
🎇个人主页:Ice_Sugar_7
🎇所属专栏:数据库
🎇欢迎点赞收藏加关注哦!
查询方式
🍉聚合查询
前面我们讲查询时带表达式,比如成绩表中有语文、数学、英语三个科目,我们要查询总分,就要用到:
select chinese + math + english from...
**这种查询方式实际上是在进行
列和列
之间的运算
而聚合查询,则是进行“行与行”之间的运算,不过这里行之间的运算有一定的限制——只能通过
聚合函数
来进行操作,这就需要用到SQL提供的一些库函数了**。聚合查询不像表达式查询那样随便写表达式就可以了
下面我们来看一下常用的聚合函数: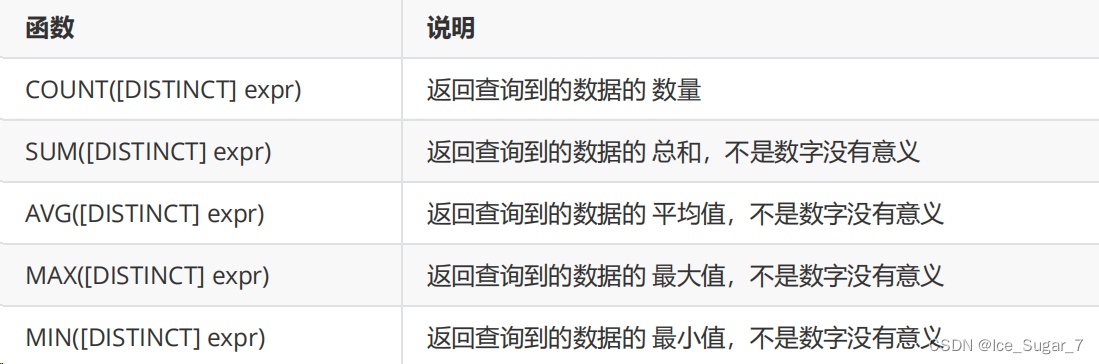
🍌count
现在有一个学生表:
selectcount(*)from students;
这行代码得到结果为4,它就相当于先执行:
select*from students;
然后再使用 count 来计算结果的行数
**大多数情况下,
count(*)
和
count(列名)
没什么区别,在特定情况下才会有差异**
比如,往上面的学生表中插入一个姓名为
NULL
的记录:
我们用 select count(*) 和 select count(name) 分别查询,得到的结果不一样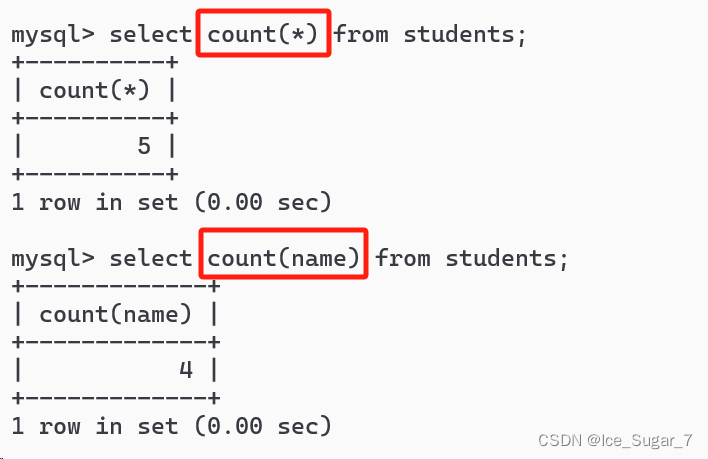
由此我们可以得出一个结论:**查询指定列时,如果查询结果带有
null值
,那么此时
null值
的记录不会计入计数;而如果使用
count(*)
,则会计入计数**
🍌sum
现在有如下的成绩表: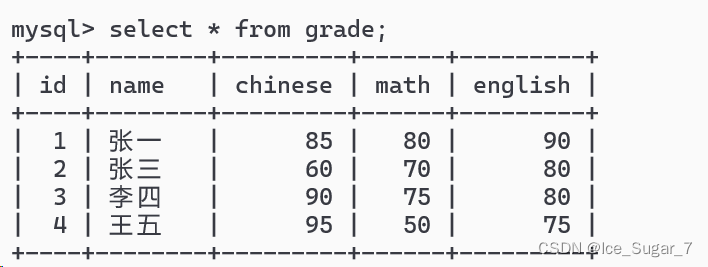
通过sum可以得到总的语文成绩
selectsum(chinese)from grade;
sum 可以把某一列的值全部放在一起相加,在这个过程中,会把
null
给忽略掉,也就是说此时
null
相当于 0
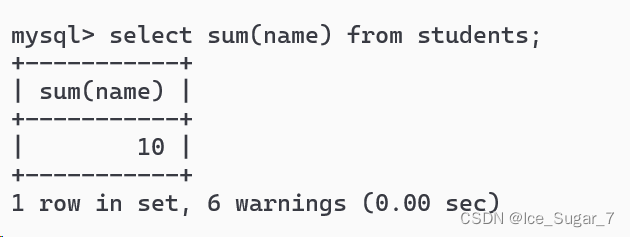
除了数字求和,如果将名字进行求和会得到什么?
