
第一章环境准备
1.1 建表语句
hive>
-- 创建学生表
DROP TABLE IF EXISTS student;
create table if not exists student_info(
stu_id string COMMENT '学生id',
stu_name string COMMENT '学生姓名',
birthday string COMMENT '出生日期',
sex string COMMENT '性别'
)
row format delimited fields terminated by ','
stored as textfile;
-- 创建课程表
DROP TABLE IF EXISTS course;
create table if not exists course_info(
course_id string COMMENT '课程id',
course_name string COMMENT '课程名',
tea_id string COMMENT '任课老师id'
)
row format delimited fields terminated by ','
stored as textfile;
-- 创建老师表
DROP TABLE IF EXISTS teacher;
create table if not exists teacher_info(
tea_id string COMMENT '老师id',
tea_name string COMMENT '老师姓名'
)
row format delimited fields terminated by ','
stored as textfile;
-- 创建分数表
DROP TABLE IF EXISTS score;
create table if not exists score_info(
stu_id string COMMENT '学生id',
course_id string COMMENT '课程id',
score int COMMENT '成绩'
)
row format delimited fields terminated by ','
stored as textfile;
1.2 数据准备
(1)创建/opt/module/data目录
[atguigu@hadoop102 module]$ mkdir data
(2)将如4个文件放到/opt/module/data目录下(数据内容如第三点所示)
(3)数据样式说明
[atguigu@hadoop102 data]$ vim student_info.txt
001,彭于晏,1995-05-16,男
002,胡歌,1994-03-20,男
003,周杰伦,1995-04-30,男
004,刘德华,1998-08-28,男
005,唐国强,1993-09-10,男
006,陈道明,1992-11-12,男
007,陈坤,1999-04-09,男
008,吴京,1994-02-06,男
009,郭德纲,1992-12-05,男
010,于谦,1998-08-23,男
011,潘长江,1995-05-27,男
012,杨紫,1996-12-21,女
013,蒋欣,1997-11-08,女
014,赵丽颖,1990-01-09,女
015,刘亦菲,1993-01-14,女
016,周冬雨,1990-06-18,女
017,范冰冰,1992-07-04,女
018,李冰冰,1993-09-24,女
019,邓紫棋,1994-08-31,女
020,宋丹丹,1991-03-01,女
[atguigu@hadoop102 data]$ vim course_info.txt
01,语文,1003
02,数学,1001
03,英语,1004
04,体育,1002
05,音乐,1002
[atguigu@hadoop102 data]$ vim teacher_info.txt
1001,张高数
1002,李体音
1003,王子文
1004,刘丽英
[atguigu@hadoop102 data]$ vim score_info.txt
001,01,94
002,01,74
004,01,85
005,01,64
006,01,71
007,01,48
008,01,56
009,01,75
010,01,84
011,01,61
012,01,44
013,01,47
014,01,81
015,01,90
016,01,71
017,01,58
018,01,38
019,01,46
020,01,89
001,02,63
002,02,84
004,02,93
005,02,44
006,02,90
007,02,55
008,02,34
009,02,78
010,02,68
011,02,49
012,02,74
013,02,35
014,02,39
015,02,48
016,02,89
017,02,34
018,02,58
019,02,39
020,02,59
001,03,79
002,03,87
004,03,89
005,03,99
006,03,59
007,03,70
008,03,39
009,03,60
010,03,47
011,03,70
012,03,62
013,03,93
014,03,32
015,03,84
016,03,71
017,03,55
018,03,49
019,03,93
020,03,81
001,04,54
002,04,100
004,04,59
005,04,85
007,04,63
009,04,79
010,04,34
013,04,69
014,04,40
016,04,94
017,04,34
020,04,50
005,05,85
007,05,63
009,05,79
015,05,59
018,05,87
1.3 插入数据
(1)插入数据
hive>
load data local inpath '/opt/module/data/student_info.txt' into table student_info;
load data local inpath '/opt/module/data/course_info.txt' into table course_info;
load data local inpath '/opt/module/data/teacher_info.txt' into table teacher_info;
load data local inpath '/opt/module/data/score_info.txt' into table score_info;
骚戴理解:(这里我不能通过下面的命令加载数据到hive数据库,我是直接把数据上传到hdfs对应的路径下)
hive>desc formatted teacher_info //查看这个表在hdfs中的存储路径

在把本地的teacher_info.txt上传到hdfs上面
