
1、Spark On Yarn的本质
Spark专注于分布式计算;Yarn专注于资源管理。
Spark将资源管理的工作交给了Yarn来负责!
2、环境搭建和启动
环境搭建
1.修改spark-env.sh
cd /export/server/spark/conf
cp spark-env.sh.template spark-env.sh
vim /export/server/spark/conf/spark-env.sh
在最后面添加以下内容:
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"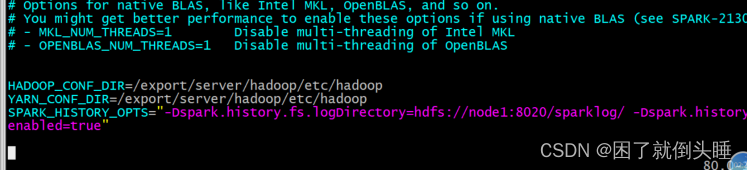
2.修改hadoop的yarn-site.xml
node1修改
cd /export/server/hadoop-3.3.0/etc/hadoop/
vim /export/server/hadoop-3.3.0/etc/hadoop/yarn-site.xml
在<configuration>下面添加以下内容:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
cd /export/server/hadoop/etc/hadoop
scp -r yarn-site.xml node2:$PWD
scp -r yarn-site.xml node3:$PWD
3.Spark设置历史服务地址
cd /export/server/spark/conf
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
添加以下内容:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/sparklog/
spark.eventLog.compress true
spark.yarn.historyServer.address node1:18080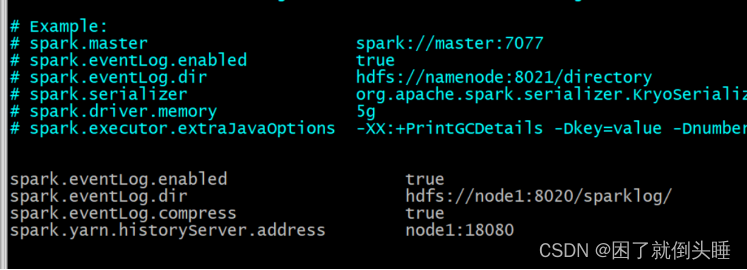
配置后, 需要在HDFS上创建 sparklog目录