selectsum(name)from grade;
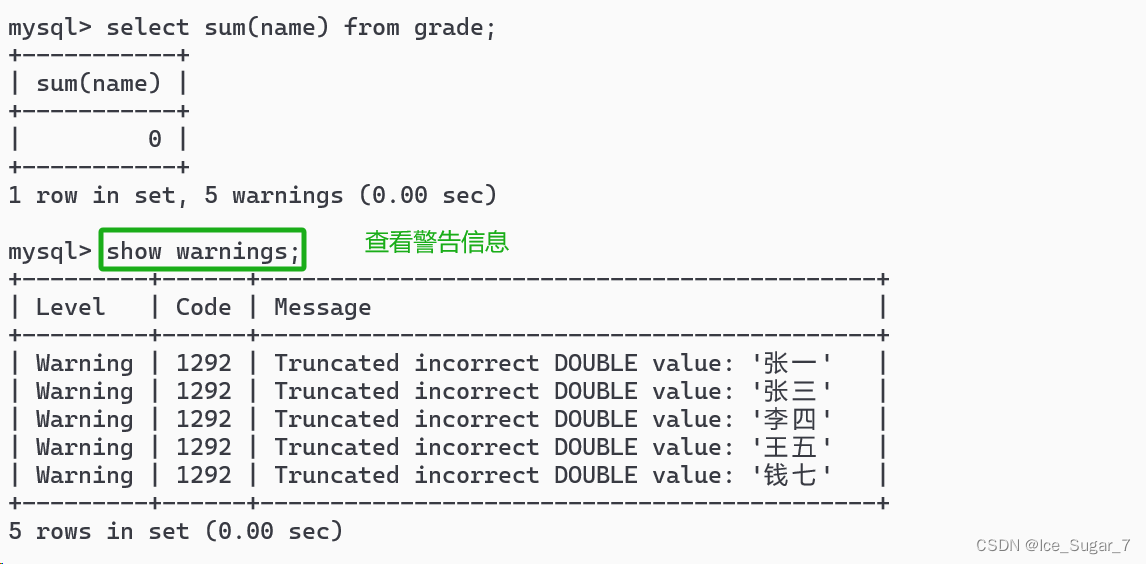
可以看到只报警告而没有报错
**在SQL中,如果把字符串当作数字来进行算术运算,就会尝试
把字符串转成数字
。但是上面这些名字是无法转成数字的,所以报警告**
而如果我们插入一个数字字符作为名字的记录,那就可以转成数字了(不过现实中肯定没人这么起名的hhh)
这次就可以得到结果了:
至此,我们已经介绍了 sum 的用法,剩下的 avg、min、max 的用法和 sum 基本类似,所以也就不再赘述了,接下来就直接用了
现在我们要查询成绩表中,数学分数最低的同学: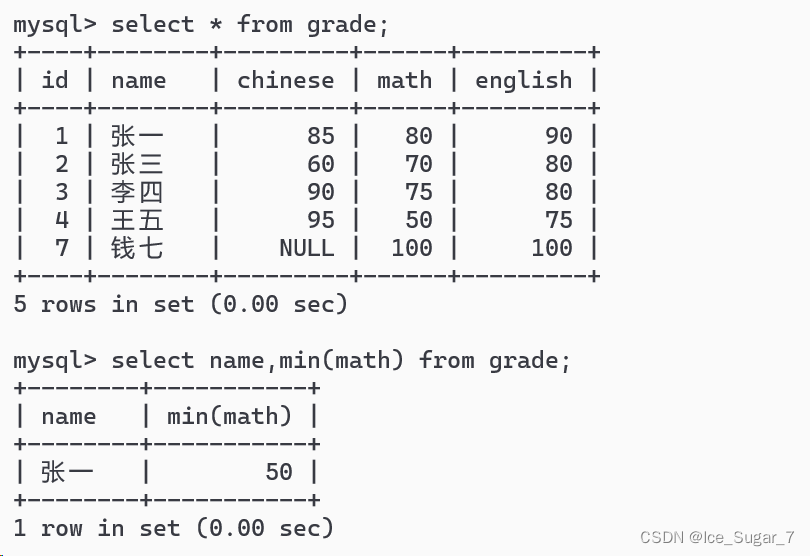
但是我们查询出来的姓名和成绩对不上!