[hive@node181 data]$ hdfs dfs -put teacher_info.txt hdfs://node181.hadoop.com:8020/warehouse/tablespace/managed/hive/teacher_info
(2)验证插入数据情况
hive>
select * from student_info limit 5;
select * from course_info limit 5;
select * from teacher_info limit 5;
select * from score_info limit 5;
第二章简单查询
2.1 查找特定条件
2.1.1 查询姓名中带“冰”的学生名单
hive>
select
*
from student_info
where stu_name like "%冰%";
结果
stu_id stu_name birthday sex
017 范冰冰 1992-07-04 女
018 李冰冰 1993-09-24 女
2.1.2 查询姓“王”老师的个数
hive>
select
count(*) wang_count
from teacher_info
where tea_name like '王%';
结果
wang_count
1
2.1.3 检索课程编号为“04”且分数小于60的学生的课程信息,结果按分数降序排列
hive>
select
stu_id,
course_id,
score
from score_info
where course_id ='04' and score<60
order by score desc;
结果
stu_id course_id score
004 04 59
001 04 54
020 04 50
014 04 40
017 04 34
010 04 34
2.1.4 查询数学成绩不及格的学生和其对应的成绩,按照学号升序排序
hive>
select
s.stu_id,
s.stu_name,
t1.score
from student_info s
join (
select
*
from score_info
where course_id=(select course_id from course_info where course_name='数学') and score < 60
) t1 on s.stu_id = t1.stu_id
order by s.stu_id;
骚戴解法
select
si.stu_id ,si.stu_name ,si2.score
from student_info si
inner join score_info si2 on si.stu_id =si2 .stu_id
where si2.score <60 and si2.course_id ='02'
order by si.stu_id;
结果
s.stu_id s.stu_name t1.score
005 唐国强 44
007 陈坤 55
008 吴京 34
011 潘长江 49
013 蒋欣 35
014 赵丽颖 39
015 刘亦菲 48
017 范冰冰 34
018 李冰冰 58
019 邓紫棋 39
020 宋丹丹 59
第三章汇总分析
3.1 汇总分析
3.1.1 查询编号为“02”的课程的总成绩
hive>
select
course_id,
sum(score) score_sum
from score_info
where course_id='02'
group by course_id;
骚戴理解:这里我忘记分组了,group by course_id要写
结果
course_id score_sum
02 1133
3.1.2 查询参加考试的学生个数
思路:对成绩表中的学号做去重并count
hive>
select
count(distinct stu_id) stu_num
from score_info;
结果
stu_num
19
3.2 分组
3.2.1 查询各科成绩最高和最低的分,以如下的形式显示:课程号,最高分,最低分
思路:按照学科分组并使用max和min。
hive>
select
course_id,
max(score) max_score,
min(score) min_score
from score_info
group by course_id;
结果
course_id max_score min_score
01 94 38
02 93 34
03 99 32
04 100 34
05 87 59
3.2.2 查询每门课程有多少学生参加了考试(有考试成绩)
hive>
select
course_id,
count(stu_id) stu_num
from score_info
group by course_id;
结果
course_id stu_num
01 19
02 19
03 19
04 12
05 5
3.2.3 查询男生、女生人数
hive>
select
sex,
count(stu_id) count
from student_info
group by sex;
结果
sex count
女 9
男 11
3.3 分组结果的条件
3.3.1 查询平均成绩大于60分的学生的学号和平均成绩
1)思路分析
(1)平均成绩:展开来说就是计算每个学生的平均成绩
(2)这里涉及到“每个”就是要分组了
(3)平均成绩大于60分,就是对分组结果指定条件
(4)首先要分组求出每个学生的平均成绩,筛选高于60分的,并反查出这批学生,统计出这些学生总的平均成绩。
2)Hql实操
hive>
select
stu_id,
avg(score) score_avg
from score_info
group by stu_id
having score_avg > 60;
骚戴理解:having是对分组聚合后的结果进行判断比较,where是对每条数据进行判断比较
结果
stu_id score_avg
001 72.5
002 86.25
004 81.5
005 75.4
006 73.33333333333333
009 74.2
013 61.0
015 70.25
016 81.25
020 69.75
3.3.2 查询至少选修四门课程的学生学号
1)思路分析
(1)需要先计算出每个学生选修的课程数据,需要按学号分组
(2)至少选修两门课程:也就是每个学生选修课程数目>=4,对分组结果指定条件
2)Hql实操
hive>
select
stu_id,
count(course_id) course_count
from score_info
group by stu_id
having course_count >=4;
骚戴解法:
select
stu_id
from score_info
group by stu_id
having count(course_id)>=4;
骚戴理解:这里可发现聚合函数可以直接在having后面使用!
