
微信公众号:运维开发故事,作者:double冬
1、Kafka 概述
2、Kafka 解决了什么问题
3、Kafka 技术特性
4、Kafka 工作原理
4.1、架构图
4.2、Kafka 写流程
4.3、Kafka 读流程
5、Kafka 数据结构说明
5.1、Kafka 在 Zookeeper 中的注册数据结构
5.2、Kafka Topic 的数据结构
6、Kafka 运维
6.1、Topic 管理指令
6.2、增删节点后的 数据均衡
6.3、消费情况指令
6.4、设置Topic过期时间
6.5、工具相关
7、Kafka 常用性能调优
7.1、磁盘目录优化
7.2、JVM参数配置
7.3、日志数据刷盘策略
7.4、日志保留时间
1 Kafka 概述
Kafka 起初是 由 LinkedIn 公司采用 Scala 语言开发的一个多分区、多副本且基于 ZooKeeper 协调的分布式消息系统,现已被捐献给 Apache 基金会。目前 Kafka 已经定位为一个分布式流式处理平台,它以高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性而被广泛使用,主要是由 Scala 和 Java 编写。
它是一种高吞吐量的分布式发布订阅消息系统,可以处理事件流数据。通过 Kafka 你可以非常方便的把想要发布的消息,分发给任何想要订阅该消息的接收者。上游生产者只需要把消息输入到 Kafka 指定 Topic ,下游接收者只要订阅该 Topic ,就能低延时、高吞吐量的接收到上游的消息;Kafka 还支持 同一个 Topic 同时被多个下游消费者消费,且不同消费者之间数据处理进度互不干扰。
- 对于一个 topic,他的每一个 partition 同一时间只能被同一消费者组中的一个消费者所消费
- 相比于 AMQ,它更加轻量级:非侵入性的、依赖的东西非常少,占用资源非常少,部署简单,没有太多依赖,比较容易使用。
目前越来越多的开源分布式处理系统如 Cloudera、Storm、Spark、Flink 等都支持与 Kafka 集成,Kafka 之所以受到越来越多的青睐,与它所“扮演”的三大角色是分不开的:
- 消息系统: Kafka 和传统的消息系统(也称作消息中间件)都具备系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。与此同时,Kafka 还提供了大多数消息系统难以实现的消息顺序性保障及回溯消费的功能。
- 存储系统: Kafka 把消息持久化到磁盘,相比于其他基于内存存储的系统而言,有效地降低了数据丢失的风险。也正是得益于 Kafka 的消息持久化功能和多副本机制,我们可以把 Kafka 作为长期的数据存储系统来使用,只需要把对应的数据保留策略设置为“永久”或启用主题的日志压缩功能即可。
- 流式处理平台: Kafka 不仅为每个流行的流式处理框架提供了可靠的数据来源,还提供了一个完整的流式处理类库,比如窗口、连接、变换和聚合等各类操作。
2 Kafka 解决了什么问题
消息队列一般主要处理:异步处理、服务解耦、流量控制,因此 Kafka 作为消息队列的一种,同样在解决这些问题。
3 Kafka 技术特性
高吞吐量、低延迟:kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个 topic 可以分多个 partition, consumer group 对 partition 进行并行 consume 操作。
可扩展性:kafka 集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失,消息被消费仍然不会被立即删除,而是会有过期时间。
容错性:允许集群中节点失败(若副本数量为 n,则允许 n-1 个节点失败)
高并发:支持数千个客户端同时读写
队列模式:所有 consumer 都在一个队列,这样消息就在队内进行分区并行消费
订阅-发布模式:所有 consumer 都不再一个队列,这样 topic 消息可以广播给所有订阅的消费者
4 Kafka 工作原理
4.1 架构图
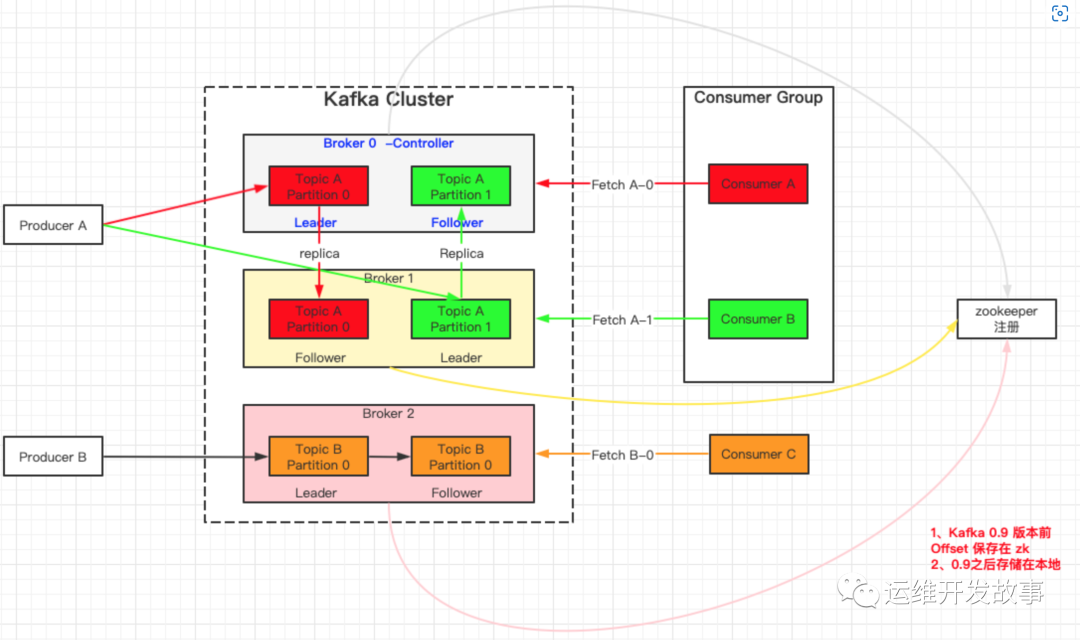
img
Producer :
消息生产者,也就是发送消息的一方。生产者负责创建消息,然后将其投递到 Kafka 中;
Consumer :
消息消费者,也就是接收消息的一方。消费者连接到 Kafka 上并接收消息,进而进行相应的业务逻辑处理;
Consumer Group (CG):
消费者组,由多个 consumer 组成。 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。 所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
Broker :
服务代理节点。对于 Kafka 而言,Broker 可以简单地看作一个独立的 Kafka 服务节点或 Kafka 服务实例。大多数情况下也可以将 Broker 看作一台 Kafka 服务器,前提是这台服务器上只部署了一个 Kafka 实例。一个或多个 Broker 组成了一个 Kafka 集群。一般而言,我们更习惯使用首字母小写的 broker 来表示服务代理节点。
Controller:
集群中会有一个或者多个 broker,其中有一个 broker 会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。
- 当某个分区的 leader 副本出现故障时,由控制器负责为该分区选举新的leader 副本。
- 当检测到某个分区的 ISR 集合发生变化时,由控制器负责通知所有 broker 更新其元数据信息。