正常来说,一行数据每个列都是对应的(比如张一学号为1,数学考了80),这些列共同构成了一条记录。但是,如果查询中包含聚合函数和非聚合的列,那么结果中的列就不是对应的(相当于各打各的)
**这是在因为使用聚合函数的时候,列和列之间的顺序已经被“打散”了。所以大部分情况下,聚合的列和非聚合的列不能一起使用。当然,有一种情况例外,那就是
group by
**
在此之前,先回到上面的例子,要找出数学成绩最低的同学,我们可以将 order by 和 limit 配合使用:

(顺便提一句,order by 默认是按升序排序的)
🍌group by
**刚才的聚合是把整个表所有行都聚合在一起,不过也可以先把所有行分成若干组,然后分别对每个组进行聚合,需要用到
group by
**
groupby 列名
**它的效果就是把指定的列,其中
值相同的记录
划分到一组,针对这些组就可以分别进行聚合查询了**
举个例子,比如现在要按照岗位,对职工表中员工的工资进行查询以及统计,就可以使用group by 了
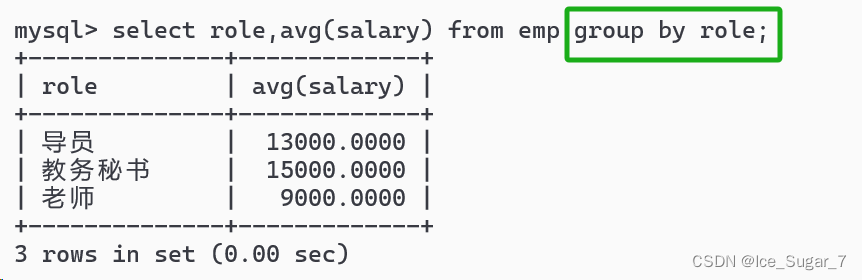
在 select 列名的时候,列名是可以写role的,因为我们是按 role 来分组的
但是注意不能写 id 或者 name,因为这样写的话你会发现一个记录它的列是对不上的,如下图:

这就类似刚才上面查询数学成绩的同学这个例子
总结一下就是:非聚合的列不能和聚合的列或者 group by 的列一起使用
**对于分组查询,它也是可以对查询结果进行条件筛选的,分组后的条件,用
having
来表示,它的用法和where是一样的,只不过 where 是用于分组之前的条件**
下面应用一下 having
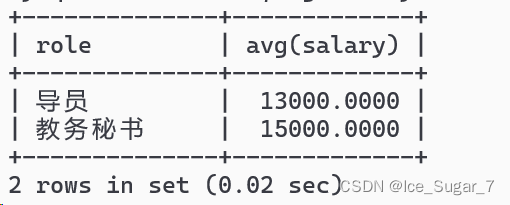
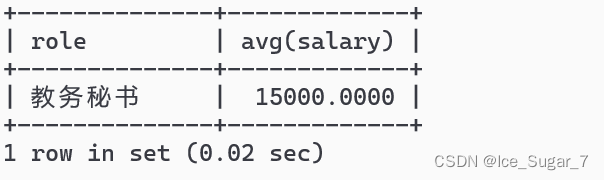
例1:要统计平均薪资高于10000的岗位