hdfs dfs -mkdir -p /sparklog
设置日志级别:
cd /export/server/spark/conf
cp log4j.properties.template log4j.properties
vim log4j.properties
修改以下内容:
4.配置依赖spark jar包
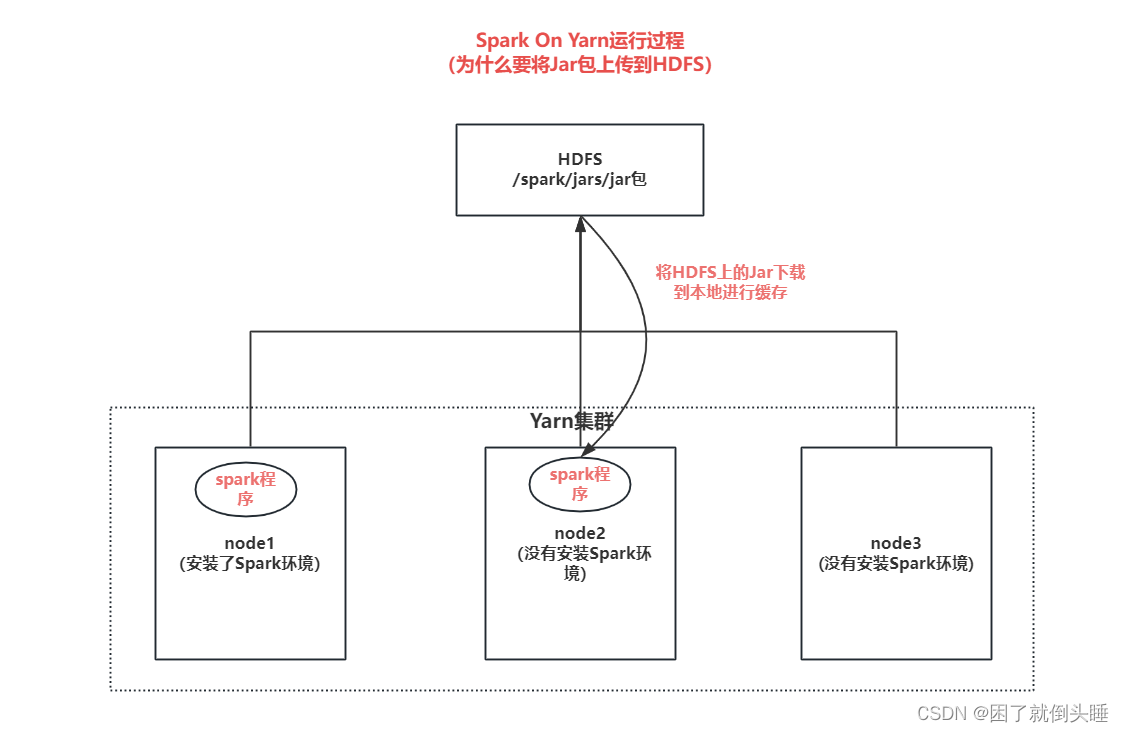
当Spark Application应用提交运行在YARN上时,默认情况下,每次提交应用都需要将依赖Spark相关jar包上传到YARN 集群中,为了节省提交时间和存储空间,将Spark相关jar包上传到HDFS目录中,设置属性告知Spark Application应用。
hadoop fs -mkdir -p /spark/jars/
hadoop fs -put /export/server/spark/jars/* /spark/jars/
修改spark-defaults.conf
cd /export/server/spark/conf
vim spark-defaults.conf
添加以下内容:
spark.yarn.jars hdfs://node1:8020/spark/jars/*
5.启动服务
Spark Application运行在YARN上时,上述配置完成
启动服务:HDFS、YARN、MRHistoryServer和Spark HistoryServer,命令如下:
重启HDFS和YARN服务,在node1执行命令
先stop-all.sh,再执行start-all.sh
注意:在onyarn模式下不需要启动start-all.sh(jps查看一下看到worker和master)
启动MRHistoryServer服务,在node1执行命令
mr-jobhistory-daemon.sh start historyserver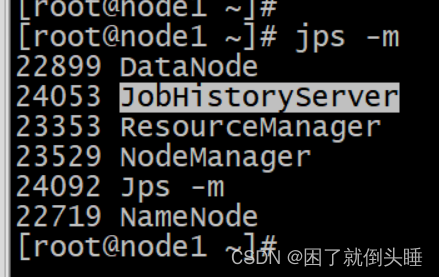
启动Spark HistoryServer服务,,在node1执行命令