- 当某个 Topic 增加分区数量时,同样还是由控制器负责分区的重新分配。
在 Kafka 中还有两个特别重要的概念—主题(Topic)与分区(Partition)
Topic :
可以理解为一个队列,生产者和消费者在队列的两端,一个输出数据,一个消费数据,它们面向的都是一个 topic;
Partition:
为了实现扩展性,一个数据量非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;那么 topic 的并发度基本等于 partition 的个数。
Kafka 中的消息以主题为单位进行归类,生产者负责将消息发送到特定的主题(发送到 Kafka 集群中的每一条消息都要指定一个主题),而消费者负责订阅主题并进行消费。
主题是一个逻辑上的概念,它还可以细分为多个分区,一个分区只属于单个主题,很多时候也会把分区称为主题分区(Topic-Partition)。同一主题下的不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。
offset 是消息在分区中的唯一标识,Kafka 通过它来保证消息在分区内的顺序性,不过 offset 并不跨越分区,也就是说,Kafka 保证的是分区有序而不是主题有序。
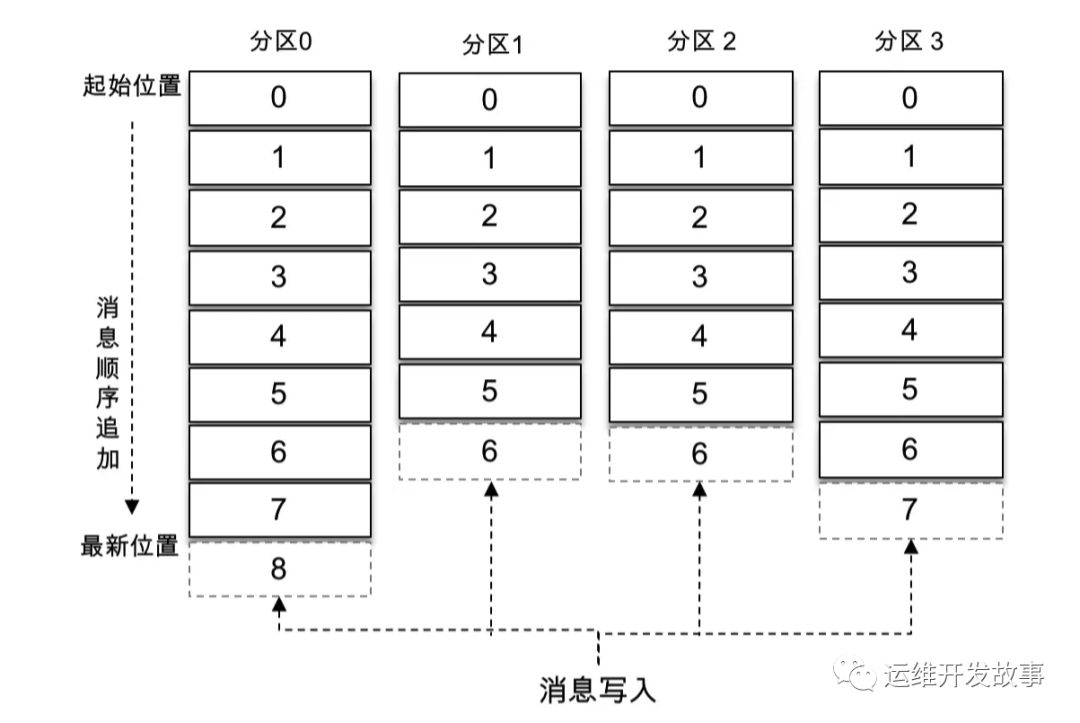
img
如上图所示,主题中有4个分区,消息被顺序追加到每个分区日志文件的尾部。Kafka 中的分区可以分布在不同的服务器(broker)上,也就是说,一个主题可以横跨多个 broker,以此来提供比单个 broker 更强大的性能。
每一条消息被发送到 broker 之前,会根据分区规则选择存储到哪个具体的分区。如果分区规则设定得合理,所有的消息都可以均匀地分配到不同的分区中。如果一个主题只对应一个文件,那么这个文件所在的机器I/O将会成为这个主题的性能瓶颈,而分区解决了这个问题。在创建主题的时候可以通过指定的参数来设置分区的个数,当然也可以在主题创建完成之后去修改分区的数量,通过增加分区的数量可以实现水平扩展。
Replica:
Kafka 为分区引入了多副本(Replica)机制,通过增加副本数量可以提升容灾能力。
同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中 leader 副本负责处理读写请求,follower 副本只负责与 leader 副本的消息同步。副本处于不同的 broker 中,当 leader 副本出现故障时,从 follower 副本中重新选举新的 leader 副本对外提供服务。Kafka 通过多副本机制实现了故障的自动转移,当 Kafka 集群中某个 broker 失效时仍然能保证服务可用。
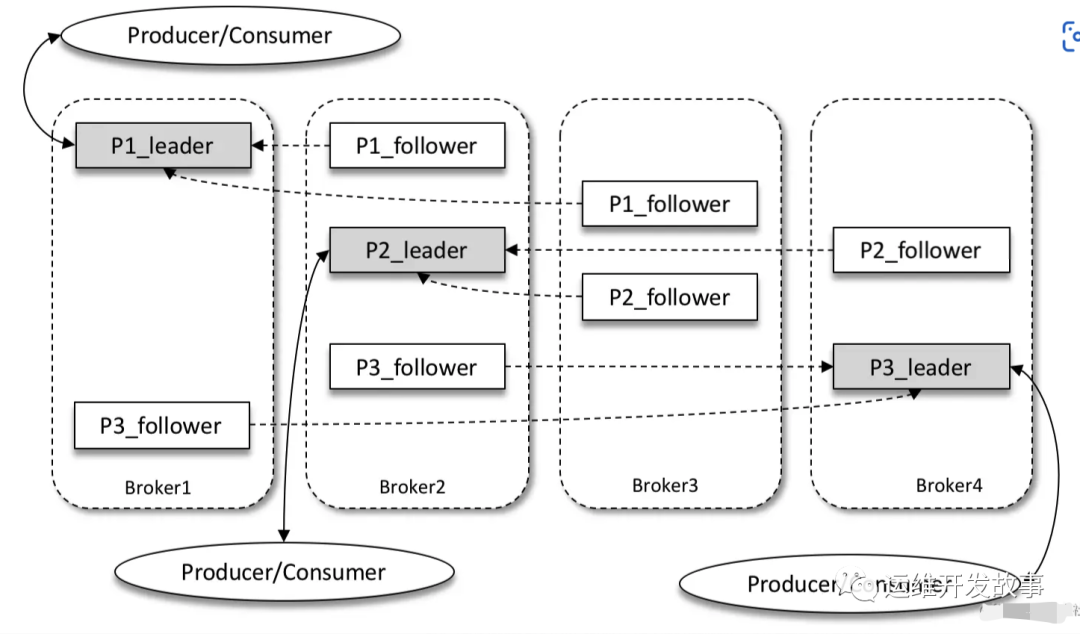
img
如上图所示,Kafka 集群中有4个 broker,某个主题中有3个分区,且副本因子(即副本个数)也为3,如此每个分区便有1个 leader 副本和2个 follower 副本。生产者和消费者只与 leader 副本进行交互,而 follower 副本只负责消息的同步,很多时候 follower 副本中的消息相对 leader 副本而言会有一定的滞后。
Kafka 消费端也具备一定的容灾能力。Consumer 使用拉(Pull)模式从服务端拉取消息,并且保存消费的具体位置,当消费者宕机后恢复上线时可以根据之前保存的消费位置重新拉取需要的消息进行消费,这样就不会造成消息丢失。
4.2 Kafka 写流程
图片来自网络
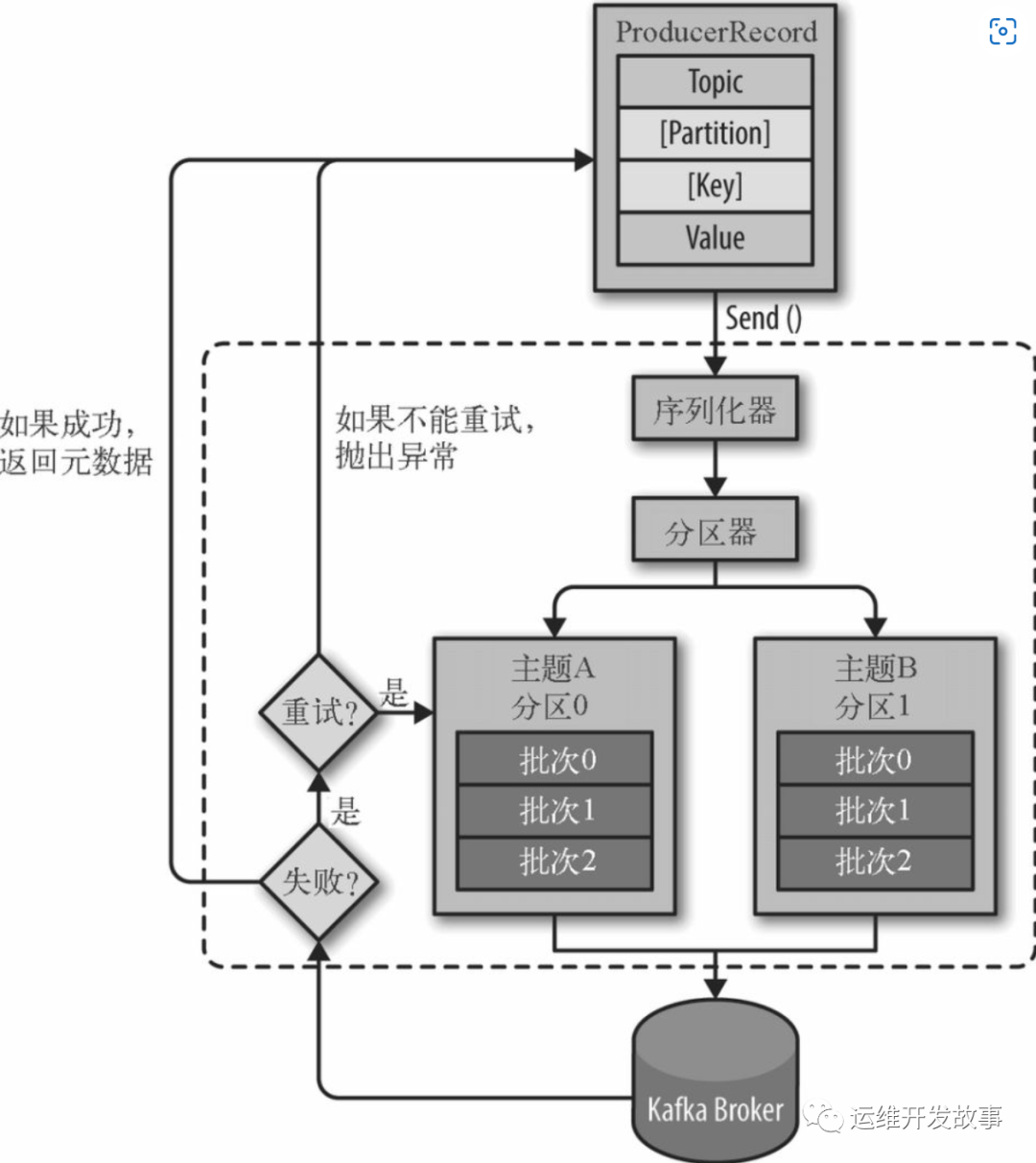
img
- 连接 zk 集群,从 zk 中拿到对应的 topic 的 partition 信息和 partition 的 leader 的相关信息。
- 向对应 broker 发消息
- 客户端在发送消息时,必须指定消息所属的 Topic 和消息值 Value,此外还可以指定消息所属的 Partition 以及消息的 Key。
- 对消息做序列化处理
- 如果 消息记录 中指定了 Partition,则 Partitioner 不做任何事情;否则,Partitioner 根据消息的 key 得到一个 Partition。这是生产者就知道向哪个 Topic下的哪个 Partition 发送这条消息。
- 消息被添加到相应的 batch 中,独立的线程将这些 batch 发送到 Broker 上(注意,消息不是一条一条发往 broker 的,而是会在 客户端本地缓存一批数量后,在发出去,因此客户端是以 批-batch 为单位发送消息的,即一批当中包含一条或多条消息;同样,broker 也是以批为单位进行数据存储的,后面会讲到 )。
- broker 收到消息会返回一个响应。如果消息成功写入 Kafka,则返回成功信息,内容包含了 Topic 信息、Patition信息、消息在 Partition 中的 Offset 信息;若失败,返回一个错误。
4.3 Kafka 读流程
- 连接 zk 集群,从 zk 中拿到对应的 topic 的 partition 信息和 partition 的 leader 的相关信息
- 连接到对应的 leader 对应的 broker
- consumer 通过请求将希望读取的 topic、partition 以及对应的 offset 发送给 leader
- leader 根据 offset 等信息定位到 segment(索引文件和日志文件)
- 根据索引文件中的内容,定位到日志文件中该偏移量对应的开始位置读取相应长度的数据并返回给 consumer
5 Kafka 数据结构说明
5.1 Kafka 在 Zookeeper 中的注册数据结构
