host</name><value>hadoop102</value></property><!-- 指定hiveserver2连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property>
🍉启动hiveserver2:
# 启动服务(这样启动会阻塞,一旦关闭该窗口就会挂掉服务)cd /opt/module/hive/;bin/hive --service hiveserver2
# 实际生产环境这样启动,退到后台运行nohup bin/hiveserver2 1>/dev/null 2>/dev/null &# 查看进程详细信息
jps -ml

🍉使用命令行客户端beeline进行远程访问:
# 启动cd /opt/module/hive;bin/beeline -u jdbc:hive2://hadoop102:10000 -n root
# 连接上hive!connect jdbc:hive2://hadoop102:10000
# 退出!quit
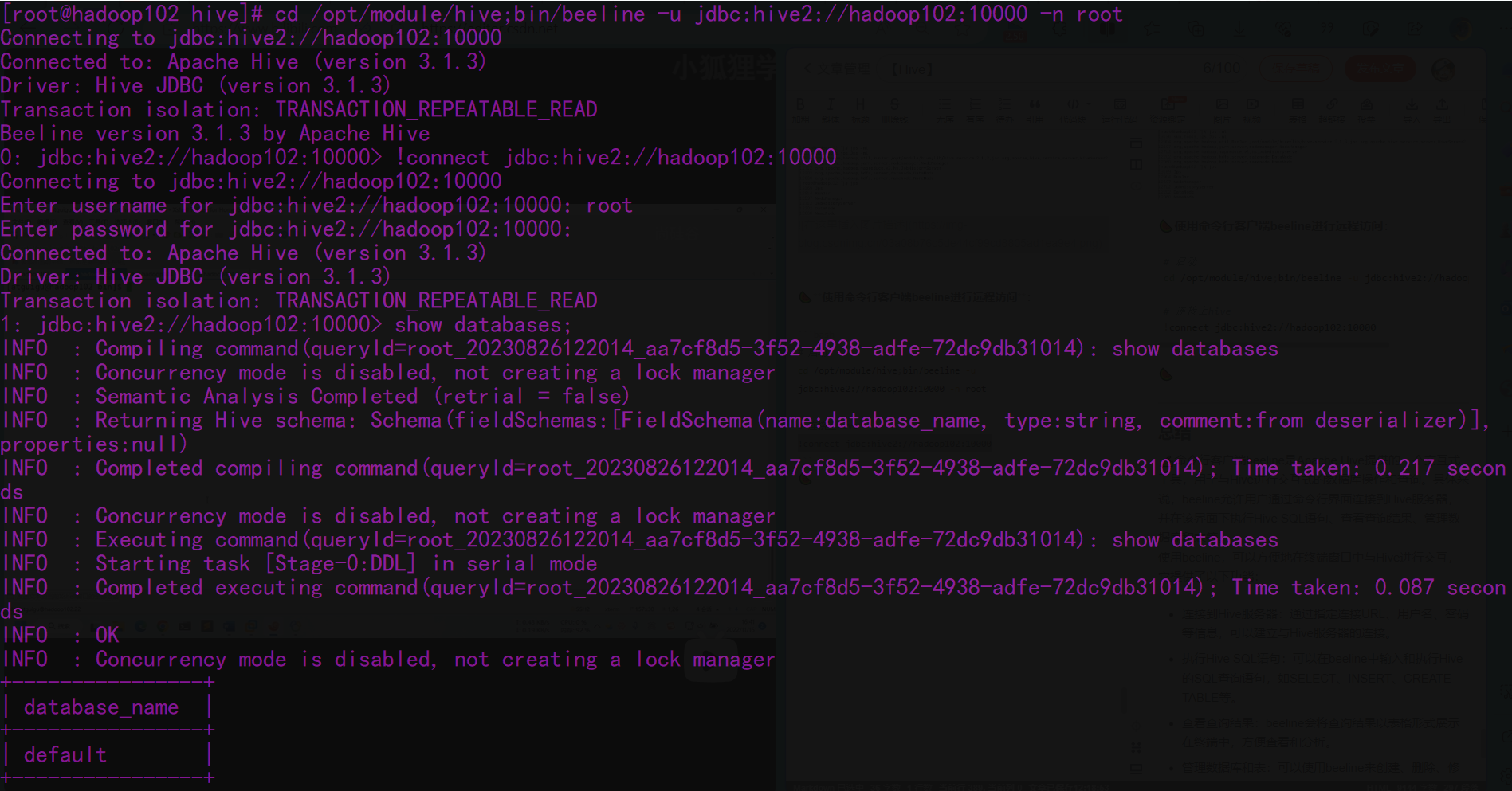
🍉使用Datagrip图形化客户端进行远程访问
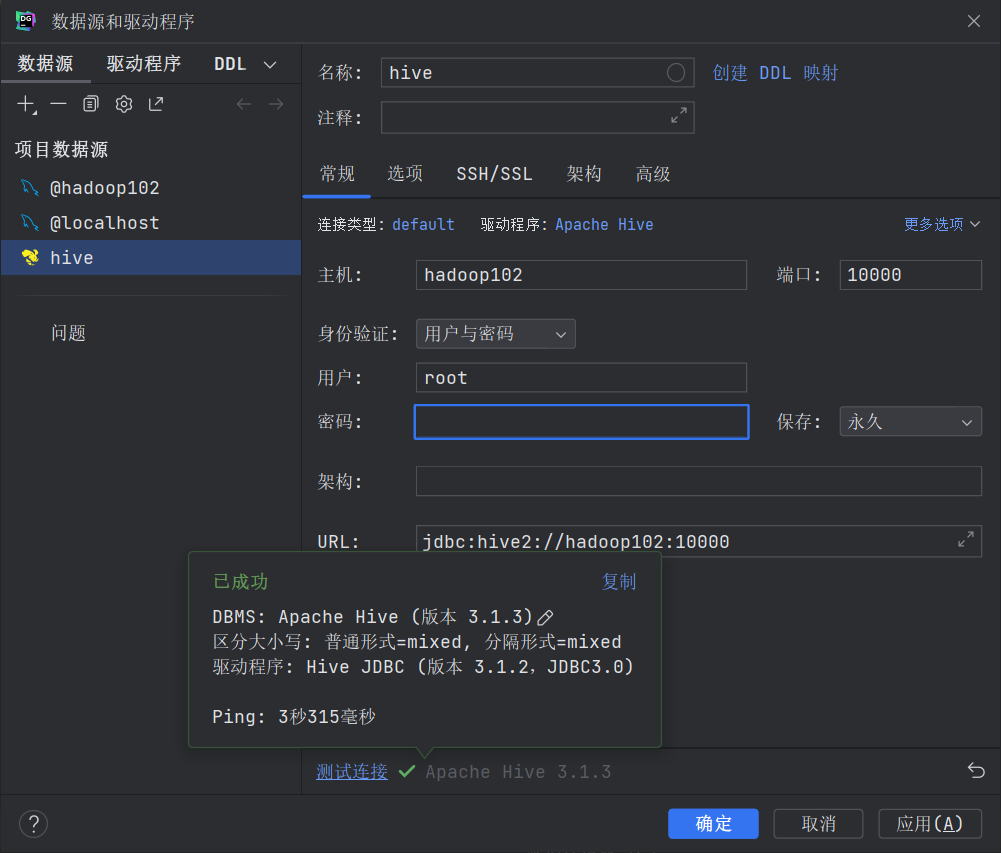
🤯如若测试连接失败,请检查主机名改成hadoop102没,以及👇

5.2. metastore服务
Hive的
metastore服务的作用是为
Hive CLI或者
Hiveserver2提供元数据访问接口
🍉metastore运行模式:分别为嵌入式模式和独立服务模式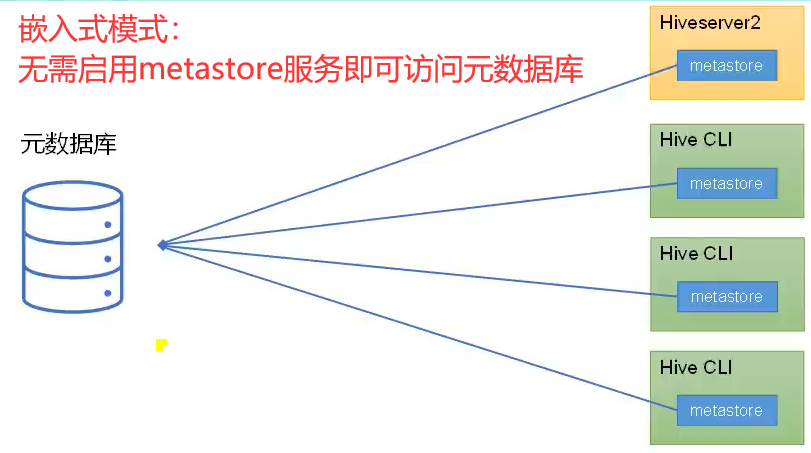
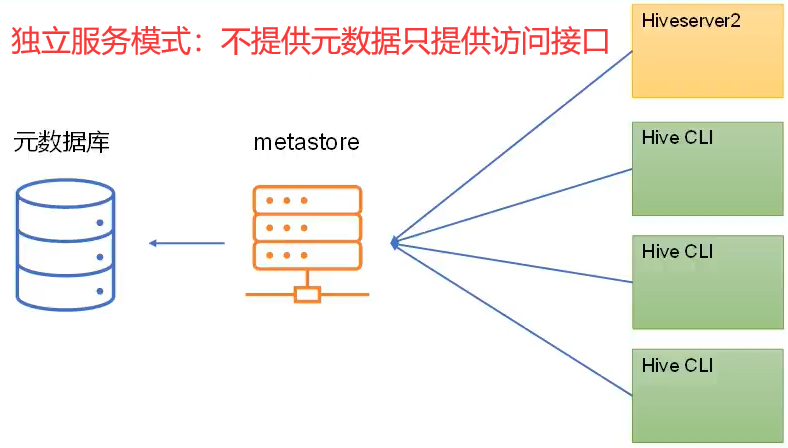
生产环境中,不推荐使用嵌入式模式。因为其存在以下两个问题:
1️⃣嵌入式模式下,每个Hive CLI都需要直接连接元数据库,当Hive CLI较多时,数据库压力会比较大。
2️⃣每个客户端都需要用户元数据库的读写权限,元数据库的安全得不到很好的保证。
