
数据导入及查询
本文档主要介绍 Doris 的数据导入及数据查询。
数据导入方式
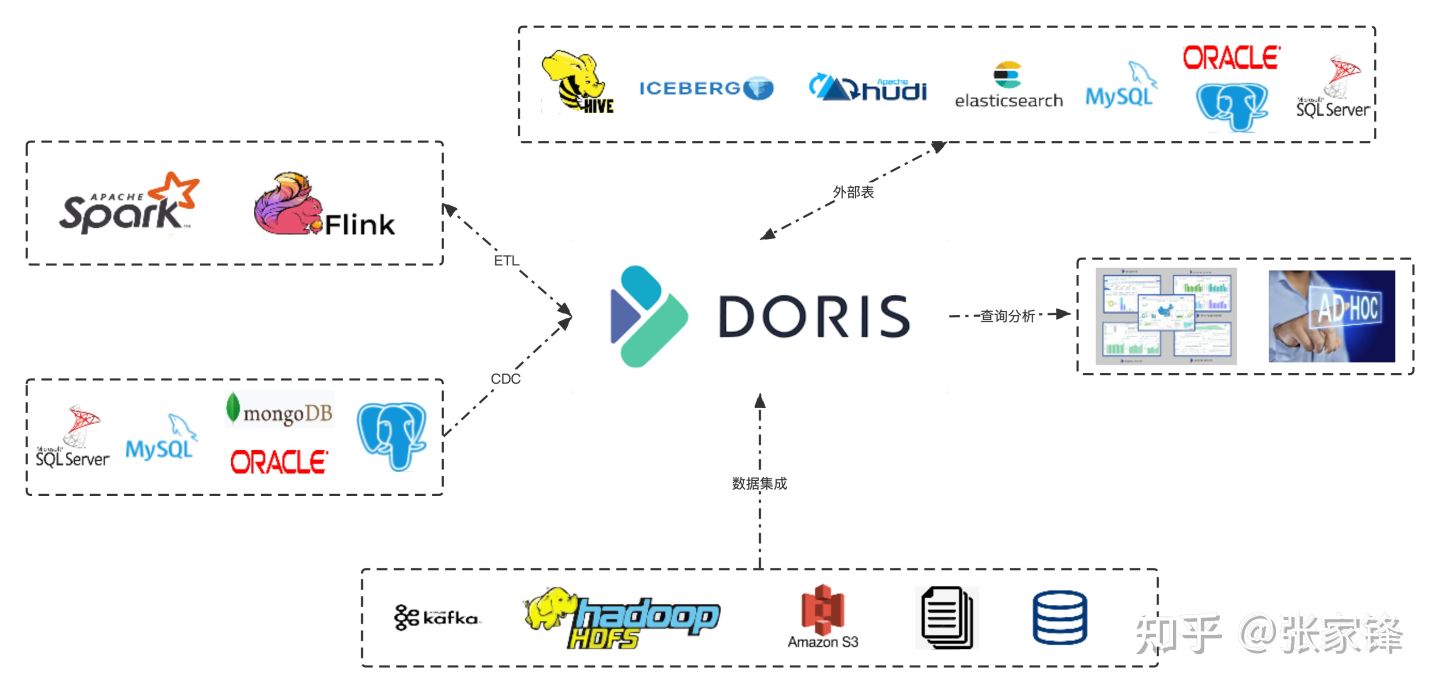
Doris 为了满足不同业务场景的数据接入需求,提供不丰富的数据导入方式,去支持不同的数据源:外部存储(HDFS,对象存储)、本地文件、消息队列(Kafka)及其他外部业务系统数据库(MySQL、Oracle、SQLServer、PostgreSQL等),支持同步和异步的方式将数据接入到 Doris 中。
Doris 数据计入方式及生态系统:
Broker Load
Broker Load 是一种异步的数据导入方式,通过 Broker 进程访问并读取外部数据源(如:HDFS,对象存储(支持S3协议)),然后通过 MySQL 协议,通过 Doris SQL 语句的方式将导入任务提交到 Doris ,然后通过
show load
查看数据导入进度及状态。
这种导入方式可以以支撑数据量达数百 GB 的导入作业。该导入方式支持 Hive 数据源的导入。
支持的数据格式:csv、orc、parquet
因为Doris 表里的数据是有序的,导入方式需要占用 Doris BE 资源进行对数据进行排序,在大数据量的数据导入的时候尽可能避开业务使用高峰,在资源相对空闲的时候进行导入。
Spark Load
Spark load 通过借助于外部的 Spark 计算资源实现对导入数据进行排序,提高 Doris 大数据量的导入性能并且节省 Doris 集群的计算资源。主要用于初次迁移,大数据量导入 Doris 的场景。对于历史海量数据迁移降低 Doris 集群资源使用及负载有很好的效果。
这种方式需要借助于Broker服务,适用于迁移大数据量(TB 级别)的场景。
Spark 支持将 hive 生成的 bitmap 数据直接导入到 Doris。详见 hive-bitmap-udf 文档。
支持的数据格式:csv、orc、parquet
Spark load 是一种异步导入方式,用户需要通过 MySQL 协议创建 Spark 类型导入任务,并通过
SHOW LOAD
查看导入结果
Stream Load
Stream Load 是一种同步的数据导入方式。用户通过 HTTP 协议提交请求并携带原始数据(可以是文件,也可以是内存数据)创建导入。主要用于快速将本地文件或数据流中的数据导入到 Doris。导入命令同步返回导入结果。
通过
SHOW STREAM LOAD
方式来查看 Stream load 作业情况,默认 BE 是不记录 Stream Load 的记录,如果你要查看需要在 BE 上启用记录,配置参数是:
enable_stream_load_record=true
,具体怎么配置请参照 BE 配置项
这种导入方式支持两种格式的数据 CVS 和 JSON 。
Stream load 支持本地文件导入,或者通过程序导入实时数据流中的数据,Spark Connector 和 Flink Connector 就是基于这种方式实现的。
Routine Load
Routine load 这种方式是以Kafka为数据源,从Kafka中读取数据并导入到Doris对应的数据表中,用户通过 Mysql 客户端提交 Routine Load数据导入作业,Doris 会在生成一个常驻线程,不间断的从 Kafka 中读取数据并存储在对应Doris表中,并自动维护 Kafka Offset位置。
通过
SHOW ROUTINE LOAD
来查看Routine load作业情况。
Insert Into
这种导入方式和 MySQL 中的 Insert 语句类似,Apache Doris 提供
INSERT INTO tbl SELECT ...;
的方式从 Doris 的表(或者ODBC方式的外表)中读取数据并导入到另一张表。或者通过
INSERT INTO tbl VALUES(...);
插入单条数据,单条插入方式不建议在生产和测试环境中使用,只是演示使用。