kafka 使用 zookeeper 来存储一些 meta 信息,并使用了zookeeper watch 机制来发现 meta 信息的变更并作出相应的动作(比如 consumer 失效,触发负载均衡等)。
0)Kafka 集群注册信息:永久节点,集群ID 当第一台 Broker 启动的时候, 发现 /cluster/id 不存在,那么它就会把自己的 cluster.id 配置写入 zk;;标记当前 zk 是属于集群哪个集群;;后面其他的 Broker 启动的时候会去获取该数据,,如果发现数据跟自己的配置不一致;;则抛出异常,加入的不是同一个集群。
数据节点:/cluster/id,数据样例:
{
"version":"1",
"id":"0"
}
- Broker 节点注册:临时节点,当一个 kafka broker 启动后,首先会向 zookeeper 注册自己的节点信息(临时 znode ),同时当 broker 和 zookeeper 断开连接时,此 znode 也会被删除。
每个 broker 的配置文件中都需要指定一个数字类型的 id(全局不可重复),znode 的值包括此 broker 的 host、port 、安全配置等信息。
当 broker 宕机或其所在的 partition 失效,则 zookeeper 会释放该 partition 节点互斥锁,其他 broker 就这个 partition 重新进行选举 leader,并更新状态信息。
数据节点:/brokers/ids/[0…N] →host:port 其中 [0…N] 表示 broker id

img
2)Topic 注册数据:一个临时 znode,当一个 broker 启动时,会向 zookeeper 注册自己持有的 topic 和 partitions 信息。znode 值包括该 Topic 的分区信息、ISR 信息等。
数据节点:/brokers/topics/[topic]/[0…N] 其中[0…N]表示 partition 索引号
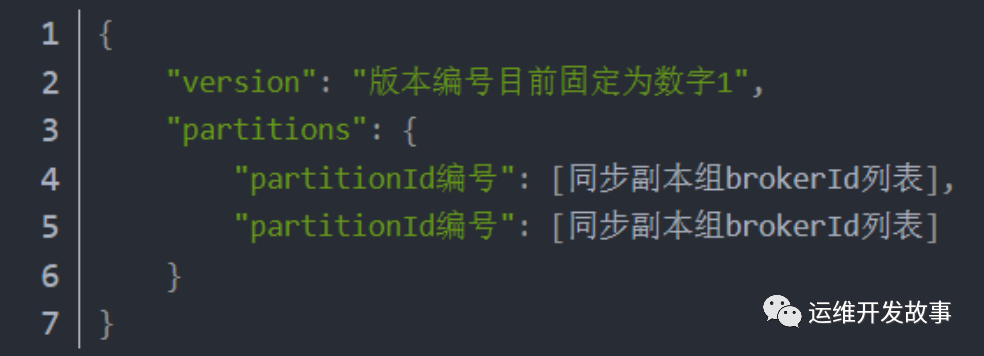
img
- Topic 分区状态信息节点:记录谁是 leader,有哪些服务器能用
数据节点:/brokers/topics/[topic]/partitions/[0…N]
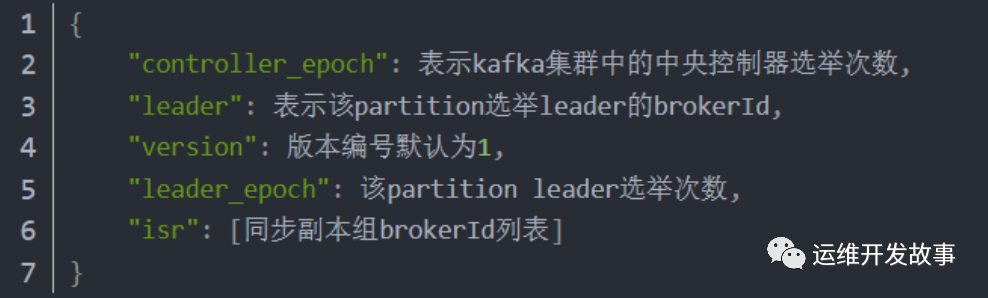
img
- 辅助选举信息节点,临时节点,记录当前 Controller 角色的 BrokerId,删除该节点立马触发重新选举
数据节点:/controller
数据样例:
[zk: localhost:2181(CONNECTED) 1] get /controller
{"version":1,"brokerid":1001,"timestamp":"1653989876415"}
cZxid = 0x100000029
ctime = Tue May 31 17:37:56 CST 2022
mZxid = 0x100000029
mtime = Tue May 31 17:37:56 CST 2022
pZxid = 0x100000029
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x3811979ba7c0001
dataLength = 57
numChildren = 0
- 选举管理节点:记录选举次数,kafka 集群中第一个 broker 第一次启动时为1,以后只要集群中 中央控制器所在 broker 变更或挂掉,就会重新选举新的 center controller,每次 center controller 变更 controller_epoch 值就会 + 1
数据节点:/controller_epoch
数据样例:
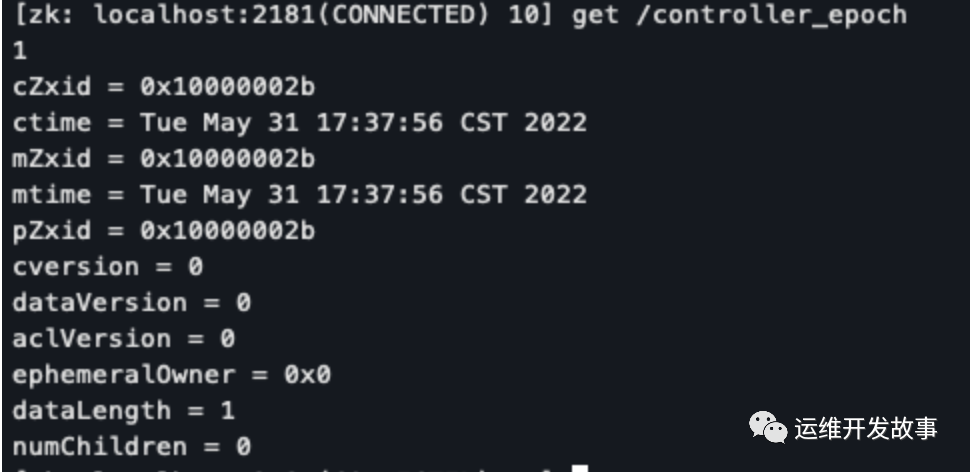
img
6)ISR 变更通知节点:当某个 Broker 上的 LogDir(即日志所在目录) 出现异常时(比如磁盘损坏,文件读写失败等),或者 其他导致 ISR 有变动(比如 topic 增加分区等); 向 zk 中新增一个子节点 **/log_dir_event_notification/**log_dir_event_序列号 ;Controller 监听到这个节点的变更之后,会向 Brokers 们发送 LeaderAndIsrRequest 请求;然后做一些副本脱机的善后操作:
- 损坏 LogDir 所在节点如果存在副本 Leader,则重新选举
- 损坏 LogDir 所在节点的副本重新分配到其他正常的 Broker 中
数据节点:/isr_change_notification
5.2 Kafka Topic 的数据结构
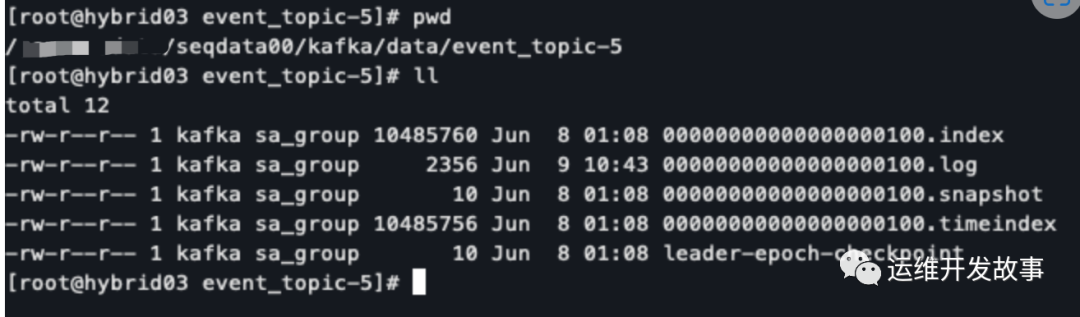
img
Kafka 消息是以 Topic 为单位,Topic 之间相互独立。以 Event_topic 为例,它由 10 个分区构成,分区数可以在创建 Topic 时指定,也可以在 Topic 创建后再修改,但只能增加一个 Topic 的分区数而不能减少其分区数。每个分区可以有一个或多个副本。
在存储结构上分区的每个副本对应一个 Log 对象,每个 Log 又会按照大小以及时间戳划分为多个 LogSegment,每个 LogSegment 包括一个日志文件和两个索引文件(如图中所示),其中两个索引文件分别为偏移量索引文件和时间戳索引文件。
我们的 Kafka 数据目录:**/sensorsdata/seqdata00/kafka/data**
数据目录下有以下 5 个文件:
- 00000000000000000100.log
- 00000000000000000100.index
