
一、创建OffsetUtils

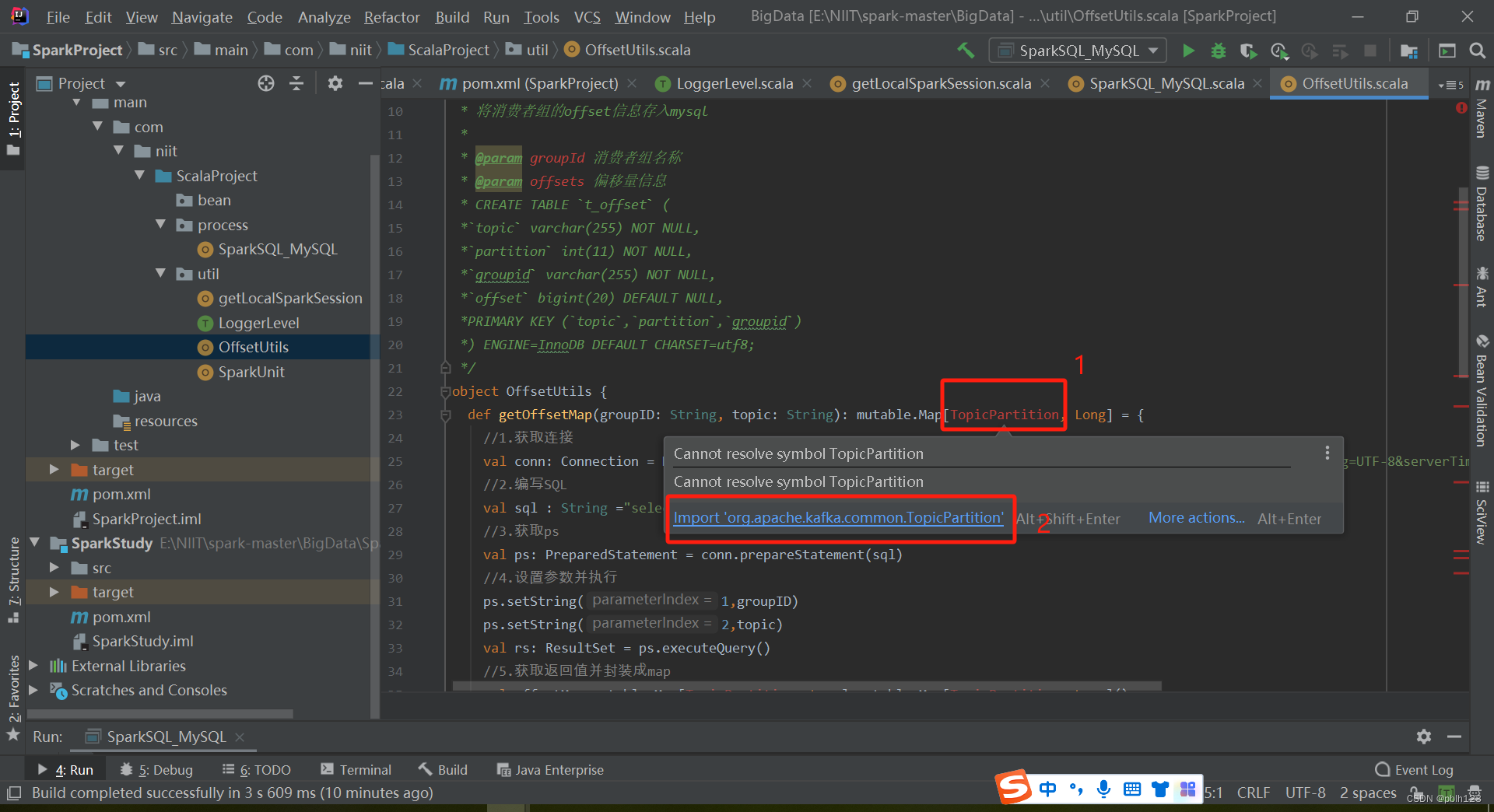
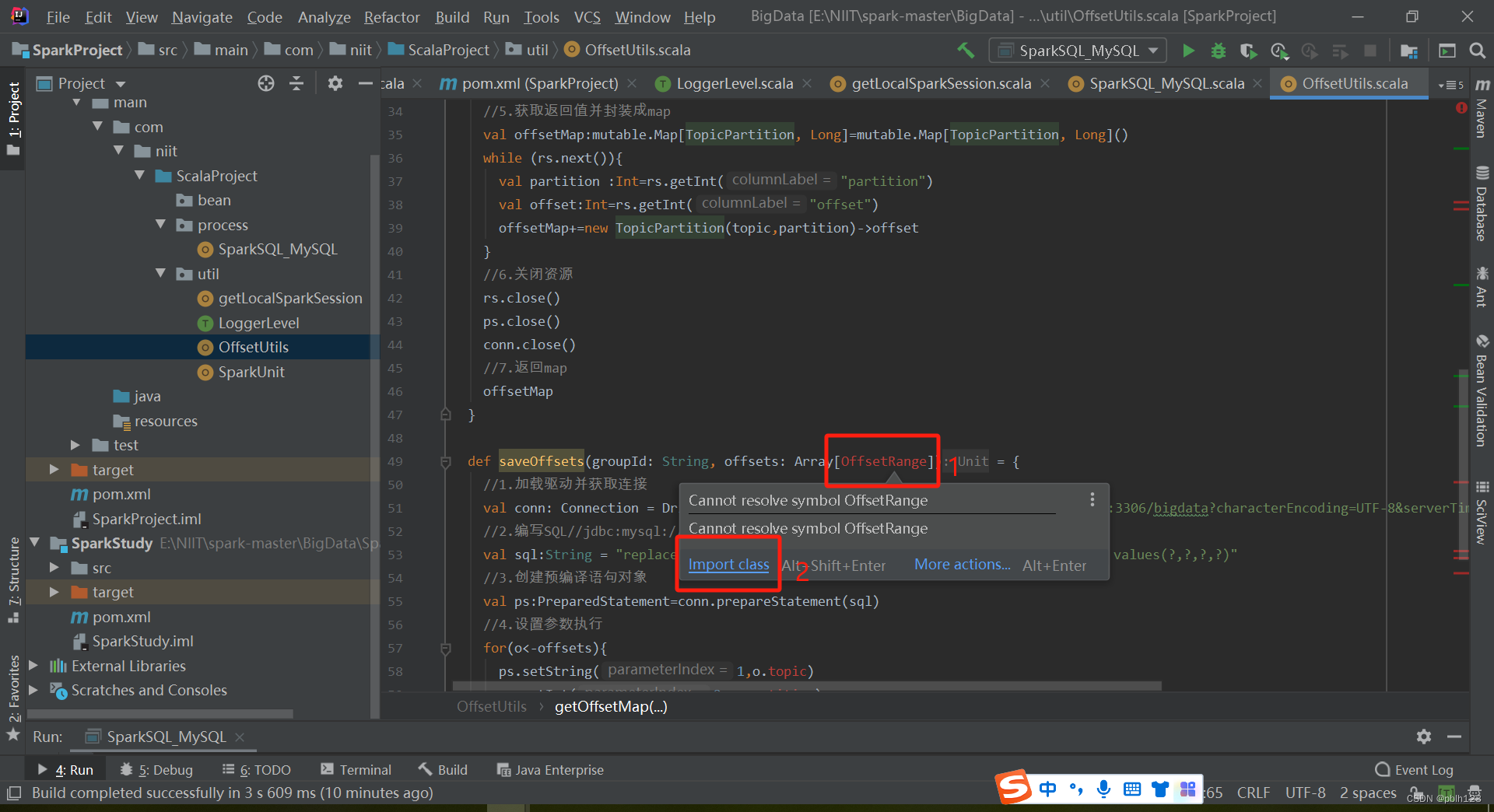
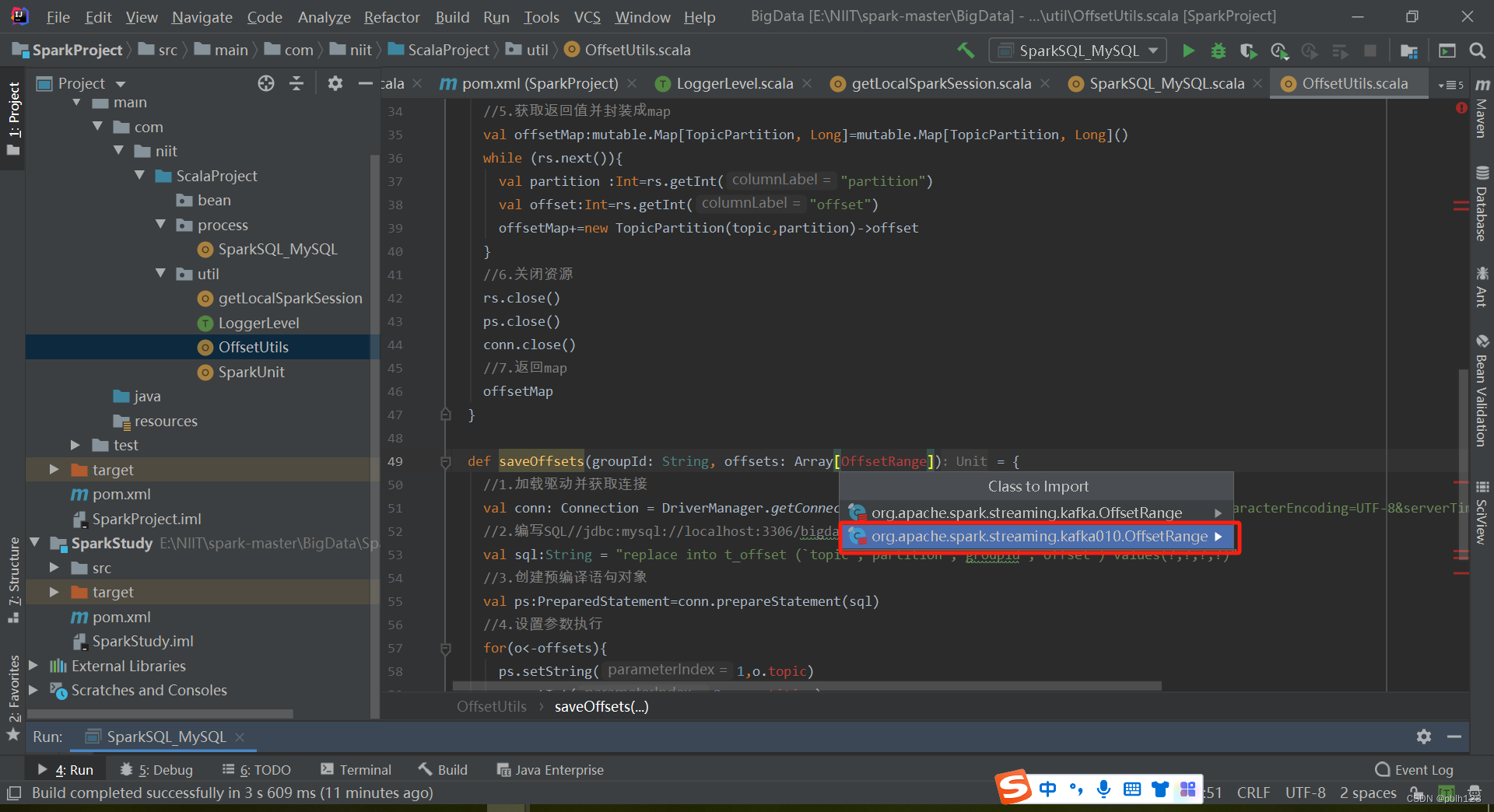
offsetutils代码
package exams
import org.apache.kafka.common.TopicPartition
import org.apache.spark.streaming.kafka010.OffsetRange
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}
import scala.collection.mutable
/**
* @projectName sparkGNU2023
* @package exams
* @className exams.OffsetUtils
* @description 将消费者组的offset信息存入mysql
* @author pblh123
* @date 2023/12/20 15:25
* @version 1.0
* @param groupId 消费者组名称
* @param offsets 偏移量信息
* CREATE TABLE `t_offset` (
* `topic` varchar(255) NOT NULL,
* `partition` int(11) NOT NULL,
* `groupid` varchar(255) NOT NULL,
* `offset` bigint(20) DEFAULT NULL,
* PRIMARY KEY (`topic`,`partition`,`groupid`)
* ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/