🍉metastore部署
- 嵌入式模式:只需保证Hiveserver2和每个
Hive CLI的配置文件hive-site.xml中包含连接元数据库所需要的以下参数即可
<!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property>
- 独立服务模式
1️⃣首先,保证metastore服务的配置文件hive-site.xml中包含连接元数据库所需的以下参数
<!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property>
2️⃣其次,保证Hiveserver2和每个
Hive CLI
的配置文件
hive-site.xml
中包含访问metastore服务地址:
<!-- 指定metastore服务的地址 --><property><name>hive.metastore.uris</name><value>thrift://hadoop102:9083</value></property>
注意:主机名需要改为metastore服务所在节点,端口号无需修改,metastore服务的默认端口就是9083
🍉独立服务模式测试(102部署服务,103客户端)
# 将hive拷贝到103scp-r /opt/module/hive/ hadoop103:/opt/module/
# 在102上启动metastorenohup hive --service metastore &# 查看启动情况
jps -ml# 修改103上hive-site.xml文件,删除服务端相关代码,添加访问metastore服务地址ssh hadoop103
cd /opt/module/hive;vim conf/hive-site.xml
# 103启动hive
hive
show tables;
关闭102服务之后,103不能查询到数据库,因为设置了连接服务地址
6.Hive使用技巧

6.1. Hive常用交互命令
