
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2-1)
27、Flink 的SQL之SELECT (窗口函数 和 窗口聚合)介绍及详细示例(3)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(6)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
本文介绍了Flink 的hints及具体的运行示例。
本文依赖flink和kafka集群能正常使用。
本文示例实在flink 1.17版本上运行的。
注意:其中官网上说有些不支持的功能,通过验证是可以使用的,可能是官网版本说明与实际发行的版本不一致?或本人没有理解其中的含义。
一、SQL Hints
SQL Hints是和 SQL 语句一起使用来改变执行计划的。本文介绍如何使用 SQL 提示来实现各种干预。
SQL 提示一般可以用于以下:
- 增强 planner:没有完美的 planner,所以实现 SQL 提示让用户更好地控制执行是非常有意义的;
- 增加元数据(或者统计信息):如"已扫描的表索引"和"一些混洗键(shuffle keys)的倾斜信息"的一些统计数据对于查询来说是动态的,用- 提示来配置它们会非常方便,因为我们从 planner 获得的计划元数据通常不那么准确;
- 算子(Operator)资源约束:在许多情况下,我们会为执行算子提供默认的资源配置,即最小并行度或托管内存(UDF 资源消耗)或特殊资源需求(GPU 或 SSD 磁盘)等,可以使用 SQL 提示非常灵活地为每个查询(非作业)配置资源。
1、动态表(Dynamic Table)选项
动态表选项允许动态地指定或覆盖表选项,不同于用 SQL DDL 或 连接 API 定义的静态表选项,这些选项可以在每个查询的每个表范围内灵活地指定。
因此,它非常适合用于交互式终端中的特定查询,例如,在 SQL-CLI 中,你可以通过添加动态选项/*+ OPTIONS(‘csv.ignore-parse-errors’=‘true’) */来指定忽略 CSV 源的解析错误。
1)、语法
为了不破坏 SQL 兼容性,我们使用 Oracle 风格的 SQL hints 语法:
table_path /*+ OPTIONS(key=val [, key=val]*) */key:
stringLiteral
val:
stringLiteral
2)、官方示例
关于kafka表属性请参考文章:16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
CREATETABLE kafka_table1 (id BIGINT, name STRING, age INT)WITH(...);CREATETABLE kafka_table2 (id BIGINT, name STRING, age INT)WITH(...);--------建表CREATETABLE alan_user_t1 (`id`INT,
name STRING,
age BIGINT)WITH('connector'='kafka','topic'='alan_user_t1_topic','scan.startup.mode'='earliest-offset','properties.bootstrap.servers'='192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092','format'='csv');CREATETABLE alan_user_t2 (`id`INT,
name STRING,
age BIGINT)WITH('connector'='kafka','topic'='alan_user_t2_topic','scan.startup.mode'='earliest-offset','properties.bootstrap.servers'='192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092','format'='csv');# 需要设置动态表的选项可用与flink版本有关settable.dynamic-table-options.enabled =true;--1、 覆盖查询语句中源表的选项# 由于数据量较少或验证环境准备不充足,不足以体现出来验证效果select id, name from kafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */;----------验证# kafka 发送数据[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic alan_user_t1_topic>1,'alan',18>2,'alanchan',19>3,'alanchanchn',20# flink sql查询
Flink SQL>select*from alan_user_t1 /*+ OPTIONS('scan.startup.mode'='latest-offset') */;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |1|'alan'|18||+I |2|'alanchan'|19||+I |3|'alanchanchn'|20|-- 覆盖 join 中源表的选项
Flink SQL>select*from alan_user_t1;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |1|'alan'|18||+I |2|'alanchan'|19||+I |3|'alanchanchn'|20|
Flink SQL>select*from alan_user_t2;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |1|'alan'|18||+I |3|'alanchanchn'|20||+I |4|'alan_chan'|19|select*from
alan_user_t1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t1
join
