
一、zookeeper 发布策略
Apache ZooKeeper 社区一次支持两个发布分支:stable和current。ZooKeeper的稳定版本是 3.7.x,当前版本是 3.8.x。一旦发布新的次要版本,稳定版本预计将很快退役,大约半年后将宣布为 End-of-Life。在半年的宽限期内,预计只会为该版本发布安全和关键修复程序。宣布 EoL 后,社区不再提供进一步的补丁。所有 ZooKeeper 版本都可以从官方 Apache 档案中访问。
Apache ZooKeeper 3.8.0(当前版本)
Apache ZooKeeper 3.7.1(最新稳定版)
Apache ZooKeeper 3.6.3 (稳定版)
Apache ZooKeeper 3.5.10(3.5 自 2022 年 6 月 1 日起停产)
详细见zookeeper官网:zookeeper 版本介绍
1、版本选择
- zookeeper版本上面已经介绍了当前最新版本3.8.0,版本选择我们最好不要选择最新版本(除非是修复了以前版本特别严重的bug),也不要选择特别老版本;选择中间版本就好,如上例子我们就可以选择 ZooKeeper 3.6.3 (稳定版)
- 为什么不选择3.7.1,主要原因有以下2点 1、业务背景是因为Flink-1.15 放弃对 Zookeeper 3.4.x 的支持,前面测试的zookeeper都是基于zookeeper 3.6.x做测试,这个时候如果我们用的是3.7.x ,那么对于开发而言又要增加测试成本的工作量 2、这边在了解版本的时候,看到网上基本都是用的 ZooKeeper 3.6.x
- Apache ZooKeeper 3.6.3 (稳定版)发行说明
- Apache ZooKeeper 3.6.3 (稳定版)下载包地址
- zookeeper 各个版本分支详见:zookeeper branch doc
2、Flink_ha 特性
Flink1.15 仅支持ZooKeeper3.5/3.6,不再支持3.4。
- FLINK-25146 Drop support for Zookeeper 3.4
- FLINK-1.15 Official website
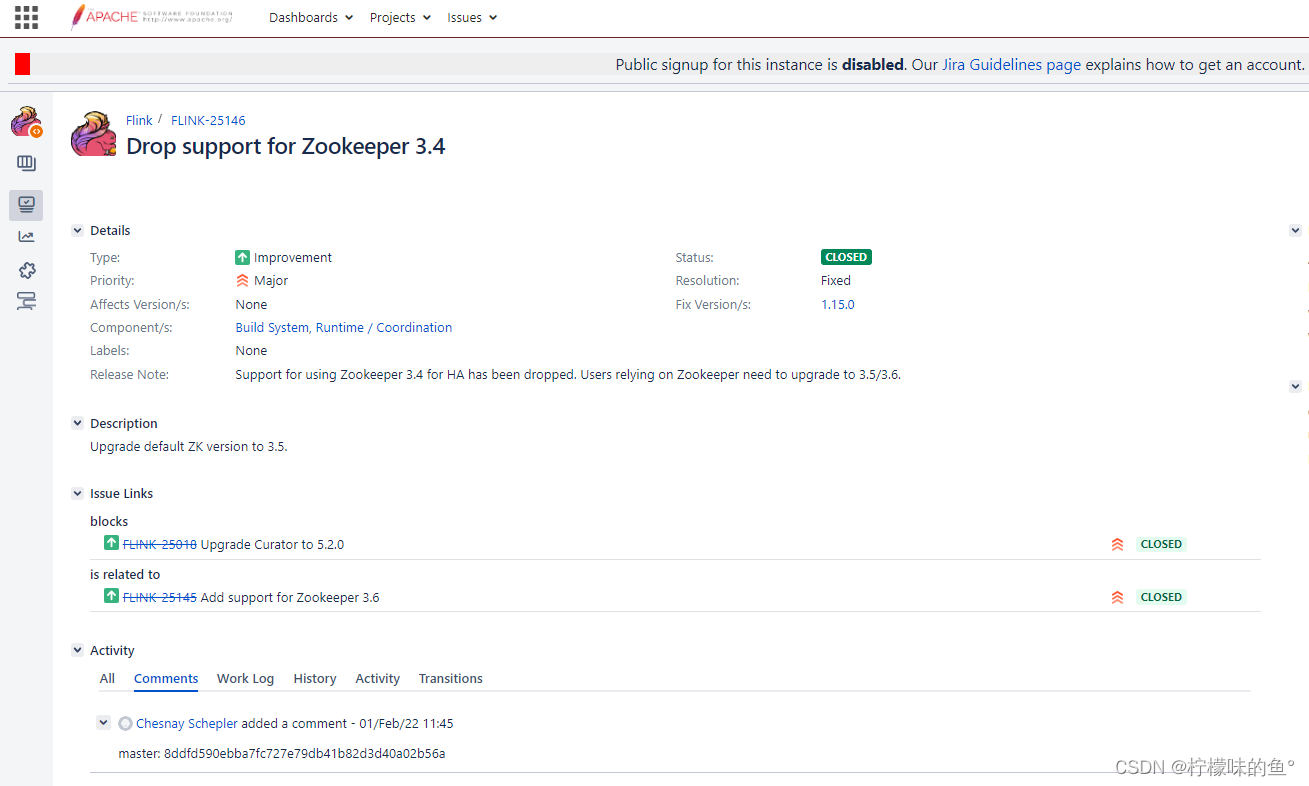
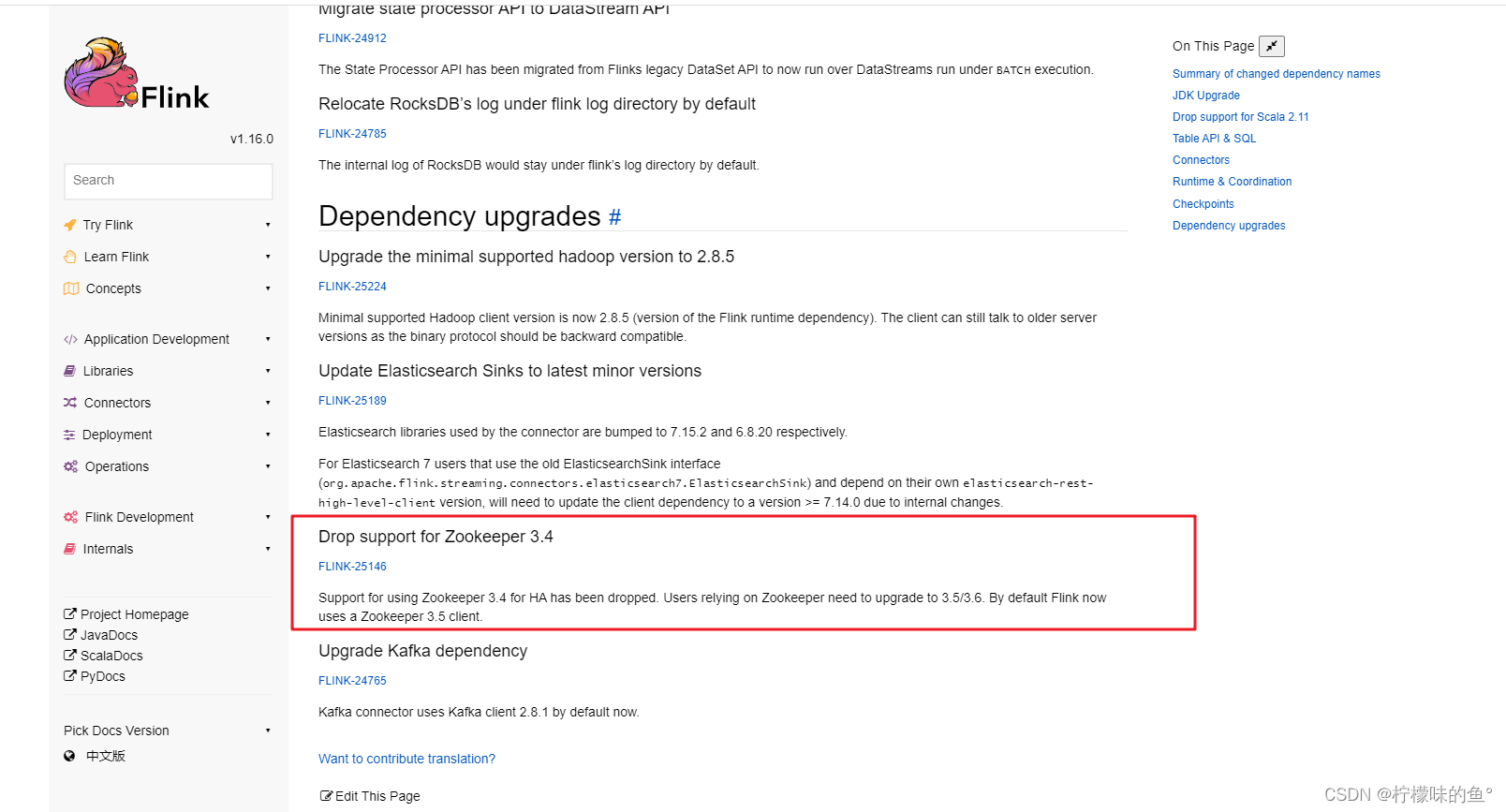
其中的ZooKeeper Versions描述默认使用3.4,可以自行调整为3.5。从文档上来看自1.11版本就添加了这段描述,到目前最新稳定版本(1.16.0)依然是这么描述的。其实在1.15的 ReleaseNote 中明确写了,不再支持3.4,网上已经有人验证过任务直接报错
二、zookeeper 参数优化
- 不要使用zk的默认配置,默认配置就是一个定时炸弹
- 在网上也找了一些相关优化参数,无非就主要的那么几个,下面列出需要调整的相关参数
1. 配置snapshot文件清理策略
autopurge.purgeInterval=1
autopurge.purgeInterval:开启清理事务日志和快照文件的功能,单位是小时。默认是0,表示不开启自动清理功能。
autopurge.snapRetainCount=10