INSERT INTO tbl SELECT …
这种方式一般是在Doris内部对数据进行加工处理,生成中间汇总表,或者在Doris内部对数据进行ETL操作使用
这种方式是一种同步的数据导入方式。
数据导入
本例我们以 Stream load 导入当时为例,将文件中的数据导入到我们的之前创建的表(expamle_tbl)中 。
CREATE TABLE IF NOT EXISTS test_doris.example_tbl
(
`timestamp` DATE NOT NULL COMMENT "['0000-01-01', '9999-12-31']",
`type` TINYINT NOT NULL COMMENT "[-128, 127]",
`error_code` INT COMMENT "[-2147483648, 2147483647]",
`error_msg` VARCHAR(300) COMMENT "[1-65533]",
`op_id` BIGINT COMMENT "[-9223372036854775808, 9223372036854775807]",
`op_time` DATETIME COMMENT "['0000-01-01 00:00:00', '9999-12-31 23:59:59']",
`target` float COMMENT "4 字节",
`source` double COMMENT "8 字节",
`lost_cost` decimal(12,2) COMMENT "",
`remark` string COMMENT "1m size",
`op_userid` LARGEINT COMMENT "[-2^127 + 1 ~ 2^127 - 1]",
`plate` SMALLINT COMMENT "[-32768, 32767]",
`iscompleted` boolean COMMENT "true 或者 false"
)
DUPLICATE KEY(`timestamp`, `type`)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
我们创建一个本地文件 example_tbl.csv ,然后将下面的数据写入到这个 csv 文件中,最后我们通过 curl 命令行将这个文件中的数据导入到刚才我们创建的表里。
2022-9-06,1,101,None found,10000000000001,2022-9-06 12:23:24,1000001,2000001,2023.03,This is test doris import,10001,2,true
2022-9-05,2,102,Server Error,10000000000002,2022-9-05 15:23:24,1000003,2000003,202.03,This is test doris import,10002,3,false
我们通过下面的命令将数据导入到 Doris 表中
curl --location-trusted -u root: -T expamle_tbl.csv -H "column_separator:," -H "label:expamle_tbl_import_test" http://localhost:8030/api/test_doris/example_tbl/_stream_load
- 本例中 root 是 Doris 的用户名,默认密码是空,若有密码在root用户名后面的冒号后面跟上密码
- IP 地址是 FE 的 IP 地址,这里我们是在 FE 的本机,使用了127.0.0.1
- 8030 是 FE 的 http 端口,默认是8030
- test_doris 是我们的要导入数据表所在的数据库名称
- example_tbl:使我们刚才创建的表,也是我们要导入的数据表的名称
导入完成后会返回下面这样的 JSON 格式的响应数据。
{
"TxnId": 14031,