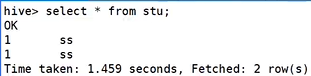
6.2. Hive常用非交互命令(无需启动hive)
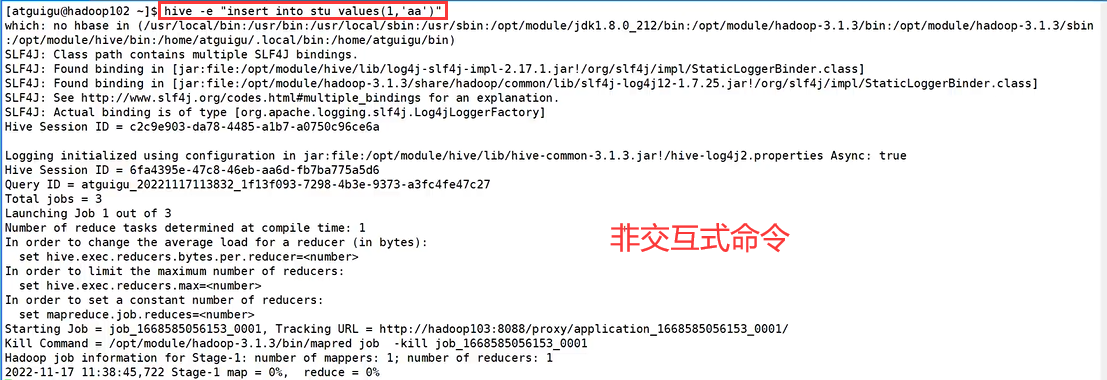
# 执行语句
hive -e"select * from stu"# 执行sql文件
hive -f stu.sql
6.3. hive参数配置方式
🍉查看当前所有的配置信息:
set
🍉参数配置的三种方式:
- 配置文件方式:用户自定义配置文件
hive-site.xml,用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效 - 命令行参数方式:启动Hive时,可以在命令行添加
-hiveconf param=value来设定参数,仅对本次Hive启动有效
bin/hive -hiveconfmapreduce.job.reduces=10;# 查看配置情况
hive (default)>set mapreduce.job.reduces;
- 参数声明方式:可以在HQL中使用SET关键字设定参数,仅对本次Hive启动有效
hive (default)>setmapreduce.job.reduces=10;# 查看配置情况
hive (default)>set mapreduce.job.reduces;
上述三种设定方式的优先级依次递增。即
配置文件 < 命令行参数 < 参数声明。注意某些系统级的参数,例如
log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了
6.4. Hive常见属性配置
🍉如何在Hive客户端显示当前库和表头?在
hive-site.xml
中加入如下两个配置
<property><name>hive.cli.print.header</name><value>true</value><description>Whether to print the names of the columns in query output.