alan_user_t2 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t2
on t1.id = t2.id;
Flink SQL>select*from> alan_user_t1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t1
>join> alan_user_t2 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t2
>on t1.id = t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20|-- 覆盖插入语句中结果表的选项insertinto alan_user_t1 /*+ OPTIONS('sink.partitioner'='round-robin') */select*from alan_user_t2;
Flink SQL>insertinto alan_user_t1 /*+ OPTIONS('sink.partitioner'='round-robin') */select*from alan_user_t2;
Job ID: 153dd7f1e3b187a93103de8da445521e
Flink SQL>select*from alan_user_t1;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |1|'alan'|18||+I |2|'alanchan'|19||+I |3|'alanchanchn'|20||+I |1|'alan'|18||+I |3|'alanchanchn'|20||+I |4|'alan_chan'|19|
3)、示例二-忽略数据格式错误
CREATETABLE alan_user_t1 (`id`INT,
name STRING,
age BIGINT)WITH('connector'='kafka','topic'='alan_user_t1_topic','scan.startup.mode'='earliest-offset','properties.bootstrap.servers'='192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092','format'='csv');----------------需要设置动态表的选项可用与flink版本有关settable.dynamic-table-options.enabled =true;--------------flink sql 查询
Flink SQL>select*from alan_user_t1;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |1|'alan'|18||+I |2|'alanchan'|19|------------kafka 发送消息[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic alan_user_t1_topic>1,'alan',18>2,'alanchan',19>{ "id":"1","name":"alan","age":"18" }
---------验证# 1、在kafka中发送数据,根据表结构定义的是csv文件,如果发送csv格式的数据,则flink sql 能正常的显示;如果发送的是json格式的数据,则任务会出现错误,flink sql 的客户端则不会显示json的数据,并且该任务不会终止,即便后续发送的数据是正确的,也不会恢复。# 2、加上选项'csv.ignore-parse-errors'='true',忽略cvs解析错误,再次查询# 解析正确的数据,flink sql可以正常的显示;如果是非正常格式的数据,则不会显示且任务也不会出现异常(直接忽略),后续收到正确格式的数据可以正常运行,即可以通过sql查询出来。下述中的kafka发送的json数据没有显示出来,任务也没有报错。
Flink SQL>select*from alan_user_t1 /*+ OPTIONS('csv.ignore-parse-errors'='true') */;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |1|'alan'|18||+I |2|'alanchan'|19||+I |3|'alanchanchn'|20|# kafka发送数据,其中第三条数据是错误的[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic alan_user_t1_topic>1,'alan',18>2,'alanchan',19>{ "id":"1","name":"alan","age":"18" }
>3,'alanchanchn',20
2、查询提示
查询提示(Query Hints)用于为优化器修改执行计划提供建议,该修改只能在当前查询提示所在的查询块中生效(Query block)。 目前,Flink 查询提示只支持联接提示(Join Hints)。
1)、查询块介绍
查询块(query block)是 SQL 语句的一个基础组成部分。例如,SQL 语句中任何的内联视图或者子查询(sub-query)都可以被当作外部查询的查询块。
一个 SQL 语句可以由多个子查询组成,子查询可以是一个 SELECT,INSERT 或者 DELETE。子查询中又可以在 FROM 子句,WHERE 子句或者 在 UNION/UNION ALL 的子 SELECT 语句中包含其他的子查询。
对于不同类型的子查询,他们可以由多个查询块组成,例如:
下面的查询语句由两个查询块组成:一个是 WHERE 子句中的 SELECT,另一个是外层的 SELECT。
下面的查询语句是一个 UNION 查询,其由两个查询块组成:一个 UNION 前的 SELECT, 另一个是 UNION 后的 SELECT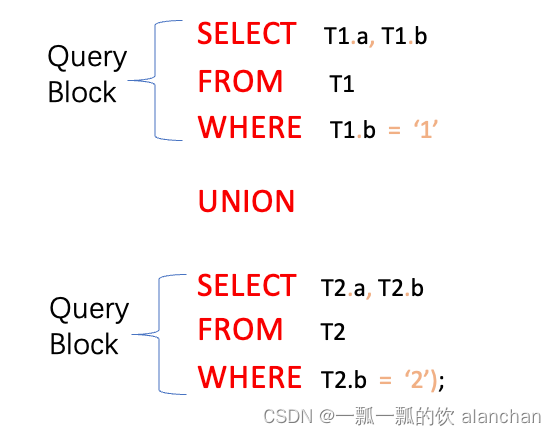
下面的查询语句包含 视图(View),其包含两个查询块:一个是外层的 SELECT,另一个是视图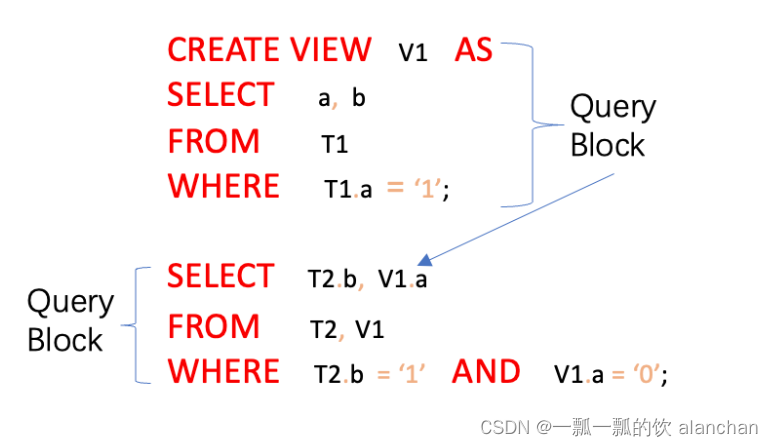
2)、语法
Flink 中的查询提示语法与 Apache Calcite 的语法一致:
# Query hints:SELECT/*+ hint [, hint ] */...
hint:
hintName
| hintName '(' optionKey '=' optionVal [, optionKey '=' optionVal ]*')'| hintName '(' hintOption [, hintOption ]*')'
optionKey:
simpleIdentifier
| stringLiteral
optionVal:
stringLiteral
hintOption:
simpleIdentifier
| numericLiteral
| stringLiteral
3)、联接提示
联接提示(Join Hints)是查询提示(Query Hints)的一种,该提示允许用户手动指定表联接(join)时使用的联接策略,来达到优化执行的目的。Flink 联接提示现在支持 BROADCAST, SHUFFLE_HASH,SHUFFLE_MERGE 和 NEST_LOOP。
1、联接提示中定义的表必须存在,否则,将会报表不存在的错误。
2、Flink 联接提示在一个查询块(Query Block)中只支持定义一个提示块,如果定义了多个提示块,类似 /*+ BROADCAST(t1) / /+ SHUFFLE_HASH(t1) /,则在 SQL 解析时会报错。
3、在同一个提示块中,Flink 支持在一个联接提示中定义多个表如:/+ BROADCAST(t1, t2, …, tn) / 或者定义多个联接提示如:/+ BROADCAST(t1), BROADCAST(t2), …, BROADCAST(tn) */。
4、对于上述的在一个联接提示中定义多个表或定义多个联接提示的例子,联接提示可能产生冲突。如果冲突产生,Flink 会选择最匹配的表或者联接策略。(详见: 联接提示使用中的冲突)
1、BROADCAST广播及示例
BROADCAST 推荐联接使用 BroadCast 策略。如果该联接提示生效,不管是否设置了 table.optimizer.join.broadcast-threshold, 指定了联接提示的联接端(join side)都会被广播到下游。所以当该联接端是小表时,更推荐使用 BROADCAST。
本部分是在flink 1.17版本中执行的,环境配置需要准备好,比如本示例中使用的是Kafka。
BROADCAST 只支持等值的联接条件,且不支持 Full Outer Join。
下面示例中,官方文档说不支持非等值连接条件,也不支持 Full Outer Join ,通过验证来看,1.17版本是支持的,估计是官方文档更新存在错误吧。
CREATETABLE t1 (id BIGINT, name STRING, age INT)WITH(...);CREATETABLE t2 (id BIGINT, name STRING, age INT)WITH(...);CREATETABLE t3 (id BIGINT, name STRING, age INT)WITH(...);-- Flink 会使用 broadcast join,且表 t1 会被当作需 broadcast 的表。SELECT/*+ BROADCAST(t1) */*FROM t1 JOIN t2 ON t1.id = t2.id;-- Flink 会在两个联接中都使用 broadcast join,且 t1 和 t3 会被作为需 broadcast 到下游的表。SELECT/*+ BROADCAST(t1, t3) */*FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;-- BROADCAST 只支持等值的联接条件-- 联接提示会失效,只能使用支持非等值条件联接的 nested loop join。SELECT/*+ BROADCAST(t1) */*FROM t1 join t2 ON t1.id > t2.id;-- BROADCAST 不支持 `Full Outer Join`-- 联接提示会失效,planner 会根据 cost 选择最合适的联接策略。SELECT/*+ BROADCAST(t1) */*FROM t1 FULLOUTERJOIN t2 ON t1.id = t2.id;------------验证-----------------# 1、建表CREATETABLE alan_user_t1 (`id`INT,
name STRING,
age BIGINT)WITH('connector'='kafka','topic'='alan_user_t1_topic','scan.startup.mode'='earliest-offset','properties.bootstrap.servers'='192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092','format'='csv');CREATETABLE alan_user_t2 (`id`INT,
name STRING,
age BIGINT)WITH('connector'='kafka','topic'='alan_user_t2_topic','scan.startup.mode'='earliest-offset','properties.bootstrap.servers'='192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092','format'='csv');CREATETABLE alan_user_t3 (`id`INT,
name STRING,
age BIGINT)WITH('connector'='kafka','topic'='alan_user_t3_topic','scan.startup.mode'='earliest-offset','properties.bootstrap.servers'='192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092','format'='csv');# 2、写入数据并查询
Flink SQL>select*from alan_user_t1;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |1|'alan'|18||+I |2|'alanchan'|19||+I |3|'alanchanchn'|20||+I |1|'alan'|18||+I |3|'alanchanchn'|20||+I |4|'alan_chan'|19|
Flink SQL>select*from alan_user_t2;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |1|'alan'|18||+I |3|'alanchanchn'|20||+I |4|'alan_chan'|19|
Flink SQL>select*from alan_user_t3;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |6|'alan'|28||+I |6|'alan'|28||+I |8|'alanchan'|29||+I |9|'ALAN'|30||+I |2|'alanchan'|19||+I |3|'alanchanchn'|20|# 3、验证 Flink 会使用 broadcast join,且表 t1 会被当作需 broadcast 的表
Flink SQL>SELECT alan_user_t1.*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |1|'alan'|18||+I |1|'alan'|18||+I |3|'alanchanchn'|20||+I |3|'alanchanchn'|20||+I |4|'alan_chan'|19|
Flink SQL>SELECT/*+ BROADCAST(alan_user_t1) */ alan_user_t1.*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |1|'alan'|18||+I |3|'alanchanchn'|20||+I |1|'alan'|18||+I |3|'alanchanchn'|20||+I |4|'alan_chan'|19|# 4、验证 Flink 会在两个联接中都使用 broadcast join,且 t1 和 t3 会被作为需 broadcast 到下游的表。