select role,avg(salary)from emp groupby role havingavg(salary)>10000;
例2:要统计每个岗位的平均薪资,不包括李四,同时除去平均薪资低于13000的情况
统计平均薪资的时候不包括李四,这是在分组之前进行的,要用where;而筛选出平均薪资高于13000的情况,这是在分组后进行的,要用 having
select role,avg(salary)from emp where name !='李四'groupby role havingavg(salary)>13000;
🍉联合/多表查询(面试常考)
前面的查询都是针对一张表的,而多表查询自然是针对多张表的,它比单表查询要复杂一些
**在正式讲多表查询之前,需要先引入一个概念——
笛卡尔积
**
**所谓笛卡尔积,其实就是简单的
排列组合
**
笛卡尔积的列数就是之前两个表的列数之和;而行数则是之前两个表的行数之积
如果表更多,比如有三张表A、B、C,那么就是先计算 A 和 B 的笛卡尔积,算出来的结果再和 C 计算笛卡尔积
(注意:将两个很大的表进行笛卡尔积是一个危险操作,因为会产生大量的运算和 IO,可能把数据库搞挂了)
🍌两个表的联合查询
**联合查询的
核心操作
就是进行笛卡尔积,比如使用两个表进行联合查询,就是先把这两个表计算笛卡尔积**
比如同时查询学生表和成绩表:
select*from students,grade;
得到下面的结果: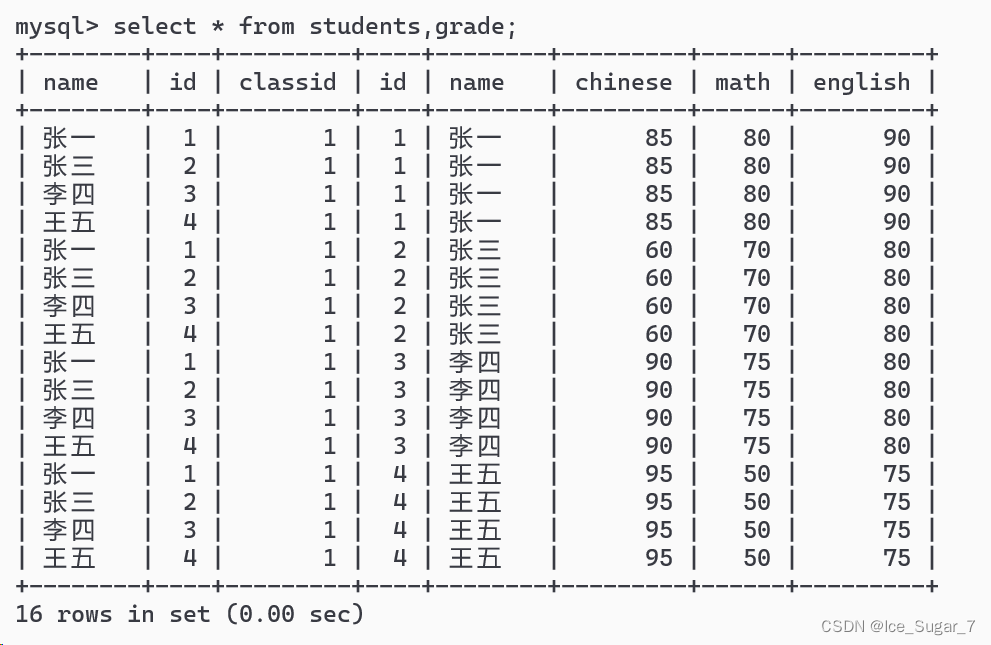
细看一下我们会发现,有一些记录是无效的,就学生表中的 id 对不上 成绩表中的 id
所以我们再指定一些条件,来得到预期的查询结果
我们要让两个表中 id 一样的记录才能配对
select*from students,grade where students.id = grade.id;
students.id = grade.id
这个把两个表连接起来的条件,就叫作
