
在数据科学的世界里,深度学习方法无疑是最先进的研究。每天都有许多新的变化被发明和实现,特别是在自然语言处理(NLP)和计算机视觉(CV)领域,深度学习在近年来取得了巨大的进步。这种趋势也可以在Kaggle比赛中观察到。在这些NLP和CV任务竞赛中,最近获胜的解决方案是利用深度学习模型。
然而,深度学习模型真的比GBDT(梯度提升决策树)这样的“传统”机器学习模型更好吗?我们知道,正如上面提到的,深度学习模型在NLP和CV中要好得多,但在现实生活中,我们仍然有很多表格数据,我们是否可以确认,即使在结构化数据集上,深度学习模型也比GBDT模型表现得更好?为了回答这个问题,本文使用Kaggle的家庭保险数据集来比较每个模型的性能。我知道我们不能仅仅通过一个数据集就得出哪个模型更好的结论,但这将是一个很好的起点来查看比较。此外,我将使用TabNet,这是一个相对较新的表格数据深度学习模型来进行比较。
这个实验的笔记本可以在我的kaggle代码中找到(https://www.kaggle.com/kyosukemorita/deep-learning-vs-gbdt-model-on-tabular-data)。这篇文章将省略对每个算法的解释,因为已经有很多这样的算法了:)
代码片段
如上所述,本实验使用了家庭保险数据集。这个数据集包括2007年到2012年的家庭保险政策数据,有超过100个特征,关于家庭特征,业主的人口统计等,在这个数据中有超过25万行。利用这个数据集,这个实验试图预测一份家庭保险政策是否会失效。不幸的是,并没有给出这个数据集中所有变量的细节,但是做这个实验已经足够好了。
现在我将通过这个实验的代码。这是最低限度的,应该是显而易见的。
首先,导入库。
import os
import numpy as np
import pandas as pd
import warnings
import time
from datetime import datetime
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import torch
from pytorch_tabnet.pretraining import TabNetPretrainer
from pytorch_tabnet.tab_model import TabNetClassifier
from sklearn.metrics import accuracy_score, f1_score, confusion_matrix, roc_auc_score
import xgboost as xgb
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
然后,创建一个计时函数,
def timer(myFunction):
def functionTimer(*args, **kwargs):
start_time = time.time()
result = myFunction(*args, **kwargs)
end_time = time.time()
computation_time = round(end_time - start_time, 2)
print("{} is excuted".format(myFunction.__name__))
print('Computation took: {:.2f} seconds'.format(computation_time))
return result
return functionTimer
这样我们就可以追踪函数运行的时间。
现在,这是数据集的预处理。这个过程包括
- 排除缺失值
- 清除目标变量
- 为分类变量创建虚拟变量
- 创建年龄特征
- 处理其他缺失值
@timer
def prepareInputs(df: "pd.dataFrame") -> "pd.dataFrame":
"""Prepare the input for training
Args:
df (pd.DataFrame): raw data
Process:
1. Exclude missing values
2. Clean the target variable
3. Create dummy variables for categorical variables
4. Create age features
5. Impute missing value
Return: pd.dataFrame
"""
# 1. Exclude missing values
df = df[df["POL_STATUS"].notnull()]
# 2. Clean the target variable
df = df[df["POL_STATUS"] != "Unknown"]
df["lapse"] = np.where(df["POL_STATUS"] == "Lapsed", 1, 0)
# 3. Create dummy variables for categorical variables
categorical_cols = ["CLAIM3YEARS", "BUS_USE", "AD_BUILDINGS",
"APPR_ALARM", "CONTENTS_COVER", "P1_SEX",
"BUILDINGS_COVER", "P1_POLICY_REFUSED",
"APPR_LOCKS", "FLOODING",
"NEIGH_WATCH", "SAFE_INSTALLED", "SEC_DISC_REQ",
"SUBSIDENCE", "LEGAL_ADDON_POST_REN",
"HOME_EM_ADDON_PRE_REN","HOME_EM_ADDON_POST_REN",