/export/server/spark/sbin/start-history-server.sh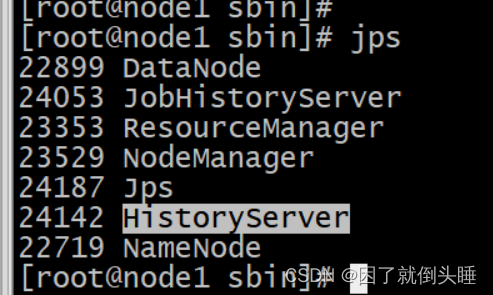
Spark HistoryServer服务WEB UI页面地址:
6.提交测试
先将圆周率PI程序提交运行在YARN上,命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
${SPARK_HOME}/examples/src/main/python/pi.py \
10
运行完成在YARN 监控页面截图如下:
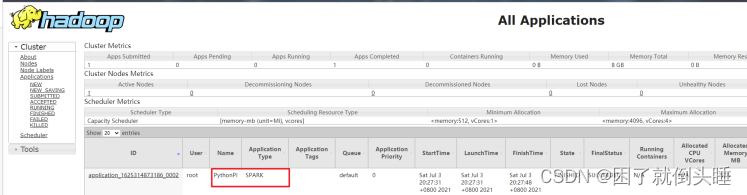
设置资源信息,提交运行pi程序至YARN上,命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--queue default \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
${SPARK_HOME}/examples/src/main/python/pi.py \
10
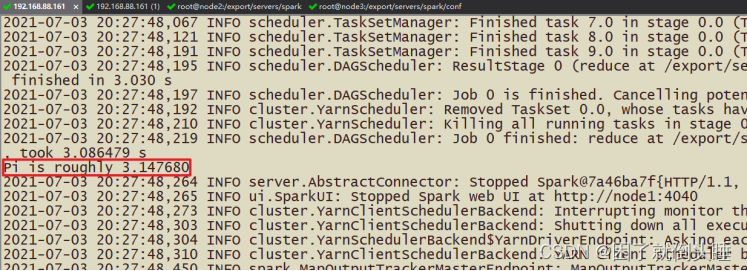
当pi应用运行YARN上完成以后,从8080 WEB 页面点击应用历史服务连接,查看应用运行状态信息。
扩展:Spark On Yarn运行过程,为什么需要将Jar包上传到HDFS
小技巧
1- vim相关快捷键:在文件中搜索关键词
输入/,然后输入关键词即可。按N进行跳转
2- 文件查找
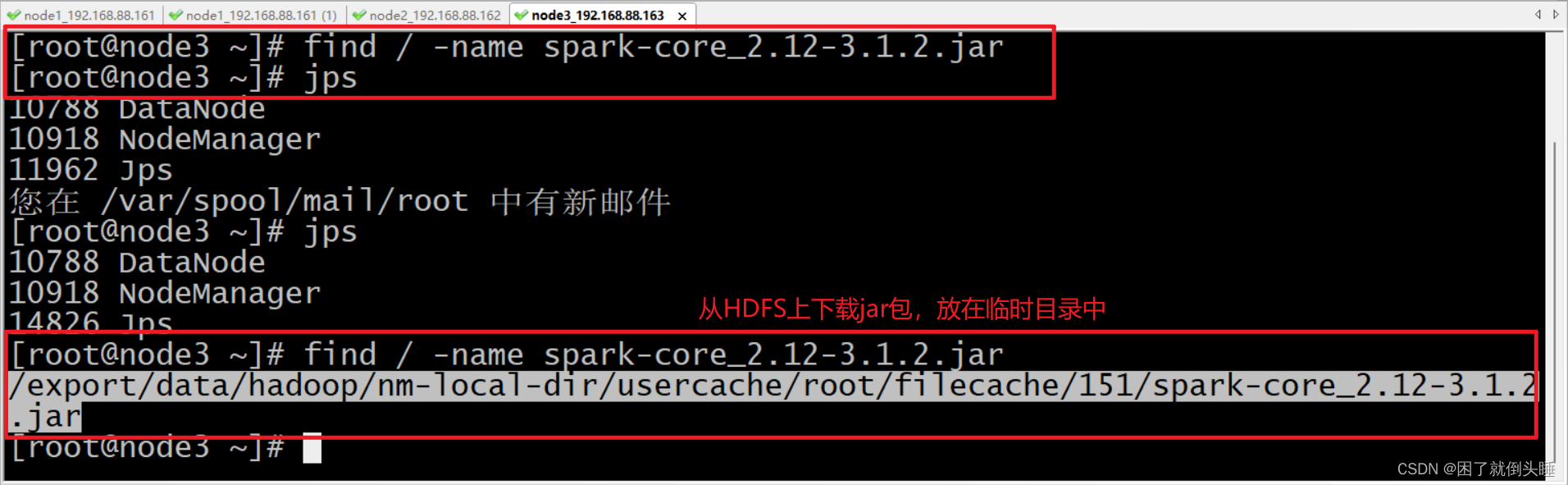
find / -name spark-core_2.12-3.1.2.jar
在服务器上查找spark-core_2.12-3.1.2.jar文件,
默认配完环境后只有node1有,当node2,node3运行spark_on_yarn程序的时候,会自动从hdfs下载对应的jar包
启动sparkonyarn
注意:
配置完环境后需要先stop-all.sh停止,再重新启动服务生效
相比原理hadoop集群,需要多启动一个spark的自己的历史服务,它是依赖hadoop的历史服务的!
