
文章目录
1. 如何何请求解析url
- 要解析 Python 中 Request 返回的 HTML DOM,你可以使用解析库,如 BeautifulSoup 或 lxml,来处理 HTML 文档。下面是使用 Beautiful Soup 和 lxml 的示例代码:
- 首先,确保你已经安装了所需的库。对于 Beautiful Soup,你可以使用 pip install beautifulsoup4 进行安装。对于 lxml,你可以使用 pip install lxml 进行安装。
- 使用 Beautiful Soup 库:
- BeautifulSoup 是一个 Python 库,用于网络爬虫目的。它提供了一种方便和高效的方式来从 HTML 和 XML 文档中提取数据。使用 BeautifulSoup,你可以解析和遍历 HTML 结构,搜索特定元素,并从网页中提取相关数据。
- 该库支持不同的解析器,如内置的 Python 解析器、lxml 和 html5lib,允许你根据特定需求选择最适合的解析器。BeautifulSoup 的优势在于它能够处理格式混乱或损坏的 HTML 代码,使其成为处理复杂情况下的网络爬虫任务的强大工具。
import requests
from bs4 import BeautifulSoup
# 发送请求获取 HTML
response = requests.get(url)
html = response.text
# 创建 Beautiful Soup 对象
soup = BeautifulSoup(html,'html.parser')# 通过选择器选择 DOM 元素进行操作
element = soup.select('#my-element')
- 在上面的示例中,requests.get(url) 发送请求并获取HTML响应。然后,我们使用 response.text 获取响应的HTML内容,并将其传递给 Beautiful Soup 构造函数 **BeautifulSoup(html, ‘html.parser’)**,创建一个 Beautiful Soup 对象 soup。
- 接下来,你可以使用 Beautiful Soup 提供的方法和选择器,如 **select()**,来选择 HTML DOM 中的特定元素。在上述示例中,我们通过选择器 #my-element 选择具有 id 为 my-element 的元素。
- 使用 lxml 库:
import requests
from lxml import etree
# 发送请求获取 HTML
response = requests.get(url)
html = response.text
# 创建 lxml HTML 解析器对象
parser = etree.HTMLParser()# 解析 HTML
tree = etree.fromstring(html, parser)# 通过XPath选择 DOM 元素进行操作
elements = tree.xpath('//div[@class="my-element"]')
- 在上面的示例中,我们首先使用 requests.get(url) 发送请求并获取HTML响应。然后,我们创建一个 lxml HTML 解析器对象 parser。
- 接下来,我们使用 etree.fromstring(html, parser) 解析 HTML,并得到一个表示 DOM 树的对象 tree。
- 最后,我们可以使用 XPath 表达式来选择 DOM 元素。在上述示例中,我们使用 XPath 表达式 //div[@class=“my-element”] 选择所有 class 属性为 “my-element” 的 div 元素。
- 无论是使用 Beautiful Soup 还是 lxml,都可以使用各自库提供的方法和属性来操作和提取选择的 DOM 元素。
2. 如何获取标签里面的文本
在Python中,你可以使用多种库和方法来获取HTML标签里面的文本。以下是几种常见的方法:
- 方式一:使用BeautifulSoup库:
from bs4 import BeautifulSoup
# 假设html为包含标签的HTML文档
soup = BeautifulSoup(html,'html.parser')# 获取所有标签内的文本
text = soup.get_text()# 获取特定标签内的文本(例如p标签)
p_text = soup.find('p').get_text()
- 方式二:使用lxml库:
from lxml import etree
# 假设html为包含标签的HTML文档
tree = etree.HTML(html)# 获取所有标签内的文本
text = tree.xpath('//text()')# 获取特定标签内的文本(例如p标签)
p_text = tree.xpath('//p/text()')
- 方式三:使用正则表达式:
import re
# 假设html为包含标签的HTML文档
pattern = re.compile('<[^>]*>')
text = re.sub(pattern,'', html)
