
爬虫问题分析
回顾
之前写了一个爬取小说网站的多线程爬虫,操作流程如下:
先爬取小说介绍页,获取所有章节信息(章节名称,章节对应阅读链接),然后使用多线程的方式(
pool = Pool(50)
),通过章节的阅读链接爬取章节正文并保存为本地markdown文件。(代码见文末 run01.python)
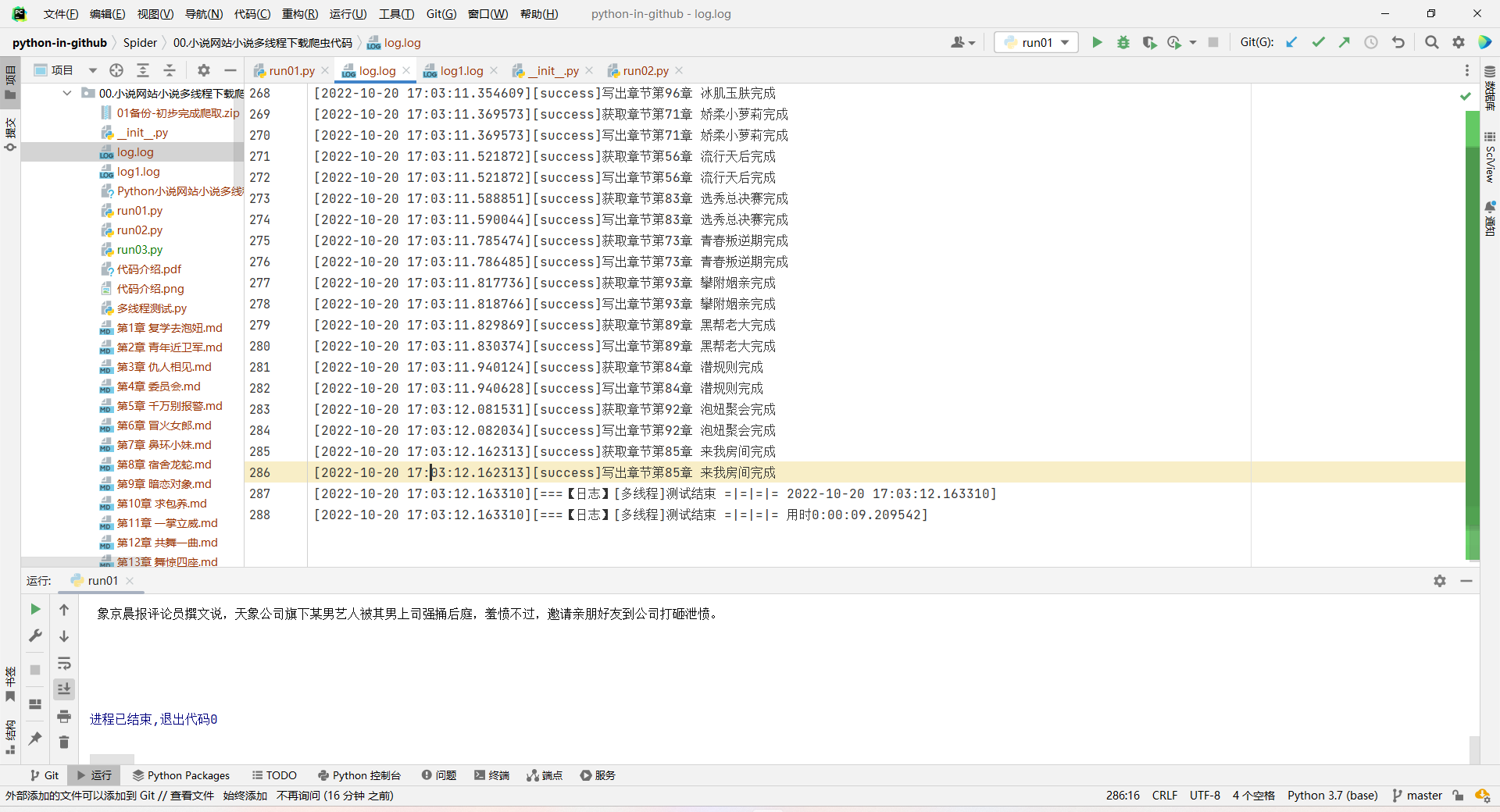

爬取100章,用了10秒
限制爬取101章,从运行程序到结束程序,用时9秒
Redis+MongoDB,无多线程
最近学了Redis和MongoDB,要求爬取后将章节链接放在redis,然后通过读取redis的章节链接来进行爬取。(代码见文末run02.python)
…不用测试了,一章一章读真的太慢了!

