
文章目录
工业大数据项目介绍及环境构建
01:专栏目标
- 项目目标 - 项目1:在线教育 - 学习如何做项目,项目中大数据工程师要负责实现的内容和流程- 学习数仓基础理论:建模、分层- 项目2:工业大数据 - 企业中项目开发的落地:代码开发 - 代码开发:SQL【DSL + SQL】 - SparkCore- SparkSQL- 数仓的一些实际应用:分层体系、建模实现
- 内容目标 - 项目业务介绍:背景、需求- 项目技术架构:选型、架构- 项目环境测试
02:项目背景
- 目标:了解项目应用背景
- 实施- 工业- 产业分类 - 第一产业:植业、林业、畜牧业、水产养殖业等直接以自然物为生产对象的产业- 第二产业:工业、建筑业- 第三产业:交通运输业、通讯产业、商业、餐饮业、金融业、教育产业- 定义:属于第二产业,指的是采集原料,并把它们加工成产品的工作和过程- 划分 - 开采业:对自然资源的开采,对采矿、晒盐、森林采伐等- 加工业:粮油加工、食品加工、 轧花、缫丝、纺织、制革等- 制造业:炼铁、炼钢、化工生产、 石油加工、机器制造、木材加工等,以及电力、自来水、煤气的生产和供应等- 机修业:对工业品的修理、翻新,如机器设备的修理、 交通运输工具的修理等- 物理网:IOT(Internet Of Things)- 定义:指的是互联网、传统电信网等信息承载体,让所有能行使独立功能的普通物体实现互联互通的网络- 特点 - 物物相连- 远程监控和设备控制- 设备自动化,提升用户体验- 设备故障分析处理- 场景 - 智能设备:手机、平板、手表、眼镜、汽车- 智能家居:门、空调、洗衣机、水壶、窗帘、灯具、马桶、牙刷- 智能机器人:语音助手、家庭管家、工业机器手臂、快递机器人- ……- 工业物联网:IIOT(Industrial Internet of Things)- 定义:指数以亿计的工业设备,在这些设备上装置传感器,连接到网络以收集和共享数据- 发展- IDC预测,到2024年全球物联网的联接量将接近650亿,是手机联接量的11.4倍
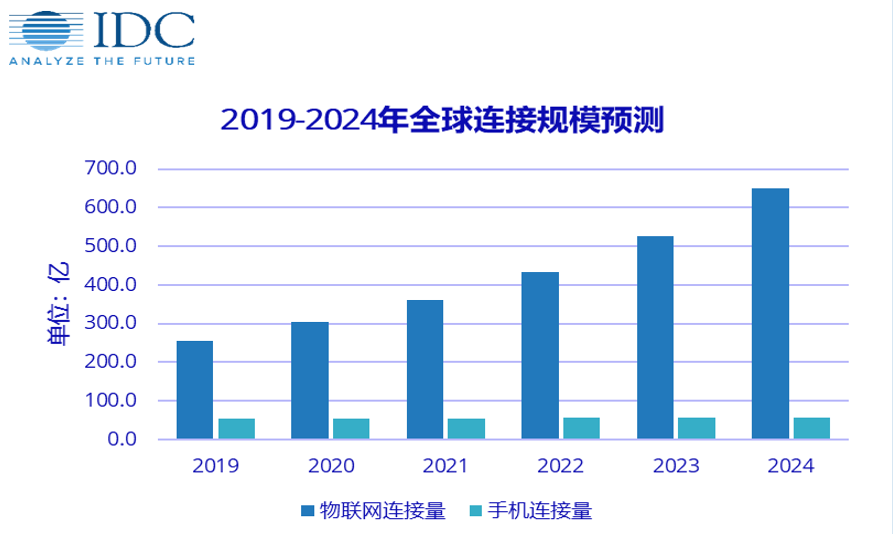
- 小结
- 了解项目应用背景
03:项目需求
- 目标:掌握项目业务需求- 这个项目属于哪个行业?- 为什么要做这个项目?- 这个项目的目的是什么?
- 实施- 项目行业:工业大数据- 项目名称:加油站服务商数据运营管理平台- 中石化,中石油,中海油、壳牌,道达尔……- 整体需求
基于加油站的设备安装、维修、巡检、改造等数据进行统计分析支撑加油站站点的设备维护需求以及售后服务的呼叫中心数据分析提高服务商服务加油站的服务质量保障零部件的仓储物流及供应链的需求实现服务商的所有成本运营核算- 具体需求- 运营分析:呼叫中心服务单数、设备工单数、参与服务工程师个数、零部件消耗与供应指标等- 设备分析:设备油量监控、设备运行状态监控、安装个数、巡检次数、维修次数、改造次数- 呼叫中心:呼叫次数、工单总数、派单总数、完工总数、核单次数- 员工分析:人员个数、接单次数、评价次数、出差次数- 报销统计分析、仓库物料管理分析、用户分析- 报表 - 小结