"GARDEN_ADDON_PRE_REN", "GARDEN_ADDON_POST_REN",
"KEYCARE_ADDON_PRE_REN", "KEYCARE_ADDON_POST_REN",
"HP1_ADDON_PRE_REN", "HP1_ADDON_POST_REN",
"HP2_ADDON_PRE_REN", "HP2_ADDON_POST_REN",
"HP3_ADDON_PRE_REN", "HP3_ADDON_POST_REN",
"MTA_FLAG", "OCC_STATUS", "OWNERSHIP_TYPE",
"PROP_TYPE", "PAYMENT_METHOD", "P1_EMP_STATUS",
"P1_MAR_STATUS"
]
for col in categorical_cols:
dummies = pd.get_dummies(df[col],
drop_first = True,
prefix = col
)
df = pd.concat([df, dummies], 1)
# 4. Create age features
df["age"] = (datetime.strptime("2013-01-01", "%Y-%m-%d") - pd.to_datetime(df["P1_DOB"])).dt.days // 365
df["property_age"] = 2013 - df["YEARBUILT"]
df["cover_length"] = 2013 - pd.to_datetime(df["COVER_START"]).dt.year
# 5. Impute missing value
df["RISK_RATED_AREA_B_imputed"] = df["RISK_RATED_AREA_B"].fillna(df["RISK_RATED_AREA_B"].mean())
df["RISK_RATED_AREA_C_imputed"] = df["RISK_RATED_AREA_C"].fillna(df["RISK_RATED_AREA_C"].mean())
df["MTA_FAP_imputed"] = df["MTA_FAP"].fillna(0)
df["MTA_APRP_imputed"] = df["MTA_APRP"].fillna(0)
return df
为了训练和评估模型,我将分割数据集。
# Split train and test
@timer
def splitData(df: "pd.DataFrame", FEATS: "list"):
"""Split the dataframe into train and test
Args:
df: preprocessed dataframe
FEATS: feature list
Returns:
X_train, y_train, X_test, y_test
"""
train, test = train_test_split(df, test_size = .3, random_state = 42)
train, test = prepareInputs(train), prepareInputs(test)
return train[FEATS], train["lapse"], test[FEATS], test["lapse"]
用深度学习模型训练数字特征需要标准化。这个函数完成了这项工作。
# Standardise the data sets
@timer
def standardiseNumericalFeats(X_train, X_test):
"""Standardise the numerical features
Returns:
Standardised X_train and X_test
"""
numerical_cols = [
"age", "property_age", "cover_length", "RISK_RATED_AREA_B_imputed",
"RISK_RATED_AREA_C_imputed", "MTA_FAP_imputed", "MTA_APRP_imputed",
"SUM_INSURED_BUILDINGS", "NCD_GRANTED_YEARS_B", "SUM_INSURED_CONTENTS",
"NCD_GRANTED_YEARS_C", "SPEC_SUM_INSURED", "SPEC_ITEM_PREM",
"UNSPEC_HRP_PREM", "BEDROOMS", "MAX_DAYS_UNOCC", "LAST_ANN_PREM_GROSS"
]
for col in numerical_cols:
scaler = StandardScaler()
X_train[col] = scaler.fit_transform(X_train[[col]])
X_test[col] = scaler.transform(X_test[[col]])
return X_train, X_test
现在所有的预处理都完成了。下面,我将展示每个模型的训练代码。
XGBoost
@timer
def trainXgbModel(X_train, y_train, X_test, y_test, FEATS, ROUNDS) -> "XGBoost model obj":
"""Train XGBoost model
Arg:
ROUNDS: Number of training rounds
Return:
Model object
"""
params = {
'eta': 0.02,
'max_depth': 10,
'min_child_weight': 7,
'subsample': 0.6,
'objective': 'binary:logistic',