这些方法可以根据你的需求选择其中之一,它们都可以帮助你提取出HTML标签里面的文本内容。请注意,这些方法在处理复杂的HTML文档时可能会有一些限制,因此建议使用专门的HTML解析库(如BeautifulSoup、lxml)来处理HTML文档以获得更好的灵活性和准确性。
3. 如何解析JSON格式
- 要获取 JSON 数据中的 title 属性的值,你可以使用 Python 的 json 模块来解析 JSON 数据。在你的示例数据中,title 属性位于 data 字典中的 pageArticleList 列表中的每个元素中。
- 下面是一个示例代码,演示如何获取 title 属性的值:
import json
# 假设你已经获取到了 JSON 数据,将其存储在 json_data 变量中
json_data ='''
{
"status": 200,
"message": "success",
"datatype": "json",
"data": {
"pageArticleList": [
{
"indexnum": 0,
"periodid": 20200651,
"ordinate": "",
"pageid": 2020035375,
"pagenum": "6 科协动态",
"title": "聚焦“科技创新+先进制造” 构建社会化大科普工作格局"
}
]
}
}
'''# 解析 JSON 数据
data = json.loads(json_data)# 提取 title 属性的值
title = data["data"]["pageArticleList"][0]["title"]# 输出 title 属性的值print(title)
- 在上述示例中,我们将示例数据存储在 json_data 字符串中。然后,我们使用 json.loads() 函数将字符串解析为 JSON 数据,将其存储在 data 变量中。
- 然后,我们可以通过字典键的层级访问方式提取 title 属性的值。在这个示例中,我们使用 data[“data”][“pageArticleList”][0][“title”] 来获取 title 属性的值。
- 最后,我们将结果打印出来或根据需求进行其他处理。
- 或者是用get()获取具体属性的值
list= json.loads(res.text)for i inlist:print(i.get('edition'))

4. 如何添加常用的header
- 如果想在实际的代码中设置HTTP请求头,可以通过使用相应编程语言和HTTP库的功能来完成。下面是一个示例,显示如何使用Python的requests库添加常用的请求头:
import requests
url ="https://example.com"
headers ={"User-Agent":"Mozilla/5.0","Accept-Language":"en-US,en;q=0.9","Referer":"https://example.com",# 添加其他常用请求头...}
response = requests.get(url,stream=True, headers=headers)
- 在上述示例中,我们创建了一个headers字典,并将常用的请求头键值对添加到字典中。然后,在发送请求时,通过传递headers参数将这些请求头添加到GET请求中。 请注意,实际使用时,可以根据需要自定义请求头部。常用的请求头包括 “User-Agent”(用户代理,用于识别客户端浏览器/设备)、“Accept-Language”(接受的语言)、“Referer”(来源页面)等。
5. 如何合并两个div
try:
html =""<html><body></body></html>""
soup = BeautifulSoup(html,'html.parser')# 创建新的div标签
new_div = soup.new_tag('div')
temp_part1 = html_dom.find('div','detail-title')
new_div.append(temp_part1)
temp_part2 = html_dom.find("div","detail-article")
new_div.append(temp_part2)
card ={"content":"","htmlContent":""}
html_dom=new_div
except:return
6. 如何删除html dom的部分结构
- 要在 Python 中删除已获取的 DOM 结构的一部分,你可以使用 Beautiful Soup 库来解析和操作 HTML。下面是一个示例代码,演示如何删除 DOM 结构的一部分:
from bs4 import BeautifulSoup
# 假设你已经获取到了 DOM 结构,将其存储在 dom 变量中
dom ='''
<div class="container">
<h1>Hello, World!</h1>
<p>This is a paragraph.</p>
</div>
'''# 创建 Beautiful Soup 对象
soup = BeautifulSoup(dom,'html.parser')# 找到要删除的部分
