
目录
前言
这段时间基于大数据技术与应用大赛所做的大数据平台环境搭建,原创文章。在自己电脑上搭建过几遍,按照上述笔记搭建没有出现问题。家人们如果在尝试搭建的过程中出现问题可以在下方评论区留言或者私信,我看到后会回复。希望能对有需求的萌新有所帮助。
大赛简介:
赛项以大数据技术与应用为核心内容和工作基础,重点考查参赛选手基于Spark、Flink平台环境下,充分利用Spark Core、Spark SQL、Flume、Kafka、Flink等技术的特点,综合软件开发相关技术,解决实际问题的能力,具体包括:
- 掌握基于Spark的离线分析平台、基于Flink的实时分析平台,按照项目需求安装相关技术组件并按照需求进行合理配置;
- 掌握基于Spark的离线数据抽取相关技术,完成指定数据的抽取并写入Hive分区表中;
- 综合利用Spark Core、Spark SQL等技术,使用Scala开发语言,完成某电商系统数据的离线统计服务,包括销量前5商品统计、某月的总销售额统计、每个月的销售额统计、每个用户在线总时长统计,并将统计结果存入MySQL数据库中;
- 综合利用Flume、Flink相关技术,使用Scala开发语言,完成将某电商系统的用户操作日志抽取到Kafka中,消费Kafka中的数据并计算商城在线人数,并统计该电商系统的UV与PV;
- 综合运用HTML、CSS、JavaScript等开发语言,Vue.js前端技术,结合Echarts数据可视化组件,对MySQL中的数据进行可视化呈现;
- 根据数据可视化结果,完成数据分析报告的编写;
- 竞赛时间6小时,竞赛连续进行。
一、Hadoop完全分布式安装配置
1、上传hadoop安装文件
hadoop压缩包为hadoop-2.7.3.tar,使用lrzsz工具上传到linux系统,直接使用rz命令,然后选择需要上传的文件就可以了。 注意:如果使用rz命令没有任何反应。如下图

可能是linux下没有安装lrzsz工具,需要使用命令安装lrzsz工具。
yum -y install lrzsz

为了方便也可以安装使用vim
yum -y install vim
使用rz命令统一将hadoop安装文件上传到linux系统中的 /usr/local/ 目录下。

2、修改主机名
修改配置文件:vim /etc/hostname
将三台默认主机名localhost.localdomain修改为hadoop7/hadoop8/hadoop9
然后使用命令reboot分别重启让修改生效。
3、映射和集群
systemctl stop firewalld 关闭防火墙
systemctl status firewalld 查看防火墙状态
A、映射
将主机名和ip地址一 一对应,之后访问某个主机名就等于连接到某个IP地址。 ip地址映射,需要修改配置文件 vim /etc/hosts,然后将ip地址和主机名写进去。同时为了搭建集群,这里顺便将每台的主机名和ip地址都添加到文件hosts里面。

windows系统也需要配置相同的ip映射地址。修改 C:\Windows\System32\drivers\etc\hosts文件 添加IP地址映射在最后一行
192.168.164.131 hadoop7
192.168.164.134 hadoop8
192.168.164.136 hadoop9

如果该文件不能直接修改保存,请先复制一份到桌面,修改完成后,替换 C:\Windows\System32\drivers\etc\hosts文件
测试是否成功,使用xshell连接刚刚做完ip映射的计算机,不使用ip地址连接,使用主机名连接,如果连接成功,表示没有问题。
B、解压
解压hadoop和jdk的安装包
(tar -zxvf 文件名 z代表压缩方式是gz,x表示解压,v表示显示信息,f表示要解压的文件名(一定写最后))
tar -zxvf hadoop-2.7.3.tar.gz
tar -zxvf jdk-8u144-linux-x64.tar.gz
解压成功如下图:

C、配置系统的环境变量
将jdk和hadoop的安装路径,写到系统的环境变量里。linux系统中,需要将程序写到/etc/profile文件中,表示写入到环境变量。使用命令vim /etc/profile 打开编辑文件 在最后一行,添加以下内容:
export JAVA_HOME=/usr/local/jdk1.8.0_144 jdk的解压路径
export HADOOP_HOME=/usr/local/hadoop-2.7.3 hadoop的解压路径
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
配置完成后 使用命令source /etc/profile (source可以让才修改的profile文件立即生效,不需要重启系统)
最后测试是否安装配置成功 javac 打印所有能使用的JDK命令 java -version 打印当前安装JDK的版本

查看配置是否成功,直接打印$PATH环境变量的值,看是否加入了HADOOP的安装路径 echo $PATH 打印hadoop2.7.3的版本信息 hadoop version