- 这个项目属于哪个行业?- 工业化大数据平台- 行业:加油站服务商运营数据分析平台- 为什么要做这个项目? - 基于所有设备的安装、维修、巡检、改造的工单数据,辅助公司的运营,提高服务质量,做合理的成本预算- 这个项目具体需求是什么? - 提高服务质量,做合理的成本预算- 需求一:对所有工单进行统计分析 - 安装工单、维修工单、巡检工单、改造工单、回访分析- 需求二:付费分析、报销分析 - 安装人工费用、安装维修材料费用、差旅交通费用
04:业务流程
- 目标:掌握加油站设备维护的主要业务流程
- 实施
 - step1:加油站服务商联系呼叫中心,申请服务:安装/巡检/维修/改造加油机- step2:呼叫中心联系对应服务站点,分派工单:联系站点主管,站点主管分配服务人员- step3:服务人员确认工单和加油站点信息- step4:服务人员在指定日期到达加油站,进行设备检修- step5:如果为安装或者巡检服务,安装或者巡检成功,则服务完成- step6:如果为维修或者改造服务,需要向服务站点申请物料,物料到达,实施结束,则服务完成- step7:服务完成,与加油站站点服务商确认服务结束,完成订单核验- step8:工程师报销过程中产生的费用- step9:呼叫中心会定期对该工单中的工程师的服务做回访
- step1:加油站服务商联系呼叫中心,申请服务:安装/巡检/维修/改造加油机- step2:呼叫中心联系对应服务站点,分派工单:联系站点主管,站点主管分配服务人员- step3:服务人员确认工单和加油站点信息- step4:服务人员在指定日期到达加油站,进行设备检修- step5:如果为安装或者巡检服务,安装或者巡检成功,则服务完成- step6:如果为维修或者改造服务,需要向服务站点申请物料,物料到达,实施结束,则服务完成- step7:服务完成,与加油站站点服务商确认服务结束,完成订单核验- step8:工程师报销过程中产生的费用- step9:呼叫中心会定期对该工单中的工程师的服务做回访 - 小结- 掌握加油站设备维护的主要业务流程- 工单分析、费用分析、物料分析、回访分析
05:技术选型
- 目标:掌握加油站服务商数据运营平台的技术选型
- 实施- 数据生成:业务数据库系统- Oracle:工单数据、物料数据、服务商数据、报销数据等- 数据采集- Sqoop:离线数据库采集- 数据存储- Hive【HDFS】:离线数据仓库【表】- 数据计算- SparkCore:类MR开发方式【写代码调用方法函数来处理:面向对象 + 面向函数】 - 对非结构化数据进行代码处理- 场景:ETL- SparkSQL:类HiveSQL开发方式【面向表】 - 对数据仓库中的结构化数据做处理分析- 场景:统计分析- 开发方式 - DSL:使用函数【DSL函数 + RDD函数】- SQL:使用SQL语句对表的进行处理- 功能:离线计算 + 实时计算- 注意:SparkSQL可以解决所有场景的分布式计算,离线计算的选型不仅仅是SparkSQL - SparkSQL/Impala/Presto- 使用方式 - Python/Jar:spark-submit - ETL- ThriftServer:SparkSQL用于接收SQL请求的服务端,类似于Hive的Hiveserver2- PyHive :Python连接SparkSQL的服务端,提交SQL语句- JDBC:Java连接SparkSQL的服务端,提交SQL语句- spark-sql -f :运行SQL文件,类似于hive -f- beeline:交互式命令行,一般用于测试- 数据应用- MySQL:结果存储- Grafana:数据可视化工具- 监控工具- Prometheus:服务器性能指标监控工具- 调度工具- AirFlow:任务流调度工具- 技术架构
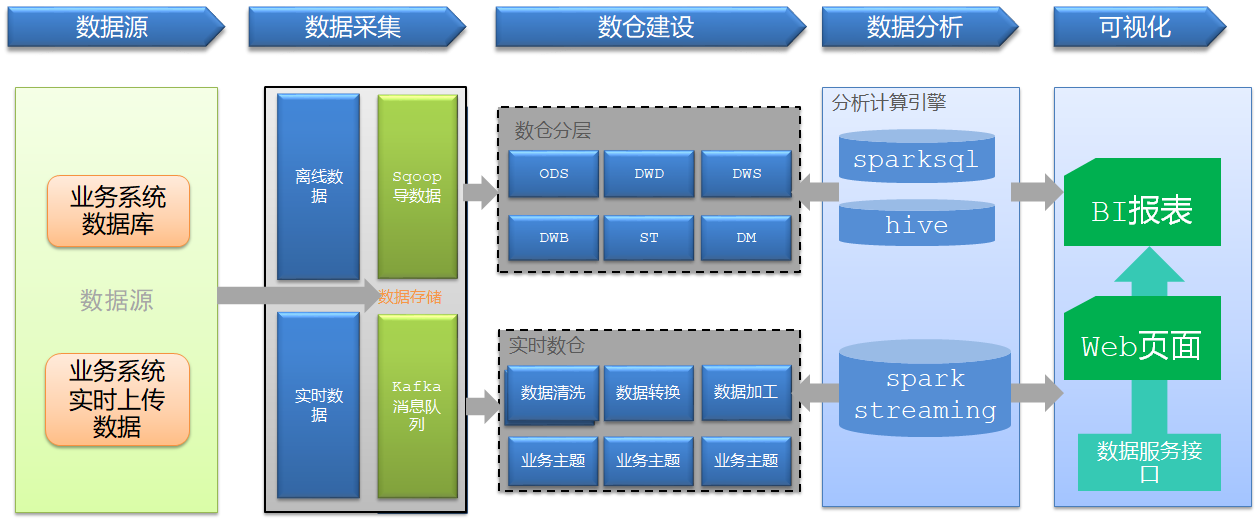
- 小结- 本次项目的技术架构是什么?- Lambda架构:离线计算层 + 实时计算层 + 数据服务层- 项目中用到了哪些技术?- 数据生成:Oracle- 数据采集:Sqoop- 数据存储:Hive- 数据处理:SparkSQL- 数据应用:MySQL + Grafana- 数据监控:Prometheus- 任务调度:AirFlow- 版本控制:Git + Gitee- 资源容器:Docker
06:Docker的介绍
- 目标:了解Docker的基本功能和设计- 为什么要用Docker?- 什么是Docker?
- 路径- step1:生产环境的问题- step2:容器的概念- step3:Docker的设计
- 实施- 生产环境的问题- 运维层面:一台机器上的应用太多,不同的环境,安装过程也不一样,管理麻烦,怎么办?- 开发层面:不同程序的运行受到环境、资源等因素的干扰,不同的环境,开发的方式也不一样,怎么办?- 容器的概念- 硬件容器:将一个硬件虚拟为多个硬件,上层共用硬件 - VMware WorkStation- 应用容器:将一个操作系统虚拟为多个操作系统,不同操作系统之间互相隔离
- Docker
- Docker的设计
 - 定义:Docker是一个开源的应用容器引擎,使用GO语言开发,基于Linux内核的cgroup,namespace,Union FS等技术,对应用程序进行封装隔离,并且独立于宿主机与其他进程,这种运行时封装的状态称为容器。- 目标- 提供简单的应用程序打包工具- 开发人员和运维人员职责逻辑分离- 多环境保持一致性,消除了环境差异- 功能:“Build,Ship and Run Any App,Anywhere”- 通过对应用组件的封装,分发,部署,运行等生命周期的管理,达到应用组件级别的一次封装,多次分发,到处部署- 架构
- 定义:Docker是一个开源的应用容器引擎,使用GO语言开发,基于Linux内核的cgroup,namespace,Union FS等技术,对应用程序进行封装隔离,并且独立于宿主机与其他进程,这种运行时封装的状态称为容器。- 目标- 提供简单的应用程序打包工具- 开发人员和运维人员职责逻辑分离- 多环境保持一致性,消除了环境差异- 功能:“Build,Ship and Run Any App,Anywhere”- 通过对应用组件的封装,分发,部署,运行等生命周期的管理,达到应用组件级别的一次封装,多次分发,到处部署- 架构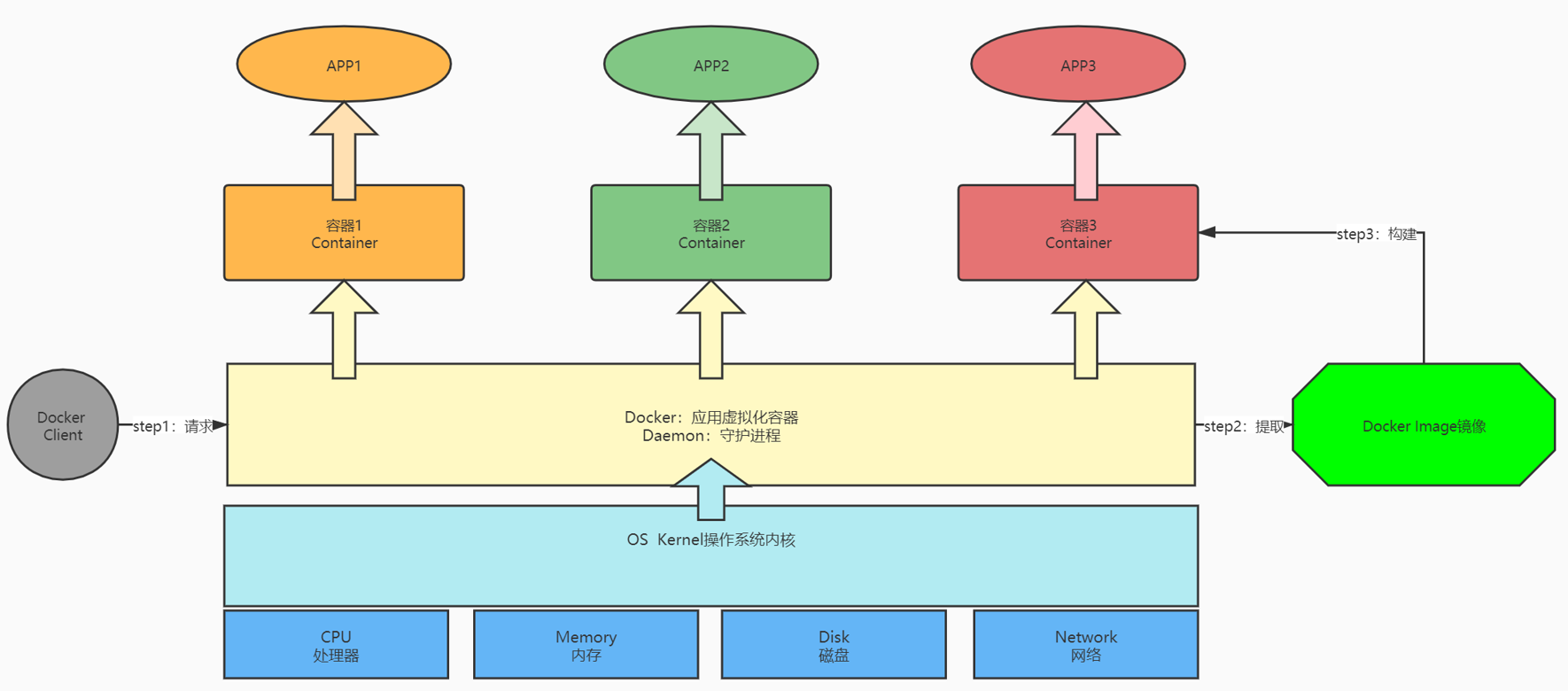 - 组成- 宿主机:安装Docker的那台实际的物理机器- docker client 【客户端】:用于连接服务端,提交命令给服务端