- 00000000000000000100.timeindex
- 00000000000000000100.snapshot
- leader-epoch-checkpoint
注:index、log、timeindex 文件是二进制文本,可以使用 kafka 工具查看内容,checkpoint 文件可以直接打开。****这里我们重点讨论 kafka 的日志文件存储,以及 offset 索引。
5.2.1 日志文件 00000000000000000100.log
数据文件用来存储消息,每条消息由一个固定长度的消息头和一个可变长度的消息体数据组成,该文件大小可通过 log.segment.bytes 参数来设置。
前面讲到,Broker 写入数据是以 Batch 为单位的,因此 日志文件就是以 batch 为单位存储数据的。一个 batch 可包含一条或多条消息,batch 格式如下:
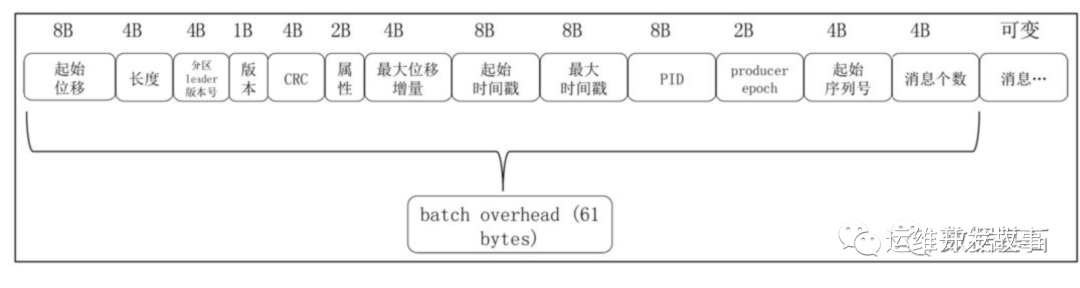
img
- 起始位移:占用 8 字节,其存储了当前 batch 中第一条消息的位移,即该 batch 的第一条消息,在整个文件中属于第几条;
- 位置「position」:当前 batch 第一条消息在文件中的二进制起始位置
- 长度:占用了 4 个字节,其存储了整个 batch 所占用的磁盘空间的大小,通过该字段,kafka 在进行消息遍历的时候,可以快速的跳跃到下一个 batch 进行数据读取;
- 分区 leader 版本号:记录了当前消息所在分区的 leader 的服务器版本,主要用于进行一些数据版本的校验和转换工作;
- CRC:对当前整个 batch 的数据的 CRC 校验码,主要是用于对数据进行差错校验的;
- 属性:占用 2 个字节,这个字段的最低 3 位记录了当前 batch 中消息的压缩方式,现在主要有 GZIP、LZ4 和 Snappy 三种。第 4 位记录了时间戳的类型,第 5 和 6 位记录了新版本引入的事务类型和控制类型;
- 最大位移增量:最新的消息的位移相对于第一条消息的唯一增量;
- 起始时间戳:占用 8 个字节,记录了 batch 中第一条消息的时间戳;
- 最大时间戳:占用 8 个字节,记录了 batch 中最新的一条消息的时间戳;
- PID、producer epoch 和起始序列号:这三个参数主要是为了实现事务和幂等性而使用的,其中 PID 和 producer epoch 用于确定当前 producer 是否合法,而起始序列号则主要用于进行消息的幂等校验;
- 消息个数:占用 4 个字节,记录当前 batch 中所有消息的个数;
- 官网更详细的说明:https://kafka.apache.org/21/documentation.html#recordbatch
- 数据样例:
[root@hybrid03 event_topic-5]# sh kafka/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000100.log
Dumping 00000000000000000100.log
Starting offset: 100
baseOffset: 100 lastOffset: 100 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false position: 0 CreateTime: 1654687438348 isvalid: true size: 711 magic: 2 compresscodec: GZIP crc: 502062677
baseOffset: 101 lastOffset: 102 count: 2 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false position: 711 CreateTime: 1654687446472 isvalid: true size: 866 magic: 2 compresscodec: GZIP crc: 2103664298
baseOffset: 103 lastOffset: 103 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false position: 1577 CreateTime: 1654742637828 isvalid: true size: 779 magic: 2 compresscodec: GZIP crc: 2848436952
baseOffset: 104 lastOffset: 104 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false position: 2356 CreateTime: 1654745849290 isvalid: true size: 710 magic: 2 compresscodec: GZIP crc: 103403051
baseOffset: 105 lastOffset: 111 count: 7 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false position: 3066 CreateTime: 1654745852374 isvalid: true size: 1060 magic: 2 compresscodec: GZIP crc: 4064619696
- 延伸阅读:每条消息 record 的内部结构:https://kafka.apache.org/21/documentation.html#record
5.2.2 索引文件:00000000000000000100.index
