
一、实验内容
爬取豆瓣电影top250 movie.douban.com的前10部电影的信息,以及每部电影的前五热评保存在文件中。
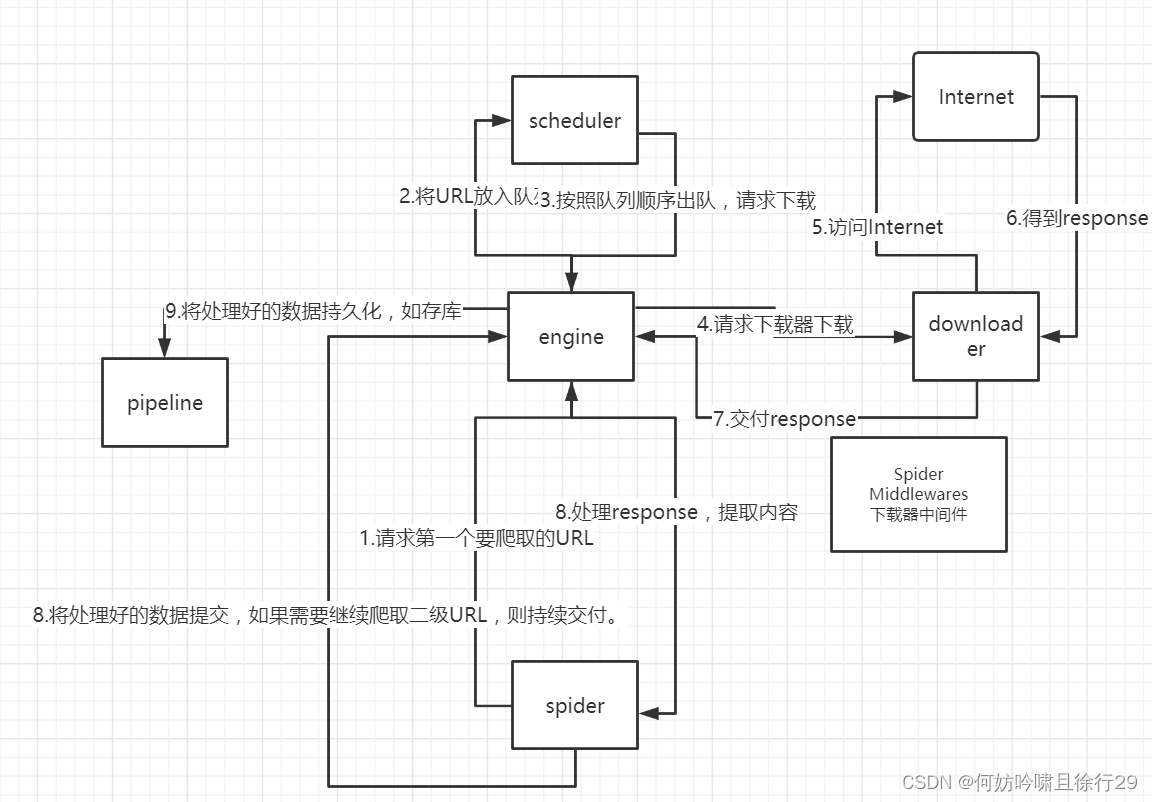
二、Scrapy框架介绍:
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。
(1)、调度器(Scheduler):
调度器,说白了把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是 什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
(2)、下载器(Downloader):
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
(3)、 爬虫(Spider):
爬虫,是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
(4)、 实体管道(Item Pipeline):
实体管道,用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
(5)、Scrapy引擎(Scrapy Engine):
Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
三、 实验步骤:
1.环境配置创建项目
1)安装scrapy框架(在cmd中)
pip install scrapy
2)创建一个新的Scrapy项目
scrapy startproject AAA AAA是你的项目名
scrapy startproject douban
3)创建Scrapy爬虫
进入AAA文件夹 scrapy genspider BBB CCC.com
BBB是你的爬虫名 CCC.com是你的目标域名
cd douban //进入你希望创建的爬虫目录
scrapy genspider douban_spider movie.douban.com
创建的目录如下
4)创建后spiders下会自动生成BBB.py,在这里进行规则编写
5)在settings.py中进行规则编写
注:善用Ctrl+F查找
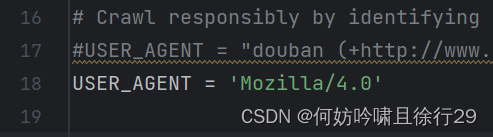
#设置用户代理避免被识别为脚本
USER_AGENT = 'Mozilla/4.0'
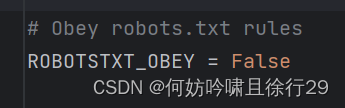
#默认遵守robots.txt,改掉
ROBOTSTXT_OBEY = False
#最大并发(默认16)
CONCURRENT_REQUESTS = 64

