
近期在工作上遇到了一个问题,我用requests写的爬虫代码交给公司运营同事使用,用于导出后台账户的某些产品数据,省的他们一个个的去页面上把数据复制到表格里,从而减轻工作量。
我再三强调代码的使用不要太过频繁,否则请求容易遭到网站拒绝,但他们毕竟必是程序员,不懂得这些,只想着用代码导数据有多快多爽,完全把我的话抛在了脑后。
好在网站只是拒绝了requests的请求,用浏览器还是能够访问的。

但这又面临一个新的问题,我用requests访问接口URL时headers里面是携带referer字段的,如果不带上正确的referer字段,接口不会返回我想要的数据。

至于为什么不直接在页面上拿数据,那是因为页面上的数据不完整,某些我们需要的数据只能从接口里获取。
我想到的解决方案有两个:
- 自定义headers头访问接口;
- 访问这个产品的页面,然后从chrome的Network里抓取我想要的接口的数据包
方案1:自定义headers
网上找的一个方法,代码大致如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument("no-sandbox")
chrome_options.add_argument("--disable-extensions")
driver = webdriver.Chrome(chrome_options=chrome_options)
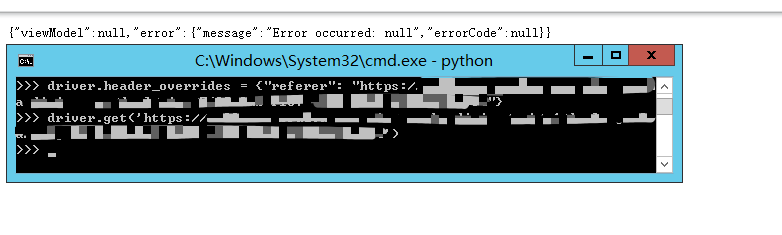
driver.header_overrides = {"referer": "要设置的referer"}
driver.get("要访问的接口")
经过多次尝试,发现并没有什么用,还是没法获取到接口的数据,于是这个方案在我这里被否决了,我不知道是不是我的代码有啥不对的地方,有发现的朋友麻烦告诉我一下。
方案2:抓取Network数据包
也是网上找的代码,稍加修改后把它变成我能够使用的样子,如下:
import json
from selenium import webdriver
from selenium.common.exceptions import WebDriverException
from selenium.webdriver.chrome.options import Options
caps = {
"browserName": "chrome",
'goog:loggingPrefs': {'performance': 'ALL'} # 开启日志性能监听
}
chrome_options = Options()
driver = webdriver.Chrome(desired_capabilities=caps, options=chrome_options) # 启动浏览器
driver.get('要访问的产品页面') # 访问该url
def filter_type(_type: str):
types = [
'application/javascript', 'application/x-javascript', 'text/css', 'webp', 'image/png', 'image/gif',
'image/jpeg', 'image/x-icon', 'application/octet-stream'
]
if _type not in types:
return True
return False
data = ''
while not data: # 当得到想要的数据时结束循环
performance_log = driver.get_log('performance') # 获取名称为performance的日志
for packet in performance_log:
message = json.loads(packet.get('message')).get('message') # 获取message的数据
if message.get('method') != 'Network.responseReceived': # 如果method不是responseReceived 类型就不往下执行
continue
packet_type = message.get('params').get('response').get('mimeType') # 获取该请求返回的type
if not filter_type(_type=packet_type): # 过滤type
continue
requestId = message.get('params').get('requestId') # 唯一的请求标识符。相当于该请求的身份证
url = message.get('params').get('response').get('url') # 获取该请求的url
if url != '想要获取数据的接口url': # 通过url来判断数据包是不是我们想要的那个
continue
try:
resp = driver.execute_cdp_cmd('Network.getResponseBody', {'requestId': requestId}) # selenium调用cdp
print(f'type: {packet_type} url: {url}')
data = resp
with open('data.json', 'w') as fp:
fp.write(json.dumps(data)) # 将数据存在文件里
break
except WebDriverException: # 忽略异常
pass
由于抓取的数据包是网页异步加载的,加载的时间受网络的影响,因此这里我加了个while循环,直到得到想要的数据包为止。

运行一次结果就出来了,我的评价是:非常好用!

保存下来的数据也正是我想要的,非常奈斯!
方案2参考来源:【Selenium】Selenium获取Network数据(高级版)
本文转载自: https://blog.csdn.net/m0_62410482/article/details/129625054
版权归原作者 夏末蝉未鸣01 所有, 如有侵权,请联系我们删除。
版权归原作者 夏末蝉未鸣01 所有, 如有侵权,请联系我们删除。