

开篇:一次小小的技术讨论
Aliware
周末的时候,和一位在国内某互联网公司负责运维的朋友聊天,由于工作相关,刚好聊到了公司项目中微服务架构这块的一些问题,他们公司的微服务架构使用的是业界比较常用的 Spring Cloud Netflix 那一套作为底座,有专门的同学负责运维一套自建的 Eureka 集群来作为微服务注册中心。服务注册中心作为微服务领域的核心组件,承载着公司核心业务的高频服务,一旦遇到可用性问题,就会大面积影响线上业务。
朋友说自从他接手负责这块之后,已经慢慢在业务发展过程中感到对这个 Eureka 集群运维上的有心无力,被拖住了人力暂且不说,日常故障频发的状态也搞的整个人心力交瘁。谈到好几个工作中碰到的问题,梳理了下发现基本上都是围绕着 Eureka 集群性能、运维能力、维护成本相关的。聊了很久在一起交流了下方案,当提议他要不考虑用 MSE Nacos 吧,朋友两手一摊,现在公司有那么多研发小组再去全部推动升级一遍哪有那么容易的。我又问他,那如果什么代码都不需要你们改呢,0 成本,心动吗?
见招拆招
Aliware
**Round 1 - 突破性能瓶颈
**
第一个碰到的痛点是当前朋友公司的 Eureka 集群里注册的服务实例数已经过万了,集群水位一直居高不下,CPU 占用率、负载都很高,时不时还会发生 Full GC 导致业务抖动。其实这是因为 Eureka Server 是传统的对等星型同步 AP 模型导致的,各 Server 节点角色相等完全对等,在这种多实例场景下,对于每次变更(注册/反注册/心跳续约/服务状态变更等)都会生成相应的同步任务来用于所有实例数据的同步,这样一来同步作业量随着集群规模、实例数正相关同步上涨。