爬取101章用时两分钟!
Redis+MongoDB+多线程


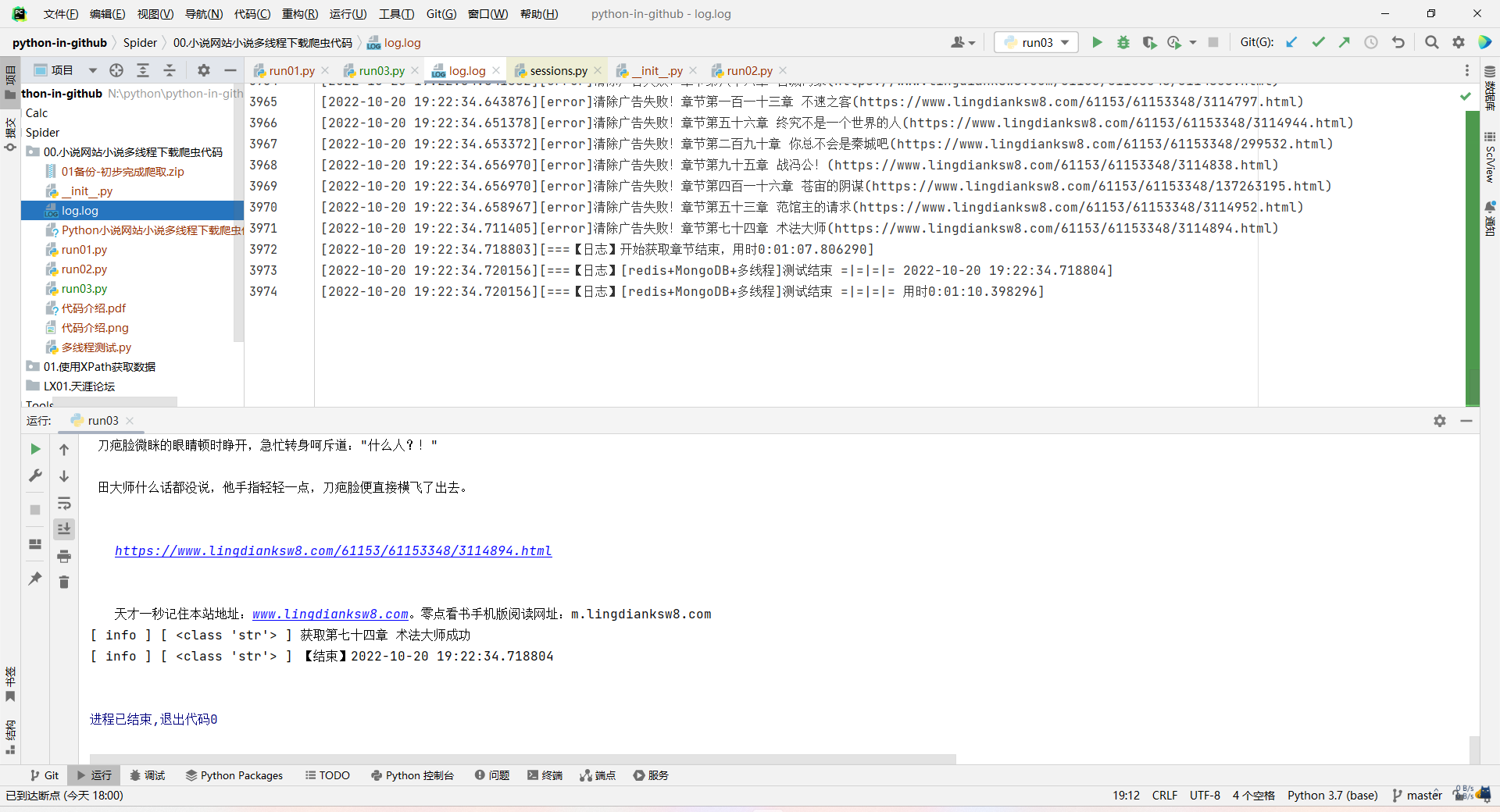
爬取101章,只需8秒!
爬取4012章,用时1分10秒!
