
Spark是什么:
Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
 Spark 借鉴 MapReduce 思想发展而来,保留分布式并行计算的优点并改进了其明显的缺陷;
Spark 借鉴 MapReduce 思想发展而来,保留分布式并行计算的优点并改进了其明显的缺陷;
让中间数据存储在内存中提高运行速度、并提供丰富的操作数据使API提高了开发速度。
Spark框架为什么如何的快呢?
1)数据结构(编程模型): Spark框架核心
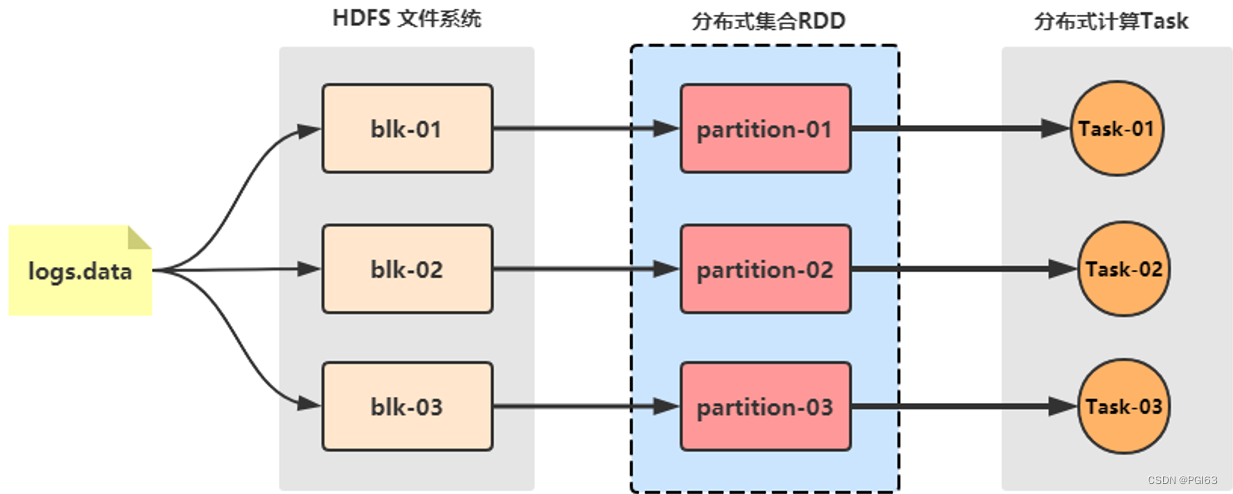
RDD:弹性分布式数据集,认为是列表List
Spark 框架将处理的数据封装到集合RDD中,调用RDD中函数处理数据
RDD 数据可以放到内存中,内存不足可以放到磁盘中
2)Task任务运行方式:以线程Thread方式运行
MapReduce中Task是以进程Process方式运行,当时Spark Task以线程Thread方式运行。
线程Thread运行在进程Process中,启动和销毁是很快的(相对于进程来说)。
扩展Hadoop基于进程计算和Spark基于线程方式优缺点?
Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。
比如多个map task读取不同数据源文件需要将数据源加载到每个map task中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行单位,缺点是线程之间会有资源竞争。
【扩展阅读】:线程基本概念
线程是CPU的基本调度单位
一个进程一般包含多个线程, 一个进程下的多个线程共享进程资源
不同进程之间的线程相互不可见
线程不能独立执行
一个线程可以创建和撤销另外一个线程
Spark四大特点
1.速度快:
计算速度快,整个计算操作,基于内存计算;Task线程完成计算任务执行
2.易于使用:
支持多种语言开发(Python,SQL,Java,Scala)
3.通用性强:
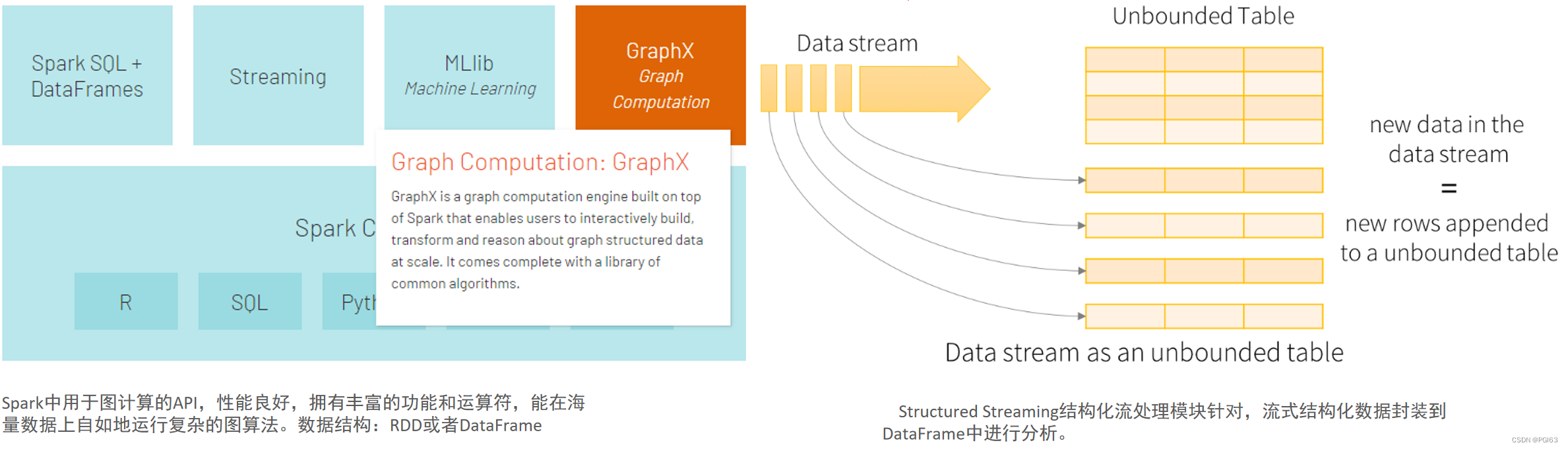
Spark 包括Spark SQL、Spark Streaming、MLlib 及GraphX在内的多个工具库
4.兼容性:(支持任何地方运行)
支持三方工具接入;支持多种操作系统
Spark 框架模块
整个Spark 框架模块包含:Spark Core、 Spark SQL、 Spark Streaming、 Spark GraphX、 Spark MLlib,后四项的能力都是建立在核心引擎之上

Python语言开发Spark程序
WordCount代码实战-原理分析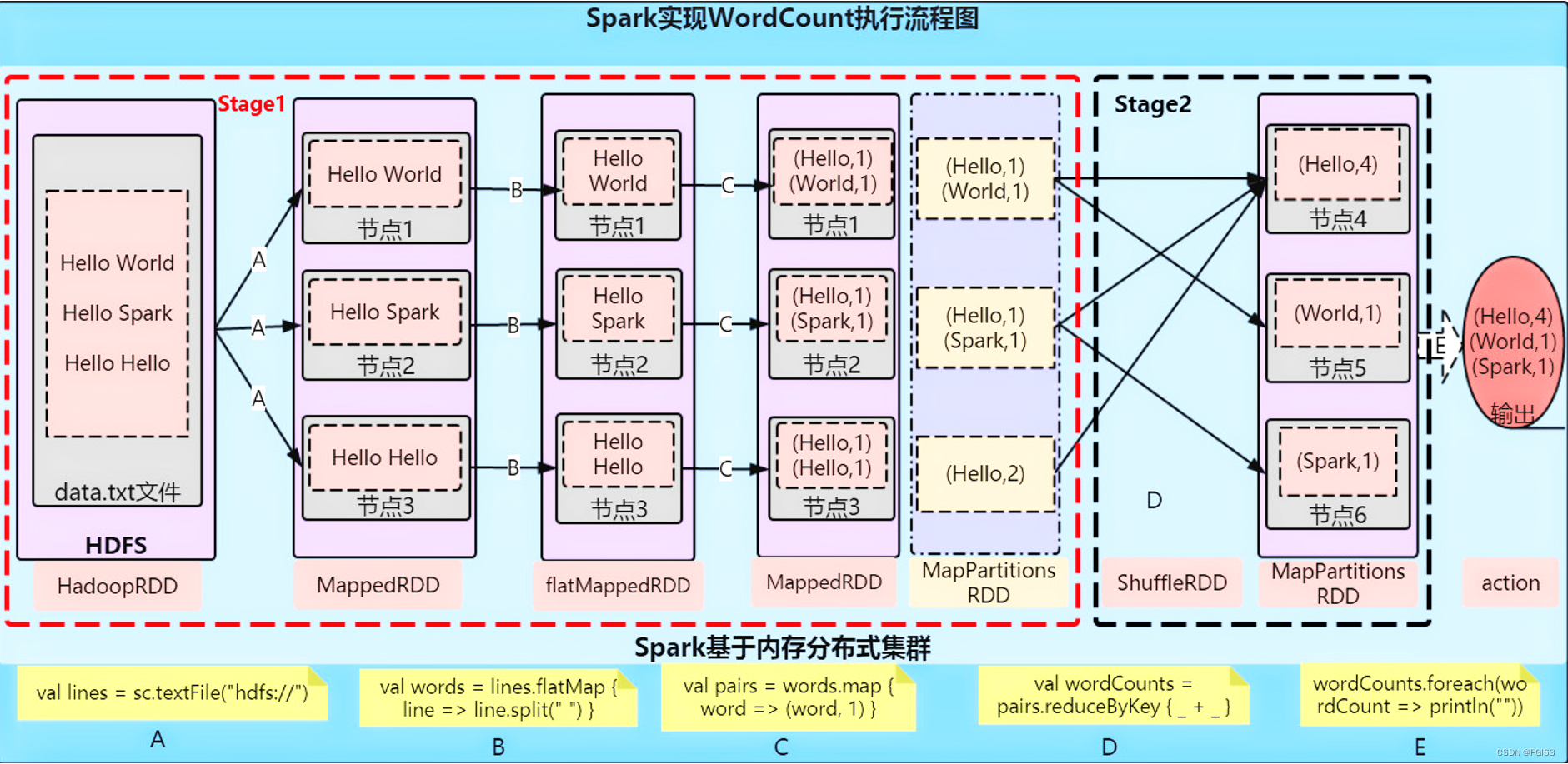
本地准备文件word.txt
hello you Spark Flink
hello me hello she Spark
PySpark代码
from pyspark import SparkContext, SparkConf
import os
# 这里可以选择本地PySpark环境执行Spark代码,也可以使用虚拟机中PySpark环境,通过os可以配置
os.environ['SPARK_HOME'] = '/export/servers/spark'
# PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
# os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
# os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
print('PySpark First Program')