'eval_metric': 'error',
'grow_policy': 'lossguide'
}
dtrain, dtest = xgb.DMatrix(X_train, y_train, feature_names=FEATS), xgb.DMatrix(X_test, y_test, feature_names=FEATS)
EVAL_LIST = [(dtrain, "train"),(dtest, "test")]
xgb_model = xgb.train(params,dtrain,ROUNDS,EVAL_LIST)
return xgb_model
MLP (1D-CNN)
@timer
def trainD1CnnModel(X_train, y_train):
"""Train D1-CNN model
Return:
keras model obj
"""
d1_cnn_model = keras.Sequential([
layers.Dense(4096, activation='relu'),
layers.Reshape((256, 16)),
layers.BatchNormalization(),
layers.Dropout(0.2),
layers.Conv1D(filters=16, kernel_size=5, strides=1, activation='relu'),
layers.MaxPooling1D(pool_size=2),
layers.Flatten(),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid'),
])
d1_cnn_model.compile(
optimizer=keras.optimizers.Adam(learning_rate=3e-3),
loss='binary_crossentropy',
metrics=[keras.metrics.BinaryCrossentropy()]
)
early_stopping = keras.callbacks.EarlyStopping(
patience=25,
min_delta=0.001,
restore_best_weights=True,
)
d1_cnn_model.fit(
X_train, y_train,
batch_size=10000,
epochs=5000,
callbacks=[early_stopping],
validation_data=(X_test, y_test),
)
return d1_cnn_model
TabNet
@timer
def trainTabNetModel(X_train, y_train, pretrainer):
"""Train TabNet model
Args:
pretrainer: pretrained model. If not using this, use None
Return:
TabNet model obj
"""
tabNet_model = TabNetClassifier(
n_d=16,
n_a=16,
n_steps=4,
gamma=1.9,
n_independent=4,
n_shared=5,
seed=42,
optimizer_fn = torch.optim.Adam,
scheduler_params = {"milestones": [150,250,300,350,400,450],'gamma':0.2},
scheduler_fn=torch.optim.lr_scheduler.MultiStepLR
)
tabNet_model.fit(
X_train = X_train.to_numpy(),
y_train = y_train.to_numpy(),
eval_set=[(X_train.to_numpy(), y_train.to_numpy()),
(X_test.to_numpy(), y_test.to_numpy())],
max_epochs = 100,
batch_size = 256,
patience = 10,
from_unsupervised = pretrainer
)
return tabNet_model
TabNet 使用预训练
预训练部分
@timer
def tabNetPretrain(X_train):
"""Pretrain TabNet model
Return:
TabNet pretrainer obj
"""
tabnet_params = dict(n_d=8, n_a=8, n_steps=3, gamma=1.3,
n_independent=2, n_shared=2,
seed=42, lambda_sparse=1e-3,
optimizer_fn=torch.optim.Adam,
optimizer_params=dict(lr=2e-2,
weight_decay=1e-5
),
mask_type="entmax",
scheduler_params=dict(max_lr=0.05,
steps_per_epoch=int(X_train.shape[0] / 256),
epochs=200,
is_batch_level=True
),
scheduler_fn=torch.optim.lr_scheduler.OneCycleLR,
verbose=10
)
pretrainer = TabNetPretrainer(**tabnet_params)
pretrainer.fit(
X_train=X_train.to_numpy(),
eval_set=[X_train.to_numpy()],