问题与解析
懒得打字,我就录成视频发在小破站上面了。(小破站搜:萌狼蓝天)
[爬狼]Python爬虫经验分享第1节:代码文件简单介绍
[爬狼]Python爬虫经验分享第2节:编码问题的处理
[爬狼]Python爬虫经验分享第3节:多线程爬小说的顺序问题解决方案分享
[爬狼]Python爬虫经验分享第4节:爬取过于频繁被拦截的解决方案
其他的去我小破站主页翻
代码20221020
run01.py
# -*- coding: UTF-8 -*-
# 开发人员:萌狼蓝天
# 博客:Https://mllt.cc
# 笔记:Https://cnblogs.com/mllt
# 哔哩哔哩/微信公众号:萌狼蓝天
# 开发时间:2022/9/28
# https://www.lingdianksw8.com/31/31596/
import datetime
import re
import random
from multiprocessing import Pool
import requests
import bs4
import os
os.environ['NO_PROXY'] = "www.lingdianksw8.com"
def Log_text(lx="info", *text):
lx.upper()
with open("log.log", "a+", encoding="utf-8") as f:
f.write("\n[" + str(datetime.datetime.now()) + "]" + "[" + lx + "]")
for i in text:
f.write(i)
f.close()
# 调试输出
def log(message, i="info"):
if type(message) == type(""):
i.upper()
print("[", i, "] [", str(type(message)), "]", message)
elif type(message) == type([]):
count = 0
for j in message:
print("[", i, "] [", str(count), "] [", str(type(message)), "]", j)
count += 1
else:
print("[", i, "] [", str(type(message)), "]", end=" ")
print(message)
# 获取源码
def getCode(url, methods="post"):
"""
获取页面源码
:param methods: 请求提交方式
:param url:书籍首页链接
:return:页面源码
"""
# 设置请求头
user_agent = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
headers = {
'User-Agent': random.choice(user_agent),
# "user-agent": user_agent[random.randint(0, len(user_agent) - 1)]
}
# 获取页面源码
result = requests.request(methods, url, headers=headers, allow_redirects=True)
log("cookie" + str(result.cookies.values()))
tag = 0
log("初始页面编码为:" + result.encoding)
if result.encoding != "gbk":
log("初始页面编码非gbk,需要进行重编码操作", "warn")
tag = 1
try:
result = requests.request(methods, url, headers=headers, allow_redirects=True, cookies=result.cookies)
except:
return "InternetError"
result_text = result.text
# print(result_text)
if tag == 1:
result_text = recoding(result)
log("转码编码完成,当前编码为gbk")
return result_text
def recoding(result):
try:
result_text = result.content.decode("gbk",errors='ignore')
except:
# UnicodeDecodeError: 'gbk' codec can't decode byte 0xae in position 6917:
try:
result_text = result.content.decode("").encode("unicode_escape").decode("gbk",errors='ignore')
except:
try:
result_text = result.content.decode("gb18030",errors='ignore')
except:
result_text = result.text
return result_text
# 分析数据
def getDict(code):
"""
分析网页源码,获取数据,并存储为以字典元素构成的列表返回
:param code:网页源码
:return:List
"""
# 通过正则的方式缩小范围
code = re.findall("正文卷</dt>(.*?)</dl>", code, re.S)[0]
# log(code)
# obj = bs4.BeautifulSoup(markup=code,features="html.parser")
obj = bs4.BeautifulSoup(markup=code, features="lxml")
# log("输出结果")
# log(obj.find_all("a"))
# 通过上面调试输出可知得到的是个列表
tag = obj.find_all("a")
log("tag长度为:" + str(len(tag)))
result = []
count = 0
for i in range(len(tag)):
count += 1
link = tag[i]["href"]
text = tag[i].get_text()
result.append({"title": text, "link": "https://www.lingdianksw8.com" + link})
return result
# 文章内容
def getContent(url):
code = getCode(url, "get")
if code=="InternetError":
return "InternetError",""
try:
code = code.replace("<br />", "\n")
code = code.replace(" ", " ")
code = code.replace(" ", " ")
except Exception as e:
# AttributeError: 'tuple' object has no attribute 'replace'
Log_text("error","[run01-161~163]"+str(e))
# with open("temp.txt","w+",encoding="utf-8") as f:
# f.write(code)
obj = bs4.BeautifulSoup(markup=code, features="lxml")
titile = obj.find_all("h1")[0].text
try:
content = obj.find_all("div", attrs={"class": "showtxt"})[0].text
except:
return None, None
# with open("temp.txt", "w+", encoding="utf-8") as f:
# f.write(content)
# log(content)
try:
g = re.findall(
"(:.*?https://www.lingdianksw8.com.*?天才一秒记住本站地址:www.lingdianksw8.com。零点看书手机版阅读网址:.*?.com)",
content, re.S)[0]
log(g)
content = content.replace(g, "")
except:
Log_text("error", "清除广告失败!章节" + titile + "(" + url + ")")
log(content)
return titile, content
def docToMd(name, title, content):
with open(name + ".md", "w+", encoding="utf-8") as f:
f.write("## " + title + "/n" + content)
f.close()
return 0
# 多线程专供函数 - 通过链接获取文章
def thead_getContent(link):
# 根据链接获取文章内容
Log_text("info", "尝试获取" + str(link))
title, content = getContent(str(link)) # 从文章内获取到标题和内容
Log_text("success", "获取章节" + title + "完成")
docToMd(title, title, content)
Log_text("success", "写出章节" + title + "完成")
# 操作汇总
def run(url):
with open("log1.log", "w+", encoding="utf-8") as f:
f.write("")
f.close()
Log_text("info", "开始获取小说首页...")