# TODO: 当应用运行在集群上的时候,MAIN函数就是Driver Program,必须创建SparkContext对象
# 创建SparkConf对象,设置应用的配置信息,比如应用名称和应用运行模式
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
# TODO: 构建SparkContext上下文实例对象,读取数据和调度Job执行
sc = SparkContext(conf=conf)
# 第一步、读取本地数据 封装到RDD集合,认为列表List
wordsRDD = sc.textFile("file:///export/pyfolder1/pyspark-chapter01_3.8/data/word.txt")
# 第二步、处理数据 调用RDD中函数,认为调用列表中的函数
# a. 每行数据分割为单词
flatMapRDD = wordsRDD.flatMap(lambda line: line.split(" "))
# b. 转换为二元组,表示每个单词出现一次
mapRDD = flatMapRDD.map(lambda x: (x, 1))
# c. 按照Key分组聚合
resultRDD = mapRDD.reduceByKey(lambda a, b: a + b)
# 第三步、输出数据
res_rdd_col2 = resultRDD.collect()
# 输出到控制台
for line in res_rdd_col2:
print(line)
# 输出到本地文件中
resultRDD.saveAsTextFile("file:///export/pyfolder1/pyspark-chapter01_3.8/data/output1/")
print('停止 PySpark SparkSession 对象')
# 关闭SparkContext
sc.stop()
运行代码注意事项:
import os
这里可以选择本地PySpark环境执行Spark代码可以使用虚拟机中PySpark环境通过os可以配置
os.environ['SPARK_HOME'] = '/export/servers/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
执行结果如下:

版权归原作者 PGl63 所有, 如有侵权,请联系我们删除。