
vue3.0生成压缩包(含在线地址、前端截图、前端文档)
需求描述
- 内容区为富文本html渲染的内容
- 要求点击下载后 需要有以下文件
- 1.当前内容的页面,即渲染内容截图,且需要将截图转化成pdf
- 2.提取html内容区的视频,单独下载
- 3.后端返回的附件地址,下载附件文档
- 4.再将以上文件总结成压缩包

效果



开始
下载插件包
- html2canvas 截图
npm install html2canvas --save
//或
yarn add html2canvas
- jspd 生成pdf插件
npm install jspdf --save
//或
yarn add jspdf
- jszip压缩文件
npm install jszip --save
//或
yarn add jszip
- 保存文件的JavaScript库
npm install file-saver --save
//或
yarn add file-saver
- 一起安装
npm i file-saver jszip html2canvas jspdf --save
基本代码构造
<div v-html="contentValue"></div>//用于展示<div ref="content" v-html="contentValue" id="content"></div>//用于截图并转化成pdf 我们调整使他不在可视范围内(不需要视频 同时把视频隐藏)-----// jsimport html2canvas from"html2canvas";import{ jsPDF }from"jspdf";import JSZip from"jszip";import FileSaver from"file-saver";-----const content = ref<any>(null);//ref实例const contentValue= ref<string>("");//contentValue富文本html数据const downloadFileUrl = ref<string[]>([]);//压缩包下载数组const pdfValue=ref<string>("")// 获取详情constgetDetail=async(id: string)=>{const res =await你的详情api({
id,});if(res){
contentValue.value = res;// 添加视频链接
downloadFileUrl.value =getVideo(res.content);if(res?.annexList?.length){// 添加附件链接
downloadFileUrl.value.push(res.annexList[0].url);}}};-----//less
#content {position: absolute;left: 100000px;top:0;/deep/video {display: none;}}
点击下载按钮
1.截图content元素,并转化为pdf
constexportToPDF=()=>{const dom = content.value;html2canvas(dom,{useCORS:true,//解决网络图片跨域问题width: dom.width,height: dom.height,windowWidth: dom.scrollWidth,dpi: window.devicePixelRatio *4,// 将分辨率提高到特定的DPI 提高四倍scale:4,// 按比例增加分辨率backgroundColor:"#fff",// 背景}).then((canvas)=>{const pdf =newjsPDF("p","mm","a4");// A4纸,纵向const ctx = canvas.getContext("2d");const a4w =170;const a4h =250;// A4大小,210mm x 297mm,四边各保留20mm的边距,显示区域170x257const imgHeight = Math.floor((a4h * canvas.width)/ a4w);// 按A4显示比例换算一页图像的像素高度let renderedHeight =0;while(renderedHeight < canvas.height){const page = document.createElement("canvas");
page.width = canvas.width;
page.height = Math.min(imgHeight, canvas.height - renderedHeight);// 可能内容不足一页// 用getImageData剪裁指定区域,并画到前面创建的canvas对象中
page
.getContext("2d").putImageData(
ctx.getImageData(0,
renderedHeight,
canvas.width,
Math.min(imgHeight, canvas.height - renderedHeight)),0,0);
pdf.addImage(
page.toDataURL("image/jpeg",1.0),"JPEG",20,20,
a4w,
Math.min(a4h,(a4w * page.height)/ page.width));// 添加图像到页面,保留10mm边距
renderedHeight += imgHeight;if(renderedHeight < canvas.height){
pdf.addPage();// 如果后面还有内容,添加一个空页}}
pdfValue.value = pdf.output("datauristring");// 获取base64Pdf});
canvas putImageData、getImageData