code = getCode(url)
Log_text("success", "获取小说首页源代码完成,开始分析...")
index = getDict(code) # 获取到[{章节名称title:链接link}]
links = []
# lineCount限制要爬取的数量
lineCount = 0
for i in index:
if lineCount > 10:
break
lineCount += 1
links.append(i["link"])
print("链接状态")
print(type(links))
print(links)
Log_text("success", "分析小说首页完成,数据整理完毕,开始获取小说内容...")
pool = Pool(50) # 多线程
pool.map(thead_getContent, links)
if __name__ == '__main__':
start = datetime.datetime.today()
Log_text("===【日志】[多线程-]开始新的测试 =|=|=|= " + str(start))
run(r"https://www.lingdianksw8.com/31/31596")
# getContent("http://www.lingdianksw8.com/31/31596/8403973.html")
end = datetime.datetime.today()
Log_text("===【日志】[多线程]测试结束 =|=|=|= " + str(end))
Log_text("===【日志】[多线程]测试结束 =|=|=|= 用时" + str(end - start))
print("")
run02.py
# -*- coding: UTF-8 -*-
# 开发人员:萌狼蓝天
# 博客:Https://mllt.cc
# 笔记:Https://cnblogs.com/mllt
# 哔哩哔哩/微信公众号:萌狼蓝天
# 开发时间:2022/9/28
# https://www.lingdianksw8.com/31/31596/
"""
1.通过run01获取章节的链接,将链接存储到Redis中
2.从Redis获取章节链接并爬取
"""
import re
import pymongo
from lxml import html
import run01 as xrilang
import redis
import datetime
client = redis.StrictRedis()
def getLinks():
xrilang.Log_text("===【日志】开始获取章节名称和链接")
code = xrilang.getCode("https://www.lingdianksw8.com/61153/61153348/","get")
source = re.findall("正文卷</dt>(.*?)</dl>", code, re.S)[0]
selector = html.fromstring(source)
title_list = selector.xpath("//dd/a/text()")
url_list = selector.xpath("//dd/a/@href")
client.flushall() # 清空Redis全部内容,避免重复运行造成的数据重复
xrilang.Log_text("===【日志】开始获取标题")
for title in title_list:
xrilang.log(title)
client.lpush('title_queue', title)
xrilang.Log_text("===【日志】开始获取章节链接")
for url in url_list:
xrilang.log(url)
client.lpush('url_queue', url)
xrilang.log(client.llen('url_queue'))
xrilang.Log_text("===【日志】获取章节链接结束,共"+str(client.llen('url_queue'))+"条")
def getContent():
xrilang.Log_text("===【日志】开始获取章节内容")
database = pymongo.MongoClient()['book']
collection = database['myWifeSoBeautifull']
startTime=datetime.datetime.today()
xrilang.log("开始"+str(startTime))
linkCount=0
datas=[]
while client.llen("url_queue")>0:
# 爬取101章
if linkCount >10:
break
linkCount += 1
url = client.lpop("url_queue").decode()
title = client.lpop("title_queue").decode()
xrilang.log(url)
# 获取文章内容并保存到数据库
content_url = "https://www.lingdianksw8.com"+url
name,content = xrilang.getContent(content_url)
if name!=None and content!=None:
datas.append({"title":title,"name":name,"content":content})
collection.insert_many(datas)
if __name__ == '__main__':
start = datetime.datetime.today()
xrilang.Log_text("===【日志】[redis+MongoDB无多线程]开始新的测试 =|=|=|= " + str(start))
getLinks()
getContent()
end = datetime.datetime.today()
xrilang.Log_text("===【日志】[redis+MongoDB无多线程]测试结束 =|=|=|= " + str(end))
xrilang.Log_text("===【日志】[redis+MongoDB无多线程]测试结束 =|=|=|= 用时" + str(end-start))
print("")
run03.py
# -*- coding: UTF-8 -*-
# 开发人员:萌狼蓝天
# 博客:Https://mllt.cc
# 笔记:Https://cnblogs.com/mllt
# 哔哩哔哩/微信公众号:萌狼蓝天
# 开发时间:2022/9/28
# https://www.lingdianksw8.com/31/31596/
"""
1.通过run01获取章节的链接,将链接存储到Redis中
2.从Redis获取章节链接并爬取
"""
import re
import time
from multiprocessing.dummy import Pool