再加上 Eureka 的二级队列发布模型机制和限流延迟策略,极易造成同步任务积压从而导致服务端的高负载影响性能。如果这个时候再不凑巧,碰上网络抖动的情况,引发了同步任务的重试风暴则会进一步加重集群性能问题,从而最终影响正常业务的稳定性,这一点 Eureka 官方文档也有提及。开源 Eureka 的这种广播复制模型,不仅会导致它自身的架构脆弱性,也影响了集群整体的横向扩展性。
Replication algorithm limits scalability: Eureka follows a broadcast replication model i.e. all the servers replicate data and heartbeats to all the peers. This is simple and effective for the data set that eureka contains however replication is implemented by relaying all the HTTP calls that a server receives as is to all the peers. This limits scalability as every node has to withstand the entire write load on eureka.
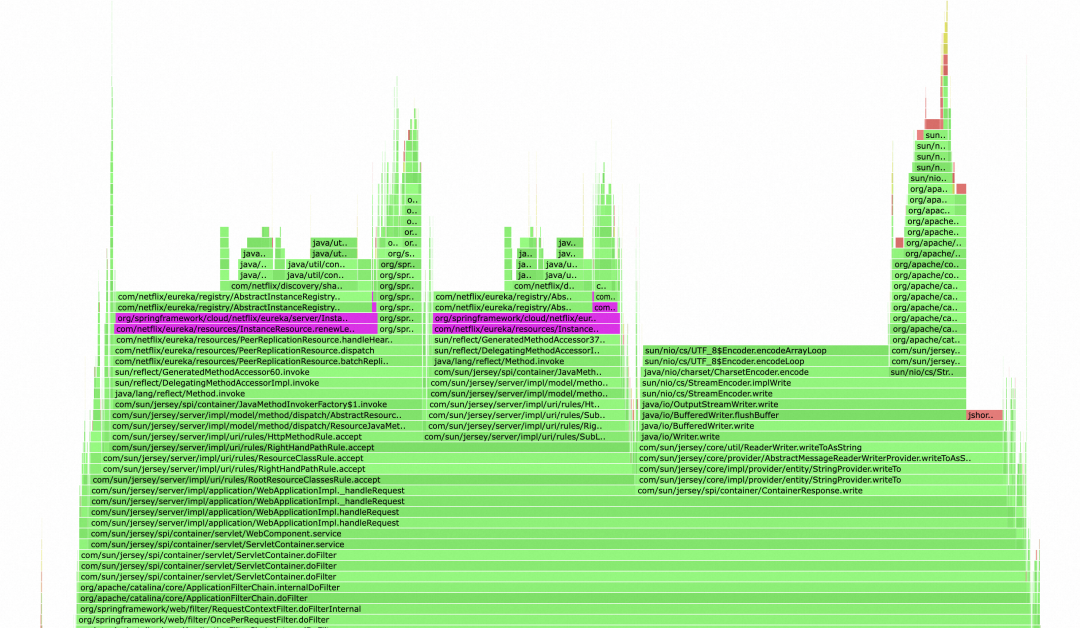
