
Python数据结构与算法(2.7)——跳表
0. 学习目标
在诸如单链表、双线链表等普通链表中,查找、插入和删除操作由于必须从头结点遍历链表才能找到相关链表,因此时间复杂度均为
O
(
n
)
O(n)
O(n)。跳表是带有附加指针的链表,使用这些附加指针可以跳过一些中间结点,用以快速完成查找、插入和删除等操作。本节将介绍跳表的相关概念及其具体实现。
通过本节学习,应掌握以下内容:
- 跳表的基本概念及其与普通链表的区别
- 跳表及其操作的实现
1. 跳表的基本概念
跳表 (Skip List) 是一种可以快速进行查找、插入和删除等操作的有序链表(链表中的数据项按照某种顺序进行排列的链表称为有序链表)。跳表的核心思想是以更大的跨度遍历链表,以便可以跳过中间结点。
1.1 跳表介绍
首先,让我们回想一下如何在以下单链表中查找数据元素,即使链表中的数据已经排好序,我们也需要从头结点开始遍历链表。

例如要在以上单链表中查找 15,查找过程为:
0-->3-->5 -->7-->10-->15
。
为了提高查找的效率,我们可以抽取链表中的一部分结点建立一个起“索引”作用的链,称为“索引层”或简称“索引”:

此时我们查找 15,首先在索引层中遍历,当我们扫描到值为 10 的结点时,由于下一结点值为 27,因此我们知道 15 应当在这两个结点之间,然后回到原链表中遍历即可找到值为 15 的结点,遍历过程如下图绿色箭头所示:

可以看到通过建立索引链,需要遍历的结点数得以减少,为了进一步减少所需遍历的结点数,可以通过对索引链添加索引,跳表是对链表叠加多级索引的数据结构。

1.2 跳表的性能
在由
n
n
n 个元素组成的简单链表中,要执行查找操作,在最坏的情况下需要进行
n
n
n 次比较。如果添加一级索引,由于每次可以跳过一个结点,则比较次数在最坏的情况下会下降到
⌈
n
2
⌉
+
1
\lceil \frac n 2 \rceil+ 1
⌈2n⌉+1;如果再添加一级索引,则最坏情况下比较次数可以减少至
⌈
n
4
⌉
+
2
\lceil \frac n 4 \rceil+ 2
⌈4n⌉+2;继续此策略,假设一共有
m
m
m 级索引,则最坏情况下比较的次数为
⌈
n
2
m
⌉
+
m
\lceil \frac n {2^m} \rceil+ m
⌈2mn⌉+m。
设
m
m
m 层结点数为 2,则
n
2
m
=
2
\frac n {2^m}=2
2mn=2,可知跳表共
l
o
g
n
logn
logn 层,我们在遍历跳表时,由于每层需要比较的结点数为常数个,因此时间复杂度为
O
(
l
o
g
n
)
O(logn)
O(logn),并且在跳表中指针的数量仅增加了一倍
(
n
+
n
2
+
n
4
+
n
8
+
n
16
+
.
.
.
.
=
2
n
)
(n + \frac n2 + \frac n4 + \frac n8 + \frac n {16} + .... = 2n)
(n+2n+4n+8n+16n+....=2n)。
1.3 跳表与普通链表的异同
我们可以将跳表理解为排序后的链表,但与普通链表相比,有以下不同点:
- 普通链表中的结点只有一个
next指针,跳表中的结点有多个next指针; - 给定结点的
next指针的数量是随机确定的。
跳表中结点的每个
next
指针称为一层,结点中的层数称为结点的大小,其决定了结点在链表中的层级;在普通的有序链表中,插入、删除和查找操作需要对链表依次遍历,因此每个操作的时间复杂度均为
O
(
n
)
O(n)
O(n),跳表允许在遍历时跳过一些中间节点,每个操作的时间复杂度为
O
(
l
o
g
n
)
O(logn)
O(logn)。
2. 跳表的实现
跳表中的每个数据元素由一个结点表示,结点的层级在结点插入时随机选择,而不考虑数据结构中数据元素的数量。第
i
i
i 级结点有
i
i
i 个
next
指针(在结点实现时使用大小为
i
i
i 的数组
next
存储
i
i
i 个
next
指针),因此我们不需要在结点中存储结点的层级,使用最大层数
max_level
来限制层级上限。跳表的头结点具有从 1 级到
max_level
级的
next
指针。
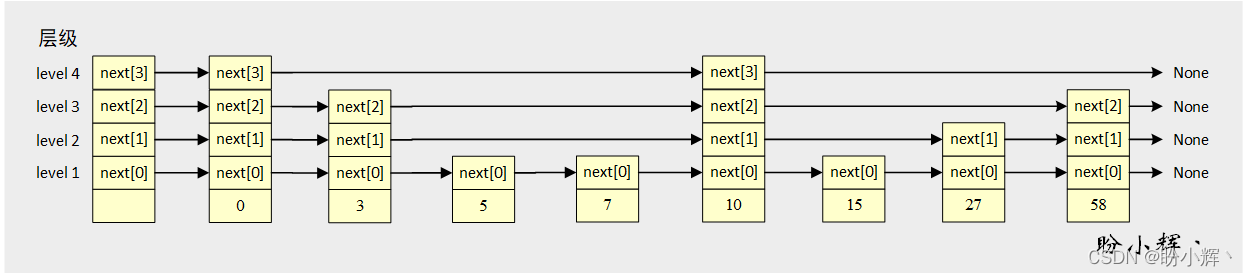
2.1 跳表结点类
跳表的结点示意图如下所示,每个结点都有一组用于指向其它层级结点的指针域列表
next
:

classNode:def__init__(self, data, level=0):
self.data = data
self.next=[None]* level
def__str__(self):return"Node({}, {})".format(self.data,len(self.next))
next
数组用于保存指向不同层级结点的指针,其中每个元素就是一个
next
指针,而
data
变量用于存储数据,重载
__str__
方法用于便于打印结点对象,
len(self.next)
可以用于表示结点中的层数。
2.2 跳表的初始化
跳表的初始化是建立一个空的带头结点的跳表,其表长
length
初始化为 0,此时链表中没有元素结点,只有一个头结点:
classSkipList:def__init__(self, max_level=8):
self.max_level = max_level
node = Node(Node, max_level)
self.head = node
self.length =0
创建跳表
SkipList
对象的时间复杂度为
O
(
1
)
O(1)
O(1)。
2.3 获取跳表长度
求取跳表长度只需要重载
__len__
从对象返回
length
的值,因此时间复杂度为
O
(
1
)
O(1)
O(1):
def__len__(self):return self.length
2.4 读取指定位置元素
由于跳表中的每个结点的层级是在结点插入时随机选择的,因此读取指定位置的数据元素和单链表类似,需要顺序遍历第 0 层结点,操作的复杂度为
O
(
n
)
O(n)
O(n),如果索引不在可接受的索引范围内,将引发
IndexError
异常::
def__getitem__(self, index):if index > self.length -1or index <0:raise IndexError("UnrolledLinkedList assignment index out of range")else:
count =0
node = self.head.next[0]while count < index:
node = node.next[0]
count +=1return node.data
2.5 查找指定元素
跳表的查找操作从最上层开始,如果待查元素
value
小于当前层的后继结点的
data
,则平移至当前层的后继结点;否则下移进入下一层,继续比较,直至第一层。