#禁用cookies(默认启用)
COOKIES_ENABLED = False

#开启管道(开启才能用piplines.py)
ITEM_PIPELINES = {
在这里设置编写的管道的优先级高低,越小优先级越高,默认会生成一个爬虫的,如果要编写入库等动作,可以设置这些动作之间的优先级顺序
}

#配置输出,设置输出为JSON格式
FEED_FORMAT = 'json'
FEED_URI = 'douban_top10_movies.json'
2.爬虫编写
在
douban/spiders
目录下
douban_spider.py
的文件中,添加以下代码:
#导入Scrapy框架,这是一个用于创建和管理Web爬虫的Python库
import scrapy
#导入名为"DoubanItem"的项目类,用于定义爬取到的数据的结构。
from douban.items import DoubanItem
#定义一个名为"DoubanSpider"的Spider类,继承自Scrapy的Spider类
class DoubanSpider(scrapy.Spider):
# 设置Spider的名称为'douban_spider',这个名称可以在运行爬虫时用来识别和调用爬虫。
name = 'douban_spider'
# 指定Spider的起始URL
start_urls = ['https://movie.douban.com/top250']
#定义了用于处理起始URL响应的parse方法,它接收一个response参数,包含了来自起始URL的页面内容。
def parse(self, response):
# 获取电影列表
movies = response.xpath('//ol[@class="grid_view"]/li')
# 仅获取前10部电影
for movie in movies[:10]:
item = DoubanItem()
item['title'] = movie.xpath('.//div[@class="hd"]/a/span[1]/text()').extract_first().strip()
item['rating'] = movie.xpath(
'.//div[@class="bd"]/div[@class="star"]/span[2]/text()').extract_first().strip()
item['link'] = movie.xpath('.//div[@class="hd"]/a/@href').extract_first()
#发送一个新的请求,爬取电影的评论页面,并将之前创建的DoubanItem对象通过meta参数传递给parse_comments方法
yield scrapy.Request(item['link'], callback=self.parse_comments, meta={'item': item})
#定义了用于处理评论页面响应的parse_comments方法,它接收包含电影评论页面内容的response
def parse_comments(self, response):
#从之前请求中传递的meta中获取item,这个item包含了电影的基本信息
item = response.meta['item']
comments = response.xpath('//div[@class="comment"]/p/span[@class="short"]')
# 获取前五热评
#通过yield返回包含电影信息和评论的item对象,将它们传递给Scrapy管道进行后续处理
item['comments'] = [comment.extract() for comment in comments[:5]]
yield item
定义Items:
在
douban/items.py
文件中定义你想要爬取的数据:
import scrapy
#"DoubanItem"是一个Scrapy的数据项(Item),用于存储网页上抓取的数据
class DoubanItem(scrapy.Item):
title = scrapy.Field() #标题
rating = scrapy.Field() #评分
link = scrapy.Field() #链接
comments = scrapy.Field() #评论
运行爬虫:
在PyCharm的终端运行以下命令:
scrapy crawl douban_spider
运行完成后,你将在项目目录下看到一个名为
douban_top10_movies.json
的文件,其中包含了豆瓣电影 Top 250 的前 10 部电影的标题、评分、链接和前五热评。
代码流程
1. 开始
2. 启动名为 'douban_spider' 的 Scrapy 爬虫
3. 跳转到起始URL:https://movie.douban.com/top250
4. 解析起始页面的响应(parse 方法)
5. 从响应中提取电影列表(movies)
6. 遍历前10部电影(movies[:10])
7. 创建一个 DoubanItem 对象(item)
8. 从电影元素中提取电影标题(title),评分(rating),和链接(link)
9. 发送一个新的请求到电影详情页面(item['link']),并指定回调函数为 parse_comments
10. 将 item 对象作为元数据(meta)附加到请求
11. 进入 parse_comments 方法,处理电影详情页面的响应
12. 从元数据中提取之前创建的 item 对象
13. 从响应中提取电影评论(comments)
14. 获取前五条热门评论
15. 将评论存储在 item 对象的 comments 字段中
16. 返回 item 对象,将其传递到 Scrapy 管道进行处理
17. 重复步骤 6-11,直到遍历完前10部电影
18. 结束
注意事项:
1.如果在PyCharm中 import scrapy 报错,在终端中再次运行
pip install scrapy
- xpath的路径是根据所选择的网页源码确定的
版权归原作者 何妨吟啸且徐行29 所有, 如有侵权,请联系我们删除。