口说无凭,特意用性能分析利器 Arthas 从线上生产环境的 Eureka Server 集群采集了一份新鲜的 Profiler 火焰图,可以看到紫色部分就是在处理心跳续约逻辑,抛开 Jersey 写 IO 的部分不谈,这部分的 CPU 调用栈处理占比那是相当的高。
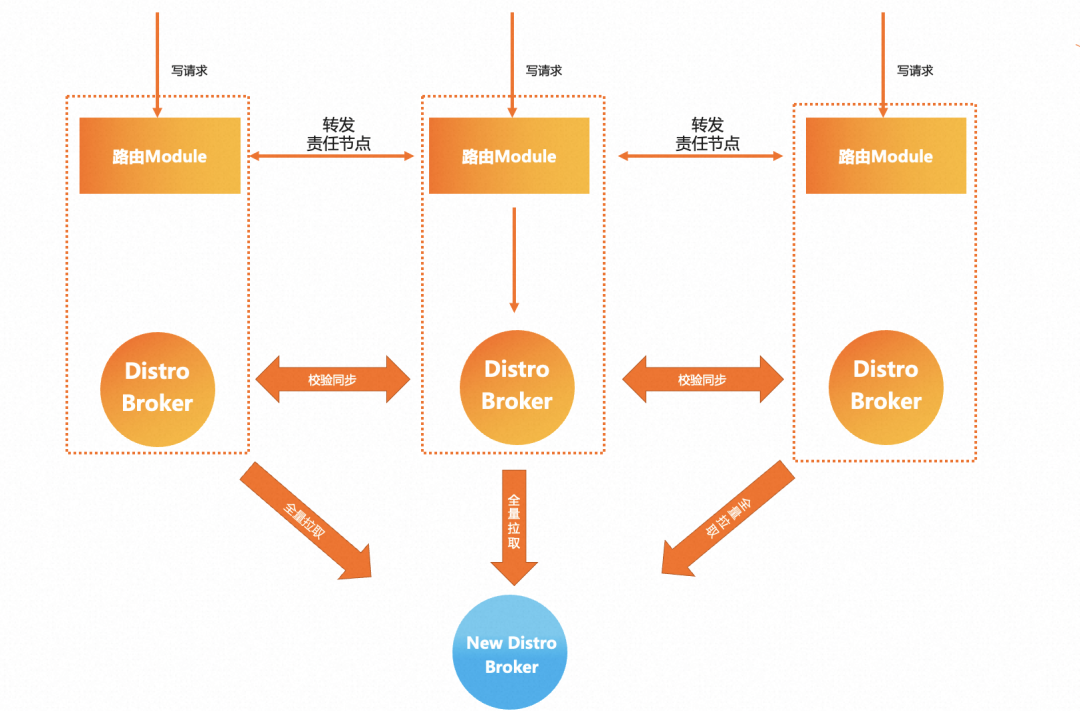
那么 MSE Nacos 是如何解决这个问题呢,这就要提到自研的 AP 模型 Distro 协议了,在保留了星型同步模型的基础上,Nacos 对所有服务注册实例数据进行了 Hash 散列、逻辑数据分片,为每一条服务实例数据分配一个集群责任节点,每一个 Server 节点仅负责自己 own 的那一部分数据的同步和续约逻辑,同时集群间数据同步的粒度相对于 Eureka 也更小。
这样带来的好处是即使在大规模部署、服务实例数据很多的情况下,集群间同步的任务量也能保证相对可控,并且集群规模越大,这样的模式带来的性能提升也愈发明显。
另外 MSE Nacos 在阿里云内部也在进行不断产品的打磨,对读写性能网络吞吐、实例索引存储容量进行了大幅优化,根据实验室压测数据,MSE Nacos 专业版支持的 Eureka 注册中心的写性能、容量均提升达一倍以上,同样的集群机器配置下,集群 CPU 开销、负载明显优于开源 Eureka。