deflocate(self, value):
node = self.head
# 由于索引从0开始,因此第i层级的索引为i-1
level = self.max_level -1while level >=0:while node.next[level]!=Noneand node.next[level].data < value:# 平移到当前层的后继结点
node = node.next[level]# 下移进入下一层
level -=1if node.next[0].data == value:return node.next[0]else:raise ValueError("{} is not in skip list".format(value))
2.6 在跳表中插入新元素
与普通链表不同,在跳表中插入新元素不能指定位置(需要保证有序性),需要通过查找确定新数据元素的插入位置。
插入元素前,首先需要确定该元素所占据的层数
level k
,这是通过算法随机生成的,这样可以减少算法实现的复杂度,同时也可以保证跳表性能。
defrandom_level(self, max_level):
num = random.randint(1,2**max_level -1)
lognum = math.log(num,2)
level =int(math.floor(lognum))return max_level - level
然后需要在
level 1, level 2, ..., level k
各层的链表都插入新元素,为了达到此目的,我们需要在查找插入位置时维护一个列表
update
,
update
中的每个元素
update[i]
指向
level i
中小于插入元素
data
的最右边结点,即插入位置的左侧,如下图所示,插入元素
data = 9
,随机层数
k=3
:
def update_list(self, data):
update = [None] * self.max_level
node = self.head
level = self.max_level - 1
while level >= 0:
while node.next[level] != None and node.next[level].data < data:
node = node.next[level]
update[level] = node
level -= 1
return update
可以看到维护
update
列表的过程与查找元素类似,根据
update
列表可以判断跳表中是否已存在元素
data
,如果不存在将其插入跳表中:
definsert_node(self, data):# 产生随机 level,并构造结点
level = self.random_level(self.max_level)
node = Node(data, level)# 获取 update 列表
update = self.update_list(data)# 插入结点iflen(update)==0or update[0].next[0]==Noneor update[0].next[0].data != data:
self.length +=1for i inrange(level):
node.next[i]= update[i].next[i]
update[i].next[i]= node
2.7 删除跳表中指定元素
删除指定元素与插入操作类似: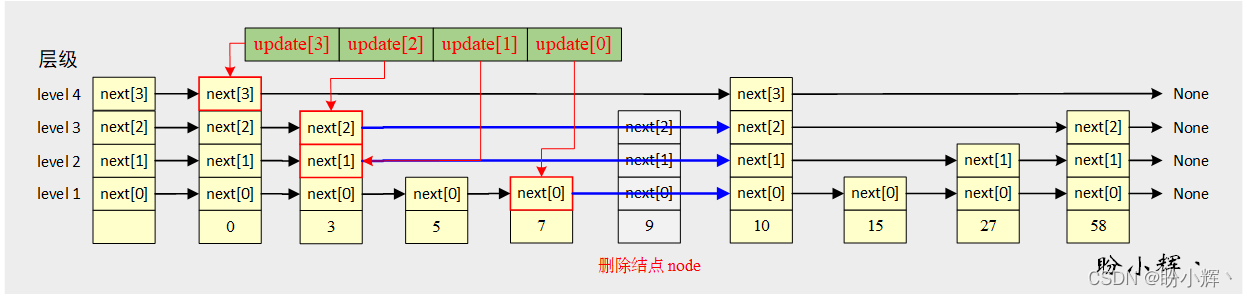
defdelete_node(self, data):# 获取 update 列表
update = self.update_list(data)iflen(update)>0:
node = update[0].next[0]# 删除指定元素结点if node !=Noneand node.data == data:
self.length -=1for i inrange(len(node.next)):
update[i].next[i]= node.next[i]del node
2.8 其它一些有用的操作
2.7.1 跳表指定层元素输出
将跳表指定层转换为字符串以便进行打印,编写
print_level
方法打印指定层中数据元素:
defget_level(self, level):"""辅助函数,用于根据给定层构造结果字符串"""
node = self.head.next[level]
result =''while node:
result = result +str(node.data)+'-->'
node = node.next[level]
result +='None'return result
defprint_level(self, level):print('level {}'.format(level))
result = self.get_level(level)print(result)
2.7.2 跳表各层元素输出
可以借助上述辅助函数
get_level
,使用
str
函数调用对象上的
__str__
方法可以创建适合打印的字符串表示:
def__str__(self):
result =''for i inlist(range(self.max_level))[self.max_level-1:0:-1]:
result = result + self.get_level(i)+'\n'
result += self.get_level(0)return result
3. 跳表应用
接下来,我们将测试上述实现的链表,以验证操作的有效性。
3.1 跳表应用示例
首先初始化一个跳表
sl
,并在其中插入若干元素:
sl = SkipList(4)for i inrange(0,30,3):
sl.insert_node(i)
我们可以直接打印跳表中的数据元素、链表长度等信息:
print('跳表 sl 各层元素为:')print(sl)print('跳表 sl 长度为:',len(sl))print('跳表 sl 第 2 个元素为:', sl[2])
以上代码输出如下:
跳表 sl 各层元素为:
9-->None
0-->9-->18-->None
0-->9-->18-->27-->None
0-->3-->6-->9-->12-->15-->18-->21-->24-->27-->None
跳表 sl 长度为: 10
跳表 sl 第 2 个元素为: 6
接下来,我们将演示在添加/删除元素、以及如何查找指定元素等:
# 插入元素
sl.insert_node(14)print('在跳表 sl 中插入数据 14 后:')print(sl)# 删除元素
sl.delete_node(14)print('删除跳表 sl 中数据 14 后:')print(sl)# 查找数据元素 15print('查找跳表 sl 中数据元素 15:', sl.locate(15))
以上代码输出如下:
在跳表 sl 中插入数据 14 后:
9-->None0-->9-->18-->None0-->9-->14-->18-->27-->None0-->3-->6-->9-->12-->14-->15-->18-->21-->24-->27-->None
删除跳表 sl 中数据 14 后:
9-->None0-->9-->18-->None0-->9-->18-->27-->None0-->3-->6-->9-->12-->15-->18-->21-->24-->27-->None
查找跳表 sl 中数据元素 15: Node(15,1)
相关链接
线性表基本概念
顺序表及其操作实现
单链表及其操作实现
版权归原作者 盼小辉丶 所有, 如有侵权,请联系我们删除。