- 组成- 宿主机:安装Docker的那台实际的物理机器- docker client 【客户端】:用于连接服务端,提交命令给服务端#拉取镜像docker pull ……#启动容器docker run ……#进入容器dockerexec ……#查看容器dockerps ……- docker daemon【服务端】:用于接收客户端请求,实现所有容器管理操作- docker image【镜像】:用于安装APP的软件库,简单点理解为软件的安装包- docker container 【容器】:用于独立运行、隔离每个APP的单元,相当于每个独立的Linux系统 - 小结- 了解Docker的基本功能和设计
07:Docker的网络
- 目标:了解Docker的网络管理设计- Docker的
- 路径- step1:问题- step2:模式- step3:选型
- 实施- 问题- Docker的本质在一个操作上虚拟了多个操作系统出来,那每个操作之间如何进行网络通信呢?- 模式- host模式:每个虚拟系统与主机共享网络,IP一致,用不同端口区分不同虚拟系统
 - container模式:第一个容器构建一个独立的虚拟网络,其他的容器与第一个容器共享网络
- container模式:第一个容器构建一个独立的虚拟网络,其他的容器与第一个容器共享网络
``` - none模式:允许自定义每个容器的网络配置及网卡信息,每个容器独立一个网络

- bridge模式:构建虚拟网络桥,所有容器都可以基于网络桥来构建自己的网络配置
```
- 选型- 本次项目中使用bridge模式,类似于VM中的Net模式使用
- 管理- 了解即可,不用操作- 创建
docker network create --subnet=172.33.0.0/24 docker-bd0- 查看模式docker network ls- 删除docker network rm …… - 小结- 了解Docker的网络管理设计
08:Docker的使用
- 目标:了解docker的基本使用
- 路径- step1:docker管理- step2:image管理- step3:container管理
- 实施- docker管理- 默认开机自启- 了解即可,不用操作- 启动服务
systemctl start docker- 查看状态systemctl status docker- 关闭服务systemctl stop docker- image管理- 了解即可,不用操作- 添加镜像docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g- 列举镜像docker images- 移除镜像docker rmi ……- container管理- 熟悉常用操作- 创建并启动container:不用做docker run --net docker-bd0 --ip172.33.0.100 -d-p1521:1521 --name oracle 3fa112fd3642- run = create + start- 列举container#列举所有的dockerps-a#列举正在运行的dockerps- 进入containerdockerexec-it Name bash- 退出containerexit- 删除containerdockerrm …… - 小结- 了解docker的基本使用
09:Oracle的介绍
- 目标:了解Oracle工具的基本功能和应用场景
- 路径- step1:数据库分类- step2:Oracle的介绍
- 实施- 数据库分类- RDBMS:关系型数据库管理系统 - 工具:MySQL、Oracle、SQL Server……- 应用:业务性数据存储系统:事务和稳定性- 特点:体现数据之间的关系,支持事务,保证业务完整性和稳定性,小数据量的性能也比较好- 开发:SQL- NoSQL:Not Only SQL:非关系型数据库 - 工具:Redis、HBASE、MongoDB……- 分类:KV、文档、时序、图……- 应用:一般用于高并发高性能场景下的数据缓存或者数据库存储- 特点:读写速度特别快,并发量非常高,相对而言不如RDBMS稳定,对事务性的支持不太友好- 开发:每种NoSQL都有自己的命令语法- Oracle的介绍- 概念:甲骨文公司的一款关系数据库管理系统- Oracle在古希腊神话中被称为“神谕”,指的是上帝的宠儿- 在中国的商周时期,把一些刻在龟壳上的文字也称为上天的指示,所以在中国Oracle又翻译为甲骨文- Oracle是现在全世界最大的数据库提供商,编程语言提供商,应用软件提供商,它的地位等价于微软的地位- 分类:RDBMS,属于大型RDBMS数据库- 大型数据库:IBM DB2、Oracle、Sybase- 中型数据库:SQL Server、MySQL、Informix、PostgreSQL- 小型数据库:Access、Visual FoxPro、SQLite- 功能:实现大规模关系型数据存储- 特点- 功能全面:数据字典、动态性能视图、TRACE跟踪、AWR、ASH、SQL Monitor等- 性能优越:支持SQL大量的表连接、子查询、集合运算,长度可达上千行- 数据量大:相比较于其他的数据库,Oracle支持千万级别以上的数据高性能存储- 高可靠性:基于Oracle自带的RAC架构下,可靠性和稳定性相对比较高- 综合排名
 - 应用- 中国各大银行、电信、政府单位等机构所有系统- 趋势- 去IOE【IBM服务器、Oracle数据库、EMC存储】
- 应用- 中国各大银行、电信、政府单位等机构所有系统- 趋势- 去IOE【IBM服务器、Oracle数据库、EMC存储】 - 小结- 了解Oracle工具的基本功能和应用场景
10:集群软件规划
- 目标:了解项目的集群软件规划
- 实施
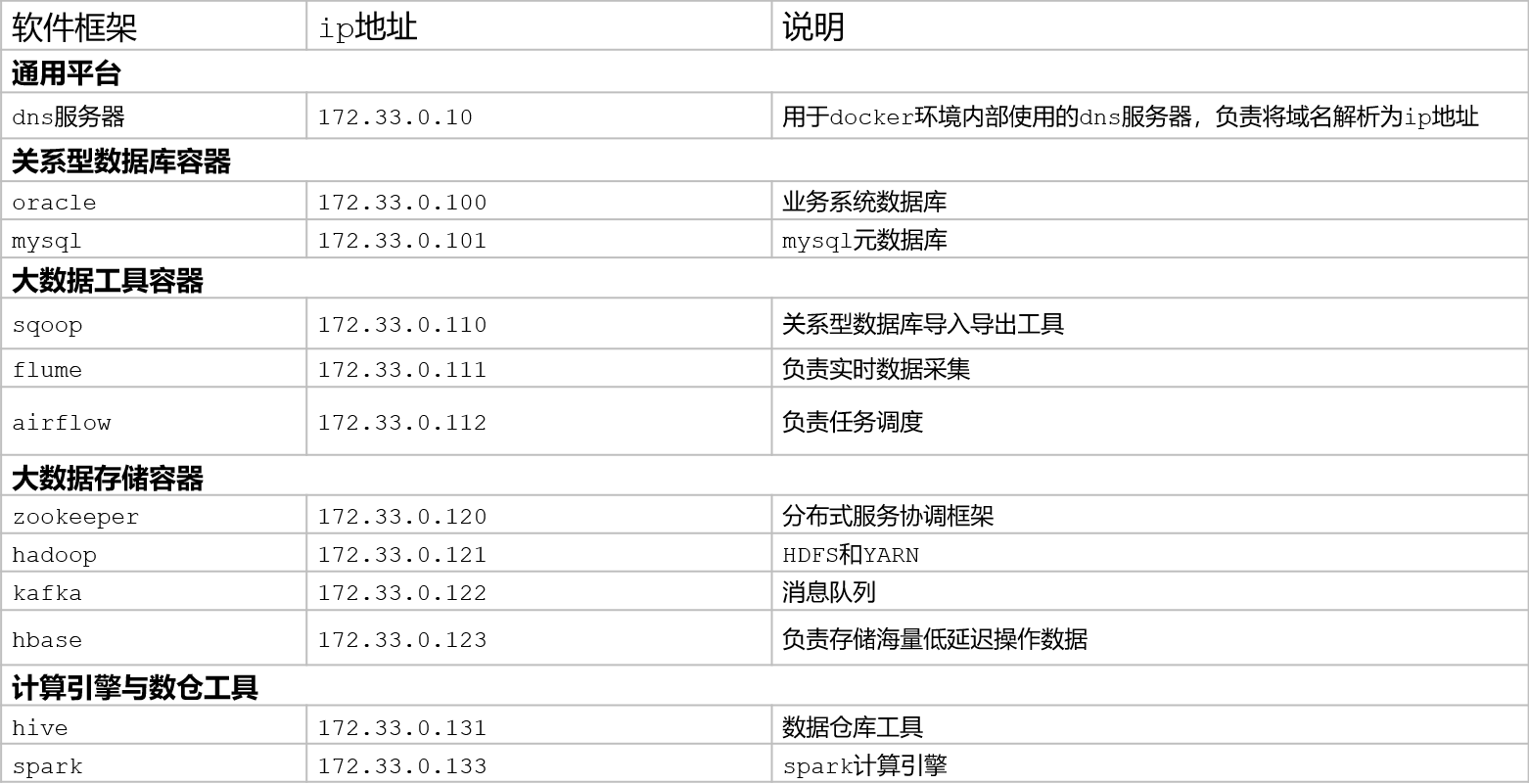