连接条件

不过也不是随便拿来两个表就能进行笛卡尔积,一定要确保这两个表有一定的
关联关系
,即至少有一个列是有关联的
总结:多表查询的一般步骤
①笛卡尔积
②连接条件
③根据需求指定其他条件
④针对列进行精简 or 使用聚合函数
除了上面的写法之外,联合查询还有一种写法,也能实现一样的效果:
select*from 表1join 表2on 连接条件;
所以上面的例子,我们也可以写为
select*from students join grade on students.id = grade.id;
可以得到一样的结果

再来看一个例子
现有学生表和课程表这两个表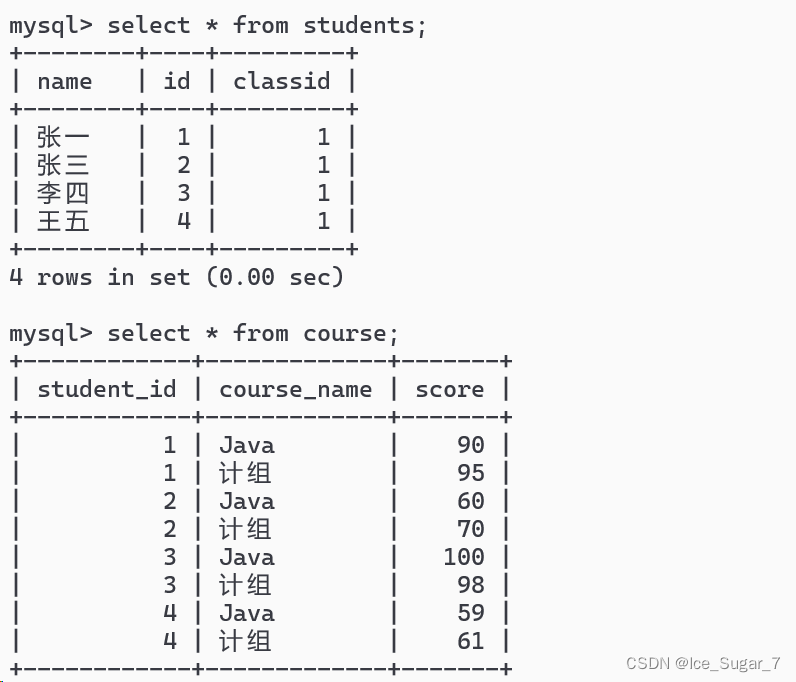
现在要求每位同学所有课程的总分
思路:按照上面的步骤,先笛卡尔积,然后指定连接条件
我们要查看的列就是姓名和总分这两列
select students.name,sum(course.score)from students,course where students.id = course.student_id;
然后根据需求指定其他条件:因为我们是要统计每一位学生的成绩,所以就要按学生名字进行分组,这就要用到 group by
select students.name,sum(course.score)from students,course where students.id = course.student_id groupby students.name;
接下来就是对列进行精简或者使用聚合函数,因为我们的目的就是求和,所以一开始就已经使用聚合函数 sum 了,这一步就不用再考虑了
🍌多个表的联合查询
上面举的例子的中有学生表和课程表这两个表,现在要再加入另一个表——课程学分表,它包括课程名字和课程学分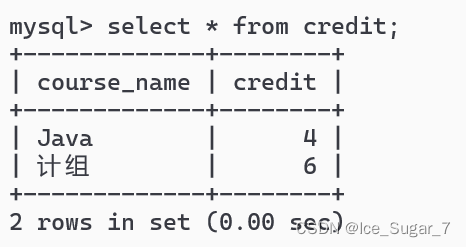
那如何把它和前面两个表连接起来呢?