结果
stu_id course_num
001 4
002 4
004 4
005 5
007 5
009 5
010 4
013 4
014 4
015 4
016 4
017 4
018 4
020 4
3.3.3 查询同姓(假设每个学生姓名的第一个字为姓)的学生名单并统计同姓人数大于等于2的姓
思路:先提取出每个学生的姓并分组,如果分组的count>=2则为同姓
hive>
select
t1.first_name,
count(*) count_first_name
from (
select
stu_id,
stu_name,
substr(stu_name,0,1) first_name
from student_info
) t1
group by t1.first_name
having count_first_name >= 2;
骚戴理解:这里是通过子查询来实现的,多看看来理解子查询的妙处
结果
t1.first_name count_first_name
刘 2
周 2
陈 2
3.3.4 查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
思路:按照课程号分组并求组内的平均值
hive>
select
course_id,
avg(score) score_avg
from score_info
group by course_id
order by score_avg asc, course_id desc;
结果
course_id score_avg
02 59.63157894736842
04 63.416666666666664
01 67.15789473684211
03 69.42105263157895
05 74.6
3.3.5 统计参加考试人数大于等于15的学科
按课程分组并统计组内人数,过滤条件大于等于15
hive>
select
course_id,
count(stu_id) stu_count
from score_info
group by course_id
having stu_count >= 15;
结果
course_id stu_count
01 19
02 19
03 19
3.4 查询结果排序&分组指定条件
3.4.1 查询学生的总成绩并按照总成绩降序排序
思路:分组、sum、排序
hive>
select
stu_id,
sum(score) sum_score
from score_info
group by stu_id
order by sum_score desc;
结果
stu_id sum_score
005 377
009 371
002 345
004 326
016 325
007 299
001 290
015 281
020 279
013 244
010 233
018 232
006 220
014 192
017 181
012 180
011 180
019 178
008 129
*3.4.2 按照如下格式显示学生的语文、数学、英语三科成绩,没有成绩的输出为0,按照学生的有效平均成绩降序显示
学生id 语文 数学 英语 有效课程数 有效平均成绩
hive>
select
si.stu_id,
sum(if(ci.course_name='语文',score,0)) `语文`,
sum(if(ci.course_name='数学',score,0)) `数学`,
sum(if(ci.course_name='英语',score,0)) `英语`,
count(*) `有效课程数`,
avg(si.score) `平均成绩`
from
score_info si
join
course_info ci
on
si.course_id=ci.course_id
group by
si.stu_id
order by
`平均成绩` desc
结果
学生id 语文 数学 英语 有效课程数 平均成绩
002 74 84 87 4 86.25
004 85 93 89 4 81.5
016 71 89 71 4 81.25
005 64 44 99 5 75.4
009 75 78 60 5 74.2
006 71 90 59 3 73.33333333333333
001 94 63 79 4 72.5
015 90 48 84 4 70.25
020 89 59 81 4 69.75
013 47 35 93 4 61.0
012 44 74 62 3 60.0
011 61 49 70 3 60.0
007 48 55 70 5 59.8
019 46 39 93 3 59.333333333333336
010 84 68 47 4 58.25
018 38 58 49 4 58.0
014 81 39 32 4 48.0
017 58 34 55 4 45.25
008 56 34 39 3 43.0
*3.4.3 查询一共参加三门课程且其中一门为语文课程的学生的id和姓名
hive>
select
t2.stu_id,
s.stu_name
from (
select t1.stu_id
from (
select stu_id,
course_id
from score_info
where stu_id in (
select stu_id
from score_info
where course_id = "01"
)
) t1
group by t1.stu_id
having count(t1.course_id) = 3
) t2
join student_info s on t2.stu_id = s.stu_id;
结果
t2.stu_id s.stu_name
006 陈道明
008 吴京
011 潘长江
012 杨紫
019 邓紫棋
第四章复杂查询
4.1 子查询
4.1.1 查询所有课程成绩均小于60分的学生的学号、姓名
hive>
select s.stu_id,
s.stu_name
from (
select stu_id,
sum(if(score >= 60, 1, 0)) flag
from score_info
group by stu_id
having flag = 0
) t1
join student_info s on s.stu_id = t1.stu_id;