</description></property><property><name>hive.cli.print.current.db</name><value>true</value><description>Whether to include the current database in the Hive prompt.</description></property>
🍉Hive运行日志路径配置:Hive 的 log 默认存放在
/tmp/root/hive.log
目录下(当前用户名下)
,修改Hive 的 log存放日志到
/opt/module/hive/logs
# 修改/opt/module/hive/conf/hive-log4j2.properties.template文件名称为hive-log4j2.propertiescd /opt/module/hive/conf
mv hive-log4j2.properties.template hive-log4j2.properties
# 在hive-log4j2.prope、、rties文件中修改log存放位置vim hive-log4j2.properties
property.hive.log.dir=/opt/module/hive/logs
🍉Hive的JVM堆内存设置:新版本的Hive启动的时候,默认申请的JVM堆内存大小为256M,JVM堆内存申请的太小,导致后期开启本地模式(内存就不够了),执行复杂的SQL时经常会报错:
java.lang.OutOfMemoryError: Java heap space
,因此最好提前调整一下
HADOOP_HEAPSIZE
这个参数
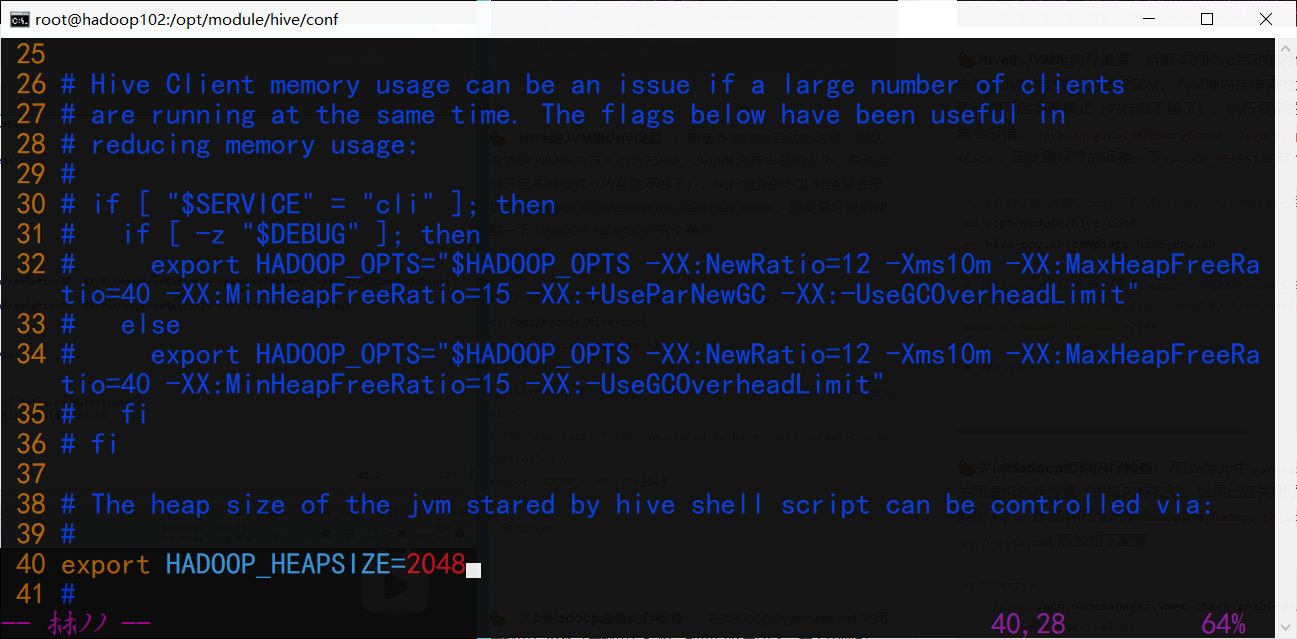
# 修改$HIVE_HOME/conf下的hive-env.sh.template为hive-env.shcd /opt/module/hive/conf
mv hive-env.sh.template hive-env.sh