import pymongo
from lxml import html
import run01 as xrilang
import redis
import datetime
client = redis.StrictRedis()
database = pymongo.MongoClient()['book']
collection = database['myWifeSoBeautifull']
def getLinks():
xrilang.Log_text("===【日志】开始获取章节名称和链接")
code = xrilang.getCode("https://www.lingdianksw8.com/61153/61153348/","get")
source = re.findall("正文卷</dt>(.*?)</dl>", code, re.S)[0]
selector = html.fromstring(source)
url_list = selector.xpath("//dd/a/@href")
client.flushall() # 清空Redis全部内容,避免重复运行造成的数据重复
xrilang.Log_text("===【日志】开始获取章节链接")
i=0
for url in url_list:
xrilang.log(url)
client.lpush('url_queue', url)
i+=1
client.lpush('sort_queue', i) # 解决多线程爬虫导致的顺序问题
xrilang.log(client.llen('url_queue'))
xrilang.Log_text("===【日志】获取章节链接结束,共"+str(client.llen('url_queue'))+"条")
def getContent(durl):
url = durl["url"]
isort=durl["isort"]
content_url = "https://www.lingdianksw8.com" + url
title, content = xrilang.getContent(content_url)
if title != "InternetError":
if title != None and content != None:
xrilang.log("获取"+title+"成功")
collection.insert_one({"isort":isort,"title": title, "content": content})
else:
# 没有成功爬取的添加回redis,等待下次爬取
client.lpush('url_queue', url)
client.lpush('sort_queue', isort) # 解决多线程爬虫导致的顺序问题
# 等待5秒
time.sleep(1000)
else:
# 没有成功爬取的添加回redis,等待下次爬取
client.lpush('url_queue', url)
client.lpush('sort_queue', isort) # 解决多线程爬虫导致的顺序问题
# 等待5秒
time.sleep(5000)
def StartGetContent():
xrilang.Log_text("===【日志】开始获取章节内容")
startTime = datetime.datetime.today()
xrilang.log("开始"+str(startTime))
urls=[]
# xrilang.log(client.llen("url_queue"))
while client.llen("url_queue")>0:
url = client.lpop("url_queue").decode()
isort= client.lpop("sort_queue").decode()
#urls.append(url)
urls.append({"url":url,"isort":isort})
# xrilang.log(urls)
pool = Pool(500) # 多线程
pool.map(getContent,urls)
endTime=datetime.datetime.today()
xrilang.log("【结束】"+str(endTime))
xrilang.Log_text("===【日志】开始获取章节结束,用时"+str(endTime-startTime))
if __name__ == '__main__':
start = datetime.datetime.today()
xrilang.Log_text("===【日志】[redis+MongoDB+多线程]开始新的测试 =|=|=|= " + str(start))
getLinks()
StartGetContent()
end = datetime.datetime.today()
xrilang.Log_text("===【日志】[redis+MongoDB+多线程]测试结束 =|=|=|= " + str(end))
xrilang.Log_text("===【日志】[redis+MongoDB+多线程]测试结束 =|=|=|= 用时" + str(end-start))
print("")
mongoQ.py
# -*- coding: UTF-8 -*-
# 开发人员:萌狼蓝天
# 博客:Https://mllt.cc
# 笔记:Https://cnblogs.com/mllt
# 哔哩哔哩/微信公众号:萌狼蓝天
# 开发时间:2022/10/20
import pymongo
database = pymongo.MongoClient()['book']
collection = database['myWifeSoBeautifull']
result = collection.find().collation({"locale":"zh", "numericOrdering":True}).sort("isort")
with open("list.txt", "a+", encoding="utf-8") as f:
for i in result:
f.writelines(i["isort"]+" "+i["title"]+"\n")
代码20221019
run01.py
# -*- coding: UTF-8 -*-
# 开发人员:萌狼蓝天
# 博客:Https://mllt.cc
# 笔记:Https://cnblogs.com/mllt
# 哔哩哔哩/微信公众号:萌狼蓝天
# 开发时间:2022/9/28
# https://www.lingdianksw8.com/31/31596/
import datetime
import re
import random
from multiprocessing import Pool
import requests
import bs4
import os
os.environ['NO_PROXY'] = "www.lingdianksw8.com"