骚戴理解:这里是通过子查询加join来实现的,我一直以为这两个是不能一起用,然后主要理解下面的语句 ,首先这里是按stu_id分组,那么分组后可以看到每个学生的所有课程,然后这里的难点就是怎么判断每个课程都小于60分,这里用到了 sum(if(score >= 60, 1, 0)) ,这句是判断每门成绩是否大于60,如果大于那么返回1,小于则返回0,然后课程不止一门,这里要求每门,所以用sum去求和每门科目的返回值得和,只有每门课程的返回结果都是0,sum(if(score >= 60, 1, 0))的结果才是0,也就是flag才是0,flag为0就说明每门课程都没及格,所以最后通过 having flag = 0来获取都没有及格的
select stu_id,
sum(if(score >= 60, 1, 0)) flag
from score_info
group by stu_id
having flag = 0
结果
s.stu_id s.stu_name
008 吴京
017 范冰冰
*4.1.2查询没有学全所有课的学生的学号、姓名
解释:没有学全所有课,也就是该学生选修的课程数 < 总的课程数
hive>
select
s.stu_id,
s.stu_name
from student_info s
left join score_info sc on s.stu_id = sc.stu_id
group by s.stu_id, s.stu_name
having count(course_id) < (select count(course_id) from course_info);
结果
s.stu_id s.stu_name
001 彭于晏
002 胡歌
003 周杰伦
004 刘德华
006 陈道明
008 吴京
010 于谦
011 潘长江
012 杨紫
013 蒋欣
014 赵丽颖
015 刘亦菲
016 周冬雨
017 范冰冰
018 李冰冰
019 邓紫棋
020 宋丹丹
4.1.3 查询出只选修了三门课程的全部学生的学号和姓名
解释:学生选修的课程数 = 3
hive>
select
s.stu_id,
s.stu_name
from student_info s
join (
select
stu_id,
count(course_id) course_count
from score_info
group by stu_id
having course_count =3
) t1
on s.stu_id = t1.stu_id;
骚戴解法
SELECT
si.stu_id,
si.stu_name
FROM (
SELECT
stu_id
FROM score_info
group by stu_id
HAVING COUNT(course_id)=3
)t1
join student_info si on si.stu_id = t1.stu_id;
结果
s.stu_id s.stu_name
006 陈道明
008 吴京
011 潘长江
012 杨紫
019 邓紫棋
第五章多表查询
5.1 表联结
5.1.1 查询有两门及以上的课程不及格的同学的学号及其平均成绩
① 先找出有两门以上不及格的学生名单,按照学生分组,过滤组内成绩低于60的并进行count,count>=2。
② 接着做出一张表查询学生的平均成绩并和上一个子查询中的学生学号进行连接
hive>
select
t1.stu_id,
t2.avg_score
from (
select
stu_id,
sum(if(score < 60,1,0)) flage
from score_info
group by stu_id
having flage >= 2
) t1
join (
select
stu_id,
avg(score) avg_score
from score_info
group by stu_id
) t2 on t1.stu_id = t2.stu_id;
骚戴理解:这里主要是学习这样的思想,把两个单独的select写出来然后再join在一起
结果
t1.stu_id t2.avg_score
007 59.8
008 43.0
010 58.25
013 61.0
014 48.0
015 70.25
017 45.25
018 58.0
019 59.333333333333336
020 69.75
5.1.2 查询所有学生的学号、姓名、选课数、总成绩
hive>
select
s.stu_id,
s.stu_name,
count(sc.course_id) count_course,
sum(sc.score) sum_score
from student_info s
left join score_info sc on s.stu_id = sc.stu_id
group by s.stu_id,s.stu_name;
骚戴理解:这里主要是注意分组是通过stu_id和stu_name来确定唯一的记录,很容易忘了对stu_name进行分组,还要注意group by的字段和select后面的字段要对应,例如下面的就是错的
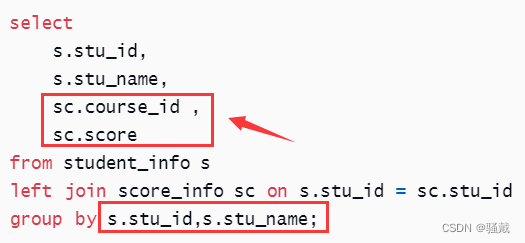
骚戴理解:这里select后面红色画出的字段没有在group by中,所以会报错,如果select后面是聚合函数就没关系
select
s.stu_id,
s.stu_name,
sc.course_id ,
sc.score
from student_info s
left join score_info sc on s.stu_id = sc.stu_id;
为了更好的理解,这里先做一个左连接,看看下面的执行结果,然后会发现stu_id和stu_name两个一起分组才可以确定唯一的一个组
stu_id stu_name course_id score
003 周杰伦
017 范冰冰 01 58
017 范冰冰 04 34
017 范冰冰 03 55
017 范冰冰 02 34
005 唐国强 01 64
005 唐国强 05 85
005 唐国强 04 85
005 唐国强 03 99
005 唐国强 02 44
018 李冰冰 01 38
018 李冰冰 05 87