max_epochs = 100,
patience = 10,
batch_size = 256,
virtual_batch_size = 128,
num_workers = 1,
drop_last = True)
return pretrainer
TabNet训练可以通过上面的“trainTabNetModel”函数来完成。
训练完成后,我们需要对测试集做出预测并进行评估。
预测
# Make predictions
def makePredictions(X_test, xgb_model, d1_cnn_model, tabNet_model):
"""Make predictions
Return:
Predictions from each models
"""
y_xgb_pred = xgb_model.predict(xgb.DMatrix(X_test, feature_names=FEATS))
y_d1_cnn_pred = d1_cnn_model.predict(X_test).reshape(1, -1)[0]
y_tabNet_pred = tabNet_model.predict_proba(X_test.to_numpy())[:,1]
return [y_xgb_pred, y_d1_cnn_pred, y_tabNet_pred]
指标评估
# Evaluation
def evaluate(y_xgb_pred, y_d1_cnn_pred, y_tabNet_pred) -> None:
"""Evaluate the predictions
Process:
Print ROC AUC and F1 score of each models
"""
preds = {"XGBoost":y_xgb_pred, "D1 CNN":y_d1_cnn_pred, "TabNet":y_tabNet_pred}
for key in preds:
print("The ROC AUC score of "+ str(key) +" model is " +
str(round(roc_auc_score(y_test, preds[key]), 4))
)
for key in preds:
print("The F1 score of "+ str(key) +" model at threshold = 0.27 is " +
str(round(f1_score(y_test, np.where(preds[key] > 0.27, 1, 0)), 4))
)
可视化
# Plot prediction distribution
def plotPredictionDistribution(y_xgb_pred, y_d1_cnn_pred, y_tabNet_pred) -> None:
"""Plot histogram of predicted probability distributions of each model
"""
preds = {"XGBoost":y_xgb_pred, "D1 CNN":y_d1_cnn_pred, "TabNet":y_tabNet_pred}
for key in preds:
plt.hist(preds[key], bins = 100)
plt.title(f"Predicted probability distribution of {key}")
plt.show()
最后,这里是要在上面运行的主要脚本。
ROUNDS = 500
FEATS = [
"CLAIM3YEARS_Y", "BUS_USE_Y", "AD_BUILDINGS_Y",
"CONTENTS_COVER_Y", "P1_SEX_M", "P1_SEX_N", "BUILDINGS_COVER_Y",
"P1_POLICY_REFUSED_Y", "APPR_ALARM_Y", "APPR_LOCKS_Y", "FLOODING_Y",
"NEIGH_WATCH_Y", "SAFE_INSTALLED_Y", "SEC_DISC_REQ_Y", "SUBSIDENCE_Y",
"LEGAL_ADDON_POST_REN_Y", "HOME_EM_ADDON_PRE_REN_Y",
"HOME_EM_ADDON_POST_REN_Y", "GARDEN_ADDON_PRE_REN_Y",
"GARDEN_ADDON_POST_REN_Y", "KEYCARE_ADDON_PRE_REN_Y",
"KEYCARE_ADDON_POST_REN_Y", "HP1_ADDON_PRE_REN_Y", "HP1_ADDON_POST_REN_Y",
"HP2_ADDON_PRE_REN_Y", "HP2_ADDON_POST_REN_Y", "HP3_ADDON_PRE_REN_Y",
"HP3_ADDON_POST_REN_Y", "MTA_FLAG_Y", "OCC_STATUS_LP",
"OCC_STATUS_PH", "OCC_STATUS_UN", "OCC_STATUS_WD",
"OWNERSHIP_TYPE_2.0", "OWNERSHIP_TYPE_3.0", "OWNERSHIP_TYPE_6.0",
"OWNERSHIP_TYPE_7.0", "OWNERSHIP_TYPE_8.0", "OWNERSHIP_TYPE_11.0",
"OWNERSHIP_TYPE_12.0", "OWNERSHIP_TYPE_13.0", "OWNERSHIP_TYPE_14.0",
"OWNERSHIP_TYPE_16.0", "OWNERSHIP_TYPE_17.0",
"OWNERSHIP_TYPE_18.0", "PROP_TYPE_2.0", "PROP_TYPE_3.0", "PROP_TYPE_4.0",