D、HDFS集群
以下操作先在主机hadoop7上配置,配置完成后进入 /usr/local/hadoop-2.7.3/etc/hadoop目录下使用scp命令将配置好的hadoop-2.7.3和jdk1.8.0_144相关文件复制到hadoop8和hadoop9的 /usr/local/hadoop-2.7.3/etc/hadoop目录下。
修改hadoop-2.7.3的配置文件slaves文件
slaves文件是指定从机的主机名:我们指定hadoop7为主机,hadoop8和hadoop9为从机 cd /usr/local/hadoop-2.7.3/etc/hadoop 编辑文件slaves vim slaves
hadoop8
hadoop9
修改hadoop-2.7.3的配置文件hadoop-env.sh文件
修改hadoop-env.sh文件中的jdk,就是将jdk的安装路径添加到该文件中。这个文件的位置,在Hadoop的安装路径下的etc下的hadoop目录 进入该目录: cd /usr/local/hadoop-2.7.3/etc/hadoop 编辑文件,添加jdk安装路径 vim hadoop-env.sh
修改export JAVA_HOME=${JAVA_HOME} 为 export JAVA_HOME=/usr/local/jdk1.8.0_144
修改hadoop-2.7.3的配置文件core-site.xml文件
进入该目录 cd /usr/local/hadoop-2.7.3/etc/hadoop
使用vim命令进入该文件进行配置:vim core-site.xml
第一个配置
<property> (属性)
<name>fs.defaultFS</name> (配置的功能名称(这里是配置默认的文件系统))
<value>hdfs://主机名:9000</value> 功能配置值(这里用的是HDFS作为文件系统,还要指定HDFS放在哪台主机上运行,9000默认端口号)
</property> (/属性)
第二个配置
<property>
<name>hadoop.tmp.dir</name> (设置数据存储目录,数据存在什么地方)
<value>自己到hadoop目录下创建一个目录,写在这里。比如 /usr/local/hadoop-2.7.3/hadoopData</value>
</property>
修改hadoop-2.7.3的配置文件hdfs-site.xml文件
进入该目录 cd /usr/local/hadoop-2.7.3/etc/hadoop
使用vim命令进入该文件进行配置:hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
E、使用scp命令
进入 /usr/local/hadoop-2.7.3/etc/hadoop目录
scp slaves root@hadoop8:/usr/local/hadoop-2.7.3/etc/hadoop
scp hadoop-env.sh root@hadoop8:/usr/local/hadoop-2.7.3/etc/hadoop
scp core-site.xml root@hadoop8:/usr/local/hadoop-2.7.3/etc/hadoop
scp hdfs-site.xml root@hadoop8:/usr/local/hadoop-2.7.3/etc/hadoop
scp slaves root@hadoop9:/usr/local/hadoop-2.7.3/etc/hadoop
scp hadoop-env.sh root@hadoop9:/usr/local/hadoop-2.7.3/etc/hadoop
scp core-site.xml root@hadoop9:/usr/local/hadoop-2.7.3/etc/hadoop
scp hdfs-site.xml root@hadoop9:/usr/local/hadoop-2.7.3/etc/hadoop

分别进入主机和从机的/usr/local/hadoop-2.7.3目录下创建hadoopData目录。
mkdir hadoopData

F、初始化HDFS文件系统
hdfs namenode -format (会在存储数据的目录,自动创建一个dfs文件目录) 初始化是否成功,就是查看数据存放目录(自己设置的目录)是否会自动生成dfs目录

4、配置yarn和mapreduce
A、配置mapreduce组件
数据分析组件,作为程序任务来执行
先进入/usr/local/hadoop-2.7.3/etc/hadoop目录
使用命令mv mapred-site.xml.template mapred-site.xml修改文件名,再使用命令vim mapred.site.xml 进入mapred.site.xml修改配置文件
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
B、配置Yarn组件
资源管理和任务调度组件
先进入/usr/local/hadoop-2.7.3/etc/hadoop目录
使用命令vim yarn-site.xml进入yarn-site.xml修改配置文件
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop7</value>
</property>
C、使用scp命令
将修改好的mapreduce组件和Yarn组件配置文件用scp命令复制到hadoop8和hadoop9的 /usr/local/hadoop-2.7.3/etc/hadoop目录下。
scp mapred-site.xml root@hadoop8:/usr/local/hadoop-2.7.3/etc/hadoop
scp yarn-site.xml root@hadoop8:/usr/local/hadoop-2.7.3/etc/hadoop
scp mapred-site.xml root@hadoop9:/usr/local/hadoop-2.7.3/etc/hadoop
scp yarn-site.xml root@hadoop9:/usr/local/hadoop-2.7.3/etc/hadoop

5、集群免密配置
每台主机 authorized_keys 文件里面包含的主机(ssh密钥),该主机都能无密码登录,所以只要每台主机的authorized_keys 文件里面都放入其他主机(需要无密码登录的主机)的ssh密钥就行了。
A、每个节点生成ssh密钥
ssh-keygen -t rsa

执行命令后会在家目录下生成.ssh文件夹,里面包含id_rsa和id_rsa.pub两个文件。
注:使用ssh-keygen -t rsa -P '' -f /root/.ssh/id_rsa命令可避免上述交互式操作。
B、拷贝秘钥
- 在主节点上将公钥拷到一个特定文件authorized_keys中。
cp id_rsa.pub authorized_keys
- 将authorized_keys文件拷到下一个节点,并将该节点的ssh密钥id_rsa.pub加入该文件中。
scp authorized_keys root@hadoop8:/root/.ssh/
#登录hadoop8主机
cat id_rsa.pub >> authorized_keys #使用cat追加方式
scp authorized_keys root@hadoop9:/root/.ssh/
#登录hadoop9主机
cat id_rsa.pub >> authorized_keys #再次使用cat追加方式
- 此时hadoop9的authorized_keys文件中拥有了hadoop7/8/9的密钥,再使用scp命令将hadoop9的authorized_keys文件发送到hadoop7和hadoop8覆盖掉原文件。
scp authorized_keys root@hadoop7:/root/.ssh/
scp authorized_keys root@hadoop8:/root/.ssh/
可以使用命令vim authorized_keys查看该文件里面是否有三台主机的密钥。

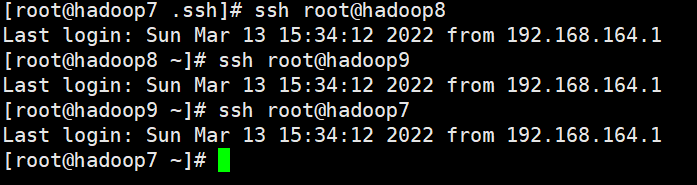
C、验证免密是否成功
使用ssh 用户名@节点名或ssh ip地址 命令验证免密码登录。
6、启动HDFS、YARN
进入目录/usr/local/hadoop-2.7.3/sbin
./start-dfs.sh
./start-yarn.sh
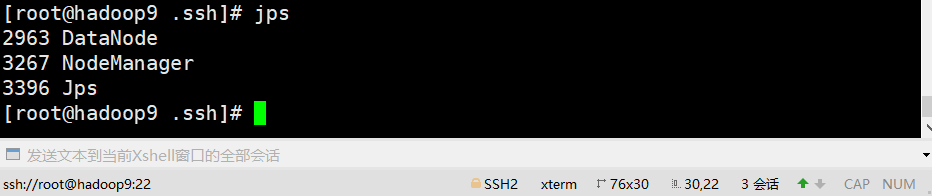
jps #查看进程
主机hadoop7