018 李冰冰 03 49
018 李冰冰 02 58
020 宋丹丹 01 89
020 宋丹丹 04 50
020 宋丹丹 03 81
020 宋丹丹 02 59
006 陈道明 01 71
006 陈道明 03 59
006 陈道明 02 90
015 刘亦菲 01 90
015 刘亦菲 05 59
015 刘亦菲 03 84
015 刘亦菲 02 48
019 邓紫棋 01 46
019 邓紫棋 03 93
019 邓紫棋 02 39
002 胡歌 01 74
002 胡歌 04 100
002 胡歌 03 87
002 胡歌 02 84
010 于谦 01 84
010 于谦 04 34
010 于谦 03 47
010 于谦 02 68
011 潘长江 01 61
011 潘长江 03 70
011 潘长江 02 49
009 郭德纲 01 75
009 郭德纲 05 79
009 郭德纲 04 79
009 郭德纲 03 60
009 郭德纲 02 78
001 彭于晏 01 94
001 彭于晏 04 54
001 彭于晏 03 79
001 彭于晏 02 63
004 刘德华 01 85
004 刘德华 04 59
004 刘德华 03 89
004 刘德华 02 93
013 蒋欣 01 47
013 蒋欣 04 69
013 蒋欣 03 93
013 蒋欣 02 35
014 赵丽颖 01 81
014 赵丽颖 04 40
014 赵丽颖 03 32
014 赵丽颖 02 39
007 陈坤 01 48
007 陈坤 05 63
007 陈坤 04 63
007 陈坤 03 70
007 陈坤 02 55
008 吴京 01 56
008 吴京 03 39
008 吴京 02 34
012 杨紫 01 44
012 杨紫 03 62
012 杨紫 02 74
016 周冬雨 01 71
016 周冬雨 04 94
016 周冬雨 03 71
016 周冬雨 02 89
结果
stu_id stu_name course_count course_sum
001 彭于晏 4 290
002 胡歌 4 345
003 周杰伦 0 0
004 刘德华 4 326
005 唐国强 5 377
006 陈道明 3 220
007 陈坤 5 299
008 吴京 3 129
009 郭德纲 5 371
010 于谦 4 233
011 潘长江 3 180
012 杨紫 3 180
013 蒋欣 4 244
014 赵丽颖 4 192
015 刘亦菲 4 281
016 周冬雨 4 325
017 范冰冰 4 181
018 李冰冰 4 232
019 邓紫棋 3 178
020 宋丹丹 4 279
5.1.3 查询平均成绩大于85的所有学生的学号、姓名和平均成绩
hive>
select s.stu_id,
s.stu_name,
avg(sc.score) avg_score
from score_info sc
left join student_info s on s.stu_id = sc.stu_id
group by s.stu_id, s.stu_name
having avg_score > 85
结果
stu_id stu_name avg_score
002 胡歌 86.25
5.1.4 查询学生的选课情况:学号,姓名,课程号,课程名称
hive>
select
s.stu_id,
s.stu_name,
c.course_id,
c.course_name
from score_info sc
join course_info c on sc.course_id = c.course_id
join student_info s on sc.stu_id = s.stu_id;
骚戴理解:这里要通过score_info表来做媒介牵绳把course_info和student_info连一起
结果
s.stu_id s.stu_name c.course_id c.course_name
017范冰冰03英语
017范冰冰04体育
005唐国强03英语
018李冰冰03英语
020宋丹丹03英语
005唐国强04体育
020宋丹丹04体育
006陈道明03英语
015刘亦菲03英语
019邓紫棋03英语
002胡歌03英语
002胡歌04体育
010于谦03英语
011潘长江03英语
010于谦04体育
009郭德纲03英语
009郭德纲04体育
001彭于晏03英语
004刘德华03英语
013蒋欣03英语
001彭于晏04体育
004刘德华04体育
013蒋欣04体育
014赵丽颖03英语
014赵丽颖04体育
007陈坤03英语
008吴京03英语
012杨紫03英语
016周冬雨03英语
007陈坤04体育
016周冬雨04体育
017范冰冰02数学
005唐国强02数学
018李冰冰02数学
020宋丹丹02数学
005唐国强05音乐
018李冰冰05音乐
006陈道明02数学
015刘亦菲02数学
019邓紫棋02数学
015刘亦菲05音乐
002胡歌02数学
010于谦02数学
011潘长江02数学
009郭德纲02数学
009郭德纲05音乐
001彭于晏02数学
004刘德华02数学
013蒋欣02数学
014赵丽颖02数学
007陈坤02数学
008吴京02数学
012杨紫02数学
016周冬雨02数学
007陈坤05音乐
017范冰冰01语文
s.stu_id s.stu_name c.course_id c.course_name
005唐国强01语文
018李冰冰01语文
020宋丹丹01语文
006陈道明01语文
015刘亦菲01语文
019邓紫棋01语文
002胡歌01语文
010于谦01语文
011潘长江01语文
009郭德纲01语文
001彭于晏01语文
004刘德华01语文
013蒋欣01语文
014赵丽颖01语文
007陈坤01语文
008吴京01语文
012杨紫01语文
016周冬雨01语文
002 胡歌 03 英语
001 彭于晏 03 英语
004 刘德华 03 英语
005 唐国强 03 英语
006 陈道明 03 英语
007 陈坤 03 英语
008 吴京 03 英语
009 郭德纲 03 英语
010 于谦 03 英语
011 潘长江 03 英语
