
第1关 基本查询的学习
查询语句SELECT
以下是MySQL数据库中查询数据通用的
SELECT
语法:
SELECT column_name1,column_name2 FROM table_name [WHERE Clause] [OFFSET M ] [LIMIT N]
- 查询语句中可以指定一个或者多个表,表之间使用逗号
,分割,并使用WHERE语句来设定查询条件 SELECT命令可以读取一条或者多条记录- 可以使用星号
*来代替字段,返回表所有字段的数据 - 可以使用
LIMIT属性来设定返回的记录数。
头歌实验
本关的应用场景是企业员工数据库的查询。本关你将自己动手完成对一个真实的员工数据库
YGGL
的查询:
- 查找财务部年龄不低于所有研发部雇员年龄的雇员姓名、编号和性别。
- 查找财务部收入在
5200元以上的雇员姓名及其薪水收入支出情况。
上述查询功能需要你掌握
SELECT
语句的基本语法、掌握子查询、连接查询的表示方法。下面就是对这些内容的详细教程,请先仔细阅读。
相关知识
查询语句SELECT
以下是MySQL数据库中查询数据通用的
SELECT
语法:
SELECT column_name1,column_name2 FROM table_name [WHERE Clause] [OFFSET M ] [LIMIT N]
- 查询语句中可以指定一个或者多个表,表之间使用逗号
,分割,并使用WHERE语句来设定查询条件 SELECT命令可以读取一条或者多条记录- 可以使用星号
*来代替字段,返回表所有字段的数据 - 可以使用
LIMIT属性来设定返回的记录数。
命令行的操作
首先我们来通过命令行操作复习上一阶段所学内容吧!
下面几个表来自于我们用于实验的员工管理系统的数据库
YGGL
,通过命令行新建数据库数据表并插入数据吧!
CREATE DATABASE YGGL;
使用数据库:
use YGGL;
员工信息表
emp
表结构:
列名数据类型长度是否允许为空值说明eidchar6否员工编号,主键enamechar10否姓名birthdate否生日sexint1否性别addrchar20是地址zipchar6是邮编telchar12是电话号码didchar3否部门编号,外键
create table emp(eid char(6) NOT NULL PRIMARY KEY,ename char(10) NOT NULL,birth date NOT NULL,sex int(1) NOT NULL,addr char(20) NULL,zip char(6) NULL,tel char(12) NULL,did char(3) NOT NULL);
数据样本:
eidenamebirthsexaddrzipteldid001wl1971-01-231zsl210003123456682008wrh1981-03-281bjdl210001123456211010wxr1987-12-091spl210006123456611018ll1965-07-300zsdl210002123456011201lm1977-10-181hjl210013123456085208zj1970-09-281plx210004123456175991zm1984-08-100zsl210003123456223006zsb1979-10-011jfl210010123456185678lt1982-04-021zsbl210008123456363566lym1973-09-201rhl210001123456914759yf1983-11-181bjxl210002123456014209cll1974-09-030hzl210018123456584
insert into emp values('001','wl','1971-01-23',1,'zsl','210003','12345668','2'),('008','wrh','1981-03-28',1,'bjdl','210001','12345621','1'),('010','wxr','1987-12-09',1,'spl','210006','12345661','1'),('018','ll','1965-07-30',0,'zsdl','210002','12345601','1'),('201','lm','1977-10-18',1,'hjl','210013','12345608','5'),('208','zj','1970-09-28',1,'plx','210004','12345617','5'),('991','zm','1984-08-10',0,'zsl','210003','12345622','3'),('006','zsb','1979-10-01',1,'jfl','210010','12345618','5'),('678','lt','1982-04-02',1,'zsbl','210008','12345636','3'),('566','lym','1973-09-20',1,'rhl','210001','12345691','4'),('759','yf','1983-11-18',1,'bjxl','210002','12345601','4'),('209','cll','1974-09-03',0,'hzl','210018','12345658','4');
部门信息表
dept
表结构:
列名数据类型长度是否允许为空值说明didchar3否部门编号,主键dnamechar20否部门名notevarchar100是备注
create table dept(did char(3) NOT NULL PRIMARY KEY,dname char(20) NOT NULL,note varchar(100) NULL);
数据样本:
diddnamenote说明1cwbNULL财务部2rlzybNULL人力资源部3jlbgsNULL经理办公室4yfbNULL研发部5scbNULL市场部
insert into dept values('1','cwb',NULL),('2','rlzyb',NULL),('3','jlbgs',NULL),('4','yfb',NULL),('5','scb',NULL);
工资表
sal
表结构:
列名数据类型长度是否允许为空值说明eidchar6否员工编号,主键incomeint8否收入outcomeint8否支出
create table sal(eid char(6) NOT NULL PRIMARY KEY,income int(8) NOT NULL,outcome int(8) NOT NULL);
数据样本:
eidincomeoutcome001510011230084582108820155691185006498710792095066110856659801210991625912810105860119801853471180759553111996785240112120849801100
insert into sal values('001',5100,1123),('008',4582,1088),('201',5569,1185),('006',4987,1079),('209',5066,1108),('566',5980,1210),('991',6259,1281),('010',5860,1198),('018',5347,1180),('759',5531,1199),('678',5240,1121),('208',4980,1100);
查询每个雇员的所有数据:
select * from emp;
查询每个雇员的地址和电话:
select ename,addr,tel from emp;
查询
eid
为
001
的雇员地址和电话:
select ename,addr,tel from emp where eid='001';
查询
emp
中所有女雇员的地址和电话,使用
as
子句将结果中各列的标题分别指定为地址和电话:
select ename as fname,addr as faddr,tel as ftel from emp where sex=0;
计算每个雇员的实际收入:
select did,income-outcome as money from sal;
找出所有姓名是
w
开头的雇员的部门号:
select did from emp where name like 'w%';
%表示任意符号
找出所有收入在5000-6000之间的雇员号码:
select eid from sal where income between 5000 and 6000;
BETWEEN运算符用于WHERE表达式中,选取介于两个值之间的数据范围。BETWEEN同AND一起搭配使用。通常value1应该小于value2。当 BETWEEN 前面加上NOT运算符时,表示与BETWEEN相反的意思,即选取这个范围之外的值。
子查询的使用
所谓子查询,即在查询语句中内嵌其他查询语句。下面,我们仍继续在命令行的操作中学习。
查找在
cwb
工作的雇员情况:
select * from emp where did=(select did from dept where dname='cwb');
连接查询的使用
比如查询每个雇员的薪水情况,但是我们要返回雇员的姓名,而在sal表中没有雇员姓名,这个时候就需要我们通过员工编号连接emp和sal两张表。
select emp.ename,sal.income from emp,sal where emp.eid=sal.eid;
一些关键字
any关键字:
假设
any
内部的查询语句返回的结果个数是三个,那么:
select ...from ... where a > any(...)
等价于
select ...from ... where a > result1 or a > result2 or a > result3
ALL
关键字与
any
关键字类似,但其含义不同,相当于上面的
or
改成
and
。
some
关键字和
any
关键字是一样的功能。
IN运算符用于WHERE表达式中,以列表项的形式支持多个选择
WHERE column IN (value1,value2,...)WHERE column NOT IN (value1,value2,...)
当
IN
前面加上
NOT
运算符时,表示与
IN
相反的意思,即不在这些列表项内选择。
UNION操作符用于连接两个以上的SELECT语句的结果组合到一个结果集合中。 1.SELECT expression_1,expression_2,...,expression_n FROM tables [WHERE conditions]2.UNION [ALL | DISTINCT]3.SELECT expression_1,expression_2,...,expression_n FROM tables[WHERE conditions];参数expression_1,expression_2, ...expression_n是要检索的列,tables是要检索的数据表,WHERE conditions是检索条件,DISTINCT是删除结果集中重复的数据。默认情况下UNION操作符已经删除了重复数据,所以DISTINCT修饰符对结果没啥影响。而ALL可以返回所有结果集,包含重复数据。
编程要求
编写查询语句,实现对数据库
YGGL
(包括表
emp
、
dept
和
sal
)的相关查询:
查询一:使用子查询的方法,查找财务部
cwb
年龄不低于所有研发部
yfb
雇员年龄的雇员姓名
ename
、编号
eid
和性别
sex
。
查询二:使用连接查询的方式,查找财务部
cwb
收入
income
在5200元以上的雇员姓名
ename
及其薪水收入
income
支出
outcome
情况。
//请在下面补齐查询一的MySQL语句
/*********begin*********/
select ename,eid,sex from emp
where did in
(select did from dept
where dname='cwb'
)
/*********end*********/
and
birth<=all
(select birth from emp
where did in
(select did from dept
where dname='yfb'
)
);
//请在下面输入查询二的MySQL语句
/*********begin*********/
select ename,income,outcome
from emp,sal,dept