**Round 2 - 简化运维
**
第二点就是运维成本的问题了,我们知道使用 Eureka 的很大一部分用户群体是运维同学,但是 Eureka 提供的运维能力、工具实在是太简陋了,完全无法满足日常工作中的运维需求。运维同学手上没有趁手的兵器,可不就只能辛苦加班加点来顶上了么。就像经常被吐槽的 Eureka 的控制台,上面只有一些很简单的服务注册列表、集群基础信息查看功能,想方便做一些高阶操作只能自己投入人力成本来定制开发。
但是相反在 MSE Nacos 的控制台上可以看到很多丰富易用的运维功能,比如实例权重配置管理,可以很方便的根据不同实例的性能分配权重,某个实例异常的时候也可以直接操作一键下线;除此之外还有服务健康状态检查、集群指标监控报警可对集群状态、服务数、TPS、请求耗时等指标进行监控,并且提供自定义告警规则及钉钉、电话、短信等告警渠道,便于排查异常。
还有一个运维同学关注比较多也是比较头疼的问题,是关于 Eureka 集群容量评估的,到底什么样的集群机器配置才能够保障业务的稳定运行,另外是否还可以从容的应对业务上一些突发的扩容场景需求。通常比较省事的解法就只能是提前预估好业务量,留够足够的资源池 buffer,那带来的问题就是明显的资源成本浪费,没办法实现降本增效的目的。
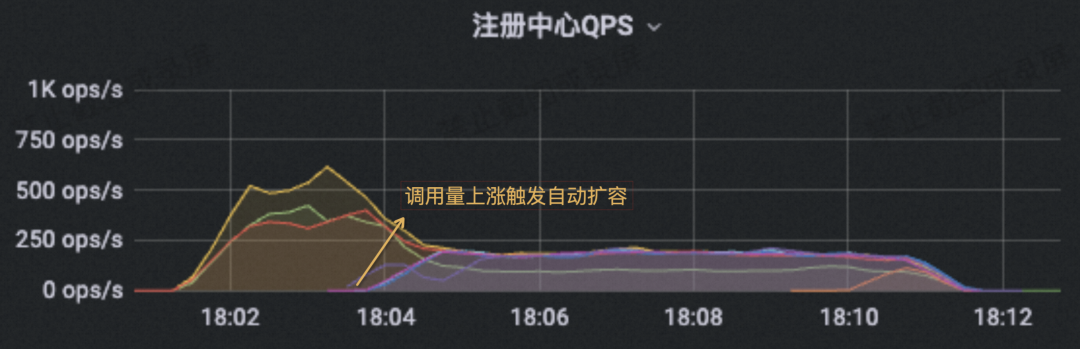
另外这些业务集群的扩缩容往往涉及人工运维操作,也极容易因为操作不规范而引发线上故障。为了解决这个问题,MSE Nacos 近期刚刚上线了 Serverless 版本并开始公测,Serverless 版本实现了对集群业务资源的精细化管理和超卖弹性调度。区别于传统实例的规格变配需要手动操作,Serverless 版本支持基于业务资源量自动扩缩容,从此不再需要提前做复杂的容量规划,对于中小规模业务及潮汐式场景又省事又省力。