012 杨紫 03 英语
013 蒋欣 03 英语
014 赵丽颖 03 英语
015 刘亦菲 03 英语
016 周冬雨 03 英语
017 范冰冰 03 英语
018 李冰冰 03 英语
019 邓紫棋 03 英语
020 宋丹丹 03 英语
001 彭于晏 04 体育
002 胡歌 04 体育
004 刘德华 04 体育
005 唐国强 04 体育
007 陈坤 04 体育
009 郭德纲 04 体育
010 于谦 04 体育
013 蒋欣 04 体育
014 赵丽颖 04 体育
016 周冬雨 04 体育
017 范冰冰 04 体育
020 宋丹丹 04 体育
005 唐国强 05 音乐
007 陈坤 05 音乐
009 郭德纲 05 音乐
015 刘亦菲 05 音乐
018 李冰冰 05 音乐
5.1.5 查询出每门课程的及格人数和不及格人数
hive>
select
c.course_id,
c.course_name,
t1.`及格人数`,
t1.`不及格人数`
from course_info c
join (
select
course_id,
sum(if(score >= 60,1,0)) as `及格人数`,
sum(if(score < 60,1,0)) as `不及格人数`
from score_info
group by course_id
) t1 on c.course_id = t1.course_id;
骚戴理解:这里注意及格人数的符号问题,是 ` 不是单引号‘
结果
c.course_id c.course_name t1.及格人数 t1.不及格人数
01 语文 12 7
02 数学 8 11
03 英语 13 6
04 体育 6 6
05 音乐 4 1
5.1.6 查询课程编号为03且课程成绩在80分以上的学生的学号和姓名及课程信息
hive>
select
s.stu_id,
s.stu_name,
t1.score,
t1.course_id,
c.course_name
from student_info s
join (
select
stu_id,
score,
course_id
from score_info
where score > 80 and course_id = '03'
) t1
on s.stu_id = t1.stu_id
join course_info c on c.course_id = t1.course_id;
骚戴解法
select
si2.stu_id ,
si2.stu_name,
si.score,
si.course_id ,
ci.course_name
from score_info si
join student_info si2 on si.stu_id = si2.stu_id
join course_info ci on si.course_id = ci.course_id
where ci.course_id ='03' and si.score >=80;
结果
s.stu_id s.stu_name t1.score t1.course_id c.course_name
002 胡歌 87 03 英语
004 刘德华 89 03 英语
005 唐国强 99 03 英语
013 蒋欣 93 03 英语
015 刘亦菲 84 03 英语
019 邓紫棋 93 03 英语
020 宋丹丹 81 03 英语
5.2 多表连接
5.2.1 课程编号为"01"且课程分数小于60,按分数降序排列的学生信息
hive>
select
s.stu_id,
s.stu_name,
s.birthday,
s.sex,
t1.score
from student_info s
join (
select
stu_id,
course_id,
score
from score_info
where score < 60 and course_id = '01'
) t1
on s.stu_id=t1.stu_id
order by t1.score desc;
骚戴解法
select
si2.stu_id ,
si2.stu_name,
si2.birthday,
si2.sex,
si.score
from score_info si
join student_info si2 on si.stu_id = si2.stu_id
join course_info ci on si.course_id = ci.course_id
where ci.course_id ='01' and si.score <60
order by si.score desc;
结果
s.stu_id s.stu_name s.birthday s.sex t1.score
017 范冰冰 1992-07-04 女 58
008 吴京 1994-02-06 男 56
007 陈坤 1999-04-09 男 48
013 蒋欣 1997-11-08 女 47
019 邓紫棋 1994-08-31 女 46
012 杨紫 1996-12-21 女 44
018 李冰冰 1993-09-24 女 38
5.2.2 查询所有课程成绩在70分以上的学生的姓名、课程名称和分数,按分数升序排列
hive>
select
s.stu_id,
s.stu_name,
c.course_name,
s2.score
from student_info s
join (
select
stu_id,
sum(if(score >= 70,0,1)) flage
from score_info
group by stu_id
having flage =0
) t1
on s.stu_id = t1.stu_id
left join score_info s2 on s.stu_id = s2.stu_id
left join course_info c on s2.course_id = c.course_id;