从机hadoop8
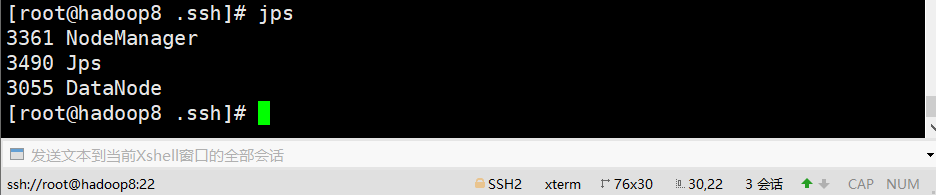
从机hadoop9
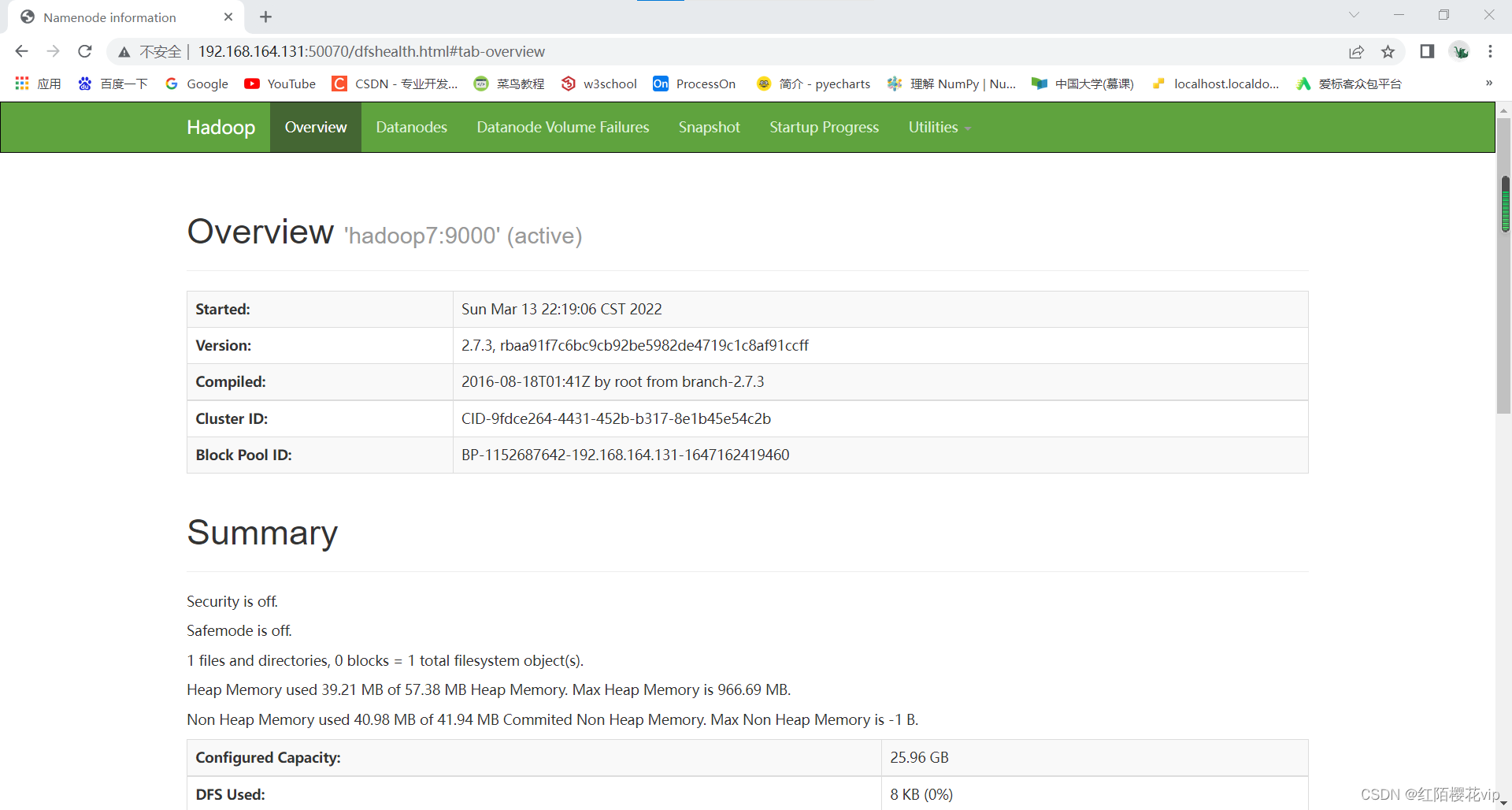
7、查看页面
在浏览器中查看hdfs和yarn的web界面
ip地址:50070

ip地址:8088


二、Spark安装配置
1、上传解压
将spark压缩包上传到Linux的/usr/local目录下并解压。
rz #上传
tar -zxvf spark-2.4.7-bin-hadoop2.7.tgz #解压
rm -rf spark-2.4.7-bin-hadoop2.7.tgz #解压完可以删除压缩包
2、文件配置
切换到spark安装包的/conf目录下,进行配置。

使用cp命令将配置文件复制一份,原文件备份
cp slaves.template slaves
cp spark-defaults.conf.template spark-defaults.conf
cp spark-env.sh.template spark-env.sh

配置slaves文件:
scp slaves root@hadoop8:/usr/local/spark-2.4.7-bin-hadoop2.7/conf
scp slaves root@hadoop9:/usr/local/spark-2.4.7-bin-hadoop2.7/conf
# 将配好的slaves文件发送到hadoop8和hadoop9
配置spark-defaults.conf文件:
hadoop7:
spark.hadoop7 spark://hadoop7:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop7:9000/spark-logs
spark.history.fs.logDirectory hdfs://hadoop7:9000/spark-logs
hadoop8和hadoop9:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop7:9000/spark-logs
spark.history.fs.logDirectory hdfs://hadoop7:9000/spark-logs
配置spark-env.sh文件:
# 结尾添加
export JAVA_HOME=/usr/local/jdk1.8.0_144
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.3/etc/hadoop
export SPARK_MASTER_IP=hadoop7
3、启动hadoop集群
cd /usr/local/hadoop-2.7.3/sbin
./start-all.sh
# 创建spark-logs目录
hdfs dfs -mkdir /spark-logs


cd /usr/local/spark-2.4.7-bin-hadoop2.7/sbin # 进入spark的/sbin目录下
./start-all.sh # 启动集群命令
启动后主节点jps进程:

从节点jps进程:

4、在web界面访问主节点
IP地址:8080

5、测试spark-shell和spark-sql
cd /usr/local/spark-2.4.7-bin-hadoop2.7/bin # 进入spark的/bin目录下
# 启动命令
./spark-shell # 退出spark-shell命令“:quit”
./spark-sql # 退出spark-sql命令“quit;”


三、 Flink安装配置
1、安装 Flink
进入下载页面。选择一个与你的Hadoop版本相匹配的Flink包。
下载后上传到主节点上,并解压:
tar -zxvf apache-flink-1.10.2.tar.gz
rm -rf apache-flink-1.10.2.tar.gz
mv apache-flink-1.10.2 flink
2、配置 Flink
cd /usr/local/flink/deps/conf
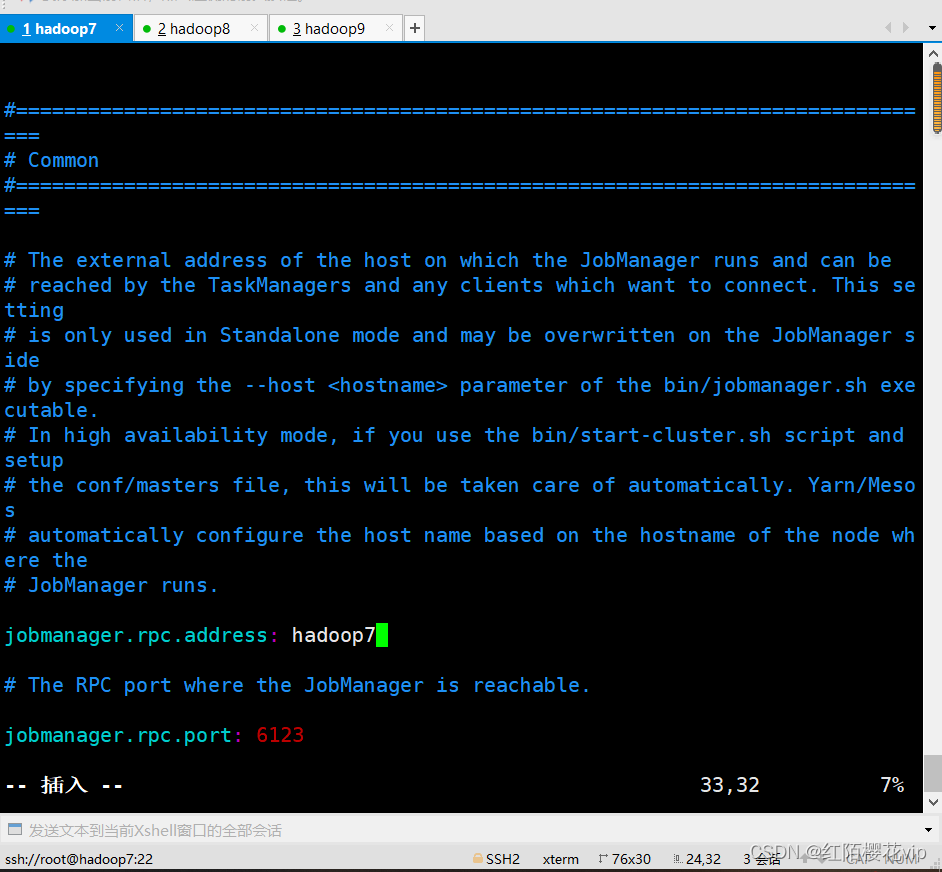
设置
jobmanager.rpc.address
配置项为你的master节点地址。另外为了明确 JVM 在每个节点上所能分配的最大内存,我们需要配置
jobmanager.heap.mb
和
taskmanager.heap.mb
,值的单位是 MB。如果对于某些worker节点,你想要分配更多的内存给Flink系统,你可以在相应节点上设置
FLINK_TM_HEAP
环境变量来覆盖默认的配置。
A、配置zoo.cfg
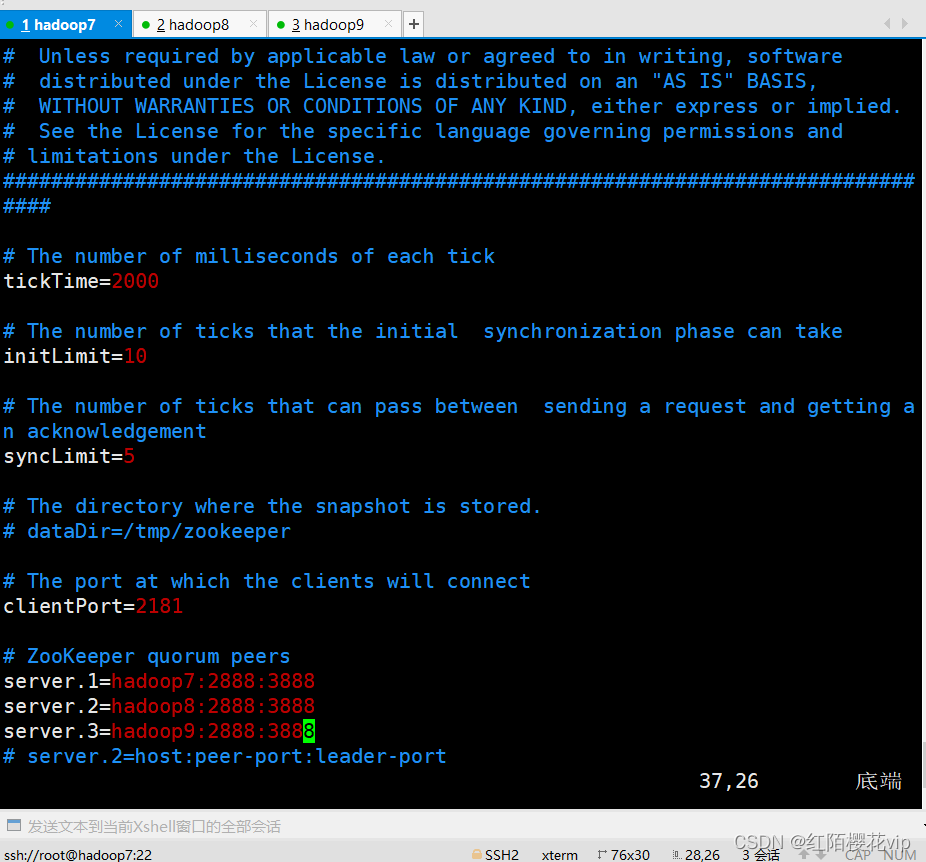
B、配置slaves
最后,你需要提供一个集群中worker节点的列表。因此,就像配置HDFS,编辑conf/slaves文件,然后输入每个worker节点的 IP/Hostname。每一个worker结点之后都会运行一个 TaskManager。
每一条记录占一行,就像下面展示的一样:
C、配置flink-conf.yaml
D、配置masters
每一个worker节点上的 Flink 路径必须一致。你可以使用共享的 NSF 目录,或者拷贝整个 Flink 目录到各个worker节点。
cd /usr/local
scp -r flink root@hadoop8:/usr/local
scp -r flink root@hadoop9:/usr/local
注意:
- TaskManager 总共能使用的内存大小(
taskmanager.heap.mb) - 每一台机器上能使用的 CPU 个数(
taskmanager.numberOfTaskSlots) - 集群中的总 CPU 个数(
parallelism.default) - 临时目录(
taskmanager.tmp.dirs)
3、启动 Flink
下面的脚本会在本地节点启动一个 JobManager,然后通过 SSH 连接所有的worker节点(slaves文件中所列的节点),并在每个节点上运行 TaskManager。现在你的 Flink 系统已经启动并运行了。跑在本地节点上的 JobManager 现在会在配置的 RPC 端口上监听并接收任务。
在主节点flink的bin目录下:
./start-cluster.sh
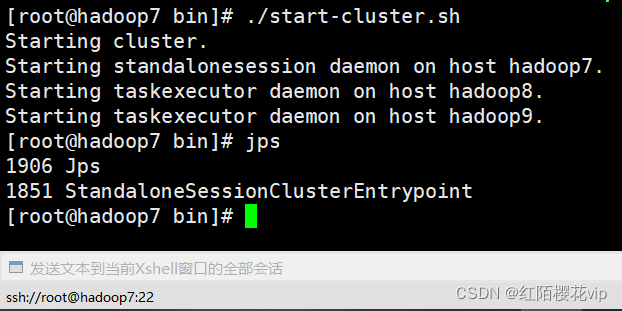
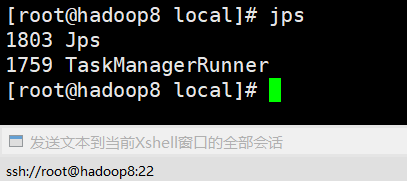
如上图flink集群进程启动成功,也可以通过web界面验证,flink端口号8081


