
一、大数据处理的基本流程——采集、存储、分析和实现
** ①数据采集->②数据归整->③数据存储->④数据处理->⑤数据呈现**
二、大数据技术
- 数据采集宇预处理
- 数据采集和管理
- 数据处理与分析
- 数据安全与隐私保护
(一)数据采集与预处理**:联机分析处理(OLAP)与实时处理分析 **

(二)数据存储与管理*:对结构、非结构、半结构等海量数据进行存储(关系数据库、非关系数据库、数***据仓库、分布式文件系统) **
(三)数据处理与分析**:利用 MapReduce 等结合着机器学习和数据挖掘算法实现数据分析和处理 **

(四)数据隐私和安全保护**:构建出隐私数据保护体系和数据安全体系,保护个人隐私和数据安全。 **

三、Hadoop技术——分布式系统基础架构
(1)**Hadoop 是用于处理(运算分析)海量数据的技术平台,且是采用分布式集群的方式。 **
(2)**功能 **
**①、存储:提供海量数据的存储服务; **
**②、计算:提供分析海量数据的编程框架及运行平台; **
(3)三大核心组件:
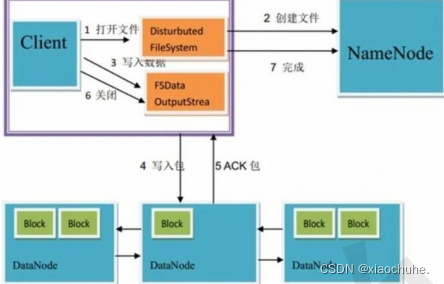
①、**HDFS:hadoop **分布式文件系统海量数据的存储(集群服务)
②、MapReduce:分布式运算框架(编程框架)(导 jar 包程序)
③、Yarn:资源调度管理集群

四、MapReduce技术
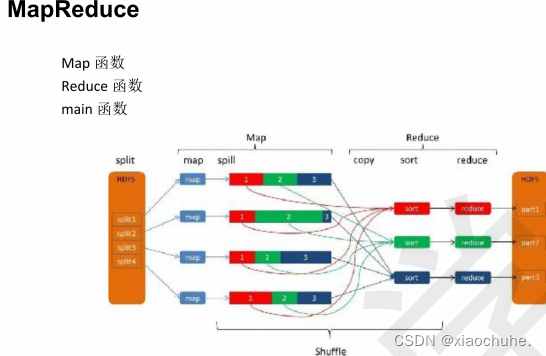
**(1)MapReduce 是 Hadoop 核心技术之一。 **
*(***2)MapReduce 框架的核心步骤主要分两部分:Map 和 Reduce。 **
*(3)为分布式计算的程序设计提供了良好的编程接口,并且屏蔽了底层通信原理,使得程序员只需关心*业务逻辑本事,就可轻易的编写出基于集群的分布式并行程序。 **
*(***4)“Map”就是将一个任务分解成为多个子任务并行的执行; **
(****5)“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果并输出。
(6)MapReduce 的功能:
①、数据划分和计算任务调度:将 job 分成多个数据块来计算,并自动调度计算节点来处理这些数据块。
②、数据/代码互定位:减少数据通信,从数据所在的本地机架上寻找可用节点以减少通信延迟。
③、系统优化:为了减少数据通信开销,中间结果数据进入 Reduce 节点前会进行一定的合并处理
④、出错检测和恢复: MapReduce 需要能检测并隔离出错节点,并调度分配新的节点接管出错节点的计算任务,维护数据存储的可靠性。
五、NoSQL技术
*(1)NoSQL 数据库是非关系型数据库,它主要是用来解决半结构化数据和非结构化数据的存储问题。***(mongoDB、redis、hbase 等) **
*(***2)NoSQL 是一种非关系型 DMS,不需要固定的架构,可以避免 joins 链接,并且易于扩展。 **
*(***3)NoSQL 技术功能: **
**①、数据管理:提供查询窗口和命令窗口功能。 **
**②、结构管理:提供库、文档和索引等对象管理功能。 **
**③、实时性能展示:提供核心性能指标的实时展示。 **
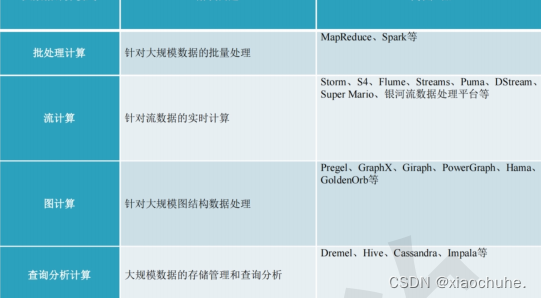
六、大数据计算模式
- 批处理计算
- 流计算
- 图计算
- 查询分析计算
(一)批处理计算
批处理计算主要解决针对大规模数据的批量处理,也是我们日常数据分析工作中常见的一类数据处理需求。
MapReduce

**Spark **

(二)流计算
批处理计算主要解决针对大规模数据的批量处理,也是我们日常数据分析工作中常见的一类数据处理需求。
流数据

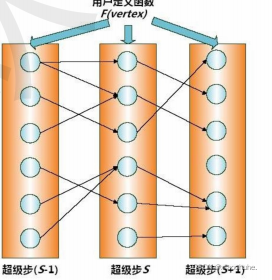
(三)图计算
在大数据时代,许多大数据都是以大规模图或网络的形式呈现,如社交网络、传染病传播途径、交通事故对路网的影响等,此外,许多非图结构的大数据也常常会被转换为图模型后再进行处理分析。

(四)查询分析计算
针对超大规模数据的存储管理和查询分析,需要提供实时或准实时的响应,才能很好地满足企业经营管理需求。
版权归原作者 xiaochuhe. 所有, 如有侵权,请联系我们删除。