
一、Spark介绍
1、什么是Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行计算框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark是Scala编写,方便快速编程。
2、总体技术栈讲解
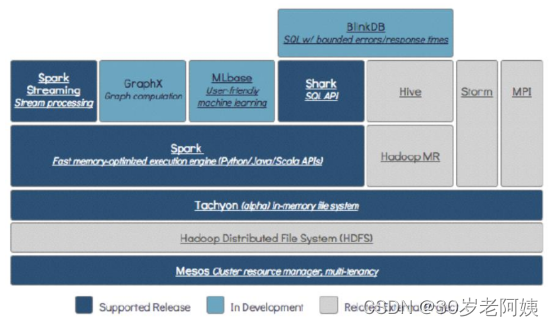
3、Spark与MapReduce的区别
都是分布式计算框架,Spark基于内存,MR基于HDFS。Spark处理数据的能力一般是MR的十倍以上,Spark中除了基于内存计算外,还有DAG有向无环图来切分任务的执行先后顺序。
4、Spark运行模式
- Local
多用于本地测试,如在eclipse,idea中写程序测试等。
- Standalone
Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
- Yarn
Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
- Mesos
资源调度框架。要基于Yarn来进行资源调度,必须实现AppalicationMaster接口,Spark实现了这个接口,所以可以基于Yarn。
二、Spark基于Maven开发
1、IDEA创建Maven项目
1)创建项目

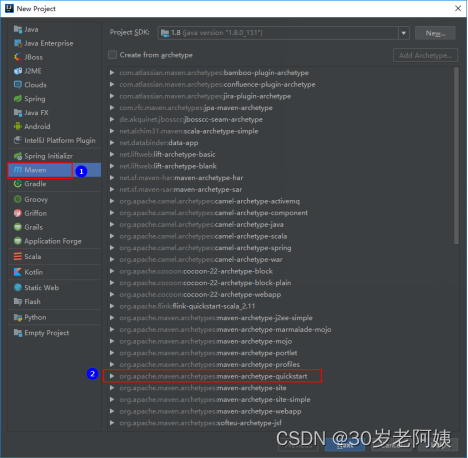
2)创建选择maven-archetype-quickstart
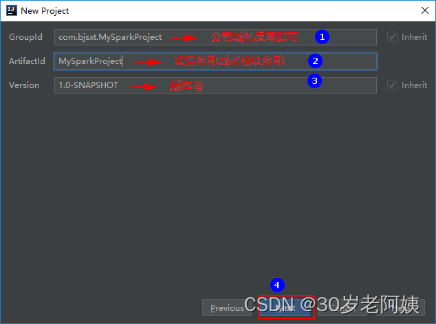
3)配置名称,点击下一步配置Maven及本地Maven仓库地址
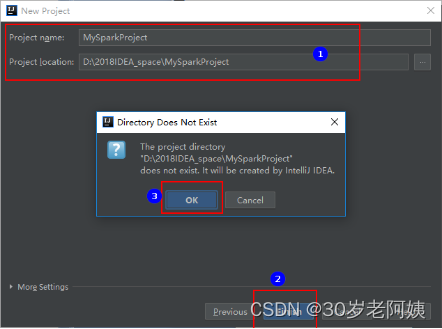
4)配置名称和位置,并创建
5)更新替换Maven pom.xml文件,注意groupId,artifactId,version不要更新替换。
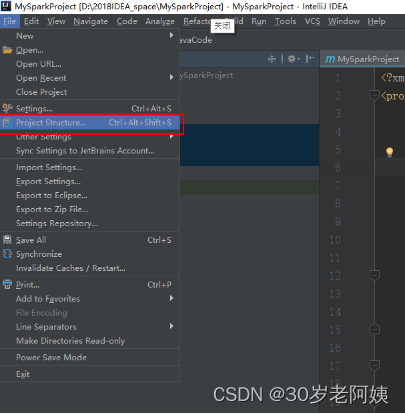
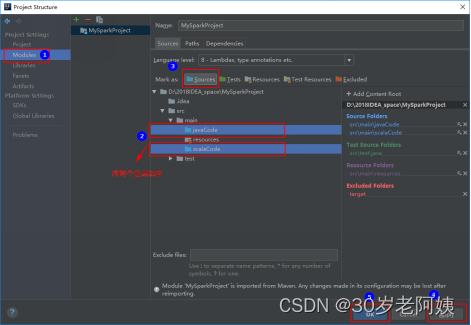
6)在main 目录下创建javaCode和scalaCode 并指定为源目录。名称任意。
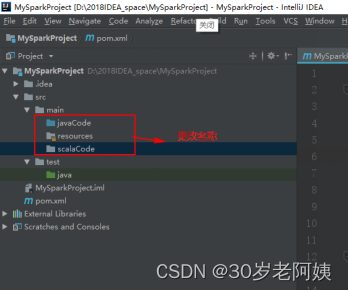
将main下的javaCode和scalaCode指定为源目录:
本文转载自: https://blog.csdn.net/yaya_jn/article/details/134523185
版权归原作者 30岁老阿姨 所有, 如有侵权,请联系我们删除。
版权归原作者 30岁老阿姨 所有, 如有侵权,请联系我们删除。