4、添加实例到集群中
添加一个 JobManager
./jobmanager.sh (start cluster)|stop|stop-all
添加一个 TaskManager
./taskmanager.sh start|stop|stop-all
四、Kafka安装配置
1、安装zookeeper
A、上传解压
将zookeeper压缩包上传到/usr/local目录下并解压
rz # 上传
tar -zxvf zookeeper-3.4.12.tar.gz # 解压
B、修改配置文件
进入zookeeper的配置文件目录,并查看该目录下的文件:
cd /usr/local/zookeeper-3.4.12/conf
ll

该目录下有示例配置文件zoo_sample.cfg,将其拷贝为zoo.cfg:
cp zoo_sample.cfg zoo.cfg
使用vim编辑配置文件zoo.cfg:
vim zoo.cfg
更改配置文件内容为下图:

在/usr/local/zookeeper-3.4.12目录下创建tmp文件
cd /usr/local/zookeeper-3.4.12
mkdir tmp
在/usr/local/zookeeper-3.4.12/tmp目录下创建myid文件
cd /usr/local/zookeeper-3.4.12/tmp
vim myid
保存退出,使用scp将/usr/local下的zookeeper-3.4.12远程拷贝到hadoop8和hadoop9主机的/usr/local目录下:
scp -r zookeeper-3.4.12 root@hadoop8:/usr/local
scp -r zookeeper-3.4.12 root@hadoop9:/usr/local
如下图所示,拷贝完成:
将myid文件的内容更改为各自主机对应的server号。
在hadoop7的myid中添加以下内容:
1
在hadoop8的myid中添加以下内容:
2
在hadoop9的myid中添加以下内容:
3
C、配置环境变量