Flink SQL>SELECT alan_user_t1.*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id JOIN alan_user_t3 ON alan_user_t1.id = alan_user_t3.id;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |3|'alanchanchn'|20||+I |3|'alanchanchn'|20|
Flink SQL>SELECT/*+ BROADCAST(alan_user_t1, alan_user_t3) */ alan_user_t1.*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id JOIN alan_user_t3 ON alan_user_t1.id = alan_user_t3.id;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |3|'alanchanchn'|20||+I |3|'alanchanchn'|20|# 5、验证 BROADCAST 只支持等值的联接条件-- 联接提示会失效,只能使用支持非等值条件联接的 nested loop join-- 会提示失效的说法好像不对,目前运行结果如下
Flink SQL>SELECT alan_user_t1.*FROM alan_user_t1 join alan_user_t2 ON alan_user_t1.id > alan_user_t2.id;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |3|'alanchanchn'|20||+I |3|'alanchanchn'|20||+I |2|'alanchan'|19||+I |4|'alan_chan'|19||+I |4|'alan_chan'|19|^CQuery terminated, received a total of5rows
Flink SQL>SELECT/*+ BROADCAST(alan_user_t1) */ alan_user_t1.*FROM alan_user_t1 join alan_user_t2 ON alan_user_t1.id > alan_user_t2.id;+----+-------------+--------------------------------+----------------------+| op | id | name | age |+----+-------------+--------------------------------+----------------------+|+I |3|'alanchanchn'|20||+I |3|'alanchanchn'|20||+I |2|'alanchan'|19||+I |4|'alan_chan'|19||+I |4|'alan_chan'|19|# 5、验证 BROADCAST 不支持 `Full Outer Join`-- 联接提示会失效,planner 会根据 cost 选择最合适的联接策略。-- 会提示失效的说法好像不对,目前运行结果如下
Flink SQL>SELECT*FROM alan_user_t1 FULLOUTERJOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |1|'alan'|18|<NULL>|<NULL>|<NULL>||+I |2|'alanchan'|19|<NULL>|<NULL>|<NULL>||+I |3|'alanchanchn'|20|<NULL>|<NULL>|<NULL>||+I |1|'alan'|18|<NULL>|<NULL>|<NULL>||+I |3|'alanchanchn'|20|<NULL>|<NULL>|<NULL>||+I |4|'alan_chan'|19|<NULL>|<NULL>|<NULL>||-D |1|'alan'|18|<NULL>|<NULL>|<NULL>||-D |1|'alan'|18|<NULL>|<NULL>|<NULL>||+I |1|'alan'|18|1|'alan'|18||+I |1|'alan'|18|1|'alan'|18||-D |3|'alanchanchn'|20|<NULL>|<NULL>|<NULL>||-D |3|'alanchanchn'|20|<NULL>|<NULL>|<NULL>||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||-D |4|'alan_chan'|19|<NULL>|<NULL>|<NULL>||+I |4|'alan_chan'|19|4|'alan_chan'|19|^CQuery terminated, received a total of16rows
Flink SQL>SELECT/*+ BROADCAST(alan_user_t1) */*FROM alan_user_t1 FULLOUTERJOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |<NULL>|<NULL>|<NULL>|1|'alan'|18||+I |<NULL>|<NULL>|<NULL>|3|'alanchanchn'|20||+I |<NULL>|<NULL>|<NULL>|4|'alan_chan'|19||-D |<NULL>|<NULL>|<NULL>|1|'alan'|18||+I |1|'alan'|18|1|'alan'|18||+I |2|'alanchan'|19|<NULL>|<NULL>|<NULL>||-D |<NULL>|<NULL>|<NULL>|3|'alanchanchn'|20||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||-D |<NULL>|<NULL>|<NULL>|4|'alan_chan'|19||+I |4|'alan_chan'|19|4|'alan_chan'|19|
2、SHUFFLE_HASH及示例
SHUFFLE_HASH 推荐联接使用 Shuffle Hash 策略。如果该联接提示生效,指定了联接提示的联接端将会被作为联接的 build 端。 该提示在被指定的表较小(相较于 BROADCAST,小表的数据量更大)时,表现得更好。
SHUFFLE_HASH 只支持等值的联接条件
下面示例中,官方文档说不支持非等值连接条件,通过验证来看,1.17版本是支持的,估计是官方文档更新存在错误吧。
CREATETABLE t1 (id BIGINT, name STRING, age INT)WITH(...);CREATETABLE t2 (id BIGINT, name STRING, age INT)WITH(...);CREATETABLE t3 (id BIGINT, name STRING, age INT)WITH(...);-- Flink 会使用 hash join,且 t1 会被作为联接的 build 端。SELECT/*+ SHUFFLE_HASH(t1) */*FROM t1 JOIN t2 ON t1.id = t2.id;-- Flink 会在两个联接中都使用 hash join,且 t1 和 t3 会被作为联接的 build 端。SELECT/*+ SHUFFLE_HASH(t1, t3) */*FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;-- SHUFFLE_HASH 只支持等值联接条件-- 联接提示会失效,只能使用支持非等值条件联接的 nested loop join。SELECT/*+ SHUFFLE_HASH(t1) */*FROM t1 join t2 ON t1.id > t2.id;---------------验证------------# 1、建表-- 参考上面关于广播的示例# 2、插入数据并查询-- 参考上面关于广播的示例# 3、验证 Flink 会使用 hash join,且 t1 会被作为联接的 build 端
Flink SQL>SELECT/*+ SHUFFLE_HASH(alan_user_t1) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |1|'alan'|18|1|'alan'|18||+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |4|'alan_chan'|19|4|'alan_chan'|19|# 4、验证 Flink 会在两个联接中都使用 hash join,且 t1 和 t3 会被作为联接的 build 端
