
一、实验目的
- 理解HDFS架构和工作原理
- 掌握HDFS部署环境和步骤
- 掌握HDFS(集群的启动start-dfs.sh)启动
- 使用Hadoop命令(文件的增/删/改/查/上传/下载)来操作分布式文件系统
二、实验内容
- HDFS伪分布式环境搭建
- HDFS(集群的启动start-dfs.sh)启动
- 练习Hadoop命令(文件的增/删/改/查/上传/下载)来操作分布式文件系统
三、实验步骤
使用tar解压命令,将已经下载好的hadoop安装包进行解压。
执行过程及结果:
1.进入软件包目录
root@evassh-10644553:~# cd /data/workspace/myshixun/
root@evassh-10644553:/data/workspace/myshixun#
2.查看软件包(通过LS命令可以看到jdk这个安装包)
root@evassh-10644553:/data/workspace/myshixun# ls hadoop-2.8.3.tar.gz
root@evassh-10644553:/data/workspace/myshixun#
3.将软件包解压到/opt目录下(tar命令是解压命令,-C参数是指定解压位置)
root@evassh-10644553:/data/workspace/myshixun# tar -zxf hadoop-2.7.1.tar.gz -C /opt
root@evassh-10644553:/data/workspace/myshixun#
4.查看是否解压成功
root@evassh-10644553:/data/workspace/myshixun# ls /opt hadoop-2.8.3