def Log_text(lx="info", *text):
lx.upper()
with open("log.log", "a+", encoding="utf-8") as f:
f.write("\n[" + str(datetime.datetime.now()) + "]" + "[" + lx + "]")
for i in text:
f.write(i)
f.close()
# 调试输出
def log(message, i="info"):
if type(message) == type(""):
i.upper()
print("[", i, "] [", str(type(message)), "]", message)
elif type(message) == type([]):
count = 0
for j in message:
print("[", i, "] [", str(count), "] [", str(type(message)), "]", j)
count += 1
else:
print("[", i, "] [", str(type(message)), "]", end=" ")
print(message)
# 获取源码
def getCode(url, methods="post"):
"""
获取页面源码
:param methods: 请求提交方式
:param url:书籍首页链接
:return:页面源码
"""
# 设置请求头
user_agent = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
headers = {
'User-Agent': random.choice(user_agent),
# "user-agent": user_agent[random.randint(0, len(user_agent) - 1)]
}
# 获取页面源码
result = requests.request(methods, url, headers=headers, allow_redirects=True)
log("cookie" + str(result.cookies.values()))
tag = 0
log("初始页面编码为:" + result.encoding)
if result.encoding == "gbk" or result.encoding == "ISO-8859-1":
log("初始页面编码非UTF-8,需要进行重编码操作", "warn")
tag = 1
try:
result = requests.request(methods, url, headers=headers, allow_redirects=True, cookies=result.cookies)
except:
return "InternetError",""
result_text = result.text
# print(result_text)
if tag == 1:
result_text = recoding(result)
log("转码编码完成,当前编码为gbk")
return result_text
def recoding(result):
try:
result_text = result.content.decode("gbk",errors='ignore')
except:
# UnicodeDecodeError: 'gbk' codec can't decode byte 0xae in position 6917:
try:
result_text = result.content.decode("").encode("unicode_escape").decode("gbk",errors='ignore')
except:
try:
result_text = result.content.decode("gb18030",errors='ignore')
except:
result_text = result.text
return result_text
# 分析数据
def getDict(code):
"""
分析网页源码,获取数据,并存储为以字典元素构成的列表返回
:param code:网页源码
:return:List
"""
# 通过正则的方式缩小范围
code = re.findall("正文卷</dt>(.*?)</dl>", code, re.S)[0]
# log(code)
# obj = bs4.BeautifulSoup(markup=code,features="html.parser")
obj = bs4.BeautifulSoup(markup=code, features="lxml")
# log("输出结果")
# log(obj.find_all("a"))
# 通过上面调试输出可知得到的是个列表
tag = obj.find_all("a")
log("tag长度为:" + str(len(tag)))
result = []
count = 0
for i in range(len(tag)):
count += 1
link = tag[i]["href"]
text = tag[i].get_text()
result.append({"title": text, "link": "https://www.lingdianksw8.com" + link})
return result
# 文章内容
def getContent(url):
code = getCode(url, "get")
try:
code = code.replace("<br />", "\n")
code = code.replace(" ", " ")
code = code.replace(" ", " ")
except Exception as e:
# AttributeError: 'tuple' object has no attribute 'replace'
Log_text("error","[run01-161~163]"+str(e))
# with open("temp.txt","w+",encoding="utf-8") as f:
# f.write(code)
obj = bs4.BeautifulSoup(markup=code, features="lxml")
titile = obj.find_all("h1")[0].text
try:
content = obj.find_all("div", attrs={"class": "showtxt"})[0].text
except:
return None, None
# with open("temp.txt", "w+", encoding="utf-8") as f:
# f.write(content)
# log(content)
try:
g = re.findall(