Round 3 - 无缝迁移、安全接管
其实在考虑转型 MSE Nacos 作为微服务注册发现中心的时候,不光是我朋友,大家都很容易有一个担忧的问题,就是如果让整个公司所有业务研发团队都要为了适配 MSE Nacos 升级改造一遍的话,不单单是代码改造量的问题,还需要有配套的集成测试、性能压力测试需要一起跟进,这些加起来需要投入的成本实在是太高了。
然而实际上这个问题其实是最不用担心的,因为 MSE Nacos 实现了对开源 Eureka 原生协议的完全兼容,业务模型层面把 Eureka 中的 InstanceInfo 数据模型和Nacos 的数据模型(Service 和 Instance)进行了对应的一一映射,对于 Eureka Client 的改变仅仅是需要更换一下服务端实例 Endpoint 配置的修改即可完成切换。在日常业务使用中,既可以使用原生的 Eureka 协议把 MSE Nacos 实例当成一个 Eureka 集群来用,也可以支持 Nacos、Eureka 客户端双协议并存,不同协议的服务注册信息之间支持互相转换,从而保证业务微服务调用的连通性。
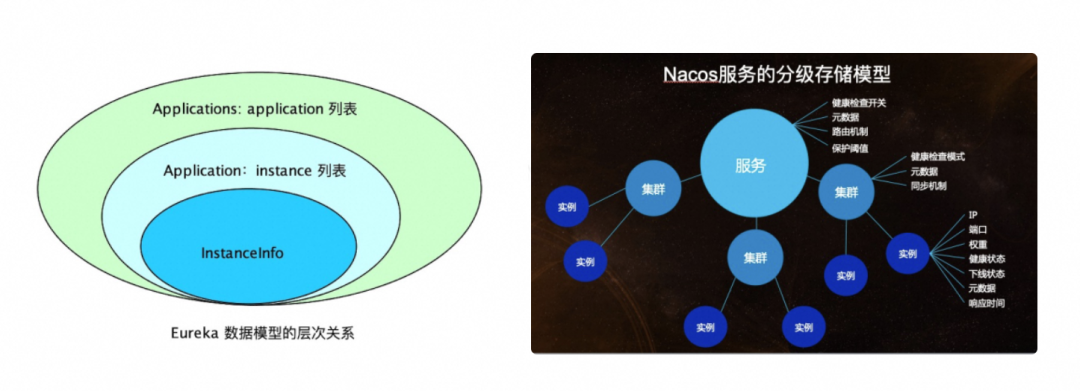
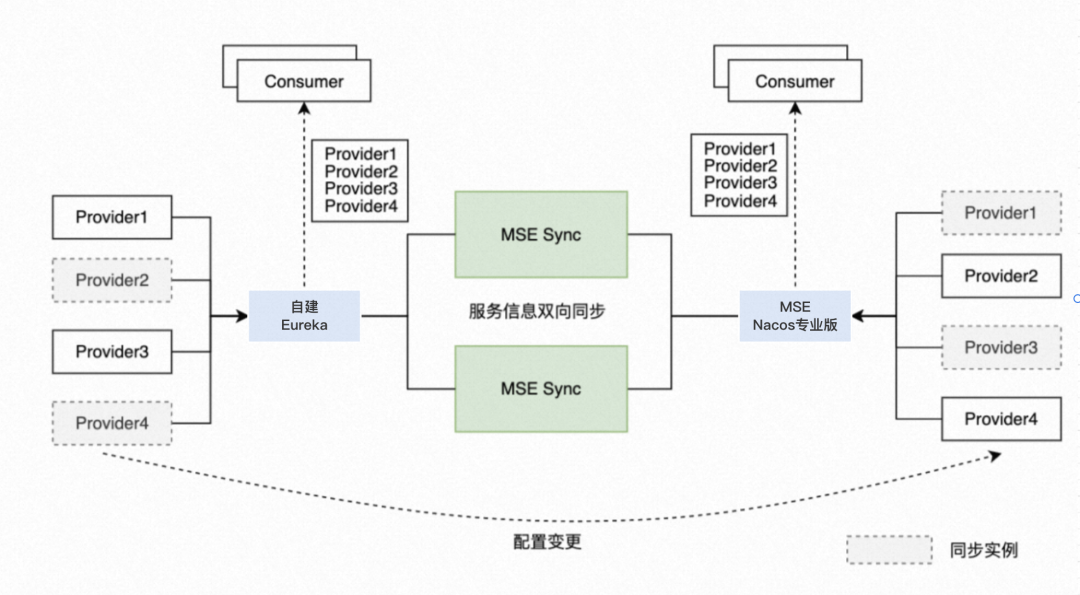