root@evassh-10644553:/data/workspace/myshixun#
5.将目录切换到root用户的家目录
root@evassh-10644553:/data/workspace/myshixun# cd
root@evassh-10644553:~#
配置环境变量
配置环境变量的目的是为了能够在全局使用hadoop或者hdfs等相关的命令。
1.使用vi命令编辑环境变量文件
root@evassh-10644553:~# vi /etc/profile
输入完成该命令后会进入文档内部,如下图 
2.按↓箭头将白色光标移动到最下面,如下图标红出所示 
3.确保当前输入法在英文状态下后,按下小写i键,按下后如下图标红处所示出现--INSERT--字符,表示已经进入文档编辑模式,可以编辑该文档了 
4.按照下图红色框内输入的内容,完成配置 
5.输入完成后,按下键盘上的esc键,退出编辑模式,按下后,可以看到--INSERT--字符已经没有了 
6.确保当前输入法在英文状态下后,输入:wq 保存文件并且退出文件 
回车后,就可以看到已经退出文件编辑
7.生效环境编辑
root@evassh-10644553:~#source /etc/profile root@evassh-10644553:~#
8.测试,单输入h字母后,快速按下键盘上面的TAB键,会返回如下结果
root@evassh-10644553:~# h

root@evassh-10644553:~# h
从上面的返回结果中我们可以看到有hadoop和hdfs开头的很多命令,如果TAB后没有hadoop和hdfs开头的命令则环境变量配置错误。