"Label": "expamle_tbl_import_test",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 2,
"NumberLoadedRows": 2,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 250,
"LoadTimeMs": 142,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 17,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 24,
"CommitAndPublishTimeMs": 96
}
- Status:导入任务的状态
- NumberTotalRows : 我们要导入的总数据记录数
- NumberLoadedRows:导入成功的记录数
查询
下面我们对刚才导入的数据表进行查询
select * from example_tbl;
查询指定字段并进行排序
mysql> select timestamp,error_code,op_id from example_tbl order by error_code desc;
+------------+------------+----------------+
| timestamp | error_code | op_id |
+------------+------------+----------------+
| 2022-09-05 | 102 | 10000000000002 |
| 2022-09-06 | 101 | 10000000000001 |
+------------+------------+----------------+
2 rows in set (0.02 sec)
Doris 支持多种 select 用法,包括:Join,子查询,With 子句 等,具体参照 SELECT 手册。
函数
Doris 提供了丰富的函数支持,包括:日期函数、数组函数、地理位置函数、字符串函数、聚合函数、Bitmap函数、Bitwise函数、条件函数、JSON函数、Hash函数、数学函数、表函数、窗口函数、加密函数、脱敏函数等,具体可以参照 Doris SQL 手册 -> SQL函数。
外部表
Doris 支持多种数据的外部表:ODBC外部表 、 Hudi外部表 , Iceberg外部表 , ElasticSearch外部表 , Hive外部表 。
其中 ODBC 外部表我们支持: MySQL、PostgreSQL、Oracle、SQLServer。
创建好外部表之后,可以通过查询外部表的方式将外部表的数据接入到 Doris 里,同时还可以和 Doris 里的表进行关联查询分析。
查询分析
Doris 支持多种方式分析查询瓶颈及优化查询性能
一般情况下出现慢查询,我们可以通过调整一个 Fragment 实例的并行数量
set parallel_fragment_exec_instance_num = 8;
来设置查询并行度,从而提高 CPU 资源利用率和查询效率。详细的参数介绍及设置,参考 查询并行度。
我们也可以通过分析 Doris SQL 执行计划和 Profile 来定位分析
查看执行计划
explain select timestamp,error_code,op_id from example_tbl order by error_code desc;
查看 Profile
首先我们需要开启Profile
set enable_profile = true;
然后执行 SQL,我们就可以看到这个 SQL 的 Profile
我们可以通过 Doris 提供的 WEBUI 来进行查看,我们在浏览器里输入FE的地址,登录后就可以看到
更详细讲解请参照 查询分析。
版权归原作者 hf200012 所有, 如有侵权,请联系我们删除。