autopurge.snapRetainCount:指定了需要保留的文件数目。默认是保留3个。
2. 限制snapshot数量
snapCount=3000000
每snapCount次事务日志输出后,触发一次快照(snapshot)。 ZooKeeper会生成一个snapshot文件和事务日志文件。 默认是100000。
3. log和data数据分磁盘存储
dataDir:存储快照文件snapshot的目录。默认情况下,事务日志也会存储在这里。
dataLogDir:事务日志输出目录。尽量给事务日志的输出配置单独的磁盘或是挂载点,这将极大的提升ZK性能。
4. 调整JVM大小
ZooKeeper的JVM内存默认是根据操作系统本身内存大小的一个百分比预先分配的,所以这不是我们所需要的。
在./bin/zkEnv.sh文件中,有如下配置项:
if[-f"$ZOOCFGDIR/java.env"]then."$ZOOCFGDIR/java.env"fi
我们在./conf/java.env文件中配置JVM的内存,增加如下配置:
exportJAVA_HOME=/usr/local/java/jdk1.8.0_151
exportJVMFLAGS="-Xms10240m -Xmx20480m $JVMFLAGS"
修改完成使用jmap -heap$pid来验证内存修改情况。
5. ZNode中可以存储数据星的最大值,默认值是1M。
jute.maxbuffer
修改jvm内存参数jute.maxbuffer大小调整到10M=10240KB=10485760Bytes
修改bin/zkServer.sh或者zkEnv.sh
JVMFLAGS="$JVMFLAGS -Djute.maxbuffer=10485760"
tickTime=2000
ZK中的一个时间单元。ZK中所有时间都是以这个时间单元为基础,进行整数倍配置的。例如,session的最小超时时间是2*tickTime。 默认值2000,单位毫秒。
initLimit=10
Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader允许F在 initLimit 时间内完成这个工作。通常情况下,我们不用太在意这个参数的设置。如果ZK集群的数据量确实很大了,Flower在启动的时候,从Leader上同步数据的时间也会相应变长,因此在这种情况下,有必要适当调大这个参数了。
initLimit=30000syncLimit=5
在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。如果Leader发出心跳包在syncLimit之后,还没有从Flower那里收到响应,那么就认为这个Flower已经不在线了。注意:不要把这个参数设置得过大,否则可能会掩盖一些问题。
maxClientCnxns=500
单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制。请注意这个限制的使用范围,仅仅是单台客户端机器与单台ZK服务器之间的连接数限制,不是针对指定客户端IP,也不是ZK集群的连接数限制,也不是单台ZK对所有客户端的连接数限制。