但这时肯定有人要问了,我在老的自建 Eureka 集群上那些已有的线上服务注册存量数据怎么办,如何平迁到 Nacos 上并且还能不影响到现在的业务调用。为了解决这个问题,MSE Nacos 推荐使用官方的 MSE-Sync 解决方案,MSE-Sync 是基于开源 Nacos-Sync 优化后的迁移配套数据同步工具,支持双向同步、自动拉取服务和一键同步的功能,可以轻松完成自建 Eureka 集群到 MSE Nacos 专业版的数据平滑迁移。
迁移方案可以参考这篇最佳实践帮助文档:https://help.aliyun.com/zh/mse/use-cases/migrate-the-user-created-euraka-registry-to-mse-nacos
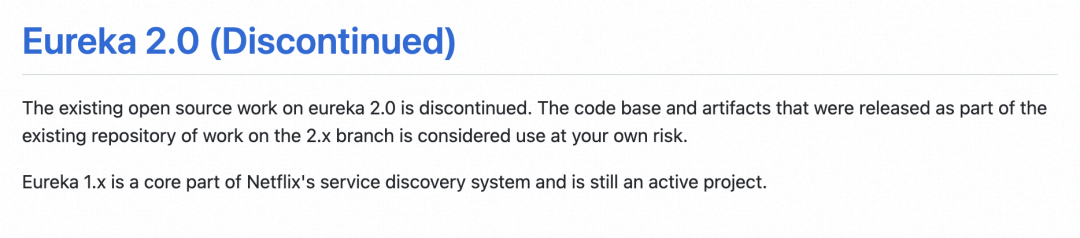
另外这里需要补充的是,Eureka 1.X 版本已经停止更新了,社区 2.0 版本的开源工作已经停止,而且 Eureka 2.0.0 Java 客户端 API 不向后兼容 1.x,看到官方下面的通知就问你慌不慌。从长远考虑继续使用自建 Eureka 作为服务注册中心,显然不是一个很好的选择。
数据对比
Aliware
为了对比两者产品能力上的差异,接下来我们来一起做一个很有意思的压力测试,这次开源 Eureka(采用闭源前次新 1.X 版本 v1.10.17)和 MSE Nacos 我们都使用了同样的 8C16G 规格容器来搭建 3 节点高可用集群。另外施压脚本我们统一采用 Golang 实现的模拟多 client 来并发注册,施压机器均是云上普通的 ECS 机器,所有的模拟的 Eureka client 实例行为跟实际生产环境行为均保持一致,包含注册、心跳续约、定时全量/增量拉取 Registry 数据等功能,其中 client 心跳上报时间间隔 3s,过期时间 10s,定时全量/增量注册数据拉取的间隔为 30s。
