
数据可视化是数据科学的重要组成部分。它帮助我们探索和理解数据。数据可视化也是传递信息和交付结果的重要工具。
由于数据可视化的重要性,在数据科学的生态系统中有许多数据可视化库和框架。其中一个流行的是Seaborn,这是一个用于Python的统计数据可视化库。
我最喜欢Seaborn原因是它巧妙的语法和易用性,通过Seaborn我们只用3个函数就可以创建普通的图表。
- Relplot:用于创建关系图
- Displot:用于创建分布图
- Catplot:用于创建分类图
这3个函数提供了一个图形级的界面,用于创建和定制不同类型的图。我们将通过几个示例来理解如何使用这些函数。
示例将基于一个超市数据集(https://www.kaggle.com/aungpyaeap/supermarket-sales)。我们首先导入库并读取数据集。
import numpy as np
import pandas as pd
import seaborn as sns
sns.set(style='darkgrid')
df = pd.read_csv("/content/supermarket.csv", parse_dates=['date'])
df.head()

Relplot
relplot函数用于创建关系图,即线图和散点图。这些图提供了变量之间关系的概述。
让我们首先创建单位价格和总数列的散点图。我们指定数据和列名。kind参数用于选择绘图类型。
sns.relplot(data=df, x='unit_price', y='total', kind='scatter')
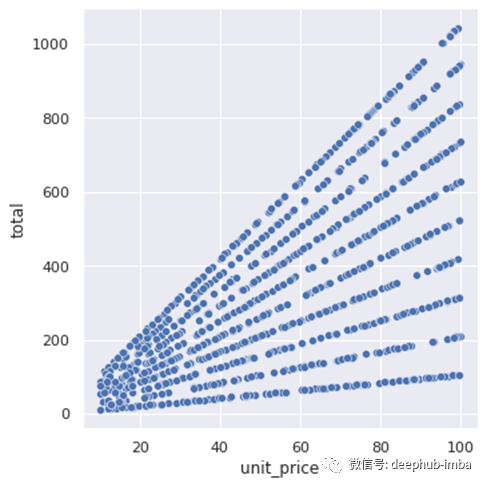
这是一堆直线,因为总价格等于单位价格乘以数量,数量就是直线的斜率。
让我们使用relplot函数创建一个线图。我们可以画出每天的总销售额。第一步是按日期对销售进行分组,然后计算总和。
df_sub = df[['total','date']].groupby('date').sum().reset_index()
df_sub.head()
现在我们可以创建直线图了。
sns.relplot(data=df_sub, x='date', y='total', kind='line',
height=4, aspect=2)

我们使用height 和aspect参数来调整绘图的大小。aspect参数设置宽高比。
Displot
使用分布函数创建分布图,从而使我们可以大致了解数值变量的分布。我们可以使用displot函数创建直方图,kde图,ecdf图和rugplots。
直方图将数值变量的取值范围划分为离散的容器,并计算每个容器中的数据点(即行)的数量。让我们画一个总销售额的柱状图。
sns.displot(data=df, x='total', hue='gender', kind='hist',
multiple='dodge', palette='Blues', height=4, aspect=1.4)
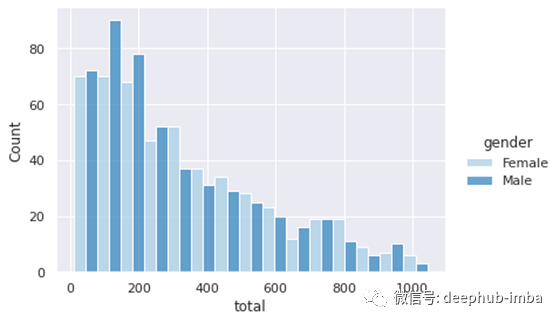
hue参数根据给定列中的不同值分隔行。我们已经将性别列传递给了hue参数,因此我们可以分别看到女性和男性的分布。
多个参数决定了不同类别的栏如何显示(“dodge”表示并排显示)。当使用hue变量时,palette 参数用于选择调色板。
这些函数的一个优点是它们的参数基本上是相同的。例如,它们都使用hue、height和aspect 参数。它使学习语法更容易。
kde图创建了给定变量(即列)的核密度估计值,因此我们得到概率分布的估计值。我们可以通过将kind参数设置为“kde”来创建kde图。
sns.displot(data=df, x='total', hue='gender', kind='kde',
palette='cool', height=5, aspect=1.4)