kafka 主要有两种类型的索引文件:位移索引文件和时间戳索引文件。
- 位移索引文件中存储的是消息的位移与该位移所对应的消息的物理地址;
- 时间戳索引文件中则存储的是消息的时间戳与该消息的位移值。
本文只讨论位置索引。为了提高查找效率,Kafka为每个数据文件创建了一个基于偏移量的索引文件,数据文件同名,后缀为.index。关于位移索引文件,这里有三点需要说明:
- 由于 kafka 消息都是以 batch 的形式进行存储,因而索引文件中索引元素的最小单元是 batch,也就是说,通过位移索引文件能够定位到消息所在的 batch,而没法定位到消息在 batch 中的具体位置,查找消息的时候,还需要进一步对 batch 进行遍历;
- Index 索引文件用来存储索引,索引是用来将偏移量映射成消息在数据文件中的物理位置,每个索引条目由 offset(第几条消息) 和 position(该消息所在的物理位置) 组成,每个索引条目唯一确定数据文件中的一条消息。索引条目的 offset 和 position 与数据文件中消息的 offset 和 position一一对应的,例如,数据文件中某条消息为 offset: 114 和position:4126,若为该条消息创建了索引,索引文件中索引值为 offset:114 和position:4126。
- 并不是每条消息都对应有索引,kafka 采用了稀疏存储的方式,每隔一定字节的数据建立一条索引,可以通过 index.interval.bytes 设置索引跨度。
[root@hybrid03 event_topic-5]# sh kafka/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000100.index
Dumping 00000000000000000100.index
offset: 114 position: 4126 「说明:第 114 条消息,要从文件的第 4126 号物理位置开始读」
offset: 140 position: 8254
offset: 178 position: 13332
offset: 232 position: 18278
offset: 286 position: 23340 「从这里可以看到,神策采用的 稀疏系数是 26」
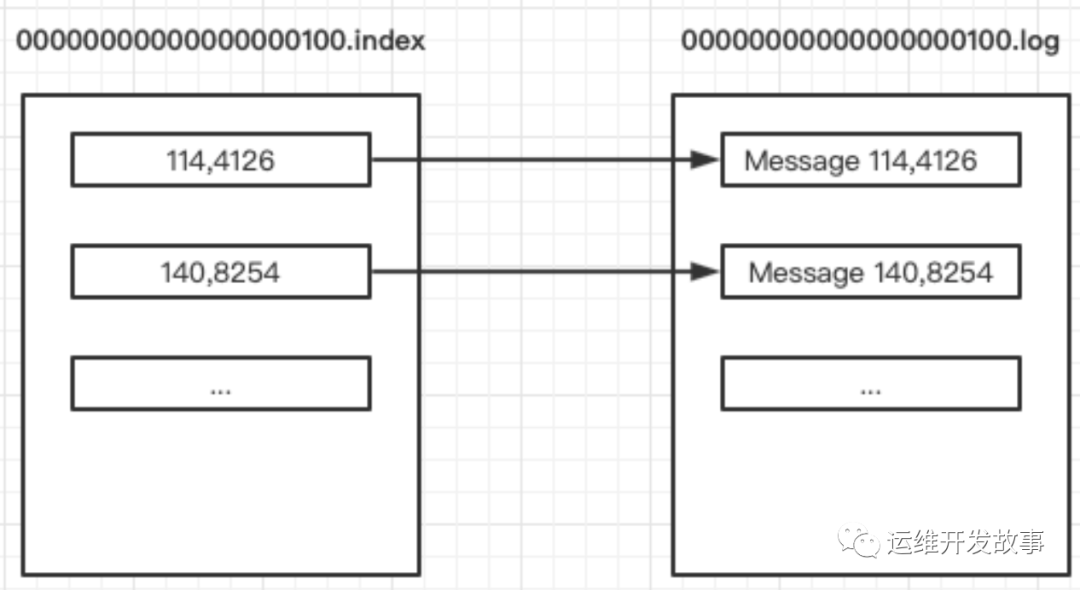
img
6 Kafka 运维
Kafka 的命令行工具路径:xxx/kafka/bin/下

img
6.1 Topic 管理指令
可以管理 Topic ,包括 创建、删除、分区扩容、查询 Topic 详细信息、查看 Topic 列表 等
命令工具:kafka-topics.sh
如果使用的kafka 版本是 2.11,kafka版本 >= 2.2 支持 --bootstrap-server 参数,其他版本只能用 --zookeeper
# 创建 Topic:
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test
# Topic 分区扩容
kafka-topics.sh --zookeeper localhost:2181 --alter --topic test --partitions 4
# 删除 Topic:
kafka-topics.sh --delete --zookeeper localhost:2181 localhost:9092 --topic test
#查询 Topic 详细信息
[DEV (v.v) sa_cluster@hybrid03 bin]$ ./kafka-topics.sh --topic event_topic --zookeeper localhost:2181 --describe
Topic:event_topic PartitionCount:10 ReplicationFactor:2 Configs:compression.type=gzip
Topic: event_topic Partition: 0 Leader: 1001 Replicas: 1001,1003 Isr: 1001,1003
Topic: event_topic Partition: 1 Leader: 1003 Replicas: 1003,1002 Isr: 1003,1002
Topic: event_topic Partition: 2 Leader: 1002 Replicas: 1002,1001 Isr: 1002,1001
Topic: event_topic Partition: 3 Leader: 1001 Replicas: 1001,1002 Isr: 1001,1002
Topic: event_topic Partition: 4 Leader: 1003 Replicas: 1003,1001 Isr: 1003,1001
Topic: event_topic Partition: 5 Leader: 1002 Replicas: 1002,1003 Isr: 1002,1003
Topic: event_topic Partition: 6 Leader: 1001 Replicas: 1001,1003 Isr: 1001,1003
Topic: event_topic Partition: 7 Leader: 1003 Replicas: 1003,1002 Isr: 1003,1002
Topic: event_topic Partition: 8 Leader: 1002 Replicas: 1002,1001 Isr: 1002,1001