where emp.eid=sal.eid and
emp.did=dept.did and
dname='cwb' and income>5200;
/*********end*********/
第2关 深入学习查询语句
MySQL聚集函数
函数说明COUNT()返回某列的行数MAX()返回某列最大值MIN()返回某列最小值AVG()返回某列平均值SUM()返回某列值之和
头歌实验
本关的应用场景是企业员工数据库的查询。上一关中简单的查询满足不了需求,比如:
- 求财务部雇员的总人数;
- 求各部门的雇员数;
- 将各雇员的姓名按收入由低到高排列。
上述查询功能需要你掌握数据汇总、掌握GROUP BY和ORDER BY子句的作用和使用方法。下面就是对这些内容的详细教程,请先仔细阅读。
相关知识
首先我们还是使用命令行操作登录数据库系统,创建数据库
YGGL
、创建数据表
emp
、
dept
和
sal
并插入数据。
MySQL聚集函数
函数说明COUNT()返回某列的行数MAX()返回某列最大值MIN()返回某列最小值AVG()返回某列平均值SUM()返回某列值之和
求财务部雇员的平均收入:
select avg(income) as avgincomefrom salwhere eid in(select eidfrom empwhere did=(select didfrom deptwhere dname='cwb'));
GROUP BY 和 ORDER BY 子句的使用
GROUP BY语句根据一个或多个列对结果集进行分组。
SELECT column_name, function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name;
如果我们需要对读取的数据进行排序,我们就可以使用MySQL的ORDER BY子句来设定你想按哪个字段哪种方式来进行排序,再返回搜索结果。
SELECT field1, field2,...,fieldN table_name1,table_name2..., ORDER BY field1,[field2...] [ASC [DESC]]
- 你可以设定多个字段来排序。
- 你可以使用
ASC(升序)或DESC(降序) 关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列。 - 你可以添加
WHERE...LIKE子句来设置条件。
编程要求
在右侧代码窗口区域的指定位置编写查询语句,实现对数据库
YGGL
(包括表
emp
、
dept
和
sal
)的相关查询:
查询一:求财务部雇员的总人数;
查询二:求各部门的雇员数;
查询三:将各雇员的姓名按收入由低到高排列(提示:使用连接查询)。
//请在下面输入查询一的MySQL语句
/*********begin*********/
select count(eid)
from emp
where did=
(select did
from dept
where dname='cwb');
/*********end*********/
//请在下面输入查询二的MySQL语句
/*********begin*********/
select count(eid)
from emp
group by did;
/*********end*********/
//请在下面输入查询三的MySQL语句
/*********begin*********/
select emp.ename
from emp,sal
where emp.eid=sal.eid
order by income;
/*********end*********/
第3关 视图的创建和使用
查看数据库中表的情况:
show tables;
头歌实验
本关的应用场景是企业员工数据库的查询。视图也是为了实现多样地查看表中的数据,比如限制财务部的经理只能看到财务部的信息。本关你创建
cx_sal
视图并使用该视图查看财务部雇员薪水情况。你需要掌握视图的使用方法~
相关知识
首先我们还是使用命令行操作登录数据库系统,创建数据库
YGGL
、创建数据表
emp
、
dept
和
sal
并插入数据。
现在,你输入以下代码查看数据库中表的情况:
show tables;
限制查看雇员的某些情况:
create or replace view cx_empasselect eid,ename,birth,sex,didfrom emp;
创建该视图后,我们可以在数据库中查看所有的表,是不是变成了下面这样?
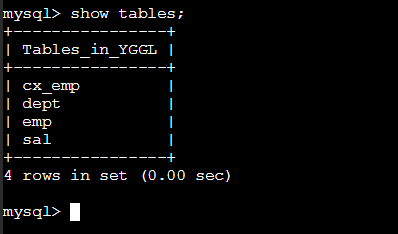
接下来我们输入下面的命令来查看该视图:
select * from cx_emp;
为了了解视图的特性,我们向视图
cx_emp
中插入一条记录:
eidenamebirthsexdid888zhj1983-09-2513
现在,我们查看一下
emp
表,你是不是已经成功把这条记录插入到
emp
表中了呢?这就是视图,原表和视图之间是同步的。
接下来请你尝试以下操作。
将
zhj
从经理办公室(部门编号
3
)转到市场部(部门编号为
5
):
update cx_emp set did='5'where ename='zhj';
请你再次查看
emp
表核查是否修改成功。
编程要求
请你思考,我们想限制各部门的经理只能查找本部雇员的薪水情况该怎么操作呢?比如财务部,只让财务部的经理查看本部门雇员姓名和收入、支出情况。
请你创建
cx_sal
视图并使用该视图查看财务部雇员薪水情况
ename
、
income
和
outcome
。
//请在下面输入创建cx_sal的视图的MySQL语句
/*********begin*********/
create or replace view cx_sal
as
select ename,income,outcome
from emp,sal,dept
where emp.eid=sal.eid and
emp.did=dept.did and
dname='cwb';
/*********end*********/
//请在下面输入查询财务部雇员薪水情况视图的MySQL语句
/*********begin*********/
select * from cx_sal;