"PROP_TYPE_7.0", "PROP_TYPE_9.0", "PROP_TYPE_10.0",
"PROP_TYPE_16.0", "PROP_TYPE_17.0", "PROP_TYPE_18.0", "PROP_TYPE_19.0",
"PROP_TYPE_20.0", "PROP_TYPE_21.0", "PROP_TYPE_22.0", "PROP_TYPE_23.0",
"PROP_TYPE_24.0", "PROP_TYPE_25.0", "PROP_TYPE_26.0", "PROP_TYPE_27.0",
"PROP_TYPE_29.0", "PROP_TYPE_30.0", "PROP_TYPE_31.0",
"PROP_TYPE_32.0", "PROP_TYPE_37.0", "PROP_TYPE_39.0",
"PROP_TYPE_40.0", "PROP_TYPE_44.0", "PROP_TYPE_45.0", "PROP_TYPE_47.0",
"PROP_TYPE_48.0", "PROP_TYPE_51.0", "PROP_TYPE_52.0", "PROP_TYPE_53.0",
"PAYMENT_METHOD_NonDD", "PAYMENT_METHOD_PureDD", "P1_EMP_STATUS_C",
"P1_EMP_STATUS_E", "P1_EMP_STATUS_F", "P1_EMP_STATUS_H", "P1_EMP_STATUS_I",
"P1_EMP_STATUS_N", "P1_EMP_STATUS_R", "P1_EMP_STATUS_S", "P1_EMP_STATUS_U",
"P1_EMP_STATUS_V", "P1_MAR_STATUS_B", "P1_MAR_STATUS_C", "P1_MAR_STATUS_D",
"P1_MAR_STATUS_M", "P1_MAR_STATUS_N", "P1_MAR_STATUS_O", "P1_MAR_STATUS_P",
"P1_MAR_STATUS_S", "P1_MAR_STATUS_W",
"age", "property_age", "cover_length", "RISK_RATED_AREA_B_imputed",
"RISK_RATED_AREA_C_imputed", "MTA_FAP_imputed", "MTA_APRP_imputed",
"SUM_INSURED_BUILDINGS", "NCD_GRANTED_YEARS_B", "SUM_INSURED_CONTENTS",
"NCD_GRANTED_YEARS_C", "SPEC_SUM_INSURED", "SPEC_ITEM_PREM",
"UNSPEC_HRP_PREM", "BEDROOMS", "MAX_DAYS_UNOCC", "LAST_ANN_PREM_GROSS"
]
print("Reading the data")
df = pd.read_csv("../input/home-insurance/home_insurance.csv")
print("Preprocessing the data")
X_train, y_train, X_test, y_test = splitData(df, FEATS)
X_train, X_test = standardiseNumericalFeats(X_train, X_test)
print("The ratio of lapse class in training set is " +
str(round(y_train.sum()/len(y_train) * 100, 2)) +
"%"
)
print("The ratio of lapse class in test set is " +
str(round(y_test.sum()/len(y_test) * 100, 2)) +
"%"
)
print("Training XGBoost model")
xgb_model = trainXgbModel(X_train, y_train, X_test, y_test, FEATS, ROUNDS)
print("Training MLP model")
d1_cnn_model = trainD1CnnModel(X_train, y_train)
print("Training TabNet model")
tabNet_model = trainTabNetModel(X_train, y_train, None)
print("Making predictions")
y_xgb_pred, y_d1_cnn_pred, y_tabNet_pred = makePredictions(X_test, xgb_model, d1_cnn_model, tabNet_model)
print("Evaluation of the model")
evaluate(y_xgb_pred, y_d1_cnn_pred, y_tabNet_pred)
print("Prediction distribution")
plotPredictionDistribution(y_xgb_pred, y_d1_cnn_pred, y_tabNet_pred)
上面是代码片段。现在,我们将在下面的部分中看到这个实验的结果。
模型的性能
如上所述,本文比较了经过和不经过预处理的XGBoost、MLP和TabNet的模型性能。采用ROC曲线下面积(AUC)评分和F1评分对模型进行评价。F1得分以0.27为阈值计算,因为我假设过期保险的分布与训练分布相似。下面是它的摘要。
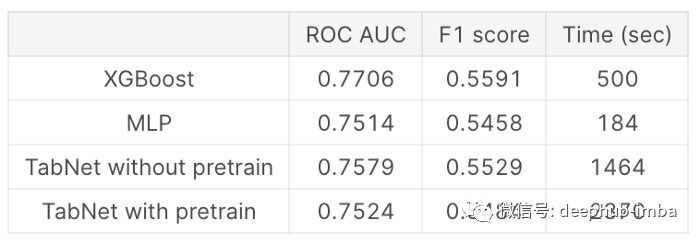