getImageData 获取指定矩形区域的像素信息
ctx.getImageData(x,y,width,height)
属性描述x开始复制的左上角位置的 x 坐标(以像素计)。y开始复制的左上角位置的 y 坐标(以像素计)。width要复制的矩形区域的宽度。height要复制的矩形区域的高度。
putImageData 将这些数据放回画布,从而实现对画布像素的编辑
ctx.putImageData(imgData,x,y,dirtyX,dirtyY,dirtyWidth,dirtyHeight)
属性描述imgData规定要放回画布的 ImageData 对象 ;xImageData 对象左上角的 x 坐标,以像素计;yImageData 对象左上角的 y 坐标,以像素计;dirtyX可选。水平值(x),以像素计,在画布上放置图像的位置;dirtyY可选。水平值(y),以像素计,在画布上放置图像的位置;dirtyWidth可选。在画布上绘制图像所使用的宽度;dirtyHeight可选。在画布上绘制图像所使用的高度
- ImageData 结构:每个ImageData对象包含三个属性: width:图像数据的宽度(以像素为单位)。 height:图像数据的高度(以像素为单位)。 data:一个一维数组,包含图像数据的RGBA值。每个像素由四个连续的数组元素表示,分别对应红、绿、蓝和透明度(alpha)通道。每个通道的值都是一个0到255之间的整数。
2.提取富文本视频
//单独提取富文本视频链接constgetVideo=(str: string)=>{const regex =/<video.*?src=["']([^"']+)["']/g;const videoTags = str.match(regex);// console.log(videoTags) arr[0]代表第一个匹配项,arr[1]代表第二个匹配项...,数组length代表有几个匹配项// ["<video poster="" controls="true" width="auto" height="auto"><source src="你的地址""]const videoUrls =[];if(videoTags){for(let i =0; i < videoTags.length; i++){const match = regex.exec(videoTags[i]);// console.log(match) [0]代表匹配项,[≥1]代表捕获的group。index是匹配的第一个字符索引,input代表str字符串// 0: "<video poster=\"\" controls=\"true\" width=\"auto\" height=\"auto\"><source src=\"你的地址\""// 1: "你的地址"// index: 0//input: "<video poster=\"\" controls=\"true\" width=\"auto\" height=\"auto\"><source src=\"你的地址\""if(match){
videoUrls.push(match[1]);// match[1] 匹配到的视频地址}}}return videoUrls;};//ps 单独提取文字正则 str.replace(/<[^>]+>/g, "")
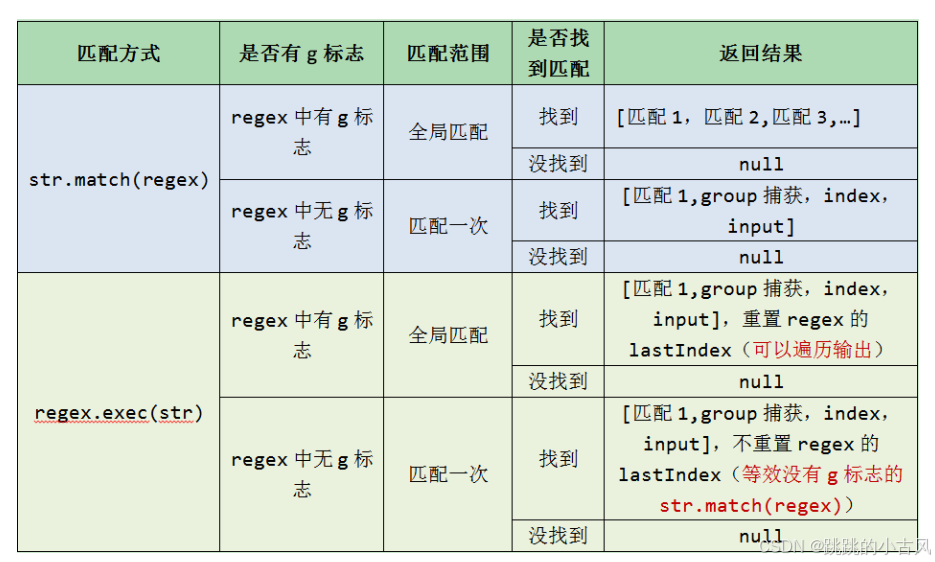
正则 str.match(regex) regex.exec(str)知识补充
3.base64和在线地址转blob
constdataURLtoFile=(dataurl: string,type: string)=>{returnnewPromise((resolve, reject)=>{if(type ==="http"){//通过请求获取文件blob格式let xmlhttp =newXMLHttpRequest();
xmlhttp.open("GET", url,true);
xmlhttp.responseType ="blob";
xmlhttp.onload=function(){if(xmlhttp.status ==200){resolve(xmlhttp.response);}else{reject(xmlhttp.response);}};
xmlhttp.send();}else{let arr = dataurl.split(",");let bstr =atob(arr[1]);let n = bstr.length;let u8arr =newUint8Array(n);while(n--){
u8arr[n]= bstr.charCodeAt(n);}resolve(u8arr);}});};
4.下载成压缩包代码
// 下载全部附件constdownloadFile=async()=>{var blogTitle =`附件批量下载`;// 下载后压缩包的名称var zip =newJSZip();var promises =[];for(let item of downloadFileUrl.value){if(item){// 在线地址转blob 添加至进程const promise =dataURLtoFile(item,"http").then((data)=>{// 下载文件, 并存成ArrayBuffer对象(blob)let fileName =getFileName(item);//文件名 这里可以自己命名 不用调这个方法 博主需求是截取地址后面的
zip.file(fileName, data,{binary:true});});
promises.push(promise);}else{// answer地址不存在时提示alert(`附件地址错误,下载失败`);}}// 单独加富文本pdf blobif(pdfUrl.value){const contentPromise =dataURLtoFile(pdfUrl.value,"base64").then((data)=>{