vim /etc/profile (配置如下图,在原有的基础上添加zookeeper环境变量,hadoop7/8/9都要配)
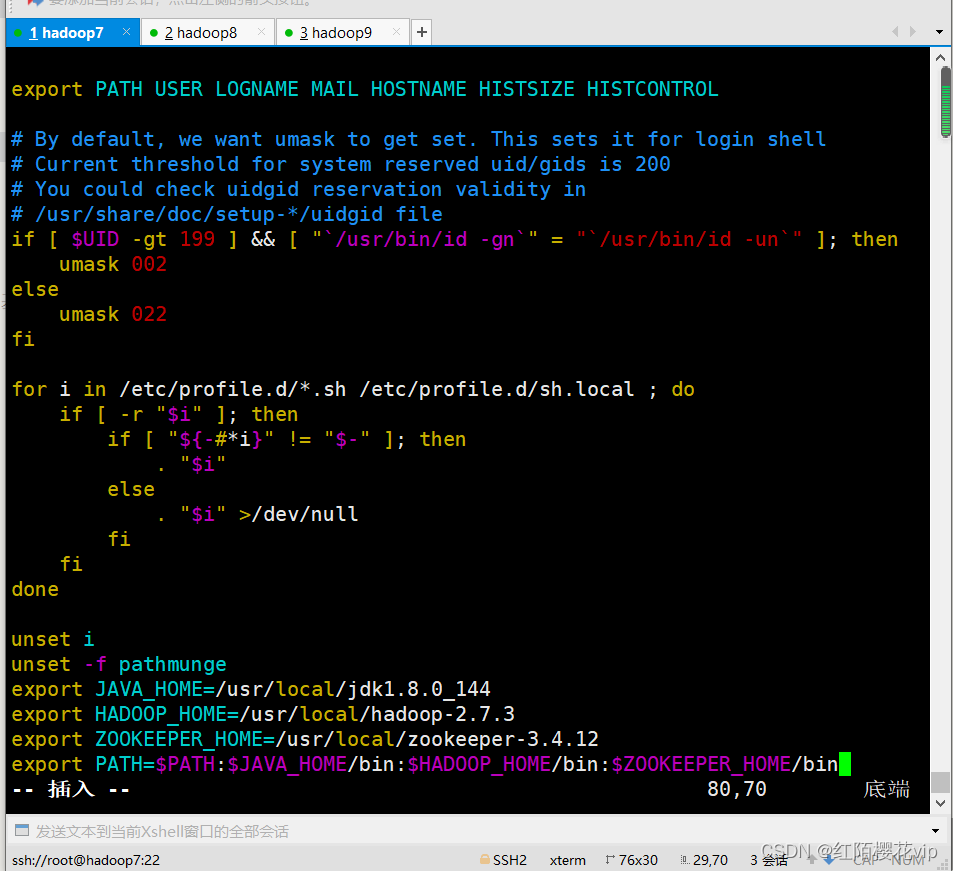
source /etc/profile # 使配置立即生效,不用重启
D、启动
分别进入三台主机的/usr/local/zookeeper-3.4.12/bin目录下,执行启动脚本:
cd /usr/local/zookeeper-3.4.12/bin
./zkServer.sh start

E、查看状态
zkServer.sh status
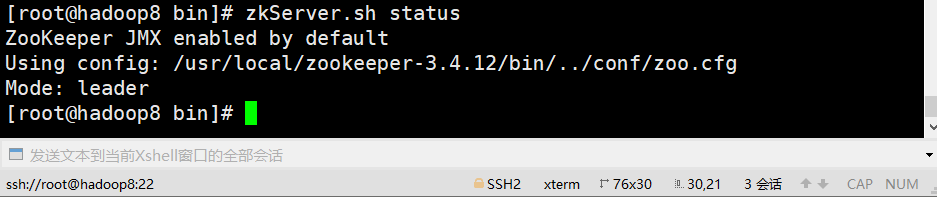
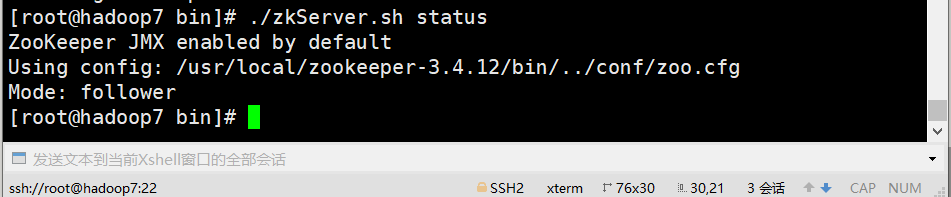
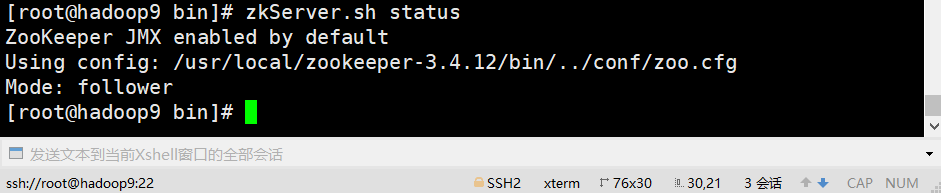
2、安装kafka
A、上传解压
将下载好的kafka压缩包上传到/usr/local目录下
rz # 上传
tar -zxvf kafka_2.11-2.0.0.tgz # 解压
rm -rf kafka_2.11-2.0.0.tgz # 删除压缩包
mv kafka_2.11-2.0.0 kafka #改名
scp -r kafka root@hadoop8:/usr/local # 将解压改名好的kafka发送到hadoop8和hadoop9,也可使用rz命令在hadoop8和hadoop9重复上面几步操作
B、启动zookeeper集群
分别进入三台主机的/usr/local/zookeeper-3.4.12/bin目录下,执行启动脚本:
cd /usr/local/zookeeper-3.4.12/bin
./zkServer.sh start
C、修改配置文件
进入/usr/local/kafka/config目录下修改server.properties配置文件
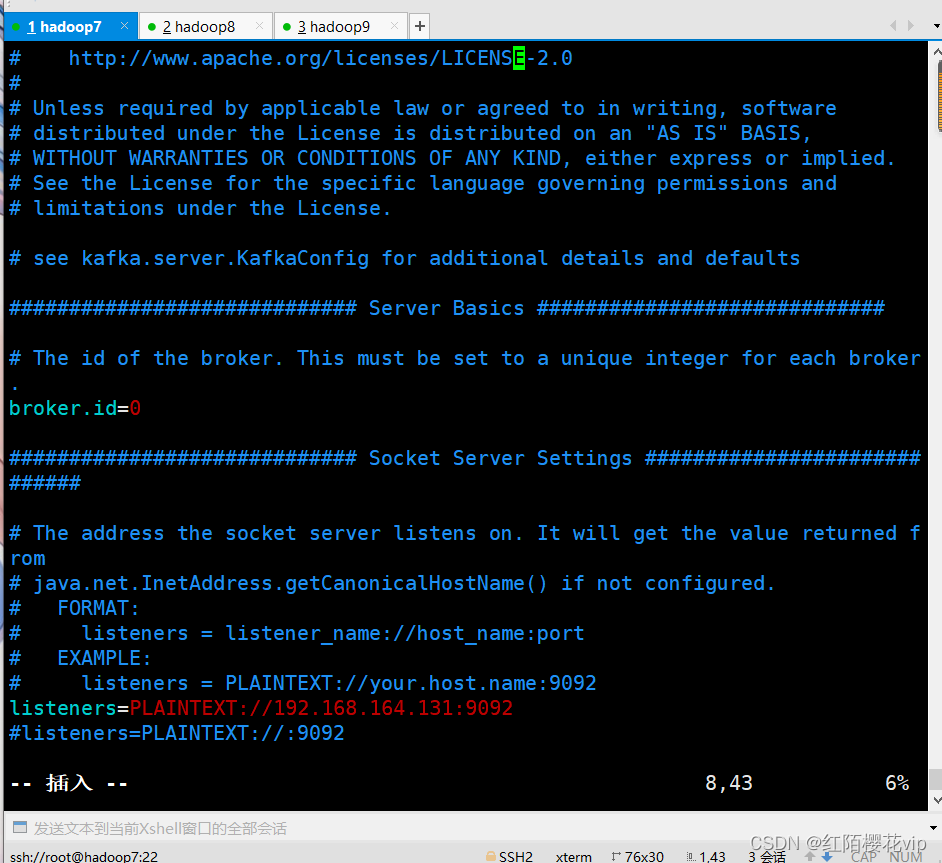