Topic: event_topic Partition: 9 Leader: 1001 Replicas: 1001,1002 Isr: 1001,1002
#列出全部 Topic
kafka-topics.sh --bootstrap-server xxxxxx:9092 --list --exclude-internal
6.2 增删节点后的数据均衡
增加数据节点后,虽然新节点上已经启动了 broker ,但 kafka 不会自动均衡数据,需要手动执行。
命令工具:kafka-reassign-partitions.sh
- 编写配置文件move-json-file.json,告诉 kafka 你希望哪些 topic 要重新分区:
{
"topics": [{
"topic": "event_topic"
},
{
"topic": "profile_topic"
},
{
"topic": "item_topic"
}
],
"version": 1
}
- 执行命令生成分配信息:要注意的是,此时分区移动尚未开始,它只 是告诉你当前的分配和建议。保存当前分配,以防你想要回滚它。
# 下面 --broker-list 参数 对应的是 brokerid
[DEV (v.v) cluster@hybrid03 bin]$ ./kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file ~/mv.json --broker-list "1001,1002" --generate
Current partition replica assignment #当前分配信息
{"version":1,"partitions":[{"topic":"event_topic","partition":2,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":8,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":3,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":6,"replicas":[1001,1003],"log_dirs":["any","any"]},{"topic":"event_topic","partition":9,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"item_topic","partition":0,"replicas":[1001,1003],"log_dirs":["any","any"]},{"topic":"event_topic","partition":0,"replicas":[1001,1003],"log_dirs":["any","any"]},{"topic":"event_topic","partition":5,"replicas":[1002,1003],"log_dirs":["any","any"]},{"topic":"profile_topic","partition":2,"replicas":[1001,1003],"log_dirs":["any","any"]},{"topic":"profile_topic","partition":1,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":4,"replicas":[1003,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":1,"replicas":[1003,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":7,"replicas":[1003,1002],"log_dirs":["any","any"]},{"topic":"profile_topic","partition":0,"replicas":[1003,1002],"log_dirs":["any","any"]}]}
Proposed partition reassignment configuration #分配后的信息
{"version":1,"partitions":[{"topic":"event_topic","partition":7,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"profile_topic","partition":1,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":1,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"item_topic","partition":0,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":4,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":9,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":6,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":3,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":8,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"profile_topic","partition":0,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":0,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":5,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"profile_topic","partition":2,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":2,"replicas":[1001,1002],"log_dirs":["any","any"]}]}