可以看出,就模型的精度而言,XGBoost模型是最好的,其他模型也相差不远。我已经使用了with和without pretraining的TabNet模型。经过预训练的TabNet结果应该更好,但是在这个数据集中,它得到的结果比没有进行预训练的结果略差。我不确定确切的原因是什么,但我猜这可以通过适当的超参数改进。
当我们研究每个模型的预测分布时,我们可以观察到XGBoost和TabNet模型之间有一定程度的相似性。我想这可能是因为TabNet也使用了类似树的算法。MLP模型的形状与其他模型有很大的不同。
在训练时间方面,MLP模型是最快的。我用过GPU,所以这是我得到这个结果的主要原因。与其他机型相比,TabNet两种机型都花费了相当长的时间。当涉及到超参数调优时,这将产生很大的差异。在这个实验中,我没有做任何超参数调优,而是使用任意参数。虽然MLP的训练时间几乎是XGBoost模型的1/3,但它需要优化的参数数量很容易超过XGBoost的10倍,所以如果我正在进行超参数优化,它可能需要比使用超参数优化的XGBoost模型的训练时间更长。
可解释性
可解释性对于一些机器学习模型业务用例是非常重要的。例如,能够解释为什么一个模型在金融/银行业中做出特定的决策是至关重要的。假设我们正在部署一个可以用于贷款批准的模型,并且客户想知道他的申请被拒绝的原因。银行不能告诉他我们不知道,因为这个行业有强大的监管机构。
模型的可解释性是MLP模型的缺点之一。虽然我们仍然可以使用一些方法(如使用SHAP)来评估哪些特性对做出预测做出了贡献,但如果我们能够快速检查特性的重要性列表,那将会更有用。在这里我将只比较XGBoost和TabNe特性的重要性。
XGBoost模型最重要的5个特性是:
- Marital status — Partner
- Payment method — Non-Direct debit
- Option “Emergencies” included after 1st renewal
- Building coverage — Self-damage
- Option “Replacement of keys” included before 1st renewal
TabNet模型的前5个重要特征是:
- Property type 21 (Detail not given)
- “HP1” included before 1st renewal
- Payment method — Pure Direct debit
- Type of membership 6 (Detail not given)
- Insurance cover length in years
令人惊讶的是,这两种模式的重要特征截然不同。XGBoost的重要特性对我来说更“可以理解和期待”——例如,如果客户有合作伙伴,这个人应该在财务上更负责,因此,家庭保险不太可能失效。另一方面,我想说,TabNet的重要特性没有那么直观。最重要的特性是“属性类型21”,这里没有给出这个特性的细节,所以我们不知道这个属性类型的特殊之处。第二重要的功能是在第一次更新之前就包含了“HP1”,我们不知道“HP1”是什么。也许,这就是TabNet的优势所在。由于它是一个深度学习模型,它可以探索特征之间不明显的关系,并使用最优的特征集,特别是像这次,没有给出所有特征的细节。
实际业务中部署的模型选择
当我们想要在现实生活中使用机器学习模型时,我们需要选择部署模型的最佳方式,通常会有一些权衡。例如,当我们建立几个像这次这样的模型,并且这些模型的精度非常相似时,集成它们可能会提高精度。如果这个整体策略很好地提高了10%的F1分数,那么采取这个策略是绝对必要的,但是如果这个改进只有1%,我们还想采取这个策略吗?可能不是,对吧?-由于多运行一个模型会增加计算成本,所以通常如果多部署一个模型的好处超过了计算成本,我们可以采用这个集成策略,否则,它在业务方面不是最优的。
此外,关于模型的可解释性,XGBoost模型使用了所有115个特性,而TabNet模型只使用了16个特性(预先训练的模型只使用了4个特性)。这是一个巨大的差异,理解这些差异也很重要。正如我上面提到的,在一些实际的业务用例中,了解这些特性的贡献是非常重要的。所以有时候,虽然准确率很高,但如果模型不能解释它为什么做出那个决定,就很难说服人们在现实生活中使用它,尤其是在非常敏感的业务中。
考虑到以上两点,在本例中,我们认为XGBoost模型优于其他深度学习模型。在精度方面,XGBoost模型比其他模型稍好一些(我没有尝试集成所有模型的预测,但让我们假设,它没有提高精度——我可能是错的)。就可解释性而言,如上所述,XGBoost模型的特性重要性列表在某种程度上是我们可以理解的(我们可以看到它背后的一些逻辑),而且在某种程度上是我们所期望的。
总结
本实验比较了XGBoost、MLP和TabNet在表格数据上的模型性能。这里我们使用家庭保险数据集来预测它的效果。从本次实验的结果来看,XGBoost模型在准确率(F1评分和ROC AUC评分)方面略优于其他深度学习模型,但由于本次实验使用GPU, MLP模型完成训练的速度最快。此外,通过查看XGBoost模型和TabNet模型的特性重要性列表,我们比较了它们的可解释性。XGBoost模型的特性重要性列表在某种程度上更容易理解和预期,另一方面,TabNet模型的特性重要性列表就不那么直观了。我认为这是由于算法的结构——深度学习模型,从本质上来说,探索的是特征之间不明显的关系,通常很难被人理解。通过这个简单的实验,我们证实了尽管近年来深度学习模型的改进令人印象深刻,而且肯定是最先进的,但在表格数据上,GBDT模型仍然和那些深度学习模型一样好,有时甚至比它们更好,特别是当我们想在现实生活中部署机器学习模型的时候。
作者:Kyosuke Morita
deephub翻译组