# 将hive-env.sh其中的参数 export HADOOP_HEAPSIZE修改为2048,重启Hive# The heap size of the jvm stared by hive shell script can be controlled via:exportHADOOP_HEAPSIZE=2048
🍉关闭Hadoop虚拟内存检查(hadoop课程配置过):在hadoop中
yarn-site.xml
关闭虚拟内存检查(虚拟内存校验,如果已经关闭了,就不需要配了),修改前记得先停Hadoop:
myhadoop.sh stop
,在
yarn-site.xml
添加如下配置:
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
最后分发
yarn-site.xml
,并重启yarn
总结
✍命令行客户端beeline是Apache Hive提供的一个交互式工具,用于与Hive进行交互式的数据库操作和查询。具体来说,beeline允许用户通过命令行界面连接到Hive服务器,并在该界面下执行Hive SQL语句、查看查询结果、管理数据库和表等。
使用beeline,可以方便地在终端窗口中与Hive进行交互,它提供了以下功能:
- 连接到Hive服务器:通过指定连接URL、用户名、密码等信息,可以建立与Hive服务器的连接。
- 执行Hive SQL语句:可以在beeline中输入和执行Hive的SQL查询语句,如SELECT、INSERT、CREATE TABLE等。
- 查看查询结果:beeline会将查询结果以表格形式展示在终端中,方便查看和分析。
- 管理数据库和表:可以使用beeline来创建、删除、修改数据库和表的元数据信息。
- 支持命令历史和自动补全:beeline支持命令历史记录和命令自动补全功能,提高了用户的交互体验。
总结来说,beeline是一个用于在命令行界面下进行与Hive交互的工具,可以帮助用户方便地执行Hive查询和管理数据库操作
✍下一站,DDL、DML!
版权归原作者 欧叶冲冲冲 所有, 如有侵权,请联系我们删除。