施压程序会分若干批,均匀不断的往集群里注册新的服务数据并通过心跳保持住,直到集群出现性能瓶颈或者是达成预期压测目标(服务数 100,每个服务实例数 500),压测过程中通过实时监控大盘来观测集群各项系统指标数据来做一个对比。
**开源 Eureka 的表现
**
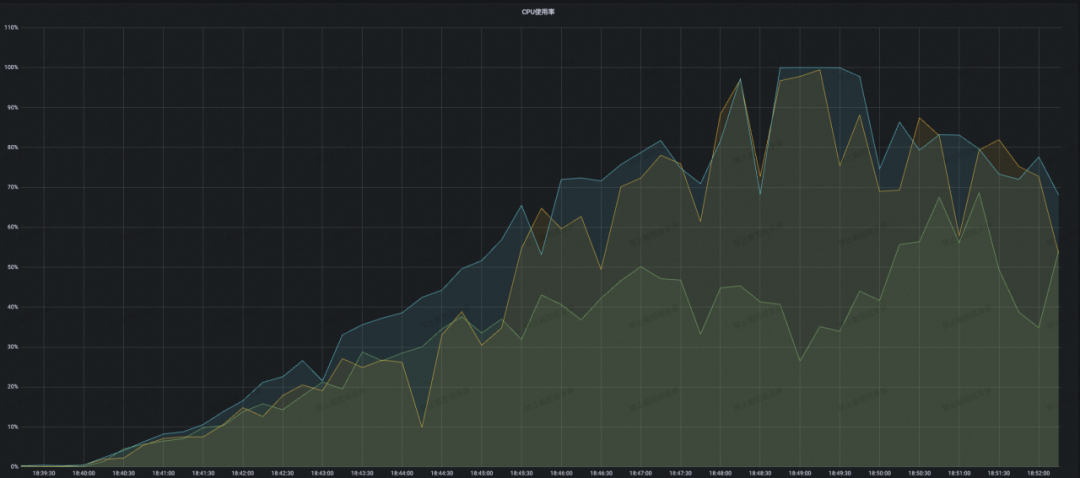
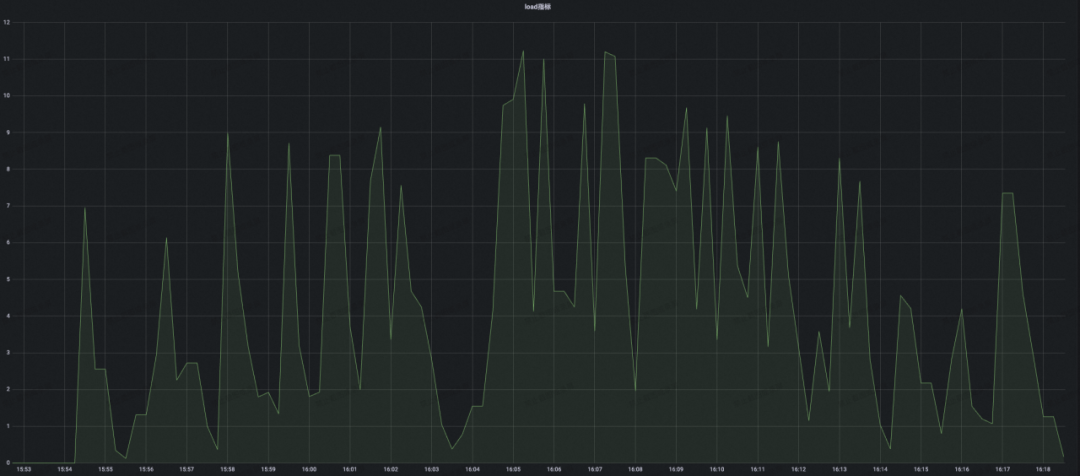
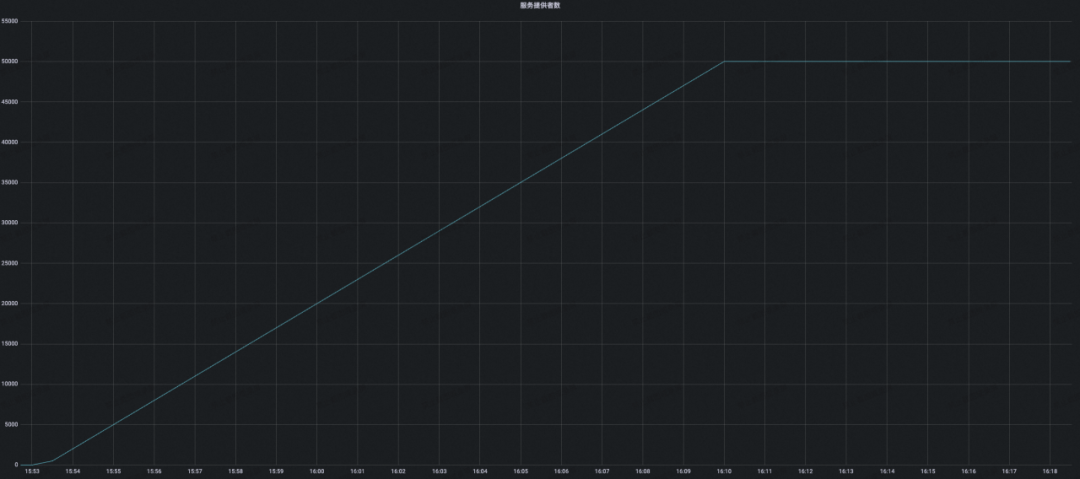
结论:开源 Eureka 集群在服务注册增长到接近 2W 附近的时候,可以看到 CPU 负载已经有飙高迹象,后面持续攀升的压力最终导致集群 CPU 被完全打满,并且集群开始频繁出现服务实例续约失败的错误,最终集群容量也只能稳定在 1.6W 左右,不满足压测预期。

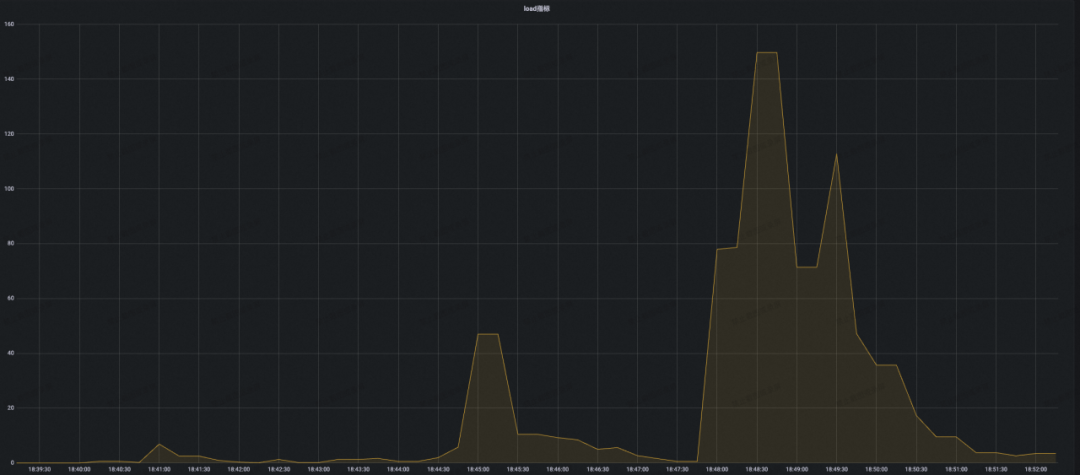
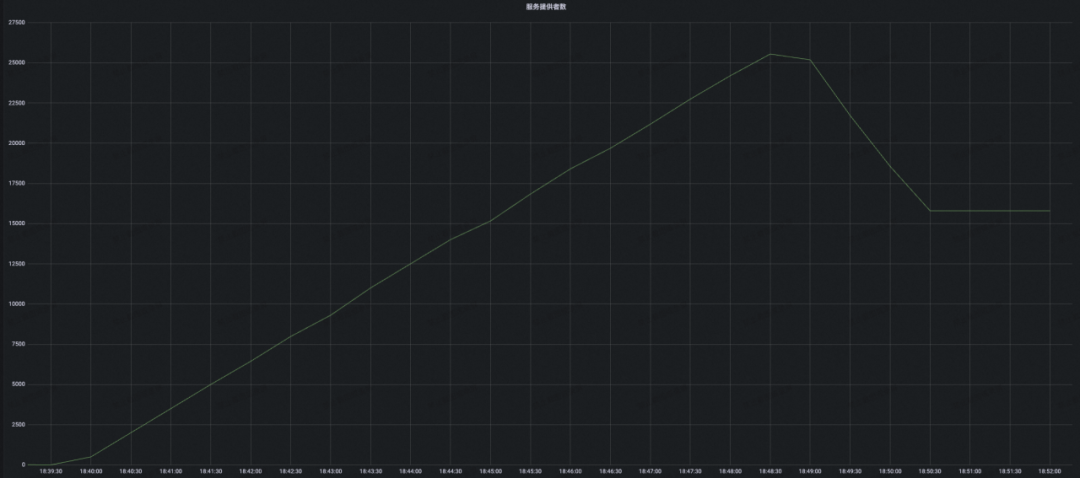
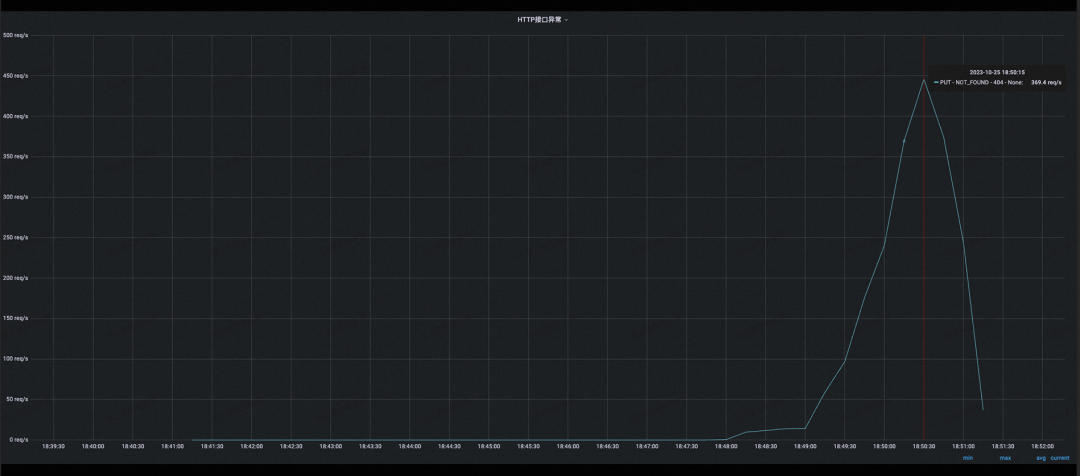
**MSE Nacos 专业版的表现
**
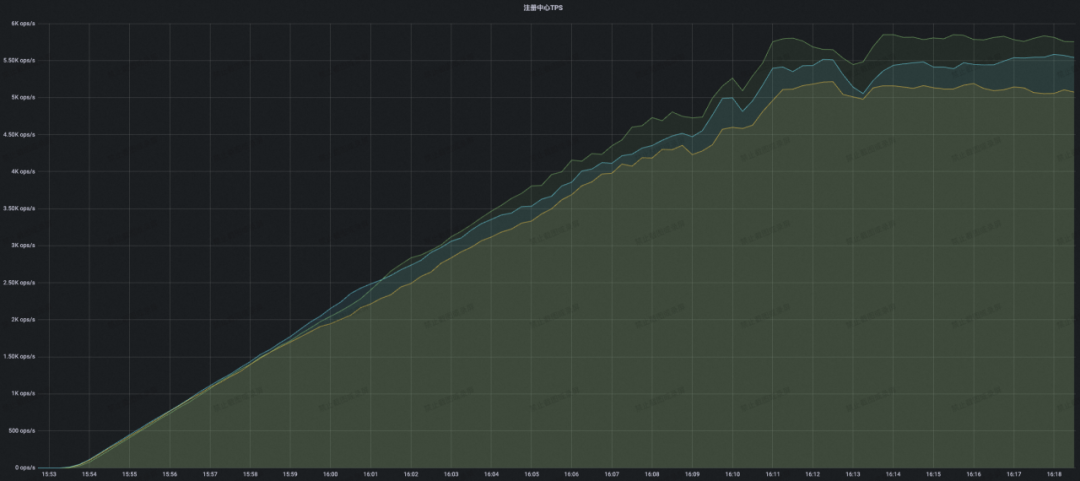
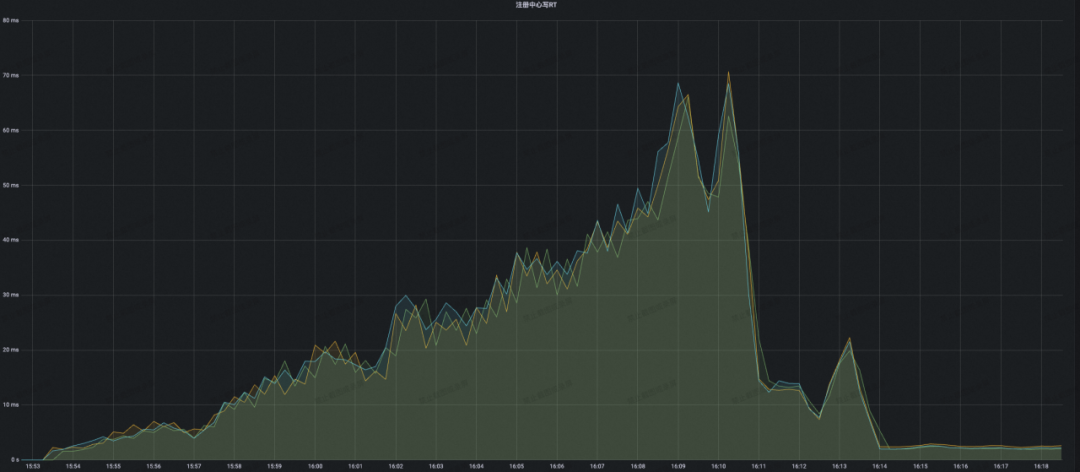