maxSessionTimeout=60000000
Session超时时间限制,如果客户端设置的超时时间不在这个范围,那么会被强制设置为最大或最小时间。默认的Session超时时间是在2 * tickTime ~ 20 * tickTime 这个范围
preAllocSize=131072
预先开辟磁盘空间,用于后续写入事务日志。默认是64M,每个事务日志大小就是64M。如果ZK的快照频率较大的话,建议适当减小这个参数。单位kb。
ZooKeeper的磁盘建议使用SSD,因为zookeeper必须具有低延迟磁盘写入才能以最佳方式执行。对zookeeper的每个请求都必须提交到仲裁中每个服务器上的磁盘上,然后才能读取结果。对于生产部署,建议在每个zookeeper服务器上使用大小至少为64 gb的专用ssd。
三、最终参数配置
# cat conf/zoo.cfg autopurge.purgeInterval=24autopurge.snapRetainCount=5clientPort=2181dataDir=/data/zookeeper
dataLogDir=/log/zookeeper
initLimit=10maxClientCnxns=500maxSessionTimeout=60000minSessionTimeout=4000syncLimit=5tickTime=20004lw.commands.whitelist=*
metricsProvider.exportJvmInfo=true
skipACL=yes
forceSync=no
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpPort=7000server.1=0.0.0.1:2888:3888
server.2=0.0.0.2:2888:3888
server.3=0.0.0.3:2888:3888
1、其他参数介绍
- 主要配置上面已经介绍了,有几个参数没有介绍的,参数介绍如下
# 3.4.10 中的新功能,此属性包含逗号分隔的四字母单词命令列表。引入它是为了对 ZooKeeper 可以执行的命令集提供细粒度的控制4lw.commands.whitelist=*
# 如果将此属性设置为true,则Prometheus.io将导出有关JVM的指标,默认值为truemetricsProvider.exportJvmInfo=true
# metric Prometheus 监控配置,如果用的其它监控方案这里可以注释掉metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
# metric Prometheus 监控端口,同上,如果用的其它监控方案这里可以注释掉metricsProvider.httpPort=7000
相关参考借鉴:
Flink_zookeeper版本
zookeeper配置优化
本文转载自: https://blog.csdn.net/weixin_45971974/article/details/128343493
版权归原作者 柠檬味的鱼° 所有, 如有侵权,请联系我们删除。
版权归原作者 柠檬味的鱼° 所有, 如有侵权,请联系我们删除。