Catplot
使用catplot函数创建分类图,如箱形图、条形图、带状图、小提琴图等。总共有8个不同的分类图可以使用catplot函数生成。
箱形图用中位数和四分位数表示变量的分布。下面是每个产品线单价栏的箱形图。
sns.catplot(data=df, x='prod_line', y='unit_price', kind='box',
height=6, aspect=1.8, width=0.5)
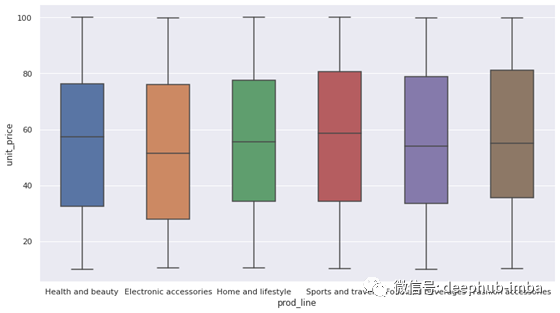
“width”参数调整框的宽度。
以下是箱形图的结构:
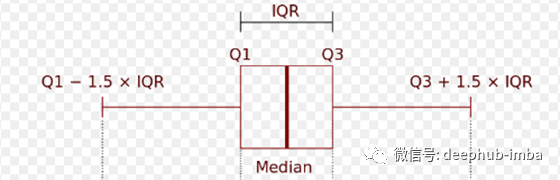
中位数是所有点都排序后的中间点。Q1(第一或下四分位数)是下半部分的中位数,Q3(第三或上四分位数)是上半部分的中位数。
我们还可以创建一个条形图来检查不同产品线的单价。与使用方框不同,条形图用一个点表示每个数据点。因此,它就像数字和分类变量的散点图。
让我们为branch和total列创建一个条形图。
sns.catplot(data=df, x='branch', y='total', kind='strip',
height=5, aspect=1.3)

这些点的密度给了我们一个分布的大致概念。似乎C分支在顶部区域有更多的数据点。我们可以通过检查每个分行的平均总额来证实我们的想法。
df[['branch','total']].groupby('branch').mean()
total
branch
--------------------
A 312.354029
B 319.872711
C 337.099726
C的平均值高于其他两分行的平均值。
catplot功能下的另一种类型是小提琴图。这是一种plto和kde的组合。因此,它提供了一个变量分布的概述。
例如,我们可以为前面示例中的strip plot所使用的列创建小提琴图。我们需要做的就是改变kind参数。
sns.catplot(data=df, x='branch', y='total', kind='violin',
height=5, aspect=1.3)
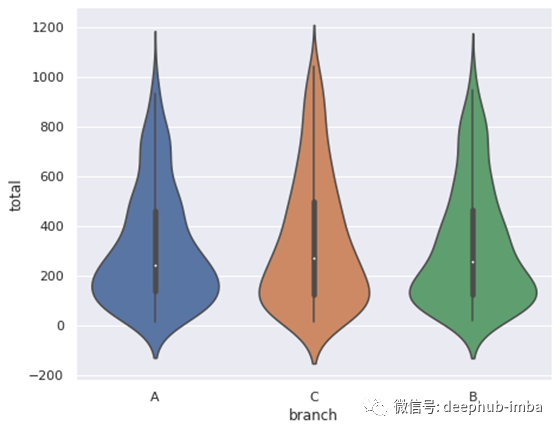
C的小提琴的顶部比其他两支略粗。
总结
relplot、displot和catplot函数可以生成14个不同的图,这些图几乎涵盖了我们在数据分析和探索中通常使用的所有可视化类型。
这些函数提供了一个标准的语法,这使得掌握它们非常容易。在大多数情况下,我们只需要更改kind参数的值。此外,自定义绘图的参数也是相同的。
在某些情况下,我们需要使用不同类型的图表。但是我们需要的大部分都在这三个函数的范围内。
作者:Soner Yıldırım
deephub翻译组