Flink SQL>SELECT/*+ SHUFFLE_HASH(alan_user_t1, alan_user_t3) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id JOIN alan_user_t3 ON alan_user_t1.id = alan_user_t3.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 | id1 | name1 | age1 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |3|'alanchanchn'|20|3|'alanchanchn'|20|3|'alanchanchn'|20||+I |3|'alanchanchn'|20|3|'alanchanchn'|20|3|'alanchanchn'|20|# 5、验证 SHUFFLE_HASH 只支持等值联接条件-- 联接提示会失效,只能使用支持非等值条件联接的 nested loop join-- 没有提示失效,运行结果如下
Flink SQL>SELECT/*+ SHUFFLE_HASH(alan_user_t1) */*FROM alan_user_t1 join alan_user_t2 ON alan_user_t1.id > alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |3|'alanchanchn'|20|1|'alan'|18||+I |3|'alanchanchn'|20|1|'alan'|18||+I |2|'alanchan'|19|1|'alan'|18||+I |4|'alan_chan'|19|1|'alan'|18||+I |4|'alan_chan'|19|3|'alanchanchn'|20|
3、SHUFFLE_MERGE及示例
SHUFFLE_MERGE 推荐联接使用 Sort Merge 策略。该联接提示适用于联接两端的表数据量都非常大,或者联接两端的表都有序的场景。
SHUFFLE_MERGE 只支持等值的联接条件
下面示例中,官方文档说不支持非等值连接条件,通过验证来看,1.17版本是支持的,估计是官方文档更新存在错误吧。
CREATETABLE t1 (id BIGINT, name STRING, age INT)WITH(...);CREATETABLE t2 (id BIGINT, name STRING, age INT)WITH(...);CREATETABLE t3 (id BIGINT, name STRING, age INT)WITH(...);-- 会使用 sort merge join。SELECT/*+ SHUFFLE_MERGE(t1) */*FROM t1 JOIN t2 ON t1.id = t2.id;-- Sort merge join 会使用在两次不同的联接中。SELECT/*+ SHUFFLE_MERGE(t1, t3) */*FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;-- SHUFFLE_MERGE 只支持等值的联接条件,-- 联接提示会失效,只能使用支持非等值条件联接的 nested loop join。SELECT/*+ SHUFFLE_MERGE(t1) */*FROM t1 join t2 ON t1.id > t2.id;---------------验证------------# 1、建表-- 参考上面关于广播的示例# 2、插入数据并查询-- 参考上面关于广播的示例# 3、验证 会使用 sort merge join
Flink SQL>SELECT/*+ SHUFFLE_MERGE(alan_user_t1) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |1|'alan'|18|1|'alan'|18||+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |4|'alan_chan'|19|4|'alan_chan'|19|# 4、验证 Sort merge join 会使用在两次不同的联接中
Flink SQL>SELECT/*+ SHUFFLE_MERGE(alan_user_t1, alan_user_t3) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id JOIN alan_user_t3 ON alan_user_t1.id = alan_user_t3.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 | id1 | name1 | age1 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |3|'alanchanchn'|20|3|'alanchanchn'|20|3|'alanchanchn'|20||+I |3|'alanchanchn'|20|3|'alanchanchn'|20|3|'alanchanchn'|20|# 5、验证 SHUFFLE_MERGE 只支持等值的联接条件,-- 联接提示会失效,只能使用支持非等值条件联接的 nested loop join。-- 没有提示失效,运行结果如下
Flink SQL>SELECT/*+ SHUFFLE_MERGE(alan_user_t1) */*FROM alan_user_t1 join alan_user_t2 ON alan_user_t1.id > alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |3|'alanchanchn'|20|1|'alan'|18||+I |3|'alanchanchn'|20|1|'alan'|18||+I |2|'alanchan'|19|1|'alan'|18||+I |4|'alan_chan'|19|1|'alan'|18||+I |4|'alan_chan'|19|3|'alanchanchn'|20|
4、NEST_LOOP及示例
NEST_LOOP 推荐联接使用 Nested Loop 策略。如无特殊的场景需求,不推荐使用该类型的联接提示。
NEST_LOOP 同时支持等值的和非等值的联接条件。
CREATETABLE t1 (id BIGINT, name STRING, age INT)WITH(...);CREATETABLE t2 (id BIGINT, name STRING, age INT)WITH(...);CREATETABLE t3 (id BIGINT, name STRING, age INT)WITH(...);-- Flink 会使用 nest loop join,且 t1 会被作为联接的 build 端。SELECT/*+ NEST_LOOP(t1) */*FROM t1 JOIN t2 ON t1.id = t2.id;-- Flink 会在两次联接中都使用 nest loop join,且 t1 和 t3 会被作为联接的 build 端。SELECT/*+ NEST_LOOP(t1, t3) */*FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;---------------验证------------# 1、建表-- 参考上面关于广播的示例# 2、插入数据并查询-- 参考上面关于广播的示例# 3、验证 Flink 会使用 nest loop join,且 t1 会被作为联接的 build 端
Flink SQL>SELECT/*+ NEST_LOOP(alan_user_t1) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |4|'alan_chan'|19|4|'alan_chan'|19|# 4、验证 Flink 会在两次联接中都使用 nest loop join,且 t1 和 t3 会被作为联接的 build 端