[root@node1 ~]# start-all.sh
[root@node1 ~]# mapred --daemon start historyserver
[root@node1 ~]# /export/server/spark/sbin/start-history-server.sh
[root@node1 ~]# jps
5570 HistoryServer
3555 DataNode
5460 JobHistoryServer
4199 NodeManager
4008 ResourceManager
3369 NameNode
29324 Jps
[root@node1 bin]#
3、提交应用验证环境
测试提交官方示例圆周率
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
${SPARK_HOME}/examples/src/main/python/pi.py \
10
测试提交自定义python类
将编写的WordCount的代码提交到Yarn平台运行
- 注意1:需要修改setMaster的参数值为yarn,或者直接将setMaster代码删除
- 注意2:需要将代码中和文件路径相关的内容改成读写分布式文件系统,例如:HDFS。因为程序是分布式运行的,我们无法确保每台节点上面都有相同的本地文件路径,会导致报错。
cd /export/server/spark/bin
./spark-submit --master yarn \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
/export/data/spark_project/spark_base/05_词频统计案例_spark_on_yarn运行.py
# 注意:py代码文件路径改成自己的linux对应py文件路径!!!
4、如何查看日志
日志用途:主要用于排查问题
- 通过Spark提供的18080日志服务器查看, 推荐使用
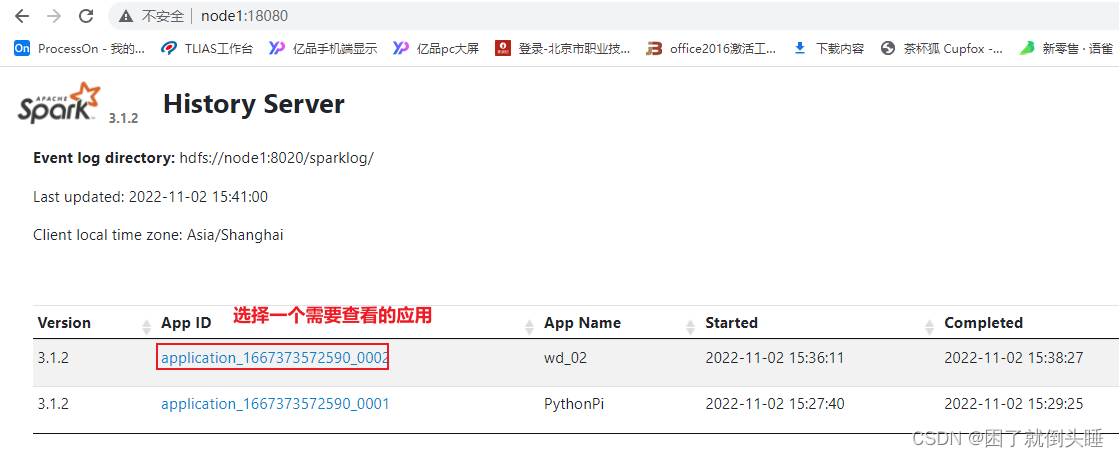