修改HDFS的core-site.xml文件
core-site.xml文件主要是指定默认文件系统为 HDFS 和 Namenode 所在节点。
1.编辑core-site.xml
root@evassh-10644553:~# vi /opt/hadoop-2.7.1/etc/hadoop/core-site.xml
输入完成该命令后会进入文档内部,如图
2.按↓箭头将白色光标移动到最下面,如下图标红出所示 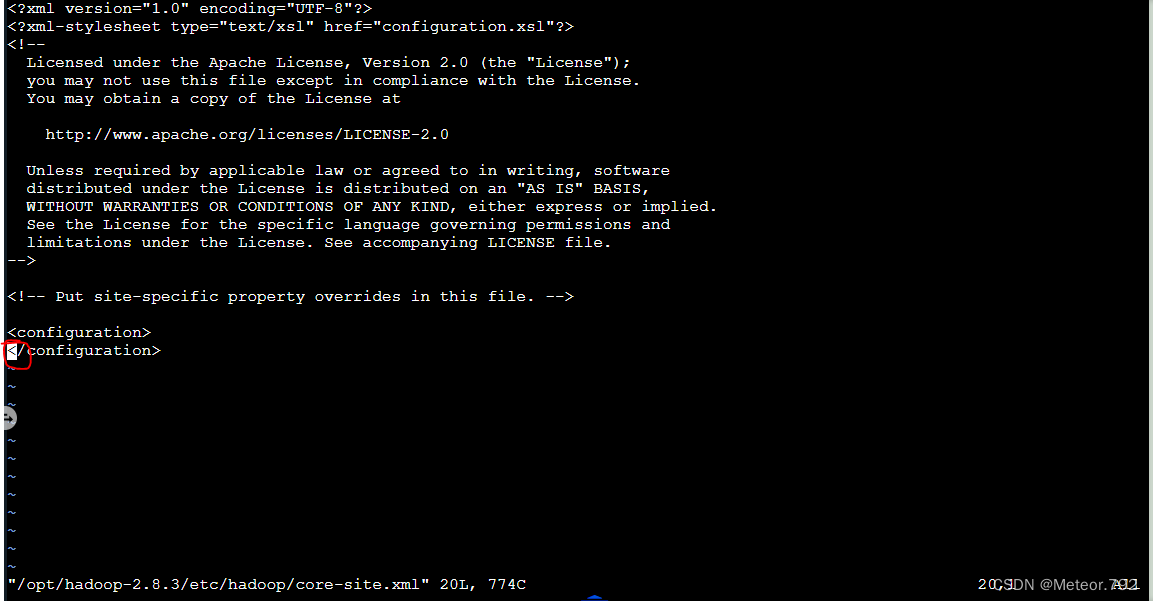
3.确保当前输入法在英文状态下后,按下小写i键,按下后如下图标红处所示出现--INSERT--字符,表示已经进入文档编辑模式,可以编辑该文档了 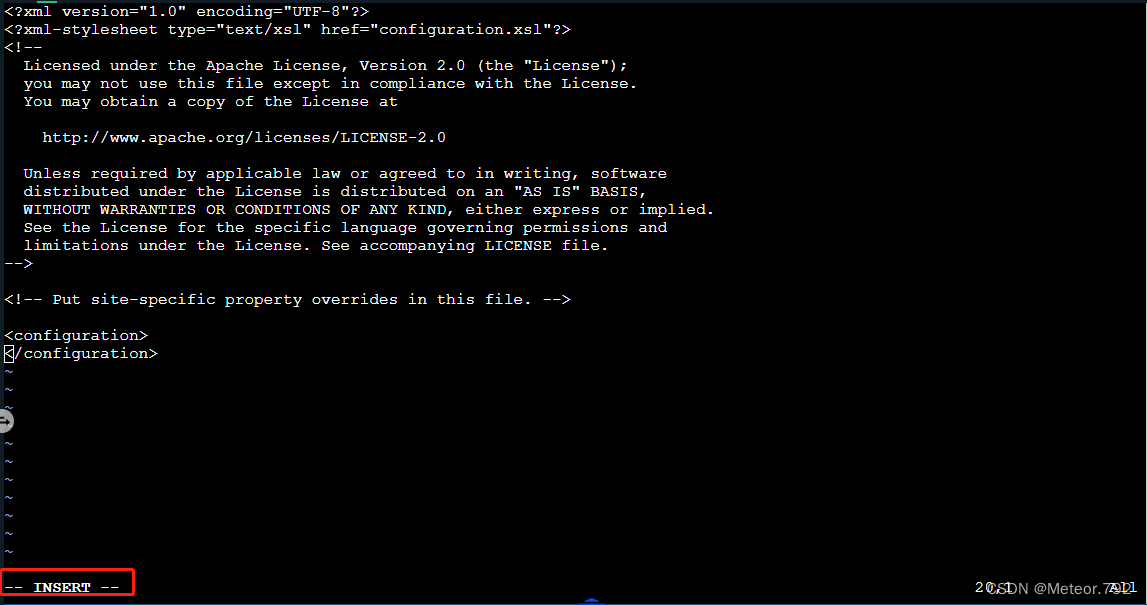
4.按照下图红色框内输入的内容,完成配置 
一定要再三核对该内容,否则后面会报错
5.输入完成后,按下键盘上的esc键,退出编辑模式,按下后,可以看到--INSERT--字符已经没有了 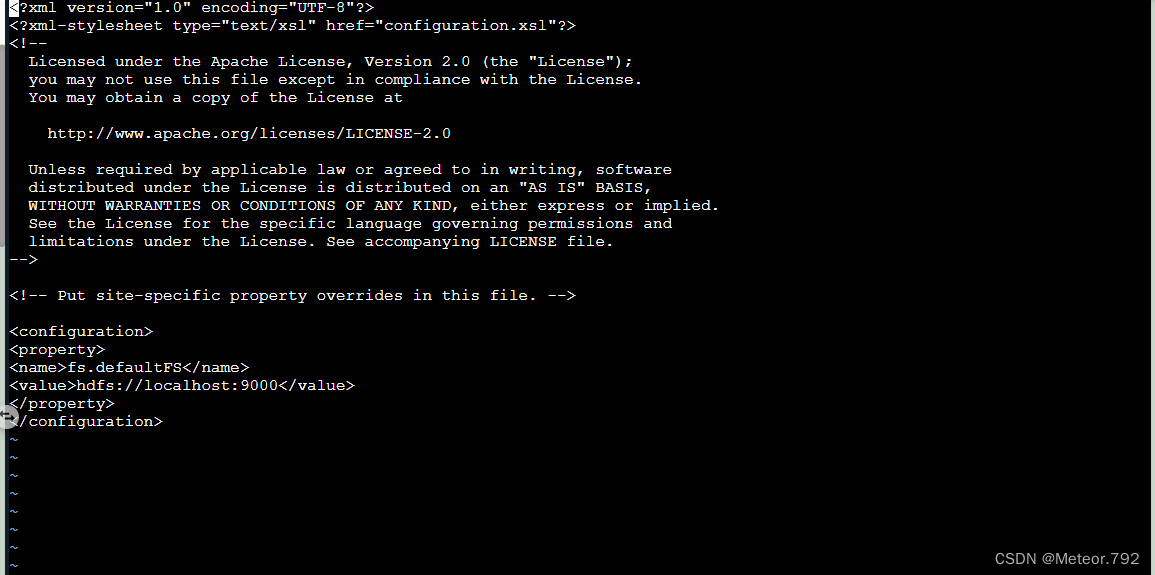
6.确保当前输入法在英文状态下后,输入:wq 保存文件并且退出文件 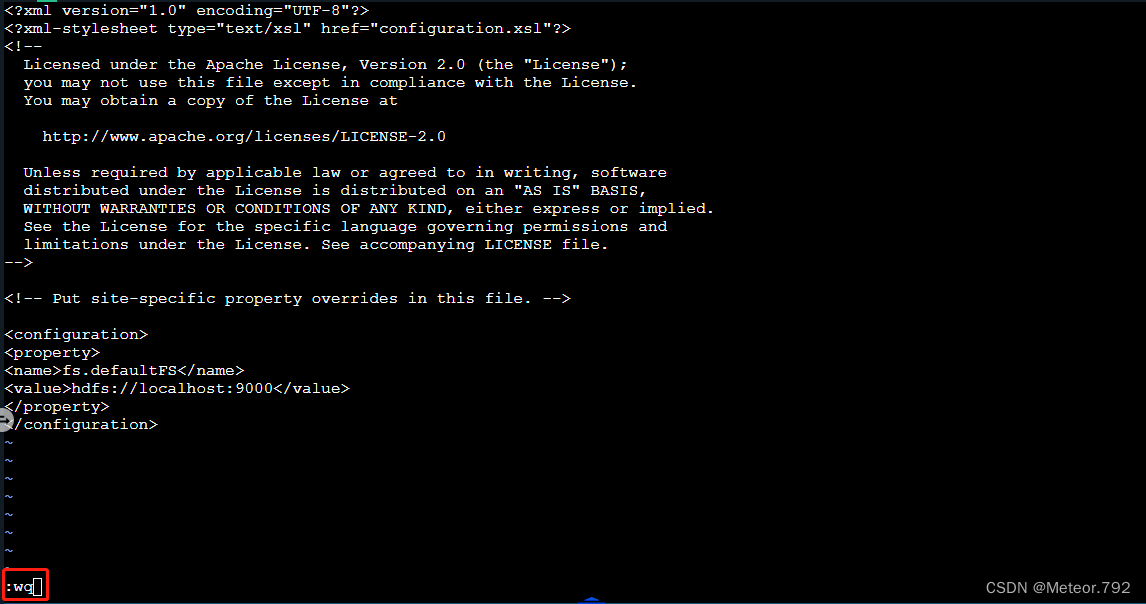
回车后,就可以看到已经退出文件编辑
修改HDFS的hdfs-site.xml文件
hdfs-site.xml文件主要是指定元数据存储目录,数据存储目录,指定备份 Namenode 节点。
1.编辑hdfs-site.xml
root@evassh-10644553:~# vi /opt/hadoop-2.7.1/etc/hadoop/hdfs-site.xml