Flink SQL>SELECT/*+ NEST_LOOP(alan_user_t1, alan_user_t3) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id JOIN alan_user_t3 ON alan_user_t1.id = alan_user_t3.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 | id1 | name1 | age1 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |3|'alanchanchn'|20|3|'alanchanchn'|20|3|'alanchanchn'|20||+I |3|'alanchanchn'|20|3|'alanchanchn'|20|3|'alanchanchn'|20|
4、LOOKUP
该功能从flink 1.16开始支持。
LOOKUP 联接提示允许用户建议 Flink 优化器:
- 使用同步或异步的查找函数
- 配置异步查找相关参数
- 启用延迟重试查找策略
1)、LOOKUP 提示选项
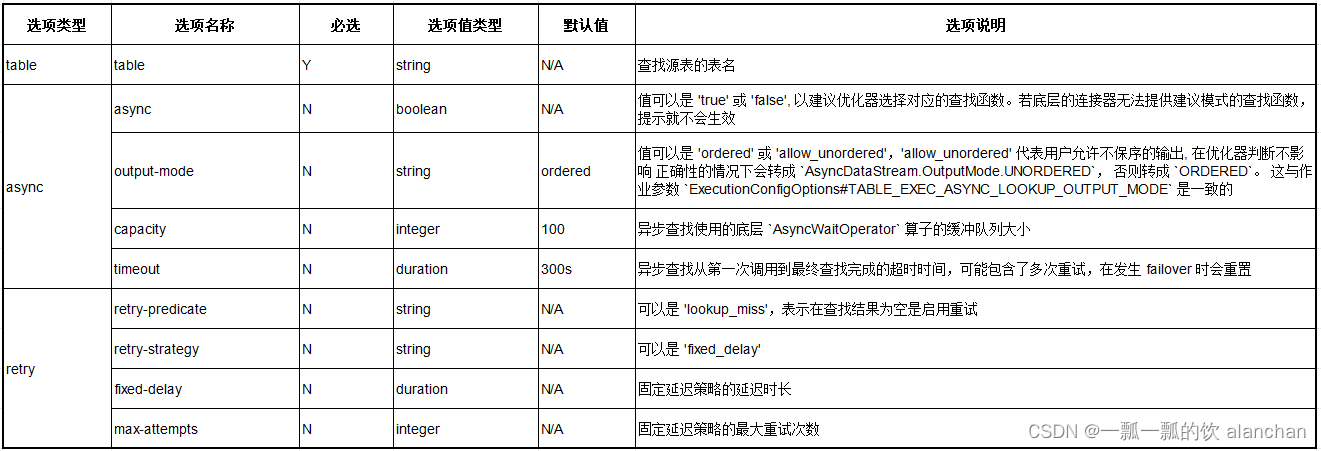
’table’ 是必选项,需要填写目标联接表的表名(和 FROM 子句引用的表名保持一致),注意如果表定义了别名,则提示选项必须使用别名。
异步查找参数可按需设置一个或多个,未设置的参数按默认值生效。
重试查找参数没有默认值,在需要开启时所有参数都必须设置为有效值。
- 使用同步或异步的查找函数 如果连接器同时具备同步和异步查找能力,用户通过给出提示选项值 ‘async’=‘false’ 来建议优化器选择同步查找, 或 ‘async’=‘true’ 来建议选择异步查找。 示例:
-- 建议优化器选择同步查找
LOOKUP('table'='Customers','async'='false')-- 建议优化器选择异步查找
LOOKUP('table'='Customers','async'='true')
当没有指定 ‘async’ 选项值时,优化器优先选择异步查找,在以下两种情况下优化器会选择同步查找:
- 当连接器仅实现了同步查找时
- 用户在参数 ’table.optimizer.non-deterministic-update.strategy’ 上启用了 ‘TRY_RESOLVE’ 模式,并且优化器推断用户查询中存在非确定性更新的潜在风险时
- 配置异步查找相关参数 在异步查找模式下,用户可通过提示选项直接配置异步查找相关参数
联接提示上的异步查找参数和作业级别配置参数的含义是一致的,没有设置的参数值由默认值生效,另一个区别是联接提示作用的范围更小,仅限于当前联接操作中对应联接提示选项设置的表名(未被联接提示作用的其他联接查询不受影响)
示例:
-- 设置异步查找参数 'output-mode', 'capacity', 'timeout', 可按需设置单个或多个参数
LOOKUP('table'='Customers','async'='true','output-mode'='allow_unordered','capacity'='100','timeout'='180s')
例如:作业级别异步查找参数设置为
table.exec.async-lookup.output-mode: ORDERED
table.exec.async-lookup.buffer-capacity:100table.exec.async-lookup.timeout: 180s
那么以下联接提示:
LOOKUP('table'='Customers','async'='true','output-mode'='allow_unordered')
LOOKUP('table'='Customers','async'='true','timeout'='300s')
分别等价于:
LOOKUP('table'='Customers','async'='true','output-mode'='allow_unordered','capacity'='100','timeout'='180s')
LOOKUP('table'='Customers','async'='true','output-mode'='ordered','capacity'='100','timeout'='300s')
- 启用延迟重试查找策略
延迟重试查找希望解决流场景中经常遇到的维表数据更新延迟而不能被流数据正确关联的问题。通过提示选项 ‘retry-predicate’=‘lookup_miss’ 可设置查找结果为空的重试条件,同时设置重试策略参数来开启重试查找功能(同步或异步查找均可),当前仅支持固定延迟重试策略。
固定延迟重试策略参数:
'retry-strategy'='fixed_delay'-- 固定重试间隔'fixed-delay'-- 最大重试次数(从重试执行开始计数,比如最大重试次数设置为 1,则对某个具体查找键的一次查找处理实际最多执行 2 次查找请求)'max-attempts'
示例:
# 开启异步查找重试
LOOKUP('table'='Customers','async'='true','retry-predicate'='lookup_miss','retry-strategy'='fixed_delay','fixed-delay'='10s','max-attempts'='3')# 开启同步查找重试
LOOKUP('table'='Customers','async'='false','retry-predicate'='lookup_miss','retry-strategy'='fixed_delay','fixed-delay'='10s','max-attempts'='3')# 若连接器仅实现了同步或异步中的一种查找能力,‘async’ 提示选项可以省略:
LOOKUP('table'='Customers','retry-predicate'='lookup_miss','retry-strategy'='fixed_delay','fixed-delay'='10s','max-attempts'='3')
2)、开启缓存对重试的影响
FLIP-221 引入了对查找源表的缓存支持, 缓存策略有部分缓存、全部缓存两种,开启全部缓存时(’lookup.cache’=‘FULL’),重试无法起作用(因为查找表被完整缓存,重试查找没有任何实际意义);开启部分缓存时,当一条数据开始查找处理时, 先在本地缓存中查找,如果没找到则通过连接器进行外部查找(如果存在,则立即返回),此时查不到的记录和不开启缓存时一样,会触发重试查找,重试结束时的结果即为最终的查找结果(在部分缓存模式下,更新本地缓存)。
3)、关于查找键及 ‘retry-predicate’=‘lookup_miss’ 重试条件的说明
对不同的连接器,提供的索引查找能力可能是不同的,例如内置的 HBase 连接器,默认仅提供了基于 rowkey 的索引查找能力(未启用二级索引),而对于内置的 JDBC 连接器,默认情况下任何字段都可以被用作索引查找,这是物理存储的特性不同所决定的。 查找键即这里提到的作为索引查找的字段或字段组合,以 lookup join 文档中的示例为例,联接条件 “ON o.customer_id = c.id” 中 c.id 即为查找键
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME ASOF o.proc_time AS c
ON o.customer_id = c.id
如果联接条件改为 “ON o.customer_id = c.id and c.country = ‘US’",即:
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME ASOF o.proc_time AS c
ON o.customer_id = c.id and c.country ='US'
当 Customers 表存储在 MySql 中时,c.id 和 c.country 都会被用作查找键
CREATETEMPORARYTABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING
)WITH('connector'='jdbc','url'='jdbc:mysql://mysqlhost:3306/customerdb','table-name'='customers')
而当 Customers 表存储在 HBase 中时,仅 c.id 会被用作查找键,而 c.country = ‘US’ 会作为剩余的联接条件在查找返回的记录上进一步检查是否满足
CREATETEMPORARYTABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING,PRIMARYKEY(id)NOT ENFORCED
)WITH('connector'='hbase-2.2',...)