- 将上面得到期望的重新分配方式文件保存在一个 json 文件里面:reassignment-json-file.json,然后通过参数–execute执行分配:
./kafka-reassign-partitions.sh --zookeeper LOCALHOST:2181 --reassignment-json-file reassignment-json-file.json --execute
该命令也可以用于以下使用场景:
- 给分区增加副本,你只需要在 第 2 步生成的内容里面, 在****replicas 参数中加入你想要增加的 副本所在 broker id 信息即可,这样执行的时候会自动在 对应 broker 上创建副本。
- 重新分配分区
6.3 消费情况指令
1.查看group的消费情况
# group: 指定group id名字
./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group test-group
# 示例:
# TOPIC: group对应的topic
# PARTITION:aprtition编号,从0开始0-5表示有6个partition
# CURRENT-OFFSET:此消费着当前已消费的offset
# LOG-END-OFFSET:生产者在此partition分区上已提交确认的offset
# LAG:两个offset的差值,就是常说的积压。此数值过大为异常。
# HOST:消费者所在的服务器ip
# CLIENT-ID:消费者的信息
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test-group
2.删除group
./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --delete --group test-group
3.重新设置消费者位移
Earliest策略:把位移调整到当前最早位移处
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-earliest –execute
Latest策略:把位移调整到当前最新位移处
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-latest --execute
Current策略:把位移调整到当前最新提交位移处
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-current --execute
Specified-Offset策略:把位移调整到指定位移处
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-offset <offset> --execute
Shift-By-N策略:把位移调整到当前位移+N处(N可以是负值)
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --topic test --reset-offsets --shift-by <offset_N> --execute
DateTime策略:(把位移调整到大于给定时间的最小位移处)
时间需要减8
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --topic test --reset-offsets --to-datetime 2019-06-20T20:00:00.000 --execute
Duration策略:把位移调整到距离当前时间指定间隔的位移处,然后将位移调整到距离当前给定时间间隔的位移处,具体格式是 PnDTnHnMnS。
以字母 P 开头,后面由 4 部分组成,即 D、H、M 和 S,分别表示天、小时、分钟和秒。
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --by-duration PT0H30M0S --execute
6.4 设置 Topic 过期时间
# 设置 topic 过期时间(单位 毫秒)
### 3600000 毫秒 = 1小时
./bin/kafka-configs.sh --zookeeper 127.0.0.1:2181 --alter --entity-name topic-devops-elk-log-hechuan-huanbao --entity-type topics --add-config retention.ms=3600000
# 查看 topic 配置
./bin/kafka-configs.sh --zookeeper 127.0.0.1:2181 --describe --entity-name topic-devops-elk-log-hechuan-huanbao --entity-type topics
6.5 工具相关
使用脚本生产/消费消息