zip.file("content.pdf", data,{binary:true});});
promises.push(contentPromise);}
Promise.all(promises).then(()=>{
zip
.generateAsync({type:"blob",}).then((content)=>{// 生成二进制流
FileSaver.saveAs(content, blogTitle);// 利用file-saver保存文件 blogTitle:自定义文件名});}).catch((res)=>{alert("文件压缩失败");});};// 获取文件名constgetFileName=(filePath: string)=>{var startIndex = filePath.lastIndexOf("/");if(startIndex !=-1)return filePath.substring(startIndex +1, filePath.length).toLowerCase();elsereturn"";};
全部代码
<template><div><div><div><p
@click="downloadAllFile()"><a-icon type="icon-xiazai"></w-icon> 下载
</p></div></div><div
class="text-content"
v-html="detaileInfo.content"></div><div
class="text-content"
ref="content"
id="content"><div v-html="detaileInfo.content"></div></div></div></template><script lang="ts">import{ defineComponent, onMounted, ref }from"vue";import html2canvas from"html2canvas";import{ jsPDF }from"jspdf";import JSZip from"jszip";import FileSaver from"file-saver";exportdefaultdefineComponent({name:"announcementDetail",setup(){const detaileInfo = ref<any>({});const content = ref<any>(null);const downloadFileUrl = ref<string[]>([]);const pdfUrl = ref<string>("");// 获取详情constgetDetail=async()=>{const res =await你的api({id:"你的id",});if(res){
detaileInfo.value = res;// 添加视频链接
downloadFileUrl.value =getVideo(res.content);if(res?.annexList?.length){// 添加附件链接
downloadFileUrl.value.push(res.annexList[0].url);}}};//单独提取富文本视频链接constgetVideo=(str: string)=>{const regex =/<video.*?src=["']([^"']+)["']/g;const videoTags = str.match(regex);const videoUrls =[];if(videoTags){for(let i =0; i < videoTags.length; i++){const match = regex.exec(videoTags[i]);if(match){
videoUrls.push(match[1]);// match[1] 匹配到的视频地址}}}return videoUrls;};constdownloadAllFile=()=>{exportToPDF();};constexportToPDF=()=>{const dom = content.value;html2canvas(dom,{useCORS:true,//解决网络图片跨域问题width: dom.width,height: dom.height,windowWidth: dom.scrollWidth,dpi: window.devicePixelRatio *4,// 将分辨率提高到特定的DPI 提高四倍scale:4,// 按比例增加分辨率backgroundColor:"#fff",// 背景}).then((canvas)=>{// eslint-disable-next-line new-capconst pdf =newjsPDF("p","mm","a4");// A4纸,纵向const ctx = canvas.getContext("2d");const a4w =170;const a4h =250;// A4大小,210mm x 297mm,四边各保留20mm的边距,显示区域170x257const imgHeight = Math.floor((a4h * canvas.width)/ a4w);// 按A4显示比例换算一页图像的像素高度let renderedHeight =0;while(renderedHeight < canvas.height){const page = document.createElement("canvas");
page.width = canvas.width;
page.height = Math.min(imgHeight, canvas.height - renderedHeight);// 可能内容不足一页// 用getImageData剪裁指定区域,并画到前面创建的canvas对象中