"(:.*?https://www.lingdianksw8.com.*?天才一秒记住本站地址:www.lingdianksw8.com。零点看书手机版阅读网址:.*?.com)",
content, re.S)[0]
log(g)
content = content.replace(g, "")
except:
Log_text("error", "清除广告失败!章节" + titile + "(" + url + ")")
log(content)
return titile, content
def docToMd(name, title, content):
with open(name + ".md", "w+", encoding="utf-8") as f:
f.write("## " + title + "/n" + content)
f.close()
return 0
# 多线程专供函数 - 通过链接获取文章
def thead_getContent(link):
# 根据链接获取文章内容
Log_text("info", "尝试获取" + str(link))
title, content = getContent(str(link)) # 从文章内获取到标题和内容
Log_text("success", "获取章节" + title + "完成")
docToMd(title, title, content)
Log_text("success", "写出章节" + title + "完成")
# 操作汇总
def run(url):
with open("log1.log", "w+", encoding="utf-8") as f:
f.write("")
f.close()
Log_text("info", "开始获取小说首页...")
code = getCode(url)
Log_text("success", "获取小说首页源代码完成,开始分析...")
index = getDict(code) # 获取到[{章节名称title:链接link}]
links = []
# lineCount限制要爬取的数量
lineCount = 0
for i in index:
if lineCount > 100:
break
lineCount += 1
links.append(i["link"])
print("链接状态")
print(type(links))
print(links)
Log_text("success", "分析小说首页完成,数据整理完毕,开始获取小说内容...")
pool = Pool(50) # 多线程
pool.map(thead_getContent, links)
if __name__ == '__main__':
start = datetime.datetime.today()
Log_text("===【日志】[多线程-]开始新的测试 =|=|=|= " + str(start))
run(r"https://www.lingdianksw8.com/31/31596")
# getContent("http://www.lingdianksw8.com/31/31596/8403973.html")
end = datetime.datetime.today()
Log_text("===【日志】[多线程]测试结束 =|=|=|= " + str(end))
Log_text("===【日志】[多线程]测试结束 =|=|=|= 用时" + str(end - start))
print("")
run02.py
# -*- coding: UTF-8 -*-
# 开发人员:萌狼蓝天
# 博客:Https://mllt.cc
# 笔记:Https://cnblogs.com/mllt
# 哔哩哔哩/微信公众号:萌狼蓝天
# 开发时间:2022/9/28
# https://www.lingdianksw8.com/31/31596/
"""
1.通过run01获取章节的链接,将链接存储到Redis中
2.从Redis获取章节链接并爬取
"""
import re
import pymongo
from lxml import html
import run01 as xrilang
import redis
import datetime
client = redis.StrictRedis()
def getLinks():
xrilang.Log_text("===【日志】开始获取章节名称和链接")
code = xrilang.getCode("https://www.lingdianksw8.com/61153/61153348/","get")
source = re.findall("正文卷</dt>(.*?)</dl>", code, re.S)[0]
selector = html.fromstring(source)
title_list = selector.xpath("//dd/a/text()")
url_list = selector.xpath("//dd/a/@href")
client.flushall() # 清空Redis全部内容,避免重复运行造成的数据重复
xrilang.Log_text("===【日志】开始获取标题")
for title in title_list:
xrilang.log(title)
client.lpush('title_queue', title)
xrilang.Log_text("===【日志】开始获取章节链接")
for url in url_list:
xrilang.log(url)
client.lpush('url_queue', url)
xrilang.log(client.llen('url_queue'))
xrilang.Log_text("===【日志】获取章节链接结束,共"+str(client.llen('url_queue'))+"条")
def getContent():
xrilang.Log_text("===【日志】开始获取章节内容")
database = pymongo.MongoClient()['book']
collection = database['myWifeSoBeautifull']
startTime=datetime.datetime.today()
xrilang.log("开始"+str(startTime))
linkCount=0
datas=[]
while client.llen("url_queue")>0:
# 爬取101章
if linkCount >10:
break
linkCount += 1
url = client.lpop("url_queue").decode()
title = client.lpop("title_queue").decode()
xrilang.log(url)
# 获取文章内容并保存到数据库
content_url = "https://www.lingdianksw8.com"+url