结论:可以看到 MSE Nacos 专业版随着注册规模的不断攀升,CPU 利用率只是稳步上升,并没有出现 CPU 负载突然飙高的情况。当到达开源 Eureka 2W 附近性能瓶颈的时候,此时 MSE Nacos 集群的 CPU 只有 40% 不到,这就意味着同样的集群容量要求,使用 MSE Nacos 专业版需要的机器规格可以更低,性价比更高。当最终稳定在本次压测目标 5W 的时候,此时集群进入稳态不再变更,整体 CPU 利用率稳定在了 50%,内存占用、读写 RT 均表现优异。
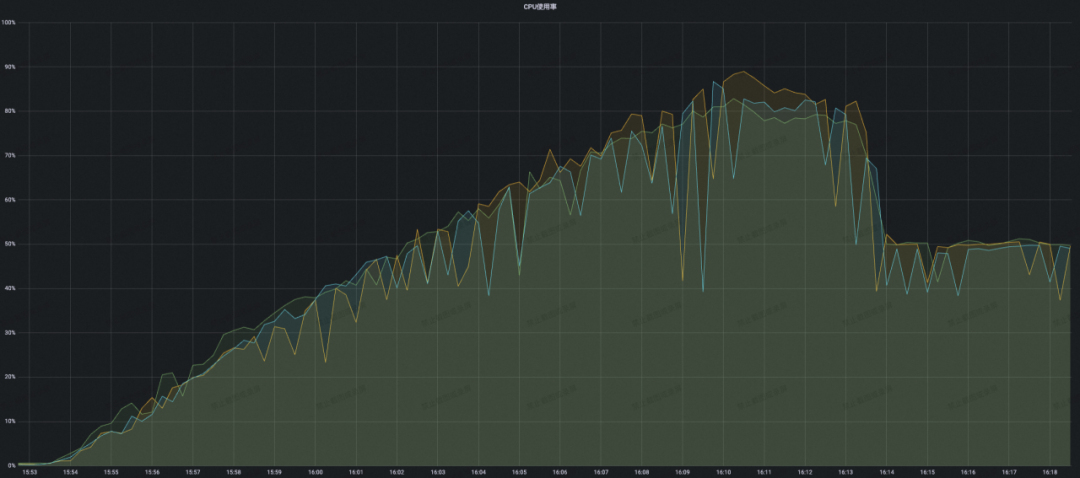
更多的差异化技术竞争力
Aliware
通过上述案例、压测数据的展示,再回到本文标题讨论的内容,自建 Eureka 显然不是一个最优的选择,深度结合云原生技术的 MSE Nacos 在成本、性能、弹性等多项指标上都已经完全超越了开源 Eureka,另外像 MSE Nacos 通过支持 MCP 协议和 XDS 协议,服务网格生态领域已完全兼容专业版的 Eureka 协议,这样搭配上 MSE 云原生网关、微服务治理的能力,就可以搭建一套面向业界主流微服务生态的一站式微服务平台,拥有一系列的高性能、高可用的企业级云服务能力,节省自建网关、注册配置中心、微服务治理体系的人力成本。
写在最后
MSE Nacos Serverless 版本已于 2023 年 11 月 17 日正式商用!
点击阅读原文即可领取 1 个月的开发版免费额度。
版权归原作者 阿里巴巴中间件 所有, 如有侵权,请联系我们删除。