172.33.0.100 oracle.bigdata.cn172.33.0.110 sqoop.bigdata.cn172.33.0.121 hadoop.bigdata.cn172.33.0.131 hive.bigdata.cn172.33.0.133 spark.bigdata.cn - 小结- 了解项目的集群软件规划
11:项目环境导入
- 目标:实现项目虚拟机的导入
- 实施- step1:导入:找到OneMake虚拟机中以.vmx结尾的文件,使用VMware打开

 - step2:启动:启动导入的虚拟机,选择我已移动该虚拟机
- step2:启动:启动导入的虚拟机,选择我已移动该虚拟机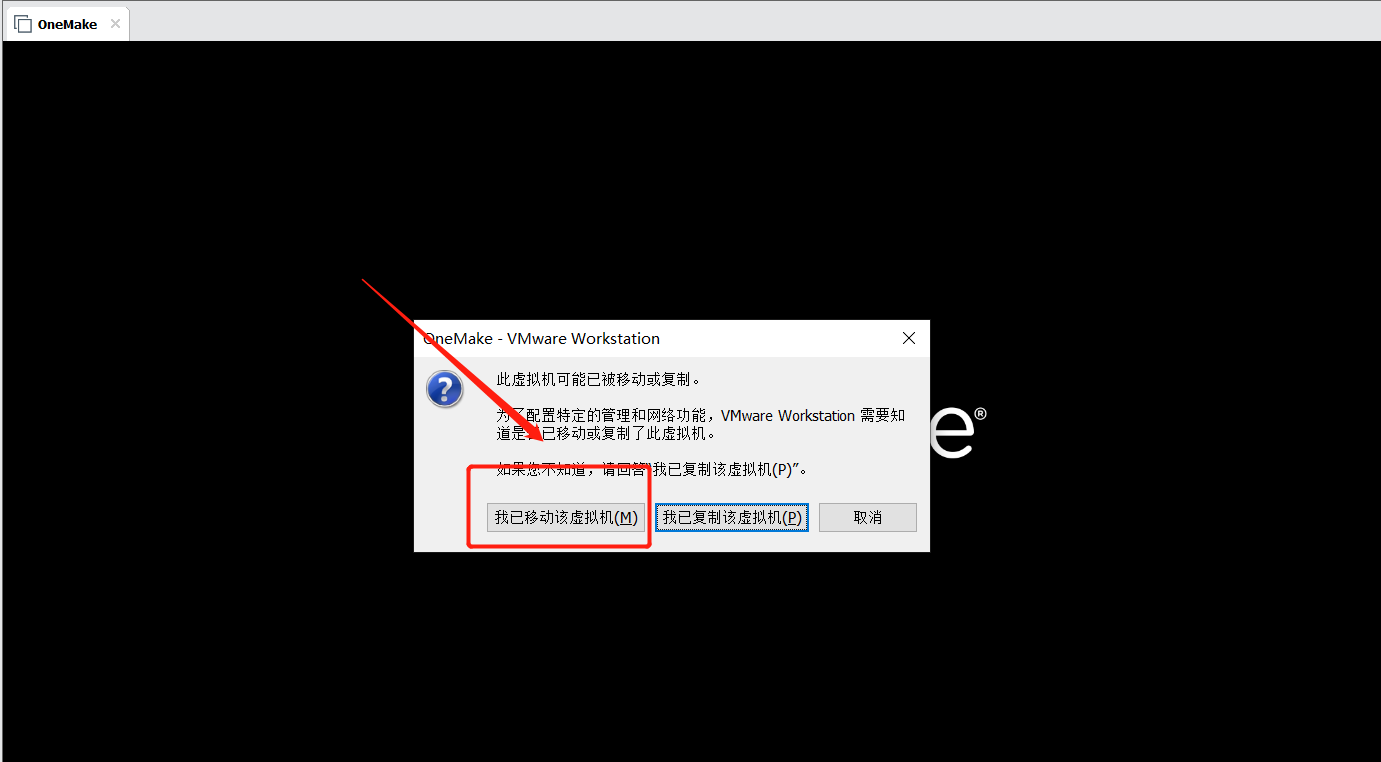
- step3:登陆:登陆到虚拟机内部,或者使用远程工具连接- 默认IP:192.168.88.100- 主机名:node1- 用户名:root- 密码:123456
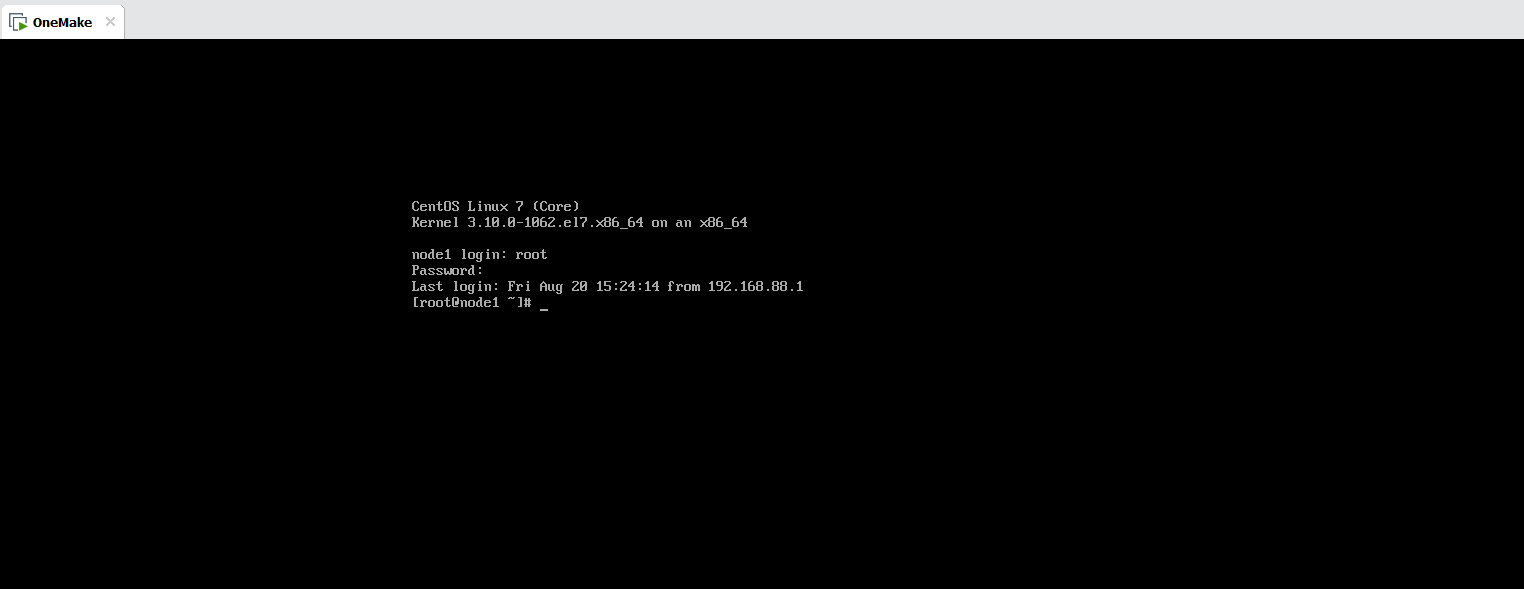
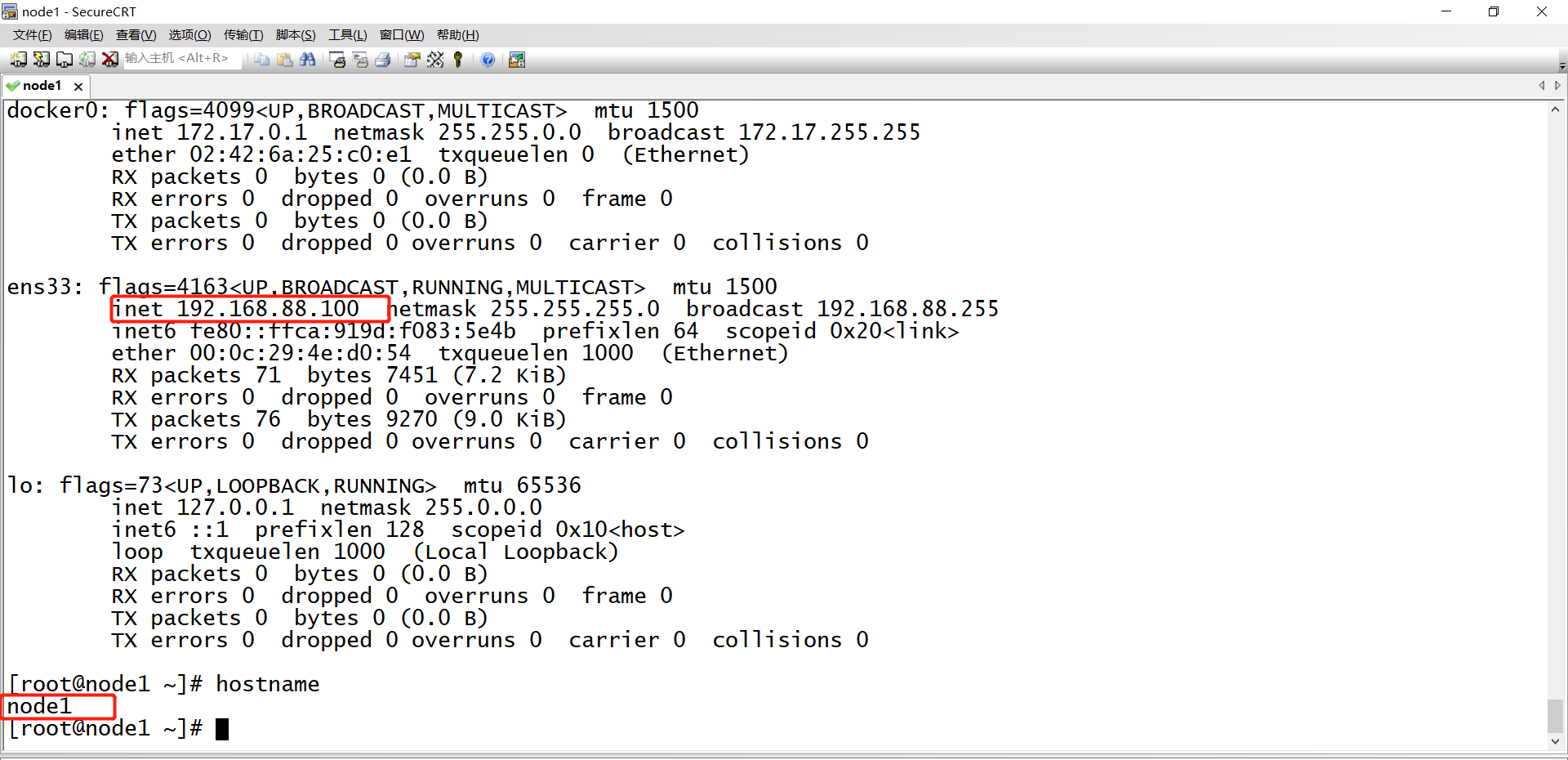
- 小结- 实现项目虚拟机的导入
12:项目环境配置
- 目标:根据需求实现项目环境配置
- 实施- 注意:所有软件Docker、Hadoop、Hive、Spark、Sqoop都已经装好,不需要额外安装配置,启动即可- 配置网络:如果你的VM Nat网络不是88网段,请按照以下修改- 修改Linux虚拟机的ens33网卡,网卡和网关,修改为自己的网段
vim /etc/sysconfig/network-scripts/ifcfg-ens33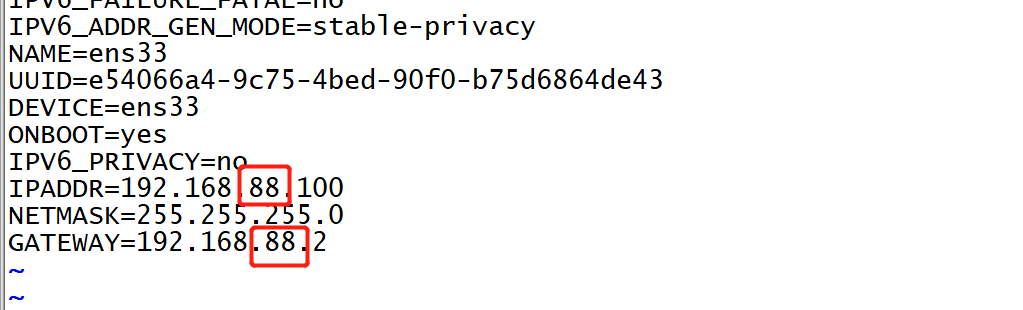 - 重启网卡
- 重启网卡systemctl restart network- 查看是否修改成功ifconfig- 配置映射- 修改Linux映射,修改为自己的网段vim /etc/hosts- 配置Windows上的映射,方便使用主机名访问【把以前的有冲突的注释掉】192.168.88.100 oracle.bigdata.cn 192.168.88.100 hadoop.bigdata.cn 192.168.88.100 hive.bigdata.cn 192.168.88.100 mysql.bigdata.cn 192.168.88.100 node1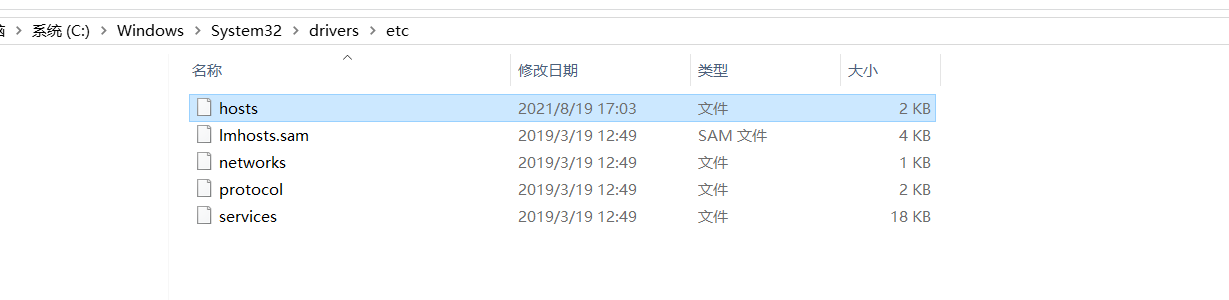 - 小结- 根据需求实现项目环境配置
13:项目环境测试:Oracle
- 目标:实现项目Oracle环境的测试
- 实施- 启动
docker start oracle- 进入docker exec -it oracle bash- 连接#进入客户端命令行:/nolog表示只打开,不登录,不用输入用户名和密码sqlplus /nolog#登陆连接服务端:/ as sysdba表示使用系统用户登录conn / as sysdba- 测试select TABLE_NAME from all_tables where TABLE_NAME LIKE ‘CISS_%’;- 退出exit- 远程连接:DG- step1:安装DG- step2:创建连接 - SID:helowin- 用户名:ciss - 密码:123456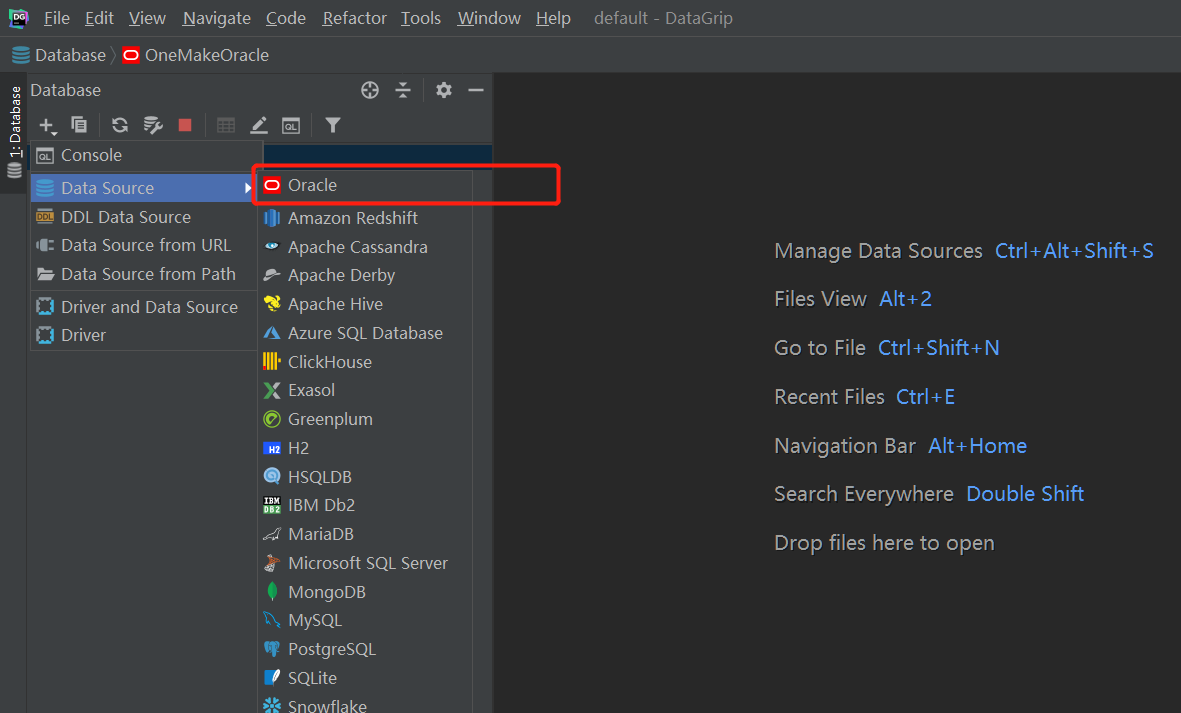

