
🙆♂️博主:发量不足
欢迎来到本博主主页逛逛
**链接:**发量不足的博客_CSDN博客-hadoop,环境配置,IDEA领域博主https://blog.csdn.net/m0_57781407?type=blog
** Spark SQL可以通过DataFrame和DataSet操作多种数据源,例如(MySql,Hive和Hase等)**
一、操作MySql
①Spark读取MySql
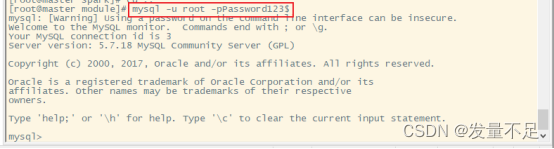
Step1 登录SQL
mysql -u root -pPassword23$ -pPassword23$
Step2 创建数据库,并选择数据库
create database spark;
use spark;

Step3 创建表
Create table person(id int(4),name char(20),age int(4));

Step4 插入数据到表中
Insert into person value(1,’zhangsan’,18);
Insert into person value(2,’lisi’,20);
select * from person;

二、操作HIVE数据库
①准备环境
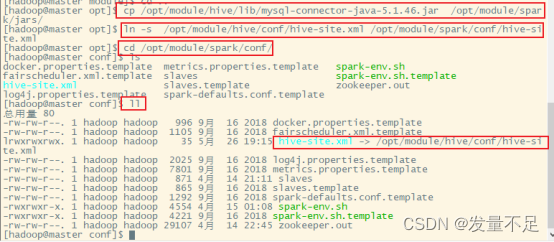
拷贝MySql驱动包到配置文件目录下
cp /opt/module/hive/lib/mysql-connector-java-5.1.46.jar /opt/module/spark/jars/
拷贝Hive-site.xml到spark目录下
ln -s /opt/module/hive/conf/hive-site.xml /opt/module/spark/conf/hive-site.xml
需要先启动hadoop zookeeper和spark
zkServer.sh start(在opt目录下)
start-all.sh(随意目录下)
sbin/start-all.sh(在spark目录下启动)
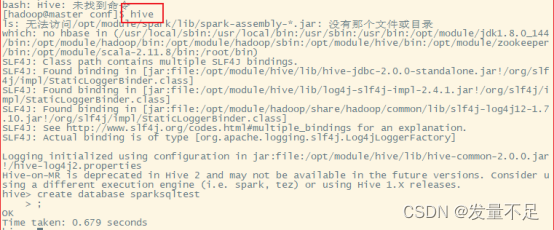
cd /opt/module/hive/bin/
启动Hive
Hive
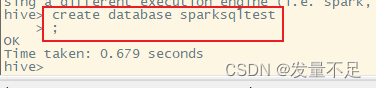
create database sparksqltest;
②创建表类型
create table if not exists sparksqltest.person(id int,name string,age int);
use sparksqltest;

③插入数据
insert into person values(1,"tom",29);
insert into person values(2,"jerry",20);
创建成功person数据表,并在该表中插入了两条数据后
##克隆master会话窗口,执行Spark-Shell****##****
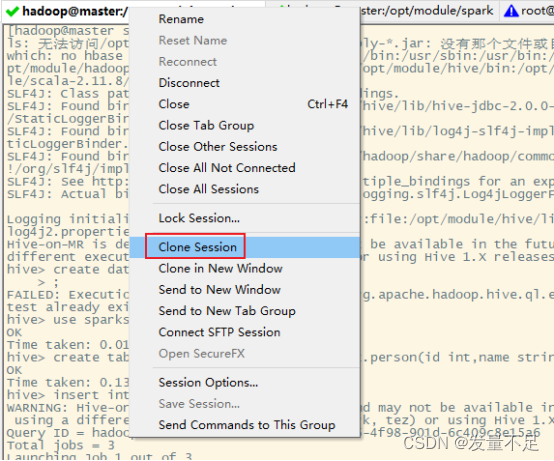
④Spark SQL 操作Hive数据库
启动Spark
bin/spark-shell --master spark://master:7077,slave1:7077,slave2:7077
查看数仓,切换数据库
spark.sql("use sparksqltest")
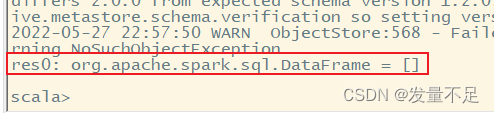
查看person表原来的数据
spark.sql("select * from person").show
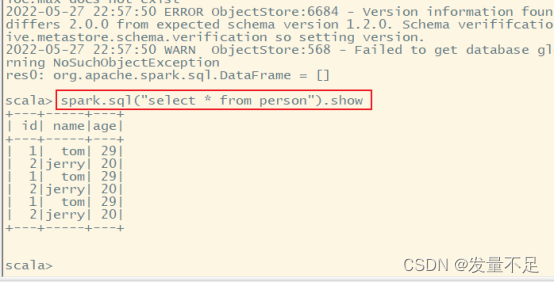
//添加两条新的数据
//导入库
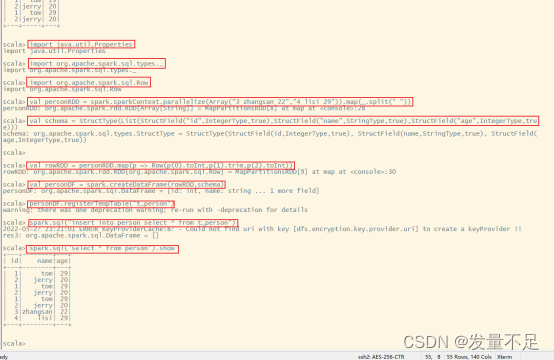
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
//创建DataFrame
val personRDD = spark.sparkContext.parallelize(Array("3 zhangsan 22","4 lisi 29")).map(_.split(" "))
val schema = StructType(List(StructField("id",IntegerType,true),StructField("name",StringType,true),StructField("age",IntegerType,true)))
val rowRDD = personRDD.map(p => Row(p(0).toInt,p(1).trim,p(2).toInt))
val personDF = spark.createDataFrame(rowRDD,schema)
//将数据插入
personDF.registerTempTable("t_person")
spark.sql("insert into person select * from t_person")
//显示输入
spark.sql("select * from person").show
** 感谢观看完本文章❤**
本文转载自: https://blog.csdn.net/m0_57781407/article/details/126782617
版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。
版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。