server.properties配置文件的修改主要在开头和结尾,中间保持默认配置即可;需要注意的点是broker.id的值三个节点要配置不同的值,分别配置为0,1,2;log.dirs必须保证目录存在,自己去创建一个,不会根据配置文件自动生成;
scp server.properties root@hadoop8:/usr/local/kafka/config #使用scp命令将配置好的文件发送到其他节点,然后修改其他节点的broker.id
还需要注意的是:因为hadoop8和hadoop9的kafka是通过scp发送的,所以除了要自己去修改主机和从机的broker.id还要自己去修改下图配置,改成从机对应的IP地址。


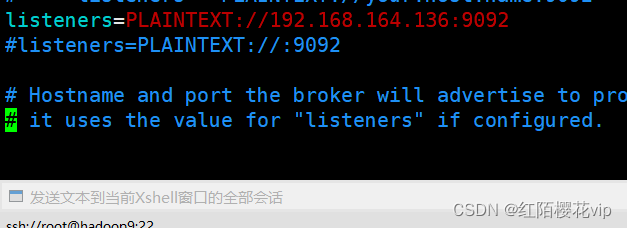
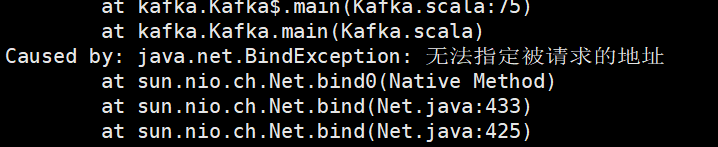
不然主机启动没问题,从机会遇到下图的问题:
(我一开始就没注意,然后从机报错启动不了,去百度看了有一会才改正错误)
D、启动kafka
启动kafka集群,进入kafka的bin目录,执行如下命令 :
./kafka-server-start.sh /usr/local/kafka/config/server.properties
# 三个节点均要启动;启动无报错,即搭建成功,可以生产和消费消息,来检测是否搭建成功。