div_element = soup.find('div', class_='container')
div_element.extract()# 输出修改后的 DOM 结构print(soup.prettify())
- 在上述示例中,我们首先将 DOM 结构存储在 dom 变量中。然后,我们使用 Beautiful Soup 创建了一个解析对象 soup。 接下来,我们使用 find() 方法找到了要删除的部分,这里是 ****。然后,我们使用 extract() 方法将该元素从 DOM 结构中删除。
- 最后,我们使用 prettify() 方法将修改后的 DOM 结构输出,以便查看结果。
在实际应用中,需要根据要删除的部分的选择器和属性进行适当的调整。7. 如何一次性获取所有div标签里的文本
- 要一次性获取所有标签里的文本,你可以使用BeautifulSoup库或lxml库进行解析。以下是使用这两个库的示例代码:
- 方式一:使用BeautifulSoup库:
from bs4 import BeautifulSoup # 假设html为包含标签的HTML文档 soup = BeautifulSoup(html,'html.parser')# 查找所有div标签并获取其文本内容 div_texts =[div.get_text()for div in soup.find_all('div')]- 方式二:使用lxml库:
from lxml import etree # 假设html为包含标签的HTML文档 tree = etree.HTML(html)# 使用XPath查找所有div标签并获取其文本内容 div_texts = tree.xpath('//div//text()')- 使用这些代码,你可以一次性获取所有的标签里的文本内容。请注意,这些方法返回的结果是一个列表,列表中的每个元素对应一个标签的文本内容。你可以根据需要进一步处理这些文本内容。
8. python爬虫如何改变响应文本字符集编码
- 在Python爬虫中,你可以通过以下几种方法来改变响应文本的字符集编码:
- 方式一:使用response.encoding属性:当使用requests库发送请求并获取到响应对象后,可以通过response.encoding属性来指定响应文本的字符集编码。根据响应中的内容,可以尝试不同的编码进行设置,例如UTF-8、GBK等。示例代码如下:
import requests response = requests.get('https://example.com') response.encoding ='UTF-8'# 设置响应文本的字符集编码为UTF-8print(response.text)apparent_encoding用于获取响应内容的推测字符集编码,是一个只读属性,它只返回推测的字符集编码,并不能用于设置或更改字符集编码。如果需要更改字符集编码,请使用response.encoding属性进行设置- 方式二:使用chardet库自动检测字符集编码:如果你不确定响应的字符集编码是什么,可以使用chardet库来自动检测响应文本的字符集编码。该库可以分析文本中的字符分布情况,并猜测出可能的字符集编码。示例代码如下:
import requests import chardet response = requests.get('https://example.com') encoding = chardet.detect(response.content)['encoding']# 检测响应文本的字符集编码 response.encoding = encoding # 设置响应文本的字符集编码print(response.text)- 方式三:使用Unicode编码:如果你无法确定响应文本的正确字符集编码,你可以将文本内容转换为Unicode编码,这样就不需要指定字符集编码了。示例代码如下:
import requests response = requests.get('https://example.com') text = response.content.decode('unicode-escape')print(text)- 以上是三种常见的方法来改变响应文本的字符集编码。根据具体情况选择最适合的方法来处理爬取的网页内容。记住,在处理字符集编码时,要注意处理异常情况,例如编码错误或无法识别字符集等。
9. 如何进行字符集转码
- 字符集转码是指将文本从一种字符集编码转换为另一种字符集编码的过程。在Python中,可以使用**encode()和decode()**方法进行字符集转码操作。
- 方式一: encode(encoding) 将文本从当前字符集编码转换为指定的编码。其中,encoding参数是目标编码格式的字符串表示。示例代码如下:
text ="你好" encoded_text = text.encode('utf-8')# 将文本从当前编码转换为UTF-8编码print(encoded_text)- 方式二:decode(encoding) 将文本从指定的编码格式解码为当前字符集编码。其中,encoding参数是原始编码格式的字符串表示。示例代码如下:
encoded_text =b'\xe4\xbd\xa0\xe5\xa5\xbd'# UTF-8 编码的字节串 decoded_text = encoded_text.decode('utf-8')# 将字节串从UTF-8解码为Unicode文本print(decoded_text)- 在进行字符集转码时,需要确保原始文本和目标编码相匹配。如果不确定原始字符集,可以先使用字符集检测工具(如chardet)来确定原始编码,然后再进行转码操作。
- 使用正确的字符集编码进行转码操作可以确保文本在不同环境中的正确显示和处理。
11. response.text 和 respone.content的区别
在许多编程语言的HTTP请求库中,比如Python的requests库,有两个常用的属性用于获取HTTP响应的内容:response.text和response.content。区别如下:
- response.text:
- response.text返回的是一个字符串,表示HTTP响应的内容。
- 这个字符串是根据HTTP响应的字符编码来解码的,默认使用UTF-8编码。
- 如果响应中包含了其他编码的内容,那么可以通过指定response.encoding属性来手动指定相应的编码方式进行解码。
- response.content:
- response.content返回的是一个字节流,表示HTTP响应的内容。
- 这个字节流是原始的二进制数据,没有进行任何编码解码操作。
- response.content适用于处理二进制文件,比如图片、音视频文件等。
简而言之,response.text适用于处理文本内容,会自动进行编码解码操作,而response.content适用于处理二进制内容,返回的是原始字节流。
使用哪个属性取决于你处理的内容类型和需求。如果你处理的是文本内容,比如HTML、JSON数据等,那么通常使用response.text。如果你处理的是二进制文件,比如图像或音视频文件,那么使用response.content更合适。
12. 如何发送post请求访问页面
解析一个请求主要关注以下几个方面
- 请求路径
- 请求参数(post请求是隐含参数,浏览器发送的是post请求)
- 请求头
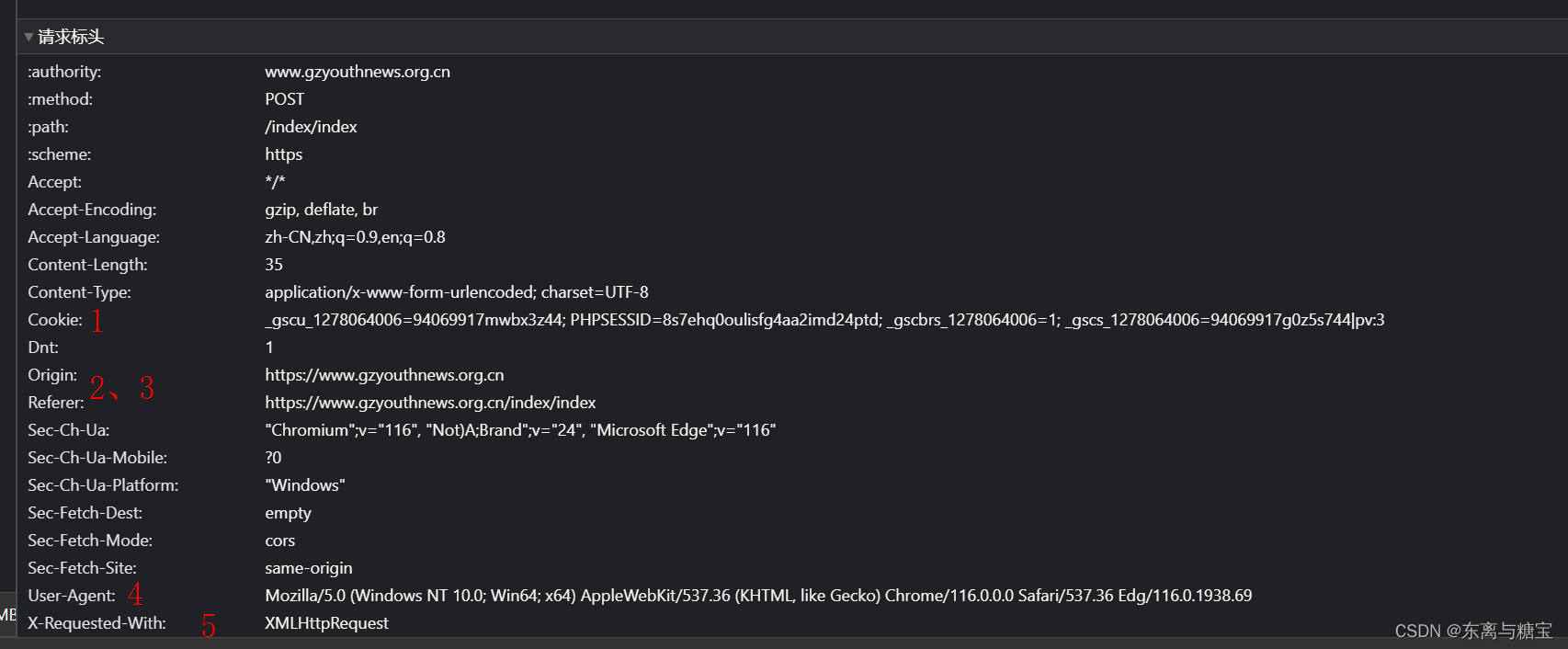
- 请求类型
以下是一个示例代码
import json import requests defmain(): url ='https://www.gzyouthnews.org.cn/index/index' header ={'X-Requested-With':'XMLHttpRequest'} data={'act':'list','date':'2023-08-10','paper_id':1} res = requests.post(url=url,headers=header,data=data)list= json.loads(res.text)for i inlist:print(i.get('edition'))if __name__ =='__main__': main()13. 如何获取 url 中的参数
要从给定的 URL 中获取参数 page=100,你可以使用 URL 解析库来解析 URL,并提取出所需的参数。
以下是使用 Python 的 urllib.parse 模块解析 URL 参数的示例代码:from urllib.parse import urlparse, parse_qs url ="https://blog.csdn.net/phoenix/web/v1/comment/list/131760390?page=100&size=10&fold=unfold&commentId=" parsed_url = urlparse(url) query_params = parse_qs(parsed_url.query) page_value = query_params.get("page",[None])[0]print(page_value)在上述示例中,我们首先使用 urlparse 函数解析 URL,然后使用 parse_qs 函数解析查询参数部分。parse_qs 函数将查询参数解析为字典,其中键是参数名称,值是参数值的列表。
然后,我们使用 query_params.get(“page”, [None])[0] 从字典中获取名为 page 的参数值。这将返回参数的值,如果该参数不存在,则返回 None。
输出结果将是 100,这是从 URL https://blog.csdn.net/phoenix/web/v1/comment/list/131760390?page=100&size=10&fold=unfold&commentId= 中提取的 page 参数的值。
请注意,如果 URL 的参数值是字符串形式,你可能需要根据需要进行进一步的类型转换。
本文转载自: https://blog.csdn.net/HHX_01/article/details/132554920
版权归原作者 东离与糖宝 所有, 如有侵权,请联系我们删除。
发表评论
“python萌新爬虫学习笔记【建议收藏】”的评论:
还没有评论 - 最后,我们使用 prettify() 方法将修改后的 DOM 结构输出,以便查看结果。