object OffsetUtils {
def getOffsetMap(groupID: String, topic: String): mutable.Map[TopicPartition, Long] = {
//1.获取连接
val conn: Connection = DriverManager.getConnection("jdbc:mysql://192.168.137.110:3306/bigdata19?characterEncoding=UTF-8&serverTimezone=UTC", "lh", "Lh123456!")
//2.编写SQL
val sql: String = "select `partition`,`offset` from t_offset where groupid = ? and topic = ? "
//3.获取ps
val ps: PreparedStatement = conn.prepareStatement(sql)
//4.设置参数并执行
ps.setString(1, groupID)
ps.setString(2, topic)
val rs: ResultSet = ps.executeQuery()
//5.获取返回值并封装成map
val offsetMap: mutable.Map[TopicPartition, Long] = mutable.Map[TopicPartition, Long]()
while (rs.next()) {
val partition: Int = rs.getInt("partition")
val offset: Int = rs.getInt("offset")
offsetMap += new TopicPartition(topic, partition) -> offset
}
//6.关闭资源
rs.close()
ps.close()
conn.close()
//7.返回map
offsetMap
}
def saveOffsets(groupId: String, offsets: Array[OffsetRange]) = {
//1.加载驱动并获取连接
val conn: Connection = DriverManager.getConnection("jdbc:mysql://192.168.137.110:3306/bigdata19?characterEncoding=UTF-8&serverTimezone=UTC", "lh", "Lh123456!")
//2.编写SQL//jdbc
val sql: String = "replace into t_offset (`topic`,`partition`,`groupid`,`offset`) values(?,?,?,?)"
//3.创建预编译语句对象
val ps: PreparedStatement = conn.prepareStatement(sql)
//4.设置参数执行
for (o <- offsets) {
ps.setString(1, o.topic)
ps.setInt(2, o.partition)
ps.setString(3, groupId)
ps.setLong(4, o.untilOffset)
ps.executeUpdate()
}
//5.关闭资源
ps.close()
conn.close()
}
}
本文转载自: https://blog.csdn.net/pblh123/article/details/135109147
版权归原作者 pblh123 所有, 如有侵权,请联系我们删除。
版权归原作者 pblh123 所有, 如有侵权,请联系我们删除。