骚戴理解:这里要有清晰的思路,首先通过子查询把所有课程都70分的学生id查出来,然后和student_info进行join,然后在和score_info进行left join,最后和course_info进行left join。注意顺序不能错!(因为子查询和student_info进行join的结果表只能先和score_info拼接),这里注意left join score_info s2 on s.stu_id = s2.stu_id语句的左边的驱动表是子查询和student_info进行join的结果表,然后我之前没有很好的理解多表联查的on后面的条件拼接,我以为在left join course_info c on s2.course_id = c.course_id;这里的on后面必须是student_info和course_info进行拼接,然而这两个表没发拼接!所以只要是join后的结果表和其他的表继续join,那么就可以使用join过的表的字段进行拼接,例如这里的left join course_info c on s2.course_id = c.course_id;语句的左边驱动表就是子查询和student_info进行join的结果表再和score_info进行left join的结果表,也就是能够和course_info进行join的on后面拼接的条件中可以使用之前的三个表的字段来连接,这里用的就是score_info和course_info拼接,拼接条件是 s2.course_id = c.course_id
结果
s.stu_id s.stu_name c.course_name s2.course
002 胡歌 语文 74
002 胡歌 数学 84
002 胡歌 英语 87
002 胡歌 体育 100
016 周冬雨 语文 71
016 周冬雨 数学 89
016 周冬雨 英语 71
016 周冬雨 体育 94
5.2.3 查询该学生不同课程的成绩相同的学生编号、课程编号、学生成绩
hive>
select
sc1.stu_id,
sc1.course_id,
sc1.score
from score_info sc1
join score_info sc2 on sc1.stu_id = sc2.stu_id
where sc1.course_id <> sc2.course_id
and sc1.score = sc2.score;
骚戴理解:这里用的是同一个表自己和自己join,理解一下这个自己join自己的场景
结果
sc1.stu_id sc1.course_id sc1.score
016 03 71
017 04 34
016 01 71
005 05 85
007 05 63
009 05 79
017 02 34
005 04 85
007 04 63
009 04 79
5.2.4 查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号
知识点:多表连接 + 条件
hive>
select
s1.stu_id
from
(
select
sc1.stu_id,
sc1.course_id,
sc1.score
from score_info sc1
where sc1.course_id ='01'
) s1
join
(
select
sc2.stu_id,
sc2.course_id,
score
from score_info sc2
where sc2.course_id ="02"
)s2
on s1.stu_id=s2.stu_id
where s1.score > s2.score;
结果
stu_id
001
005
008
010
011
013
014
015
017
019
020
5.2.5 查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
hive>
select
t1.stu_id as `学号`,
s.stu_name as `姓名`
from
(
select
stu_id
from score_info sc1
where sc1.course_id='01'
and stu_id in (
select
stu_id
from score_info sc2
where sc2.course_id='02'
)
)t1
join student_info s
on t1.stu_id = s.stu_id;
骚戴理解:这里用的where...in....来处理学过编号为“01”的课程并且也学过编号为“02”的课程这个条件筛选
结果
学号 姓名
001 彭于晏
002 胡歌
004 刘德华
005 唐国强
006 陈道明
007 陈坤
008 吴京
009 郭德纲
010 于谦
011 潘长江
012 杨紫
013 蒋欣
014 赵丽颖
015 刘亦菲
016 周冬雨
017 范冰冰
018 李冰冰
019 邓紫棋
020 宋丹丹
5.2.6 查询学过“李体音”老师所教的所有课的同学的学号、姓名
hive>
select
t1.stu_id,
si.stu_name
from
(
select
stu_id
from score_info si
where course_id in
(
select
course_id
from course_info c
join teacher_info t
on c.tea_id = t.tea_id
where tea_name='李体音' --李体音教的所有课程
)
group by stu_id
having count(*)=2 --学习所有课程的学生
)t1
left join student_info si
on t1.stu_id=si.stu_id;
骚戴解法
select
si.stu_id ,
si.stu_name
from (
select
stu_id
from score_info
where course_id in (
select
course_id
from course_info
where tea_id in(
select
tea_id
from teacher_info
where tea_name = '李体音'
)
)
group by stu_id
having count(*)=2
)t
join student_info si on si.stu_id = t.stu_id;
结果
s.stu_id s.stu_name
005 唐国强
007 陈坤
009 郭德纲
5.2.7查询学过“李体音”老师所讲授的任意一门课程的学生的学号、姓名