输入完成该命令后会进入文档内部,如下图
2.按↓箭头将白色光标移动到如下图标红出所示 
3.确保当前输入法在英文状态下后,按下小写i键,按下后如下图标红处所示出现--INSERT--字符,表示已经进入文档编辑模式,可以编辑该文档了 
4.按照下图红色框内输入的内容,完成配置 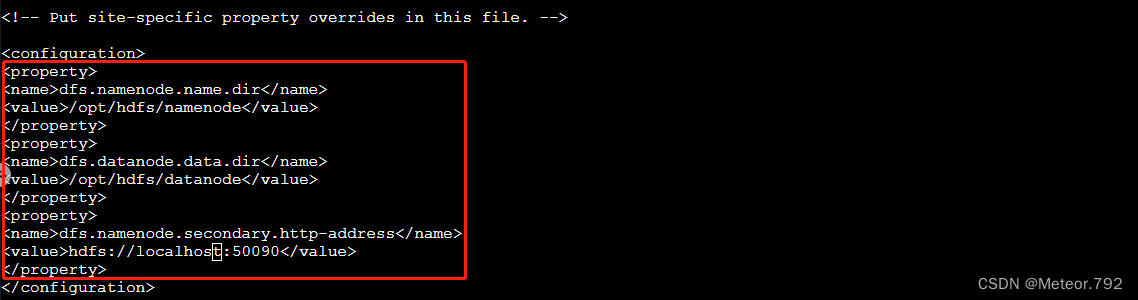 一定要再三核对该内容,否则后面会报错
一定要再三核对该内容,否则后面会报错
5.输入完成后,按下键盘上的esc键,退出编辑模式,按下后,可以看到--INSERT--字符已经没有了 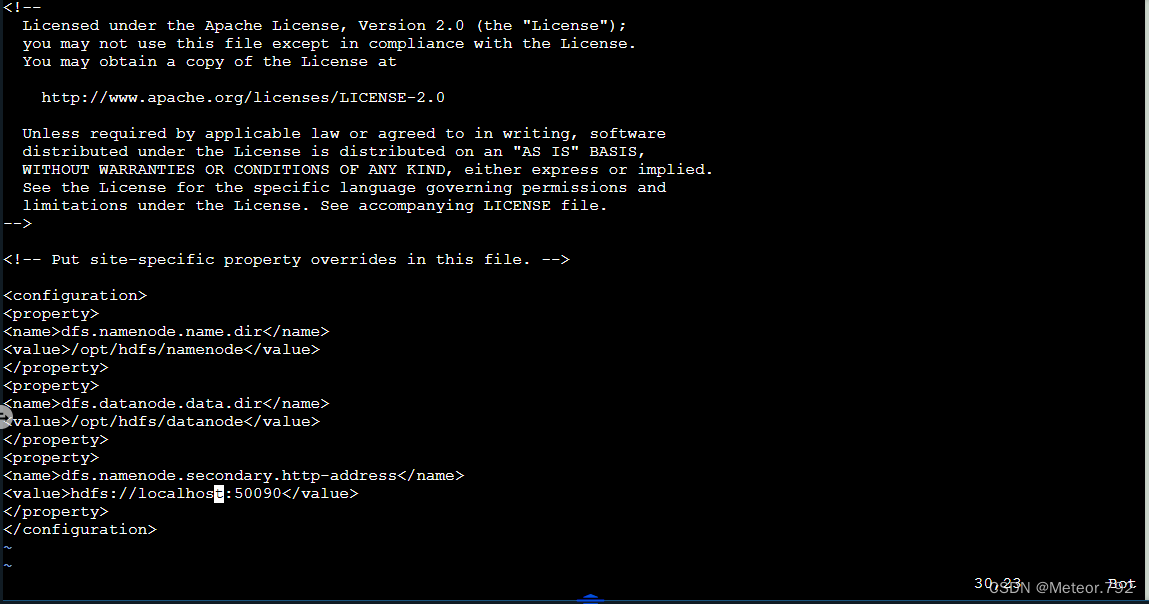
6.确保当前输入法在英文状态下后,输入:wq 保存文件并且退出文件 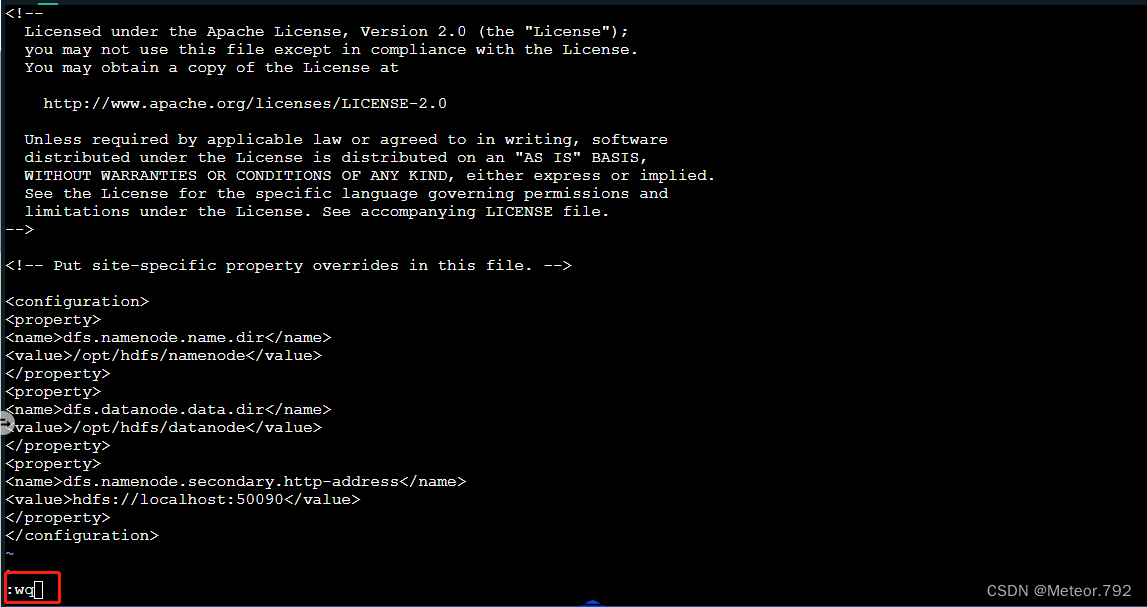 回车后,就可以看到已经退出文件编辑
回车后,就可以看到已经退出文件编辑
初始化集群
所谓的初始化集群,就是格式化,生成文件系统。主要目的是:
①创建一个全新的元数据目录
②生成记录元数据的文件 fsimage
③生成集群的相关标识:如集群 ID—clusterID
root@evassh-10644553:~# hadoop namenode -format
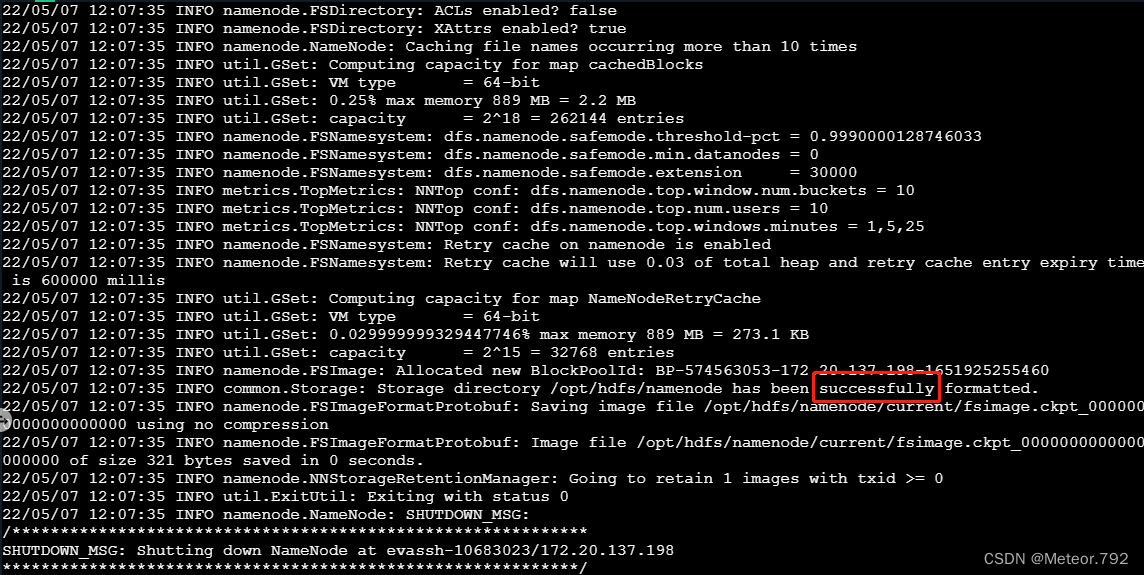
在返回结果中看到“successfully”,标志着出初始化成功。初始化成功后,千万不要再次操作。每次初始化都会生成一个新的集群ID,会使DataNode和NameNode中记录的集群ID不一致,两者无法识别。
ssh免密配置