E、常见kafka命令
# 创建topic–test
./bin/kafka-topics.sh --create --zookeeper IP地址:2181, IP地址:2181, IP地址:2181 --replication-factor 3 --partitions 3 --topic test
# 列出已创建的topic列表
./bin/kafka-topics.sh --list --zookeeper hadoop7:2181
# 更多:https://blog.csdn.net/zxy987872674/article/details/72493128
五、Flume安装配置
1、上传解压
rz
tar -zxvf apache-flume-1.8.0-bin.tar.gz
mv apache-flume-1.8.0-bin flume
2、配置环境变量
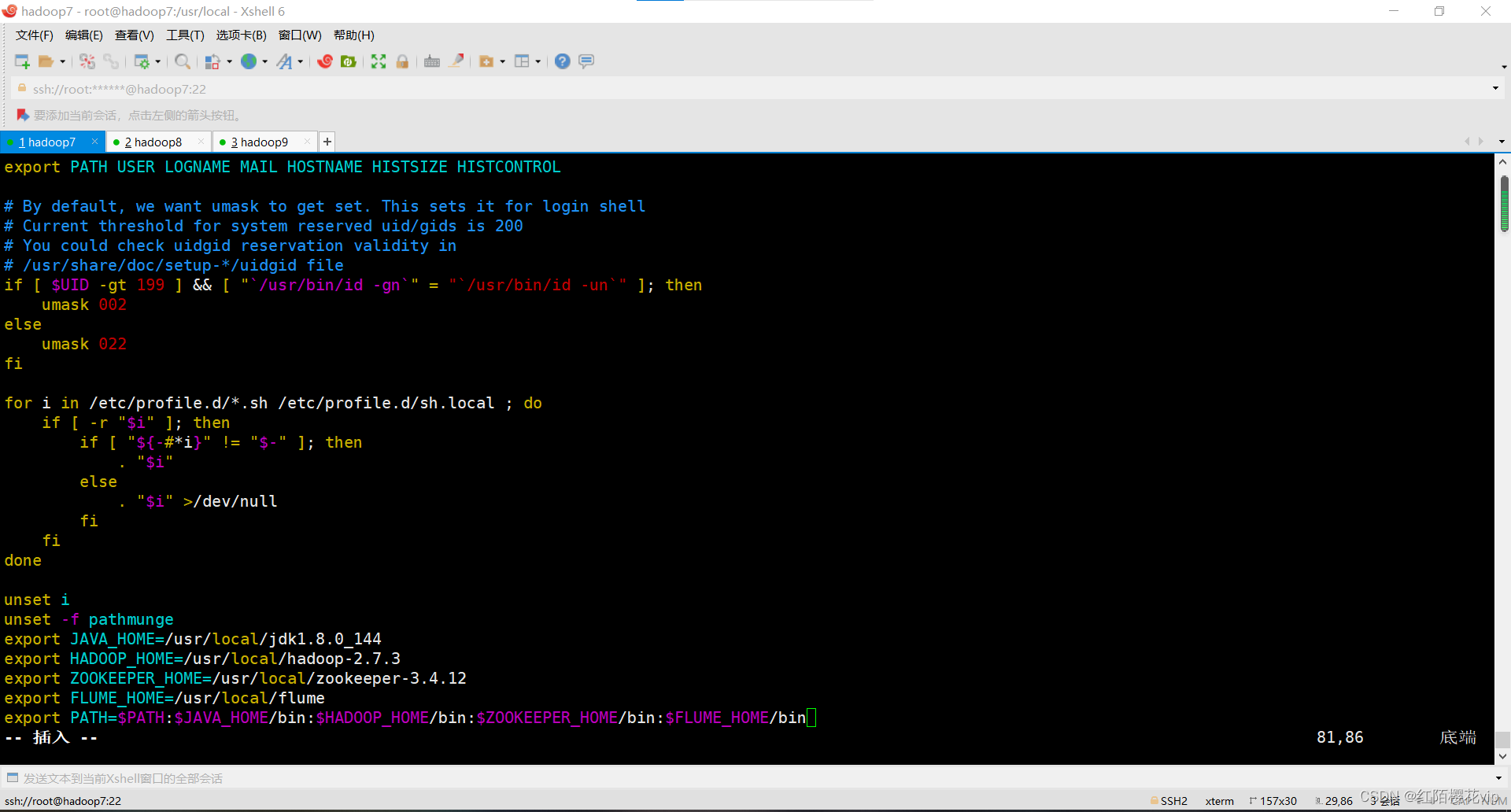
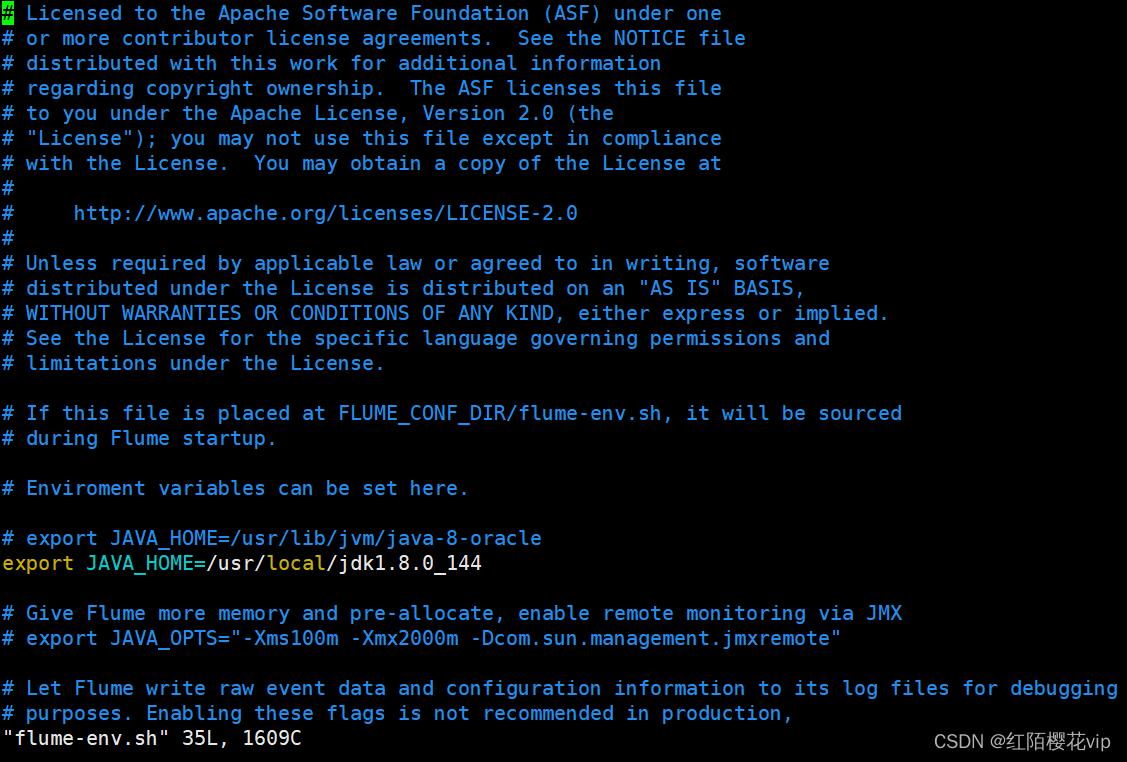
然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
3、测试是否安装成功
使用命令flume-ng version
如下图则成功:

继续测试:
1、先在flume的conf目录下新建一个文件
vim netcat-logger.conf
定义这个agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1描述和配置source组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444描述和配置sink组件:k1
a1.sinks.k1.type = logger
描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100描述和配置source channel sink之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 在Flume安装目录下启动agent去采集数据
/usr/local/flume/bin/flume-ng agent -c conf -f /usr/local/flume/conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
3.测试
再开一shell窗口 输入以下命令
telnet localhost 44444
注意: 如出现找不到这个命令 则是没有安装 telnet 服务
就去安装一下 再来执行上面的命令
六、各压缩包链接地址
hadoop:Index of /hadoop/core
jdk:Java Downloads | Oracle
spark:Index of /spark
flink:Index of /flink
zookeeper:Index of /zookeeper
kafka:Index of /kafka
flume:Index of /flume
版权归原作者 红陌樱花vip 所有, 如有侵权,请联系我们删除。