# 连接到test-topic,然后通过输入+会车生产消息
$ bin/kafka-console-producer.sh --broker-list kafka-host:port --topic test-topic --producer-property
>
# --from-beginning: 指定从开始消费消息,否则会从最新的地方开始消费消息
$ bin/kafka-console-consumer.sh --bootstrap-server kafka-host:port --topic test-topic --group test-group --from-beginning --consumer-property
kafka性能测试
# 测试生产者
# 向指定主题发送了 1 千万条消息,每条消息大小是 1KB
# 它会打印出测试生产者的吞吐量 (MB/s)、消息发送延时以及各种分位数下的延时
$ bin/kafka-producer-perf-test.sh --topic test-topic --num-records 10000000 --throughput -1 --record-size 1024 --producer-props bootstrap.servers=kafka-host:port acks=-1 linger.ms=2000 compression.type=lz4
2175479 records sent, 435095.8 records/sec (424.90 MB/sec), 131.1 ms avg latency, 681.0 ms max latency.
4190124 records sent, 838024.8 records/sec (818.38 MB/sec), 4.4 ms avg latency, 73.0 ms max latency.
10000000 records sent, 737463.126844 records/sec (720.18 MB/sec), 31.81 ms avg latency, 681.00 ms max latency, 4 ms 50th, 126 ms 95th, 604 ms 99th, 672 ms 99.9th.
# 测试消费者性能
$ bin/kafka-consumer-perf-test.sh --broker-list kafka-host:port --messages 10000000 --topic test-topic
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2019-06-26 15:24:18:138, 2019-06-26 15:24:23:805, 9765.6202, 1723.2434, 10000000, 1764602.0822, 16, 5651, 1728.1225, 1769598.3012
7 Kafka 常用性能调优
7.1 磁盘目录优化
kafka 读写的单位是 partition,因此将一个 topic 拆分为多个 partition 可以提高吞吐量。但是这里有个前提,就是不同 partition 需要位于不同的磁盘(可以在同一个机器)。如果多个 partition 位于同一个磁盘,那么意味着有多个进程同时对一个磁盘的多个文件进行读写,使得操作系统会对磁盘读写进行频繁调度,也就是破坏了磁盘读写的连续性。
优化参数:l****og.dirs=/data/seqdata00/kafka/data, /data/seqdata01/kafka/data, /data/seqdata02/kafka/data
7.2 JVM参数配置
推荐使用最新的 G1 来代替 CMS 作为垃圾回收器。 推荐 Java 使用的最低版本为 JDK 1.7u51。
G1相比较于CMS的优势:
- G1 是一种适用于服务器端的垃圾回收器,很好的平衡了吞吐量和响应能力
- 对于内存的划分方法不同,Eden, Survivor, Old 区域不再固定,使用内存会更高效。G1 通过对内存进行 Region 的划分,有效避免了内存碎片问题。
- G1 可以指定GC时可用于暂停线程的时间(不保证严格遵守)。而 CMS 并不提供可控选项。
- CMS 只有在 FullGC 之后会重新合并压缩内存,而G1把回收和合并集合在一起。
- CMS 只能使用在 Old 区,在清理 Young 时一般是配合使用 ParNew,而 G1 可以统一两类分区的回收算法。
G1的适用场景:
- JVM占用内存较大(At least 4G)
- 应用本身频繁申请、释放内存,进而产生大量内存碎片时。
- 对于GC时间较为敏感的应用。
目前我们使用的 JVM 参数:

img
7.3 日志数据刷盘策略
为了大幅度提高 producer 写入吞吐量,需要定期批量写文件。
有 2 个参数可配置:
- log.flush.interval.messages = 100000 :每当 producer 写入 100000 条数据时,就把数据刷到磁盘
- log.flush.interval.ms=1000:每隔 1 秒,就刷一次盘
7.4 日志保留时间
当 kafka server 的被写入海量消息后,会生成很多数据文件,且占用大量磁盘空间,如果不及时清理,可能导致磁盘空间不够用,kafka 默认是保留7天。
参数: log.retention.hours = 168
公众号:运维开发故事
博客****:https://www.devopstory.cn
爱生活,爱运维
我是冬子先生,《运维开发故事》公众号团队中的一员,一线运维农民工,云原生实践者,这里不仅有硬核的技术干货,还有我们对技术的思考和感悟,欢迎关注我们的公众号,期待和你一起成长!

版权归原作者 运维开发故事 所有, 如有侵权,请联系我们删除。