hive>
select
t1.stu_id,
si.stu_name
from
(
select
stu_id
from score_info si
where course_id in
(
select
course_id
from course_info c
join teacher_info t
on c.tea_id = t.tea_id
where tea_name='李体音'
)
)t1
left join student_info si
on t1.stu_id=si.stu_id;
骚戴解法
SELECT
si.stu_id ,
si.stu_name
FROM (
SELECT
stu_id
FROM score_info
WHERE course_id in (
SELECT
course_id
FROM course_info
WHERE tea_id in(
SELECT
tea_id
FROM teacher_info
WHERE tea_name = '李体音'
)
)
)t
join student_info si on si.stu_id = t.stu_id;
结果
s.stu_id s.stu_name
001 彭于晏
002 胡歌
004 刘德华
005 唐国强
007 陈坤
009 郭德纲
010 于谦
013 蒋欣
014 赵丽颖
015 刘亦菲
016 周冬雨
017 范冰冰
018 李冰冰
020 宋丹丹
5.2.8 查询没学过"李体音"老师讲授的任一门课程的学生姓名
hive>
select
stu_id,
stu_name
from student_info
where stu_id not in
(
select
stu_id
from score_info si
where course_id in
(
select
course_id
from course_info c
join teacher_info t
on c.tea_id = t.tea_id
where tea_name='李体音'
)
group by stu_id
);
结果
stu_id stu_name
003 周杰伦
006 陈道明
008 吴京
011 潘长江
012 杨紫
019 邓紫棋
5.2.9查询至少有一门课与学号为“001”的学生所学课程相同的学生的学号和姓名
hive>
select
si.stu_id,
si.stu_name
from score_info sc
join student_info si
on sc.stu_id = si.stu_id
where sc.course_id in
(
select
course_id
from score_info
where stu_id='001' --001的课程
) and sc.stu_id <> '001' --排除001学生
group by si.stu_id,si.stu_name;
骚戴理解
select
stu_id ,
stu_name
from student_info
where stu_id not in (
select
stu_id
from score_info
where course_id not in (
select
course_id
from score_info
where stu_id = '001'
)
);
结果
s1.stu_id s2.stu_name
002 胡歌
004 刘德华
005 唐国强
006 陈道明
007 陈坤
008 吴京
009 郭德纲
010 于谦
011 潘长江
012 杨紫
013 蒋欣
014 赵丽颖
015 刘亦菲
016 周冬雨
017 范冰冰
018 李冰冰
019 邓紫棋
020 宋丹丹
5.2.10 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
hive>
select
si.stu_name,
ci.course_name,
sc.score,
t1.avg_score
from score_info sc
join student_info si
on sc.stu_id=si.stu_id
join course_info ci
on sc.course_id=ci.course_id
join
(
select
stu_id,
avg(score) avg_score
from score_info
group by stu_id
)t1
on sc.stu_id=t1.stu_id
order by t1.avg_score desc;
结果
t2.stu_name t2.course_name t2.score t1.avg_score
胡歌 体育 100 86.25
胡歌 数学 84 86.25
胡歌 英语 87 86.25
胡歌 语文 74 86.25
刘德华 体育 59 81.5
刘德华 语文 85 81.5
刘德华 英语 89 81.5
刘德华 数学 93 81.5
周冬雨 英语 71 81.25
周冬雨 数学 89 81.25
周冬雨 体育 94 81.25
周冬雨 语文 71 81.25
唐国强 数学 44 75.4
唐国强 音乐 85 75.4
唐国强 语文 64 75.4
唐国强 体育 85 75.4
唐国强 英语 99 75.4
郭德纲 音乐 79 74.2
郭德纲 体育 79 74.2
郭德纲 英语 60 74.2
郭德纲 语文 75 74.2
郭德纲 数学 78 74.2
陈道明 语文 71 73.33333333333333
陈道明 数学 90 73.33333333333333
陈道明 英语 59 73.33333333333333
……
李冰冰 音乐 87 58.0
李冰冰 语文 38 58.0
李冰冰 英语 49 58.0
李冰冰 数学 58 58.0
赵丽颖 数学 39 48.0
赵丽颖 语文 81 48.0
赵丽颖 体育 40 48.0
赵丽颖 英语 32 48.0
范冰冰 英语 55 45.25
范冰冰 体育 34 45.25
范冰冰 数学 34 45.25
范冰冰 语文 58 45.25
吴京 语文 56 43.0
吴京 数学 34 43.0
吴京 英语 39 43.0
版权归原作者 骚戴 所有, 如有侵权,请联系我们删除。