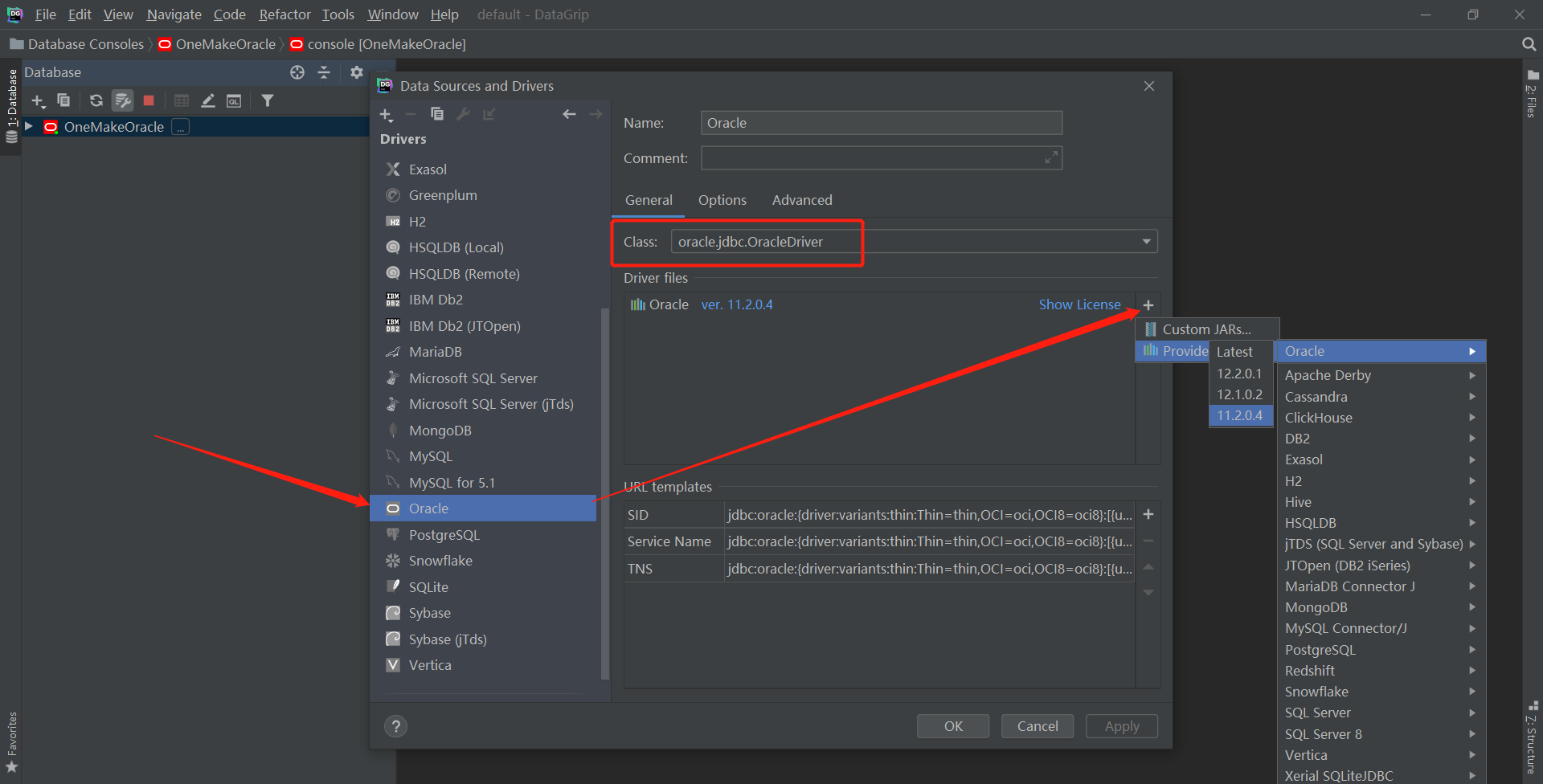
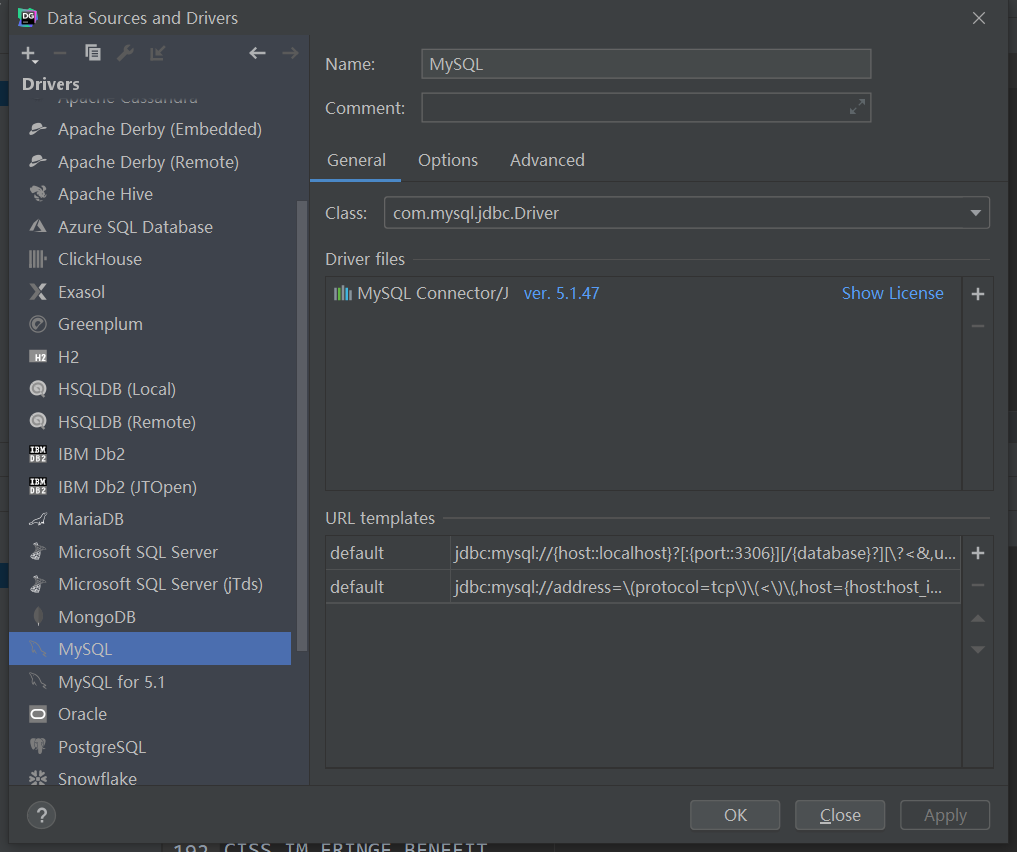
- step3:配置驱动包
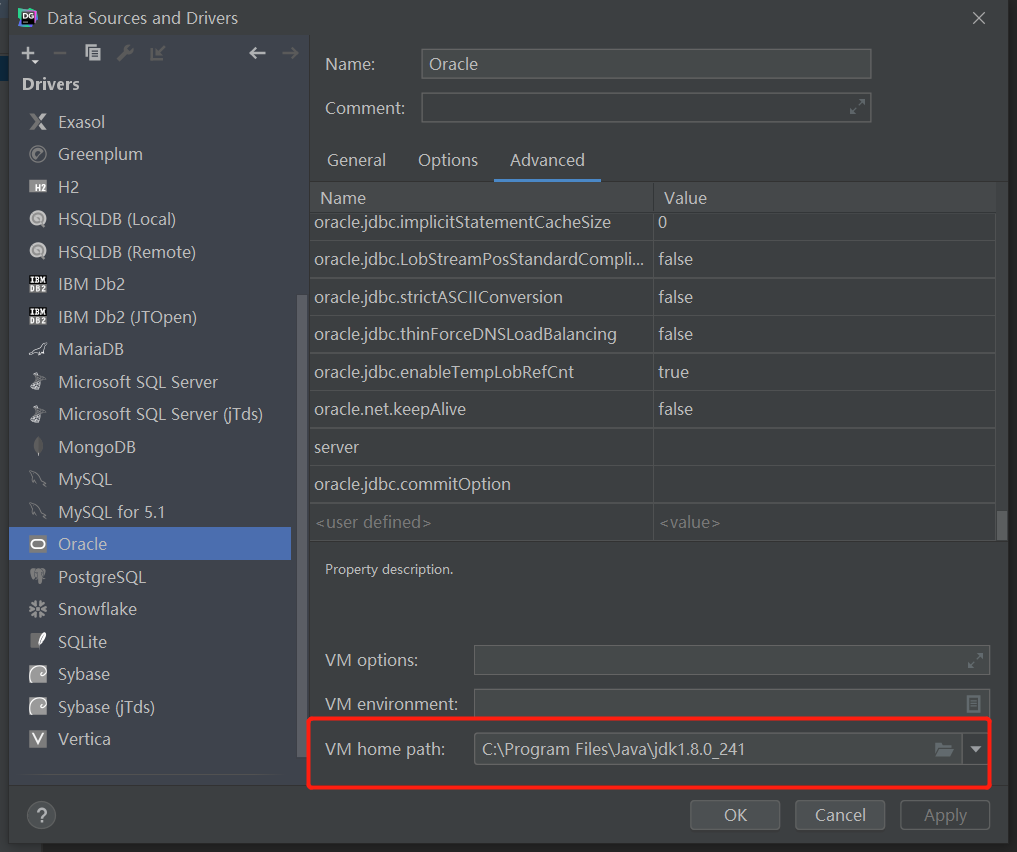
- step4:配置JDK
- step5:测试
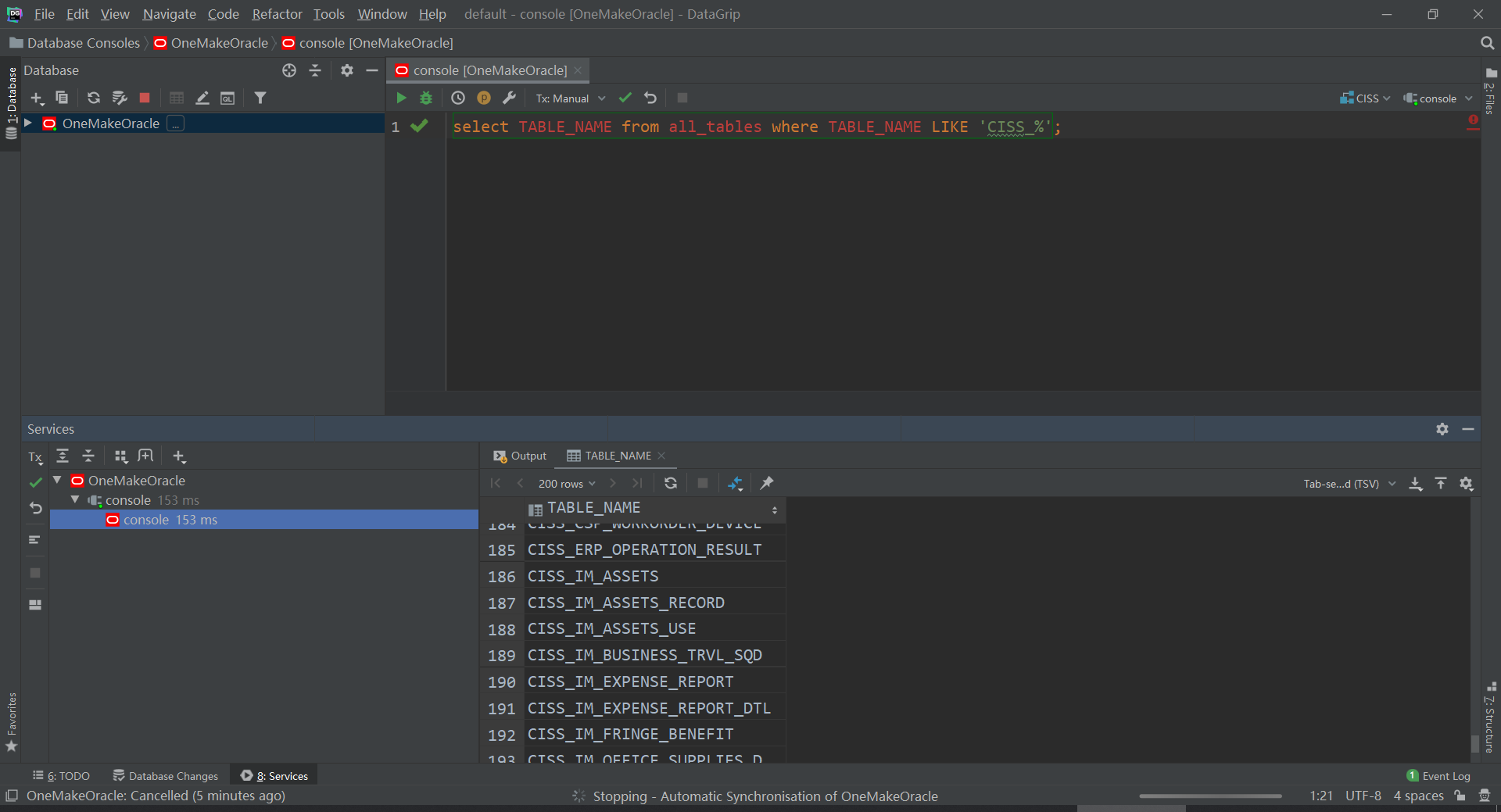
- 关闭
docker stop oracle - 小结- 实现项目Oracle环境的测试
14:项目环境测试:MySQL
- 目标:实现项目MySQL环境的测试
- 实施- 大数据平台中自己管理的MySQL:两台机器- 存储软件元数据:Hive、Sqoop、Airflow、Oozie、Hue- 存储统计分析结果- 注意:MySQL没有使用Docker容器部署,直接部署在当前node1宿主机器上- 启动/关闭:默认开启自启动- 连接:使用命令行客户端、Navicat、DG都可以- 用户名:root- 密码:123456
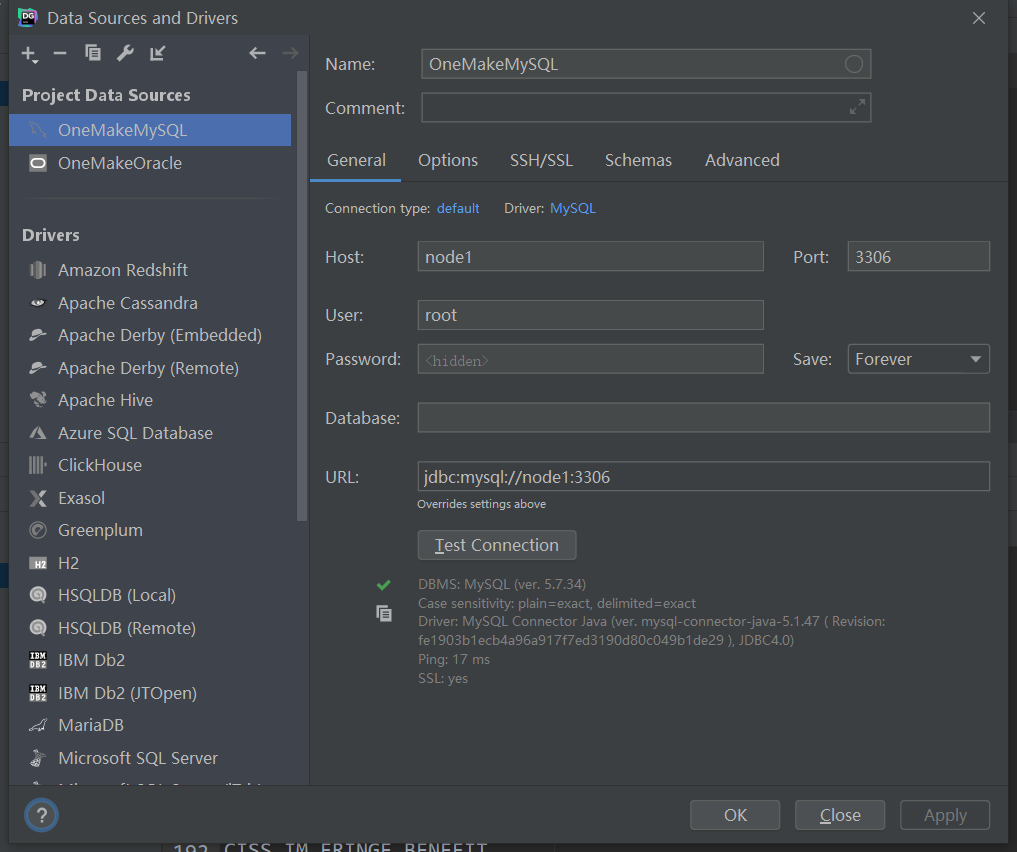
 - 查看
- 查看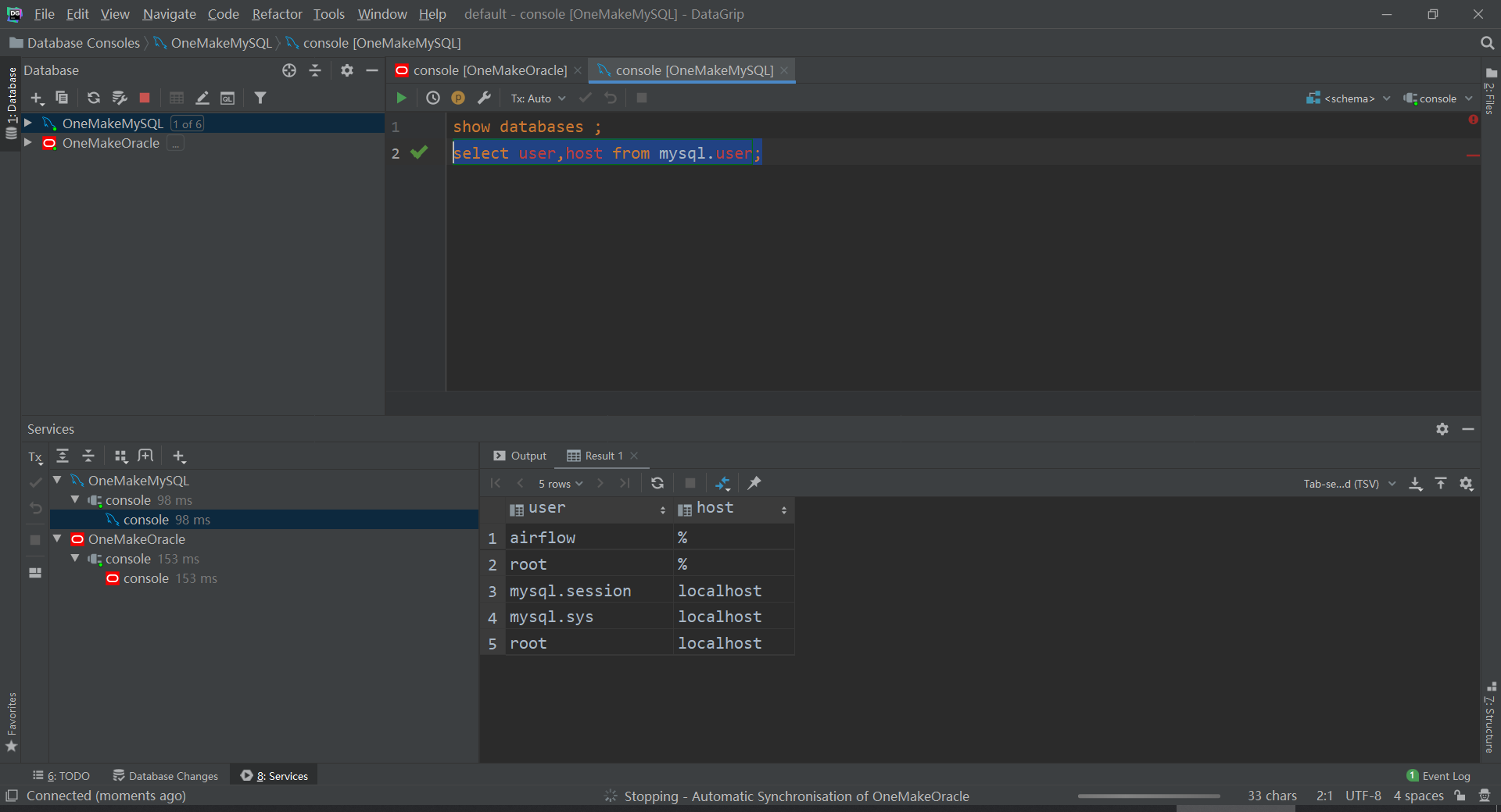
- 小结- 实现项目MySQL环境的测试
15:项目环境测试:Hadoop
- 目标:实现项目Hadoop环境的测试
- 实施- 启动
docker start hadoop- 进入docker exec -it hadoop bash- 查看进程jps- 启动进程start-dfs.shstart-yarn.shmr-jobhistory-daemon.sh start historyserver- 访问页面- node1:50070 - node1:8088
- node1:8088 - node1:19888
- node1:19888 - 退出
- 退出exit- 关闭docker stop hadoop - 小结- 实现项目Hadoop环境的测试
16:项目环境测试:Hive
- 目标:实现项目Hive环境的测试
- 实施- 启动Hive容器
docker start hive- 进入Hive容器docker exec -it hive bashsource /etc/profile- 连接beeline!connect jdbc:hive2://hive.bigdata.cn:10000账号为root,密码为123456- SQL测试select count(1);- Shuffle【分区、排序、分组】三种场景- 重分区:repartition:分区个数由小变大 - 调用分区器对所有数据进行重新分区- rdd1 - part0:1 2 3- part1: 4 5 6- rdd2:调用分区器【只有shuffle阶段才能调用分区器】 - part0:0 6- part1:1 4- part2:2 5- 全局排序:sortBy - part0:1 2 5- part1: 4 3 6- 方案:将所有数据放入磁盘- 实现:对数据做了范围分区:将所有数据做了采样:4 - part0:6 5 4- part1:3 2 1- 全局分组:groupBy,reduceByKey- 关闭Hive容器docker stop hive - 小结- 实现项目Hive环境的测试