我们可以发现,课程学分表和学生表之间其实没有联系,因为它们没有相关联的列;反之,它和课程表就很有联系——都有“课程名字”这一列
所以先把它们俩连起来
select*from course,credit where course.course_name = credit.course_name;
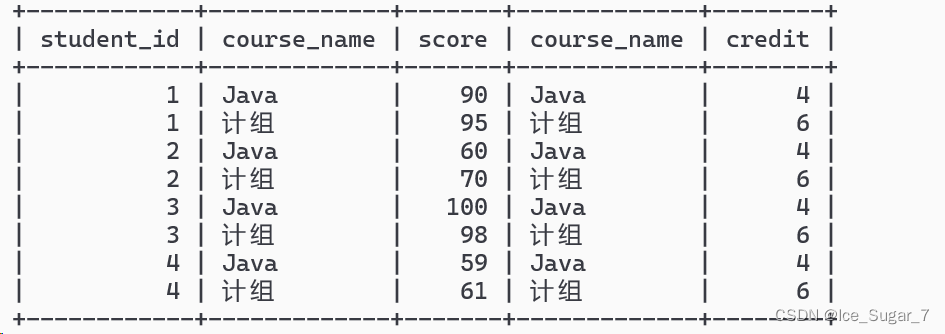
接下来再把这个表和学生表连起来
只需在原来的基础上,再查询一下学生表,并加上连接条件(即学生表的 id 和课程表的学生 id 相等),现在就有两个连接条件了,用 and 把两条件结合起来
select*from students,course,credit where students.id = course.student_id and course.course_name = credit.course
_name;

不过查询结果的列数太多了,我们需要精简一下,三个表分别查询指定列就 ok 了
select students.name,students.id,course.course_name,course.score,credit.credit from students,course,credit where
students.id = course.student_id and course.course_name = credit.course_name;
这条SQL语句看起来很长,但是我们拆分成一步步来写,其实也就没那么复杂了
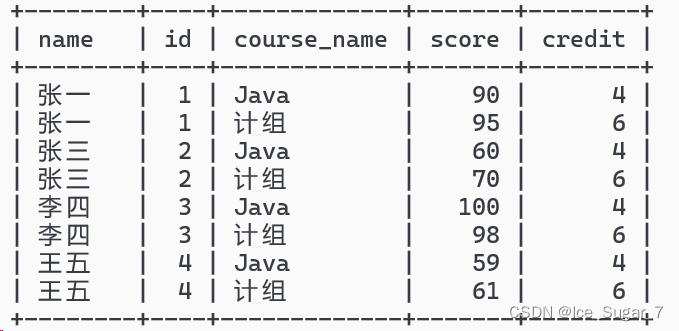
上面的SQL语句也可以使用 join on 来改写:
select students.name,students.id,course.course_name,course.score,credit.credit from students join course on stude