相应的,在启用查找结果为空的重试条件和对应的固定间隔重试策略时,上述查询在不同的存储上的重试效果可能是不一样的,比如 Customers 表中的有一条记录:
id=100, country='CN'
处理订单流中一条 ‘id=100’ 的记录,当连接器为 ‘jdbc’ 时,因为 c.id 和 c.country 都会被用作查找键,对应的查找结果为空(country=‘CN’ 不满足条件 c.country = ‘US’),会触发重试查找; 而当连接器为 ‘hbase-2.2’ 时,因为仅 c.id 会被用作查找键,因而对应的查找结果非空(会返回 id=100, country=‘CN’ 的记录),因此不会触发重试查找,只是在检查剩余的联接条件 c.country = ‘US’ 时不满足。
当前基于 SQL 语义的考虑,仅提供了 ’lookup_miss’ 重试条件,当需要等待维度表中某些更新时(表中已存在历史版本记录,而非不存在),用户可以尝试两种选择:
利用 DataStream Async I/O 中新增的异步重试支持,实现定制的重试条件(可实现对返回记录更复杂的判断)
利用上述查找键在不同连接器上的特性区别,某些场景下延迟查找维表更新记录的一种解决方案是在联接条件上增加数据的时间版本比较: 比如示例中 Customers 维表每小时都会更新,可以新增一个时间相关的版本字段 update_version,保留到小时精度(可根据时效性需求修改生成方式),如更新时间 ‘2022-08-15 12:01:02’ 记录 update_version 为 ‘2022-08-15 12:00’
CREATETEMPORARYTABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING,-- 新增时间相关的数据版本字段,
update_version STRING
)WITH('connector'='jdbc','url'='jdbc:mysql://mysqlhost:3306/customerdb','table-name'='customers')
增加使用订单流的时间字段和维表 Customers.update_version 的等值联接条件:
ON o.customer_id = c.id AND DATE_FORMAT(o.order_timestamp,'yyyy-MM-dd HH:mm')= c.update_version
这样当新来的订单流数据未查到 Customers 表 12 点的新数据时,就能开启等待重试来查找期望的更新值。
4)、常见问题排查
开启延迟重试查找后,较容易遇到的问题是维表查找节点形成反压,通过 web ui Task Manager 页面的 Thread Dump 功能可以快速确认是否延迟重试引起。 从异步和同步查找分别来看,thread sleep 调用栈会出现在:
- 异步查找:RetryableAsyncLookupFunctionDelegator
- 同步查找:RetryableLookupFunctionDelegator
1、异步查找时,如果所有流数据需要等待一定时长再去查找维表,我们建议尝试其他更轻量的方式(比如源表延迟一定时间消费)。
2、同步查找中的延迟等待重试执行是完全同步的,即在当前数据没有完成重试前,不会开始下一条数据的处理。 异步查找中,如果
3、 ‘output-mode’ 最终为 ‘ORDERED’,那延迟重试造成反压的概率相对 ‘UNORDERED’ 更高,这种情况下调大 ‘capacity’ 不一定能有效减轻反压,可能需要考虑减小延迟等待的时长。
4、联接提示使用中的冲突
当联接提示产生冲突时,Flink 会选择最匹配的执行方式。
- 同一种联接提示间产生冲突时,Flink 会为联接选择第一个最匹配的表。
- 不同联接提示间产生冲突时,Flink 会为联接选择第一个最匹配的联接提示。
- 同一种关联提示间产生冲突示例
CREATETABLE t1 (id BIGINT, name STRING, age INT)WITH(...);CREATETABLE t2 (id BIGINT, name STRING, age INT)WITH(...);CREATETABLE t3 (id BIGINT, name STRING, age INT)WITH(...);-- 同一种联接提示间产生冲突-- 前一个联接提示策略会被选择,即 alan_user_t2 会被作为需 broadcast 的表。SELECT/*+ BROADCAST(alan_user_t2), BROADCAST(alan_user_t1) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;
Flink SQL>SELECT/*+ BROADCAST(alan_user_t1) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |1|'alan'|18|1|'alan'|18||+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |4|'alan_chan'|19|4|'alan_chan'|19|^CQuery terminated, received a total of5rows
Flink SQL>SELECT/*+ BROADCAST(alan_user_t2), BROADCAST(alan_user_t1) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |4|'alan_chan'|19|4|'alan_chan'|19|-- BROADCAST(alan_user_t2, alan_user_t1) 会被选择, 且 alan_user_t2 会被作为需 broadcast 的表。SELECT/*+ BROADCAST(alan_user_t2, alan_user_t1), BROADCAST(alan_user_t1, alan_user_t2) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;
Flink SQL>SELECT/*+ BROADCAST(alan_user_t1, alan_user_t2) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |4|'alan_chan'|19|4|'alan_chan'|19|^CQuery terminated, received a total of5rows
Flink SQL>SELECT/*+ BROADCAST(alan_user_t2, alan_user_t1), BROADCAST(alan_user_t1, alan_user_t2) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |1|'alan'|18|1|'alan'|18||+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |4|'alan_chan'|19|4|'alan_chan'|19|-- 这个例子等同于 BROADCAST(alan_user_t1, alan_user_t2) + BROADCAST(alan_user_t3),-- 当 alan_user_t1与 alan_user_t2联接时,alan_user_t1会被作为需 broadcast 的表,-- 当 alan_user_t1与 alan_user_t2联接后,再与 alan_user_t3联接时,则 alan_user_t3会被作为需 broadcast 的表。SELECT/*+ BROADCAST(alan_user_t1, alan_user_t2, alan_user_t3) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id JOIN alan_user_t3 ON alan_user_t1.id = alan_user_t3.id;