17:项目环境测试:Spark
- 目标:实现项目Spark环境的测试
- 实施- 启动Spark容器
docker start spark- 进入Spark容器docker exec -it spark bashsource /etc/profile- 启动Thrift Server【默认已经启动】start-thriftserver.sh \--name sparksql-thrift-server \--master yarn \--deploy-mode client \--driver-memory 1g \--hiveconf hive.server2.thrift.http.port=10001 \--num-executors 3 \--executor-memory 1g \--conf spark.sql.shuffle.partitions=2 - 测试
- 测试beeline -u jdbc:hive2://spark.bigdata.cn:10001 -n root -p 123456select count(1);- 关闭Spark容器docker stop spark - 小结- 实现项目Spark环境的测试
18:项目环境测试:Sqoop
- 目标:实现项目Sqoop环境的测试
- 实施- 启动Sqoop容器
docker start sqoop- 进入Sqoop容器docker exec -it sqoop bashsource /etc/profile- 测试sqoop list-databases \--connect jdbc:oracle:thin:@oracle.bigdata.cn:1521:helowin \--username ciss \--password 123456- 关闭Sqoop容器docker stop sqoop - 小结- 实现项目Sqoop环境的测试
要求
- Python面向对象- 类和对象- 方法
- Hive中建表语法
create [external] table tbname( 字段 类型 comment,) commentpartitioned by clustered by col into N bucketsrow format stored as textfilelocation - 提前预习:EntranceApp.py
本文转载自: https://blog.csdn.net/xianyu120/article/details/128081267
版权归原作者 Maynor996 所有, 如有侵权,请联系我们删除。
版权归原作者 Maynor996 所有, 如有侵权,请联系我们删除。