直接查看对应executor的日志
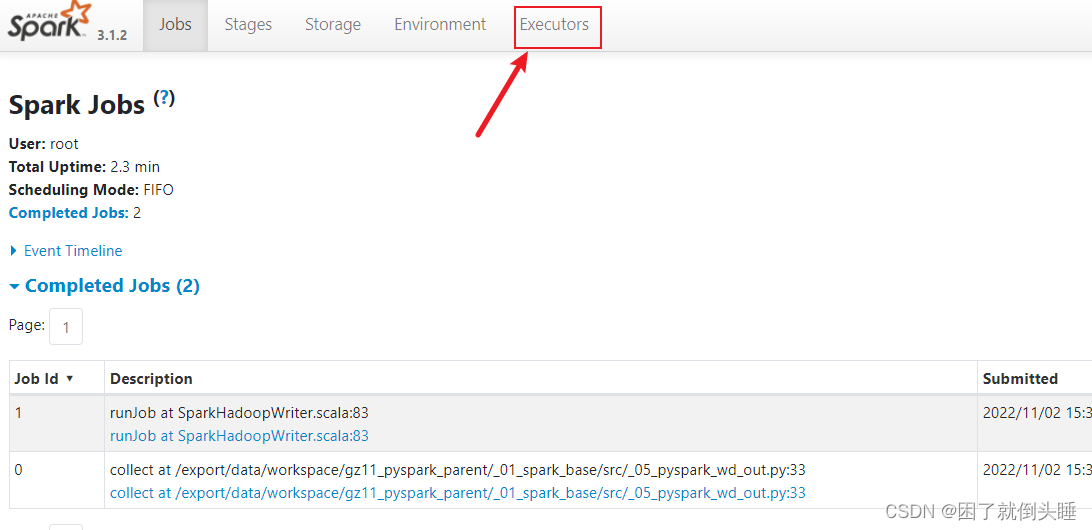
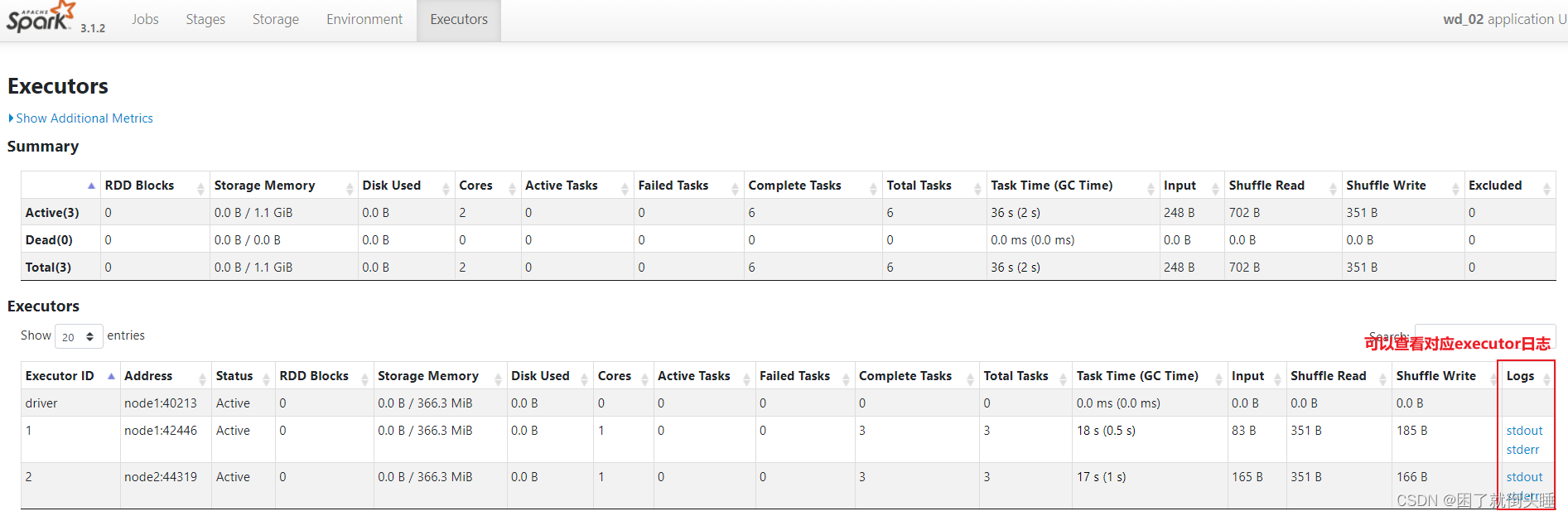
发现不管是进程还是线程,日志内容都很少。原因如下:
1- 因为在进行环境部署的时候将日志级别,由INFO变成了WARN级别
2- 和部署方式有关。
查看对应线程的日志
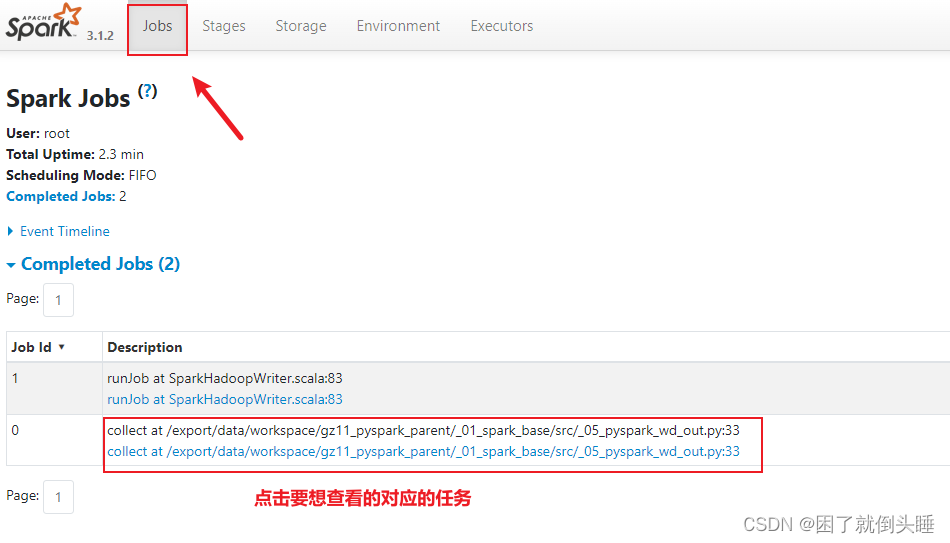
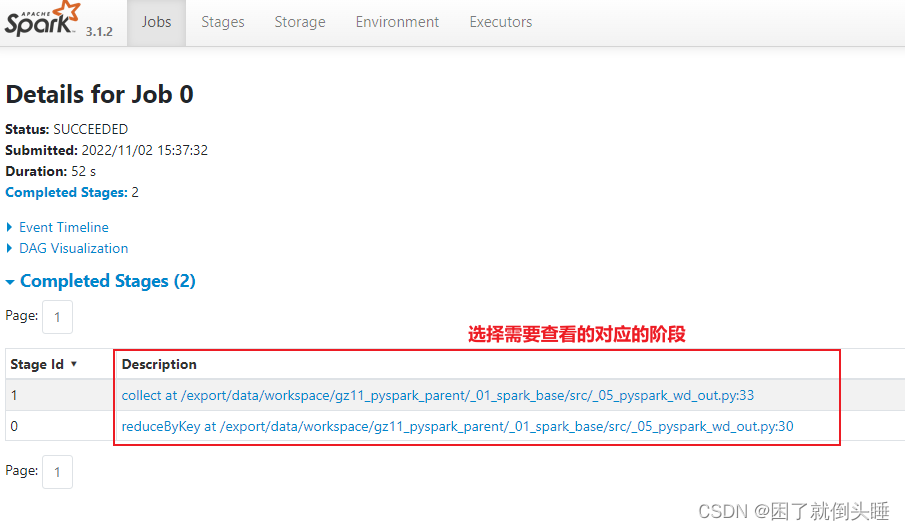
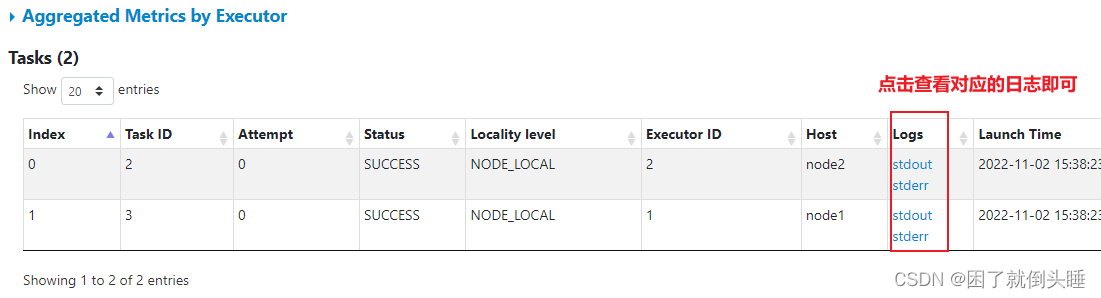
还可以通过Yarn的8088界面查看日志
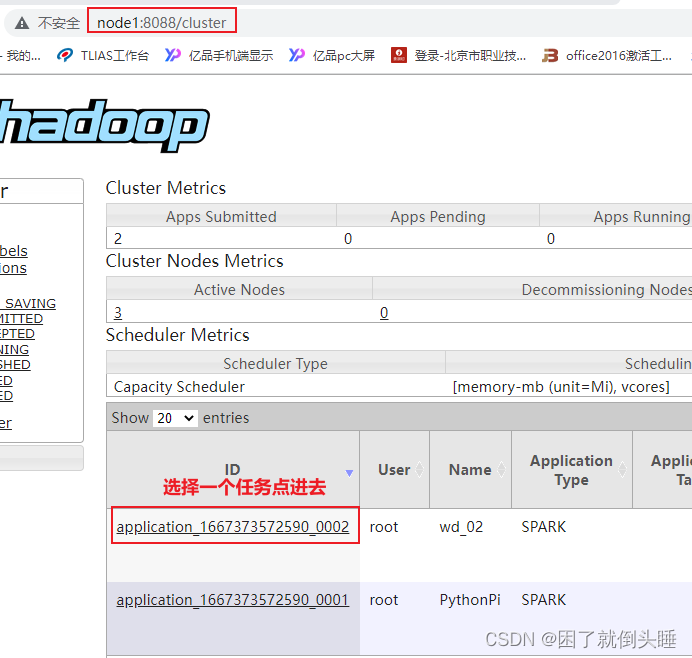
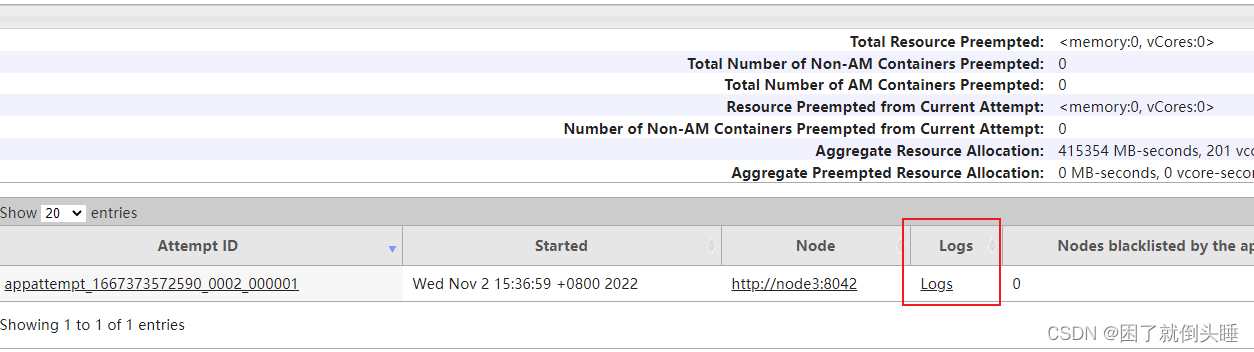
点进去后, 如果日志比较多, 也可以点击查看详细日志

