
报错日志:

问题分析过程
1、报错各式各样的方法栈,但是终归于head of empty list,于是去看scala相关代码。
2、为什么List在为空的情况下,还要继续执行head方法呢,scala List map代码:

3、google “scala head of empty list”, list.map method throws "head of empty list" exception · Issue #9584 · scala/bug · GitHub中讲到Nil是一个object单例,如果有反序列化或反射的情况,就会出现单例破坏。看看Nil的代码:

PS:使用jmap、jhat,实锤有多个Nil实例情况
在spark上找到driver用的端口,netstat查找端口对应java的【pid】
把jvm内存dump下来:
jmap -dump:live,format=b,file=heap.hprof 【pid】
将jvm内存展示到web前端8087端口:
jhat -J-Xmx2g -port 8087 heap.hprof
进入web页面,搜索Nil$,查看Nil的全部实例Instances,实锤有多个Nil实例被创建。


4、接下来就是要找到到底是哪块代码将Nil反序列化或反射了,需要用到arthas工具。
需要在对应spark任务的ApplicationMaster机器上,执行java -jar arthas-boot.jar
选择ApplicationMaster进程
看下Nil的方法:sm scala.collection.immutable.Nil$

*Nil被序列化或是被反射都需要初始化,所以stack Nil*的<init>**方法
stack scala.collection.immutable.Nil$ <init>
然后执行后端接口,触发报错,捕捉Nil被初始化的方法栈,发现是livy这块反序列化的时候创建了Nil实例。查看自己的业务代码,发现确实代码是通过闭包 Job的形式提交给livy执行的。代码就定位到闭包反序列化这块。

5、具体是哪一个接口任务的Job反序列化了呢,就需要远程调试了。
远程调试步骤:
需要远程调试spark的driver端,增加livy session的spark参数:
**“spark.driver.extraJavaOptions”:”-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=15005”**
调试端口为15005,在IDEA中配置如下图步骤:
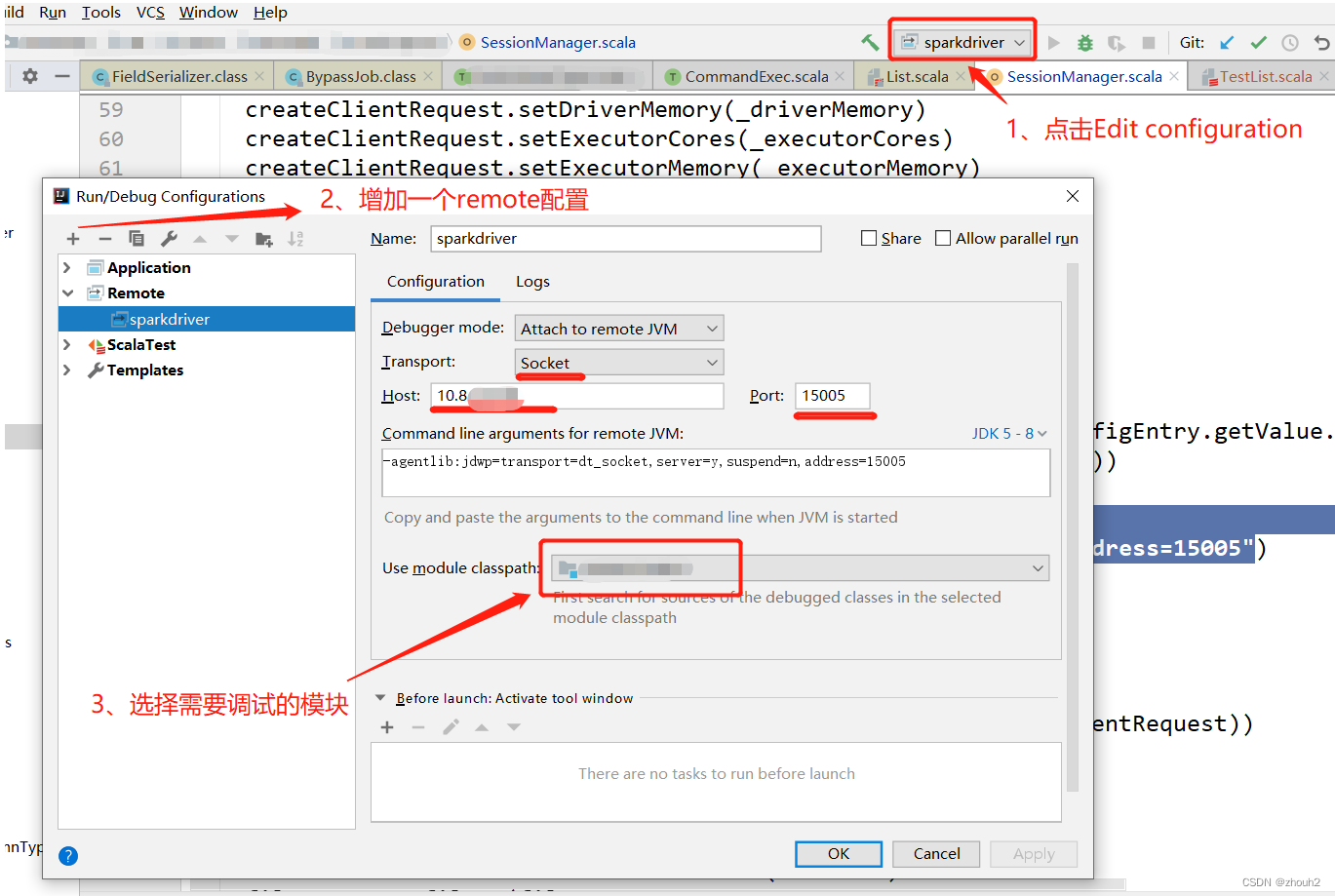
运行启动脚本,提交的session中包含调试参数
livy启动的spark driver就会等待调试触发
driver stdout日志:Listening for transport dt_socket at address: 15005
然后点击debug调试刚才的运行配置。
6、远程调试配置好,按照4步stack的方法栈,打断点到创建对象的地方,增加断点条件为当object是Nil$对象的时候暂停。
object **instanceof **scala.collection.immutable.Nil$