page
.getContext("2d").putImageData(
ctx.getImageData(0,
renderedHeight,
canvas.width,
Math.min(imgHeight, canvas.height - renderedHeight)),0,0);
pdf.addImage(
page.toDataURL("image/jpeg",1.0),"JPEG",20,20,
a4w,
Math.min(a4h,(a4w * page.height)/ page.width));// 添加图像到页面,保留10mm边距
renderedHeight += imgHeight;if(renderedHeight < canvas.height){
pdf.addPage();// 如果后面还有内容,添加一个空页}}
pdfUrl.value = pdf.output("datauristring");// 获取base64PdfdownloadFile();});};//返回blob值 在线地址和前端生成的base64编码constdataURLtoFile=(dataurl: string,type: string)=>{returnnewPromise((resolve, reject)=>{if(type ==="http"){//通过请求获取文件blob格式let xmlhttp =newXMLHttpRequest();
xmlhttp.open("GET", url,true);
xmlhttp.responseType ="blob";
xmlhttp.onload=function(){if(xmlhttp.status ==200){resolve(xmlhttp.response);}else{reject(xmlhttp.response);}};
xmlhttp.send();}else{let arr = dataurl.split(",");let bstr =atob(arr[1]);let n = bstr.length;let u8arr =newUint8Array(n);while(n--){
u8arr[n]= bstr.charCodeAt(n);}resolve(u8arr);}});};// 下载全部附件constdownloadFile=async()=>{var blogTitle =`附件批量下载`;// 下载后压缩包的名称var zip =newJSZip();var promises =[];for(let item of downloadFileUrl.value){if(item){// 在线地址转blob 添加至进程const promise =dataURLtoFile(item,"http").then((data)=>{// 下载文件, 并存成ArrayBuffer对象(blob)let fileName =getFileName(item);//文件名
zip.file(fileName, data,{binary:true});});
promises.push(promise);}else{alert(`附件地址错误,下载失败`);}}// 单独加富文本blobif(pdfUrl.value){const contentPromise =dataURLtoFile(pdfUrl.value,"base64").then((data)=>{
zip.file("content.pdf", data,{binary:true});});
promises.push(contentPromise);}
Promise.all(promises).then(()=>{
zip
.generateAsync({type:"blob",}).then((content)=>{// 生成二进制流
FileSaver.saveAs(content, blogTitle);// 利用file-saver保存文件 blogTitle:自定义文件名});}).catch((res)=>{alert("文件压缩失败");});};// 获取文件名constgetFileName=(filePath: string)=>{var startIndex = filePath.lastIndexOf("/");if(startIndex !=-1)return filePath.substring(startIndex +1, filePath.length).toLowerCase();elsereturn"";};onMounted(()=>{getDetail();});return{
content,
detaileInfo,
downloadAllFile,};},});</script><style lang="less" scoped>.text-content {
font-family:"PingFang SC";
font-weight:400;
font-size: 15px;
letter-spacing:0.06px;
line-height: 30px;
text-align: left;color: #666;width:100%;/deep/video,/deep/img {width:100%;}}
#content {position: absolute;left: 100000px;top:0;.label {display: inline-block;}/deep/video {display: none;}}</style>
本文转载自: https://blog.csdn.net/weixin_43787651/article/details/144129653
版权归原作者 跳跳的小古风 所有, 如有侵权,请联系我们删除。
版权归原作者 跳跳的小古风 所有, 如有侵权,请联系我们删除。