nts.id = course.student_id join credit on course.course_name = credit.course_name;
另外,在多表查询中,前面涉及到的去重、排序、limit 等操作也是同样适用的,具体就不演示了
🍌外连接
**刚才上面那些写法,叫作
内连接
,而
外连接
也是多表查询的一种体现形式
在大多数情况下,内连接和外连接的查询结果没什么区别,只有在一些特殊情况下,查询结果才会存在差异**
那么“大多数情况”是什么样的情况呢?举个例子:
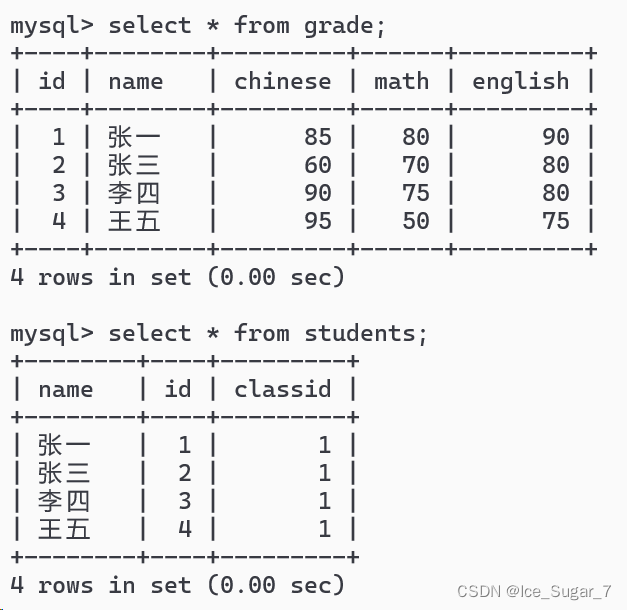
在上面的学生表和成绩表中,这两个表的数据是一一对应的,即学生表中的任何一个记录都能在分数表中体现出来;反过来,分数表中的每个记录,也能在学生表中体现出来,那此时外连接和内连接的结果就是一样的
**前面我们说可以使用 join on 进行联合查询,其实那里的 join 前面省略了
inner
,它表示内连接,一般 inner 是不用写的**
**而外连接分为
左外连接
和
右外连接
,需要在 join 前面分别加上
left
或
right
**
举例,现有两张表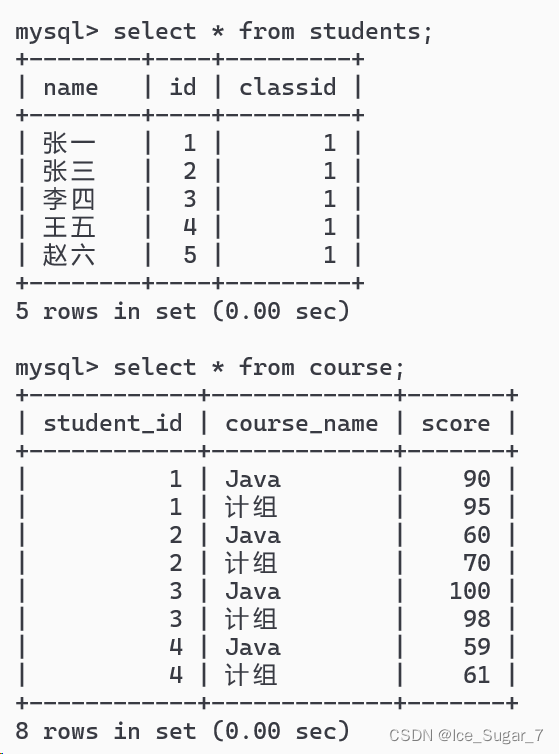
注意,课程表中没有赵六的信息
分别对学生表和课程表进行左、右外连接,得到如下结果:
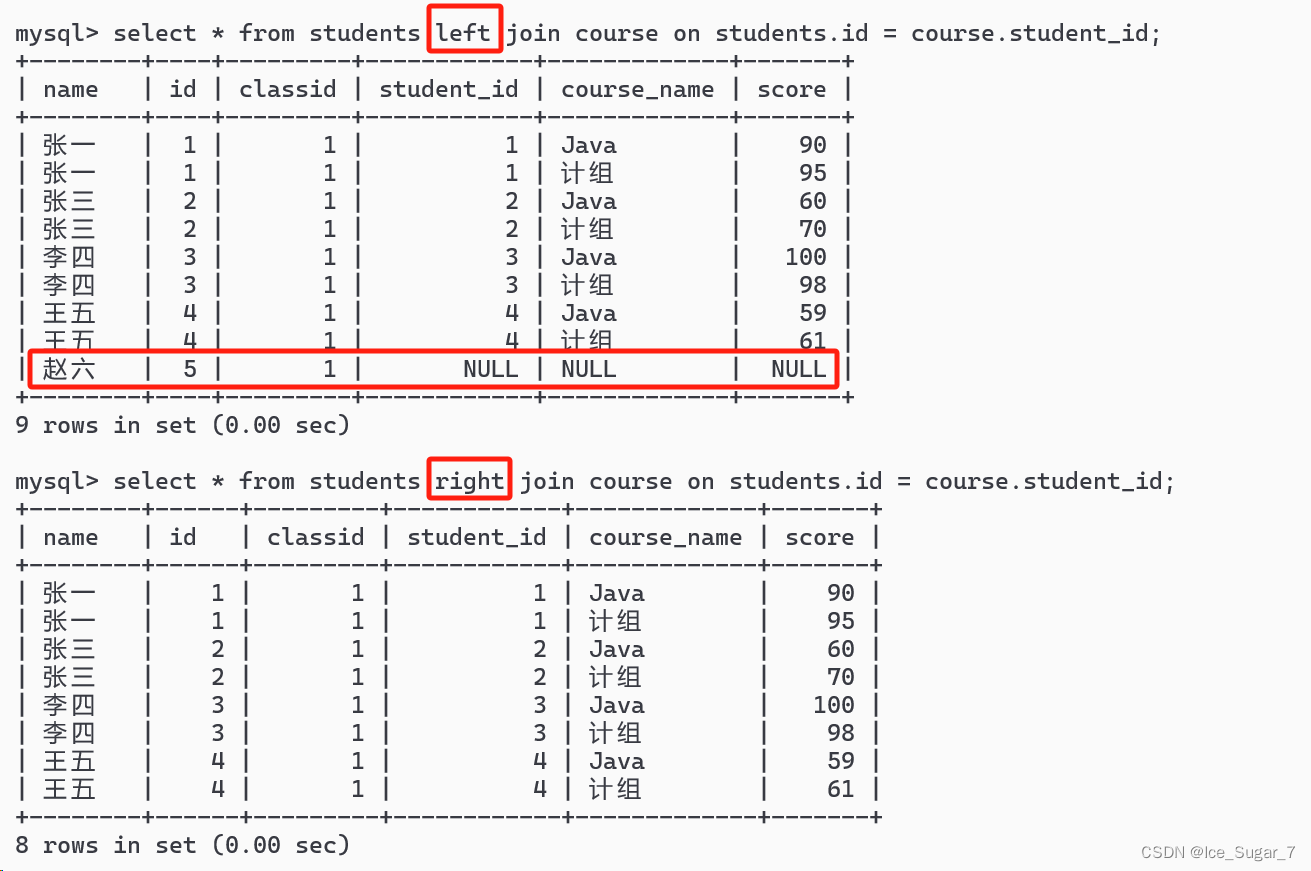
可以发现左外连接的结果有赵六这条记录,右表中的列全为 NULL;而右外连接没有这条记录
结论如下:
①左外连接就是以左表为主,保证左侧的表(join 左边的表)每个记录都体现在最终结果里,如果这个记录在右表中没有匹配,就把对应的列填成 NULL
②同理,右外连接就是以右表为主,保证右表中每个记录都存在,如果对应的数据在左表中没有,则会填成 NULL
🍉子查询
其实就是套娃,把多个简单 sql 合并为一个复杂的 sql
注意:实际开发中不建议这样写,因为当有多个 sql 语句时,合并后就是一坨…