然后运行后端接口任务,等待执行到此处。然后在打断点到Job被反序列化出来
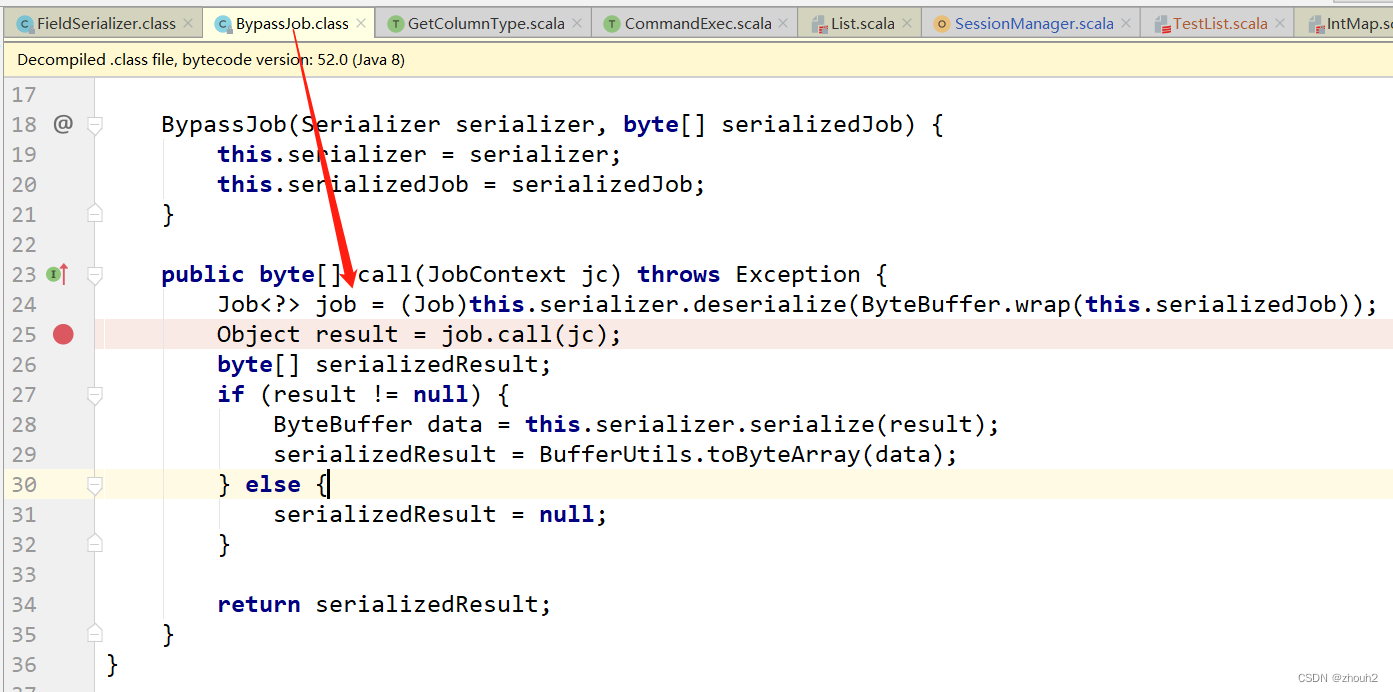
然后查看job对象,里面有Nil$被反序列化出来都是不允许的。都需要修改对应的接口Job闭包。(可以按照job对象的字段信息,可以找到对应的Job闭包代码)
问题代码
问题代码在形成闭包的时候,传入了scala的List,livy用的org.apache.livy.shaded.kryo.kryo.Kryo类,是java写的 没考虑到scala的一些转化,所以会在反序列化的时候,创建新的Nil实例。
最小化还原了错误代码...
规范提示
在调用livy Job任务闭包的时候,闭包中不要传入scala的List类型实例(闭包里初始化的对象不会被序列化),因为livy的序列化kryo类对scala类型不支持,会造成Nil单例破坏。
**PS**: Nil是有readResolve方法的,只是livy的kryo没去用JavaSerializer去反序列化,而是用的FieldSerializer。
版权归原作者 zhouh2 所有, 如有侵权,请联系我们删除。