ssh是连接linux主机的方式之一,在启动HDFS相关服务时会创建一个新的链接来连接linux主机,需要配置免密码登录,这样就可以直接启动服务了,不需要输入密码了。
1.生成密钥,连续按三次回车
root@evassh-10644553:~# ssh-keygen -t rsa -P ''
root@evassh-10644553:~#
2.把id_rsa.pub追加到授权的key里面去
root@evassh-10644553:~#cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
root@evassh-10644553:~#
3.测试
root@evassh-10644553:~#ssh localhost
在下面标红的地方输入yes  输入完成后没有输入密码提示,就是成功了
输入完成后没有输入密码提示,就是成功了
启动HDFS并简单查看
1.使用start-dfs.sh命令启动HDFS集群。
root@evassh-10644553:~# start-dfs.sh localhost:
starting namenode, logging to /opt/hadoop-2.7.1/logs/hadoop-root-namenode-evassh-10683023.out localhost:
starting datanode, logging to /opt/hadoop-2.7.1/logs/hadoop-root-datanode-evassh-10683023.out Starting secondary namenodes [localhost] localhost:
starting secondarynamenode, logging to /opt/hadoop-2.7.1/logs/hadoop-root-secondarynamenode-evassh-10683023.out
root@evassh-10644553:~#
2.使用JPS命令验证
root@evassh-10644553:~#jps 1328 SecondaryNameNode 979 NameNode 1126 DataNode 1608 Jps
前面的数字为服务的进程号,每次启动进程号都会不同。只要能看到有NameNode、DataNode、SecondaryNameNode这三个进程在线就可以了
3.使用ls命令查看hdfs上面的文件
root@evassh-10644553:~#hdfs dfs -ls /
root@evassh-10644553:~#
返回结果为空即正常。
HDFS的常用命令
启动Hadoop

在HDFS中创建/usr/output/文件夹;

在本地创建hello.txt文件并添加内容:“HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。”;

将hello.txt上传至HDFS的/usr/output/目录下;

删除HDFS的/user/hadoop目录;
将Hadoop上的文件hello.txt从HDFS复制到本地/usr/local目录。

四、实验心得
掌握了HDFS(集群的启动start-dfs.sh)启动
会使用Hadoop命令(文件的增/删/改/查/上传/下载)来操作分布式文件系统
版权归原作者 Meteor.792 所有, 如有侵权,请联系我们删除。