name,content = xrilang.getContent(content_url)
if name!=None and content!=None:
datas.append({"title":title,"name":name,"content":content})
collection.insert_many(datas)
if __name__ == '__main__':
start = datetime.datetime.today()
xrilang.Log_text("===【日志】[redis+MongoDB无多线程]开始新的测试 =|=|=|= " + str(start))
getLinks()
getContent()
end = datetime.datetime.today()
xrilang.Log_text("===【日志】[redis+MongoDB无多线程]测试结束 =|=|=|= " + str(end))
xrilang.Log_text("===【日志】[redis+MongoDB无多线程]测试结束 =|=|=|= 用时" + str(end-start))
print("")
run03.py
# -*- coding: UTF-8 -*-
# 开发人员:萌狼蓝天
# 博客:Https://mllt.cc
# 笔记:Https://cnblogs.com/mllt
# 哔哩哔哩/微信公众号:萌狼蓝天
# 开发时间:2022/9/28
# https://www.lingdianksw8.com/31/31596/
"""
1.通过run01获取章节的链接,将链接存储到Redis中
2.从Redis获取章节链接并爬取
"""
import re
import time
from multiprocessing.dummy import Pool
import pymongo
from lxml import html
import run01 as xrilang
import redis
import datetime
client = redis.StrictRedis()
database = pymongo.MongoClient()['book']
collection = database['myWifeSoBeautifull']
def getLinks():
xrilang.Log_text("===【日志】开始获取章节名称和链接")
code = xrilang.getCode("https://www.lingdianksw8.com/61153/61153348/","get")
source = re.findall("正文卷</dt>(.*?)</dl>", code, re.S)[0]
selector = html.fromstring(source)
url_list = selector.xpath("//dd/a/@href")
client.flushall() # 清空Redis全部内容,避免重复运行造成的数据重复
xrilang.Log_text("===【日志】开始获取章节链接")
i=0
for url in url_list:
xrilang.log(url)
client.lpush('url_queue', url)
i+=1
client.lpush('sort_queue', i) # 解决多线程爬虫导致的顺序问题
xrilang.log(client.llen('url_queue'))
xrilang.Log_text("===【日志】获取章节链接结束,共"+str(client.llen('url_queue'))+"条")
def getContent(durl):
url = durl["url"]
isort=durl["isort"]
content_url = "https://www.lingdianksw8.com" + url
title, content = xrilang.getContent(content_url)
if title != None and content != None:
if (title != "InternetError"):
xrilang.log("获取"+title+"成功")
collection.insert_one({"isort":isort,"title": title, "content": content})
else:
# 没有成功爬取的添加回redis,等待下次爬取
client.lpush('url_queue', url)
client.lpush('sort_queue', isort) # 解决多线程爬虫导致的顺序问题
# 等待5秒
time.sleep(5000)
def StartGetContent():
xrilang.Log_text("===【日志】开始获取章节内容")
startTime = datetime.datetime.today()
xrilang.log("开始"+str(startTime))
urls=[]
# xrilang.log(client.llen("url_queue"))
while client.llen("url_queue")>0:
url = client.lpop("url_queue").decode()
isort= client.lpop("sort_queue").decode()
#urls.append(url)
urls.append({"url":url,"isort":isort})
# xrilang.log(urls)
pool = Pool(500) # 多线程
pool.map(getContent,urls)
endTime=datetime.datetime.today()
xrilang.log("【结束】"+str(endTime))
xrilang.Log_text("===【日志】开始获取章节结束,用时"+str(endTime-startTime))
if __name__ == '__main__':
start = datetime.datetime.today()
xrilang.Log_text("===【日志】[redis+MongoDB+多线程]开始新的测试 =|=|=|= " + str(start))
getLinks()
StartGetContent()
end = datetime.datetime.today()
xrilang.Log_text("===【日志】[redis+MongoDB+多线程]测试结束 =|=|=|= " + str(end))
xrilang.Log_text("===【日志】[redis+MongoDB+多线程]测试结束 =|=|=|= 用时" + str(end-start))
print("")
本文转载自: https://blog.csdn.net/ks2686/article/details/127436518
版权归原作者 萌狼蓝天 所有, 如有侵权,请联系我们删除。
版权归原作者 萌狼蓝天 所有, 如有侵权,请联系我们删除。