5、Spark On Yarn两种部署方式
Spark中有两种部署方式,Client和Cluster方式,默认是Client方式。这两种方式的本质区别,是Driver进程运行的地方不一样。
Client部署方式: Driver进程运行在你提交程序的那台机器上
优点: 将运行结果和运行日志全部输出到了提交程序的机器上,方便查看结果
缺点: Driver进程和Yarn集群可能不在同一个集群中,会导致Driver和Executor进程间进行数据交换的时候,效率比较低
使用: 一般用在开发和测试中
Cluster部署方式: Driver进程运行在集群中某个从节点上
优点: Driver进程和Yarn集群在同一个集群中,Driver和Executor进程间进行数据交换的时候,效率比较高
缺点: 需要去18080或者8088页面查看日志和运行结果
使用: 一般用在生产环境使用
演示操作:
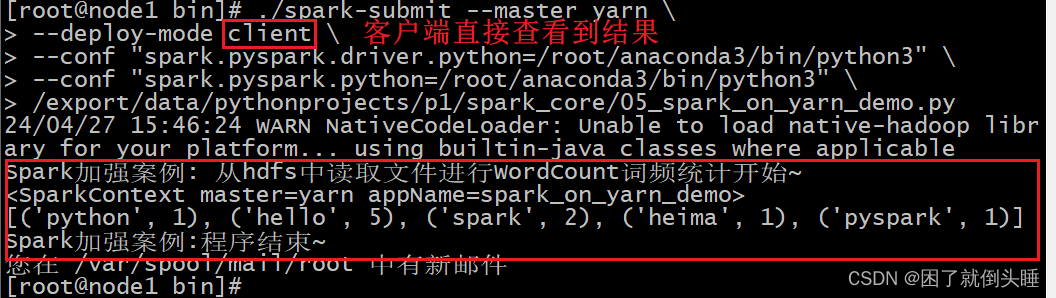
client模式:
./spark-submit --master yarn \
--deploy-mode client \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
/export/data/spark_project/spark_base/05_词频统计案例_spark_on_yarn运行.py
# 注意:py代码文件路径改成自己的linux虚拟机中的对应py文件路径!!!

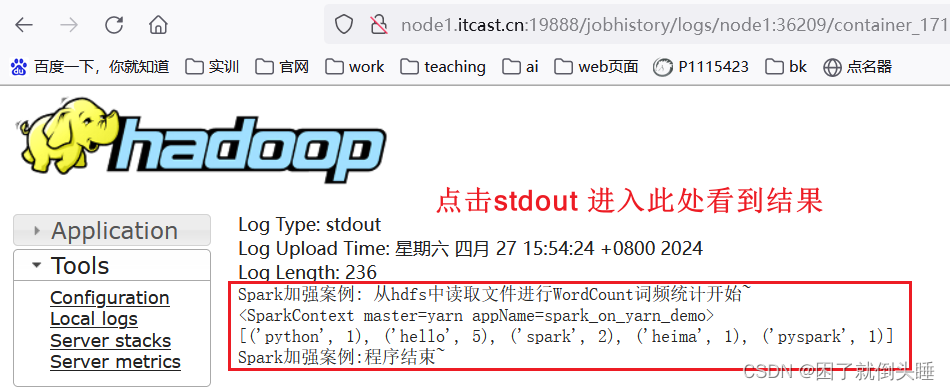
cluster模式
./spark-submit --master yarn \
--deploy-mode cluster \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
/export/data/spark_project/spark_base/05_词频统计案例_spark_on_yarn运行.py
# 注意:py代码文件路径改成自己的linux对应py文件路径!!!


观察两种模式结果区别?
client模式: driver一直是node1(客户端) 运行输出结果在node1窗口直接输出
cluter模式: driver是集群节点中切换 运行输出结果在driver对应stdout日志展示出
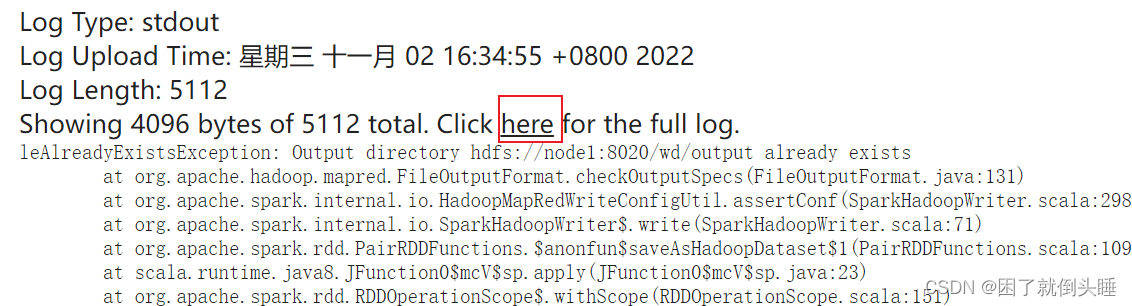
如果输出内容不是直接打印而是到hdfs,有可能报错,看日志可以从以下位置找:
版权归原作者 困了就倒头睡 所有, 如有侵权,请联系我们删除。