Flink SQL>SELECT/*+ BROADCAST(alan_user_t1, alan_user_t2, alan_user_t3) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id JOIN alan_user_t3 ON alan_user_t1.id = alan_user_t3.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 | id1 | name1 | age1 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |3|'alanchanchn'|20|3|'alanchanchn'|20|3|'alanchanchn'|20||+I |3|'alanchanchn'|20|3|'alanchanchn'|20|3|'alanchanchn'|20|
- 不同联接提示间产生冲突
-- BROADCAST(alan_user_t1) 会被选择,且 alan_user_t1 会被作为需 broadcast 的表。SELECT/*+ BROADCAST(alan_user_t1),SHUFFLE_HASH(alan_user_t1) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;
Flink SQL>SELECT/*+ BROADCAST(alan_user_t1),SHUFFLE_HASH(alan_user_t1) */*FROM alan_user_t1 JOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |1|'alan'|18|1|'alan'|18||+I |1|'alan'|18|1|'alan'|18||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |4|'alan_chan'|19|4|'alan_chan'|19|-- 尽管先指定的是 BROADCAST 策略。但是,因为 BROADCAST 不支持 Full Outer Join。所以,后一种策略会被选择。---验证结果如下,关于full outer join前面有说明,可能官方文档没有及时更新SELECT/*+ BROADCAST(alan_user_t1),SHUFFLE_HASH(alan_user_t1) */*FROM alan_user_t1 FULLOUTERJOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;
Flink SQL>SELECT/*+ BROADCAST(alan_user_t1),SHUFFLE_HASH(alan_user_t1) */*FROM alan_user_t1 FULLOUTERJOIN alan_user_t2 ON alan_user_t1.id = alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |1|'alan'|18|<NULL>|<NULL>|<NULL>||+I |2|'alanchan'|19|<NULL>|<NULL>|<NULL>||+I |3|'alanchanchn'|20|<NULL>|<NULL>|<NULL>||+I |1|'alan'|18|<NULL>|<NULL>|<NULL>||+I |3|'alanchanchn'|20|<NULL>|<NULL>|<NULL>||+I |4|'alan_chan'|19|<NULL>|<NULL>|<NULL>||-D |1|'alan'|18|<NULL>|<NULL>|<NULL>||-D |1|'alan'|18|<NULL>|<NULL>|<NULL>||+I |1|'alan'|18|1|'alan'|18||+I |1|'alan'|18|1|'alan'|18||-D |3|'alanchanchn'|20|<NULL>|<NULL>|<NULL>||-D |3|'alanchanchn'|20|<NULL>|<NULL>|<NULL>||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||+I |3|'alanchanchn'|20|3|'alanchanchn'|20||-D |4|'alan_chan'|19|<NULL>|<NULL>|<NULL>||+I |4|'alan_chan'|19|4|'alan_chan'|19|-- 由于指定的两种联接提示都不支持不等值的联接条件。所以,只能使用支持非等值联接条件的 nested loop join。SELECT/*+ BROADCAST(t1) SHUFFLE_HASH(t1) */*FROM t1 FULLOUTERJOIN t2 ON t1.id > t2.id;
Flink SQL>SELECT/*+ BROADCAST(alan_user_t1),SHUFFLE_HASH(alan_user_t1) */*FROM alan_user_t1 FULLOUTERJOIN alan_user_t2 ON alan_user_t1.id > alan_user_t2.id;+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+| op | id | name | age | id0 | name0 | age0 |+----+-------------+--------------------------------+----------------------+-------------+--------------------------------+----------------------+|+I |<NULL>|<NULL>|<NULL>|1|'alan'|18||+I |<NULL>|<NULL>|<NULL>|3|'alanchanchn'|20||+I |<NULL>|<NULL>|<NULL>|4|'alan_chan'|19||+I |1|'alan'|18|<NULL>|<NULL>|<NULL>||-D |<NULL>|<NULL>|<NULL>|1|'alan'|18||+I |2|'alanchan'|19|1|'alan'|18||+I |3|'alanchanchn'|20|1|'alan'|18||+I |1|'alan'|18|<NULL>|<NULL>|<NULL>||+I |3|'alanchanchn'|20|1|'alan'|18||-D |<NULL>|<NULL>|<NULL>|3|'alanchanchn'|20||+I |4|'alan_chan'|19|1|'alan'|18||+I |4|'alan_chan'|19|3|'alanchanchn'|20|
版权归原作者 一瓢一瓢的饮 alanchan 所有, 如有侵权,请联系我们删除。