
什么是存算分离?
存算分离架构是一种新的数据架构的设计范式,自上而下分为数据分析层、计算层和存储层,其中计算层和存储层解耦合,都是独立的分布式服务。其设计的目标是要解决三个需求:数据可以灵活开放给不同业务做数据分析、计算和存储独立扩展以及计算与存储的资源隔离,同时也提供与存算一体架构等同的存算性能。
随着硬件技术的快速进步,尤其是网络和存储设备的性能迅速提升,以及云计算厂商推动软硬件协同加速的云存储服务,越来越多的企业开始基于云存储来构建数据存储服务,或数据湖,因此就需要单独再建设一个独立的计算层来提供数据分析服务,这也就是存算分离架构(Disaggregated Storage and Compute Architecture)。
最近几年,存算分离架构不仅在公有云上广泛落地,在私有化场景下,也逐渐成为热点。但是需要特别强调的是,存算分离架构并不等同于采用兼容S3接口的对象存储来构建数据湖,也不是采用容器化来实现资源隔离或者弹性伸缩,更好的满足业务需求是存算架构升级的一个根本原因。
为什么需要存算分离?
异构的工作负载: 得益于现在云原生的环境,用户可以自由配置每台云服务器的cpu型号,内存,磁盘,带宽。但是存在的问题是适合高 I/O 带宽、轻计算的系统配置不适合复杂查询,而适合复杂查询的系统配置却不能满足高吞吐的要求。简单的理解为需要在计算和IO之间做平衡。
扩缩容: 由于计算和存储的耦合,当扩缩容的时候势必需要在节点之间移动数据,而节点同时需要对外提供计算服务,因此此时的性能可能会收到很大影响。如果存储分离,那么计算层和存储层可以独立增加减少节点而互不干扰。
从一个抽象的角度,其存储层和计算层相对独立,存储层采用HDFS或其他与Hadoop兼容存储(HCFS)甚至是关系型数据库,而计算层一般采用多样化的计算引擎,如Spark、Presto、Flink等。这种架构带来的的好处主要在以下三个方面:
- 更方便的为不同的业务提供数据分析服务,对接不同的计算引擎,避免热门数据要在不同的业务都重复存储的问题。
- 计算层和存储层可以按照各自业务的需求来做独立扩缩容,一般情况下计算资源的增长速度要显式快于存储增长,这种方式就可以减少存储部分的成本。
- 计算服务与存储服务相对资源隔离,对业务稳定性也有很好的提高
分布式数据库系统架构

数据库系统架构典型的架构有Shared Everything、Shared Memory、Shared Disk和Shared Nothing。这里Share的资源主要是指内存,磁盘。
单机数据库系统称为shared everything,因为是单机节点,有自己独立的内存空间和独立的磁盘。
Shared Memory
现实中并不常见,多个cpu通过网络来共享一个内存地址空间,并且共享同一个disk。
Shared Disk
多个数据库实例,每个实例有自己的内存,但是通过网络共享同一个disk。Shared Disk架构在云原生比较常见,这样的好处就是利于存算分离,计算层和存储层能够解耦,因此计算层和存储层在扩缩容的时候彼此不影响。缺点是因为共享disk,因此对于高并发的写请求势必性能会比较差,因此这种架构比较适合OLAP这种读多写少的数仓。
Shared Nothing
各个数据库实例,都有自己的内存和disk,这些实例之间只能通过网络通信来感知各个实例的状态变化。通常表会水平划分到各个节点,每个节点只负责其本地磁盘上的数据行。 这种设计非常适合星型模式查询,因为连接维度比较小的维度表和宽的事实表所需的带宽非常少。Share Nothing架构的优点在于性能和效率比较高,缺点在于灵活性较差,因为扩缩容的时候,需要在节点之间移动数据。而且对于事物的支持性较差,因为各个节点之间必须通过网络进行协调。
SnowFlake中的存算分离
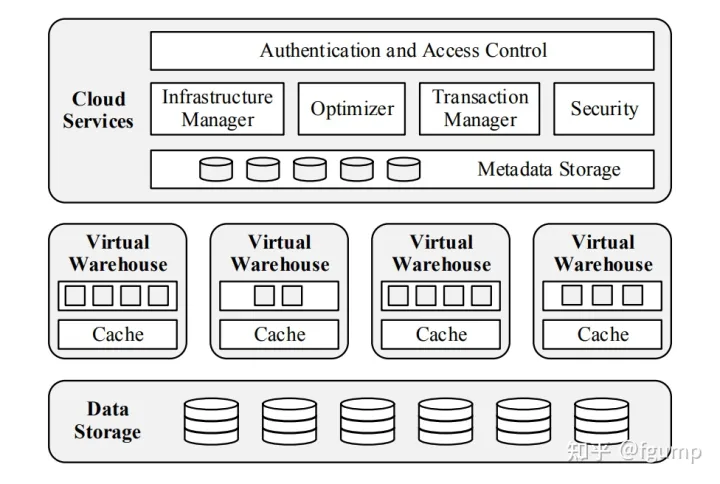
Data Storage : 存储层使用S3
Virtual Warehouses : SnowFlake的计算层,负责执行查询计算。 由多个EC2实例组成,是MPP架构。
Cloud Services : 主要对外提供服务,用户无法感知到VW的存在。维护元数据信息。主要包括database schemas, access control information, encryption keys, usage statistics。
SnowFlake通过VW和S3来将计算和存储分离。整体上来看是使用了Shared Disk架构。但是为了减少VW和S3之间的数据传输,SnowFlake通过本地磁盘做一个cache系统。如果cache系统做的比较好,那么性能上面几乎可以媲美于share nothing架构。
TiDB中的存算分离
TiDB中的核心理念基本源自于Spanner。 TiDB将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:

TiDB中的核心理念基本源自于Spanner。 TiDB将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:
TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构。
TiKV Server:存储数据节点,内部使用Raft一致性协议来维护数据。
TiDB通过在TiDB层实现了计算,在TiKV实现了存储来解耦计算和存储。
ClickHouse 是一个典型的Shared Nothing架构的分布式数据库,2022年ClickHouse社区的RoadMap中存算分离也是一个大的方向。目前ClickHouse已经支持DiskOss,设想一个可能的方案,类比于SnowFlake,很容易扩展为一个Shared Disk架构。但是还需要完成一个元数据信息的管理功能以支持动态的扩缩容。
成本:由于存算一体,计算资源和存储资源是按某一比例强绑定,系统扩容必须按节点数目增加,导致内存或磁盘的浪费。另外由于使用3副本的数据存储模式,在大集群(100+ 节点、PB级别)下将造成高昂的存储成本。
资源利用率低:由于多个Hadoop 集群承接不同的工作负载,随着支撑业务需求的波动,系统负载出现峰谷,然而存算一体的架构导致各集群的资源完全独立隔离不能共享(跨行业的存算一体架构下的Hadoop集群平均资源利用率在25%以下)。
考虑到上述问题,不少企业开始思考这种一体化架构以及数据本地化的必要性。2012年前后,Facebook、AWS等厂商基于GFS论文中的EC算法,提出了存储和计算分离的架构原型。2014年,EMC Isilon使用One File System (OneFS)作为底层文件系统提供EC能力,并局部兼容HDFS以RPC协议来连接Hadoop计算集群,从而为Hadoop集群实现了存算分离的能力。
随着新兴业务的发展,解决数据存得下的问题已经无法满足企业大数据建设的诉求,下一代大数据存储应该更多以数据为中心,聚焦数据用得好的问题,以数据驱动融合分析、统一存储,进一步驱动数据价值实时变现。

Hadoop三代版本的演进中证明了存算分离已成为大数据建设的必然趋势。
开源社区提出了湖仓融合的新兴数据格式,支持数据湖、数据仓库使用同一种格式,同一份数据支持多种组件访问,减少数据重复存储和搬迁,缩短了数据加工链路、减少中间过程的同时,大大提高了数据分析的效率。
华为海量存储在商用的存算分离1.0方案满足降成本的客户需求后,当前率先在存储上支持湖仓融合的新兴数据格式,在下一代存算分离架构下,基于一份数据支持接数据湖、数据仓库同时访问。提供以业务为中心的高弹性大数据计算,以数据为中心的高性能海量存储,用户无感知的原生HDFS和S3兼容能力,进一步向湖仓一体、一湖多云、实时分析演进。

版权归原作者 振宅的博客 所有, 如有侵权,请联系我们删除。