/*********end*********/
第4关 索引和完整性
索引
索引是根据表中一列或若干列按照一定的顺序建立的列值与记录行之间的对应关系表。在列上创建了索引之后,查找数据是可以直接根据该列上的索引找到对应行的位置,从而快速找到数据。
索引类型分成下列几个:
- 普通索引(INDEX):基本索引类型
- 唯一性索引(UNIQUE):该列的所有值没有重复
- 主键(PRIMARY KEY):一种唯一性索引,一个表只能有一个主键
- 全文索引(FLLTEXT):只能在varchar或text类型上创建
头歌实验
任务描述
经理觉得查找数据的速度偏慢、精度较低,这个时候,你需要创建索引来使查询的速度更快,使用完整性来提高查询精度。
上述查询功能需要你掌握索引的使用方法、理解数据完整性的概念及分类、掌握各种数据完整性的实现方法。下面就是对这些内容的详细教程,请先仔细阅读。
背景知识
索引
索引是根据表中一列或若干列按照一定的顺序建立的列值与记录行之间的对应关系表。在列上创建了索引之后,查找数据是可以直接根据该列上的索引找到对应行的位置,从而快速找到数据。
索引类型分成下列几个:
- 普通索引(INDEX):基本索引类型
- 唯一性索引(UNIQUE):该列的所有值没有重复
- 主键(PRIMARY KEY):一种唯一性索引,一个表只能有一个主键
- 全文索引(FLLTEXT):只能在varchar或text类型上创建
语法格式:
//创建CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名称 ON 表名{字段名称[(长度)] [ASC|DESC]}//修改ALTER TABLE tbl_name ADD [UNIQUE|FULLTEXT|SPATIAL] INDEX索引名称(字段名称[(长度)][ASC|DESC]);
下面我们用命令行操作试一试。
在创建好整个数据库的基础上,对
YGGL
数据库的
emp
表的
ename
列建立索引:
create index emp_name_idxon emp(ename);
查看是否创建成功:
show index from emp;
重命名索引:
alter index emp_name_idxrename to emp_idx;
删除索引:
drop index emp_idex;
数据完整性
为了防止不合规定的数据进入基表中,我们定义完整性规则。分为:域完整性、实体完整性和参照完整性。
域完整性
域完整性又叫列完整性,主要是对一列的数据进行约束。比如
emp
中限定
sex
的值只能为
1
和
2
中的一个,可以在创建表时将
sex
做以下定义:
sex int(1) check(sex='1' or sex='2') NOT NULL,
或者在所有字段定义完成后加一句:
constraint ch_sex check(sex='1' or sex='2')
下面,我们在命令行中通过修改表的方式创建约束:
alter table empadd(constraint ch_sex check(sex='1' or sex='2'));
删除约束:
alter table empdrop constraint ch_sex;
实体完整性
又叫行完整性,要求每一行都有一个唯一的标识符。比如
emp
中的员工
eid
是唯一的,才能唯一确定某一个人。通过
unique
约束和
primary key
约束可以实现实体完整性。
同样的,在创建表时对
tel
创建约束应该将
tel
定义为:
tel char(12) NULL constraint un_tel unique,
下面我们在命令行中通过修改表的方式创建约束:
alter table empadd constraint un_tel unique(tel);
参照完整性
又叫引用完整性,它保证主表和从表中的数据一致性,实现方式是定义外键与主键。例如
emp
和
sal
表,
eid
在
emp
中是外键,而在
sal
中
eid
定义为主键。
- 从表不能引用主表不存在的键值
- 主表中的值更改了,则从表中所有引用都也要修改
- 若要删除主表中的记录,应先删除从表中匹配的记录
如果在创建
sal
表时想创建参照完整性使
emp
表中所有
eid
都要出现在
sal
中,可以在定义
emp
的
eid
时这样定义:
eid char(6) NOT NULL references sal(eid),
下面我们在命令行中通过修改表的方式定义:
alter table empadd constraint sal_id foreign key(eid)references sal(eid);
编程要求
在已经创建好整个
YGGL
数据库的基础上进行以下操作:
建立索引
pk_xs_bak
:对
emp
的
eid
建立索引;
实现域完整性
ch_tel
:为
emp
的
tel
建立
check
约束,其值只能为
0
的数字;9
实现实体完整性
:为un_dept
的dept
创建唯一性索引;dname
实现参照完整性
:将fk_emp
中的emp
列为外键。did
//请在下面输入创建索引的MySQL语句
/*********begin*********/
create index pk_xs_bak
on emp(eid);
/*********end*********/
//请在下面输入实现域完整性的MySQL语句
/*********begin*********/
alter table emp
add(constraint ch_tel check(tel between 0 and 9));
/*********end*********/
//请在下面输入实现实体完整性的MySQL语句
/*********begin*********/
alter table dept
add constraint un_dept unique(dname);
/*********end*********/
//请在下面输入实现参照完整性的MySQL语句
/*********begin*********/
alter table emp
add constraint sal_id foreign key(eid)
references sal(eid);
/*********end*********/
版权归原作者 椅糖 所有, 如有侵权,请联系我们删除。