我们不写 ≠ 别人不写,为了看懂别人写的子查询 sql,我们还是有必要学习一下
举一个简单的例子,比如现在要从下面这个表中找出张一的同班同学的名字
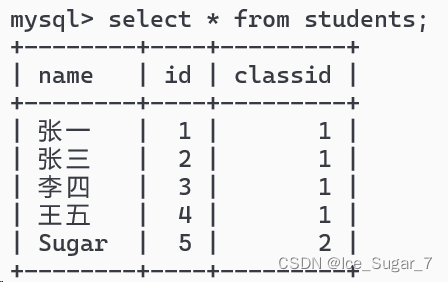
照正常的思路,那就是先找出张一的班级: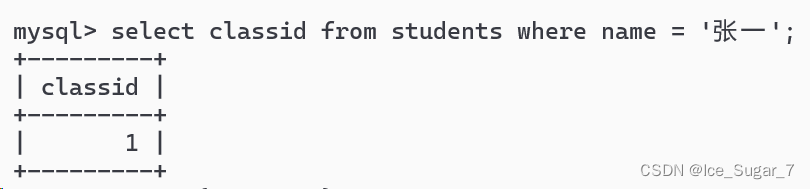
然后再找出1班中名字不是张一的同学:
可以看到,在这个过程中,我们进行两次查询,先得到班级信息,然后由此进行第二次查询得到同学姓名
使用子查询的话,那就是将上面这两步合并起来:
select name from students where name !='张一'and classid =(select classid from students where name ='张一');
🍉合并查询
**这个查询很好理解,就是把两个查询结果的结果集,合并成一个集合,这个过程我们使用
union
关键字来完成**
语法:
select1unionselect2
注意:合并查询要求两个 select 查询的结果集的列数和类型要匹配,最终的列名就是第一个 select 的列名
**合并查询看起来和 or 差不多,但是 or 只能在一个表中进行查询,而 union 左右两侧的 sql 可以是查询两个不同的表,并且还会自动对查询结果进行
去重
(如果使用
union all
的话,则不会去重)**
下面还是举些例子运用 union:

select*from students where name ='张三'unionselect*from students where id =1;
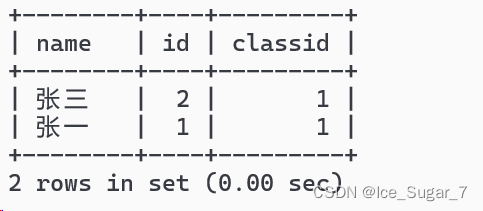
select*from students where name ='张三'unionselect*from students where id =2;
版权归原作者 Ice_Sugar_7 所有, 如有侵权,请联系我们删除。