
Apache Spark 简介
Apache Spark
是一种分布式处理系统,用于在大型数据集上执行大数据和机器学习任务。
作为数据科学爱好者,您可能熟悉在本地设备上存储文件并使用 R 和 Python 等语言进行处理。但是,本地工作站有其局限性,无法处理非常大的数据集。
这就是像
Apache Spark
这样的分布式处理系统的用武之地。分布式处理是使用多个处理器来运行应用程序的设置。无需尝试在一台计算机上处理大型数据集,而是可以在相互通信的多个设备之间分配任务。
借助
Apache Spark
,用户可以对 PB 级数据运行查询和机器学习工作流,这在本地设备上是无法做到的。
这个框架甚至比以前的数据处理引擎(如
Hadoop
)更快,并且在过去八年中越来越受欢迎。IBM、亚马逊和雅虎等公司正在使用
Apache Spark
作为他们的计算框架。
如果您想成为一名数据科学家,在大规模数据集上分析数据和训练机器学习模型的能力是一项宝贵的技能。拥有使用
Apache Spark
等大数据框架的专业知识将使您在该领域的其他人中脱颖而出。
什么是
PySpark
?
PySpark
是 Python 中
Apache Spark
的接口。使用
PySpark
,您可以编写类似 Python 和类似 SQL 的命令,以在分布式处理环境中操作和分析数据。这是一个初学者程序,将引导您使用 PySpark 操作数据、构建机器学习管道和调整模型。
PySpark
是做什么用的?
大多数数据科学家和分析师都熟悉 Python,并使用它来实现机器学习工作流。PySpark允许他们在大规模分布式数据集上使用熟悉的语言。
为什么选择
PySpark
?
收集TB级数据的公司将拥有像
Apache Spark
这样的大数据框架。要使用这些大规模数据集,仅了解 Python 和 R 框架是不够的。
你需要学习一个框架,允许你在分布式处理系统之上操作数据集,因为大多数数据驱动的组织都会要求你这样做。
PySpark
是一个很好的入门点,因为它的语法很简单,如果您已经熟悉 Python,则可以轻松上手。
公司选择使用像
PySpark
这样的框架的原因是因为它可以快速处理大数据。它比
Pandas
和
Dask
等库更快,并且可以处理比这些框架更多的数据。例如,如果您要处理超过 PB 的数据,
Pandas
和
Dask
将失败,但
PySpark
将能够轻松处理它。
虽然也可以在像
Hadoop
这样的分布式系统上编写Python代码,但许多组织选择使用
Spark
并使用
PySpark API
,因为它速度更快,可以处理实时数据。使用
PySpark
,您可以编写代码从不断更新的源中收集数据,而数据只能使用
Hadoop
以批处理模式进行。
Apache Flink
是一个分布式处理系统,它有一个叫做
PyFlink
的
Python API
,在性能方面实际上比
Spark
快。但是,
Apache Spark
已经存在了更长的时间,并且拥有更好的社区支持,这意味着它更可靠。
此外,
PySpark
提供容错能力,这意味着它能够在故障发生后恢复损失。该框架还具有内存计算功能,并存储在随机存取存储器 (RAM) 中。它可以在未安装硬盘驱动器或 SSD 的计算机上运行。
如何安装
PySpark
先决条件:
在安装 Apache Spark 和 PySpark 之前,您需要在设备上设置以下软件:
python
如果您尚未安装 Python,请按照我们的 Python 开发人员设置指南进行设置,然后再继续下一步。
java
接下来,如果您使用的是 Windows,请按照本教程在您的计算机上安装 Java。这是MacOs的安装指南,这是Linux的安装指南。
Jupyter Notebook
Jupyter Notebook 是一个 Web 应用程序,可用于编写代码和显示公式、可视化效果和文本。它是数据科学家最常用的编程编辑器之一。在本教程中,我们将使用
Jupyter Notebook
编写所有
PySpark
代码,因此请确保已安装它。
您可以按照我们的教程在本地设备上启动并运行 Jupyter。
数据
在本教程中,我们将使用 Datacamp 的电子商务数据集进行所有分析,因此请务必下载它。我们已将文件重命名为“datacamp_ecommerce.csv”并将其保存到父目录,您可以执行相同的操作,以便更轻松地编写代码。
安装指南
设置好所有先决条件后,可以继续安装
Apache Spark
和
PySpark
。
安装
Apache Spark
要安装
Apache Spark
,请导航到下载页面并下载页面上显示的 .tgz 文件:
然后,如果您使用的是 Windows,请在 C 目录中创建一个名为“spark”的文件夹。如果您使用的是 Linux 或 Mac,则可以将其粘贴到主目录中的新文件夹中。
接下来,提取您刚刚下载的文件并将其内容粘贴到此“spark”文件夹中。文件夹路径应如下所示:
现在,您需要设置环境变量。有两种方法可以做到这一点:
方法 1:使用 Powershell 更改环境变量
如果使用的是 Windows 计算机,则更改环境变量的第一种方法是使用 Powershell:
步骤1:单击“开始”->Windows Powershell ->“以管理员身份运行”
步骤 2:在 Windows Powershell 中键入以下行以设置SPARK_HOME:
setx SPARK_HOME "C:\spark\spark-3.3.0-bin-hadoop3"# 更改为你的安装路径
第 3 步:接下来,将 Spark bin 目录设置为路径变量:
setx PATH "C:\spark\spark-3.3.0-bin-hadoop3\bin"
方法 2:手动更改环境变量
步骤1:导航到“开始”->“系统”-“>设置”->“高级设置”
步骤2:单击环境变量
步骤3:在“环境变量”选项卡中,单击“新建”。
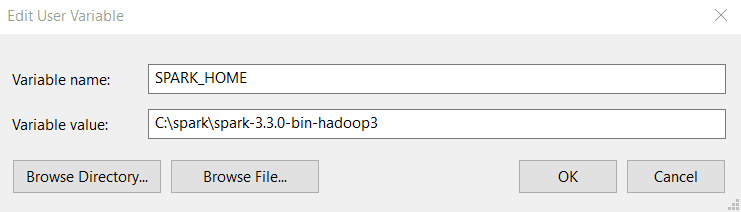
步骤4:在变量名称和变量值中输入以下值。请注意,安装的版本可能与下面显示的版本不同,因此请将路径复制并粘贴到 Spark 目录。
步骤5:接下来,在“环境变量”选项卡中,单击“path”,然后选择“编辑”。
第 6 步:单击“新建”并粘贴到 Spark bin 目录的路径中。下面是 bin 目录的示例:
C:\spark\spark-3.3.0-bin-hadoop3\bin
如果您使用 Linux 设备,以下是设置环境变量的指南,这是适用于 MacOS 的指南。
安装 PySpark
现在,您已成功安装 Apache Spark 和所有其他必要的先决条件,请在 Jupyter Notebook 中打开 Python 文件,并在第一个单元格中运行以下代码行:
!pip install pyspark
或者,您可以按照此端到端 PySpark 安装指南在您的设备上安装软件。
端到端机器学习PySpark 教程
现在,您已经启动并运行了
PySpark
,我们将向您展示如何使用该库执行端到端客户细分项目。
客户细分是公司用来识别和分组表现出相似特征的用户的一种营销技术。例如,如果你只在夏天去星巴克购买冷饮,你可以被细分为“季节性购物者”,并被夏季策划的特别促销活动所吸引。
数据科学家通常构建无监督机器学习算法,例如
K-Means
聚类或分层聚类来执行客户细分。这些模型非常擅长识别用户组之间的相似模式,而这些模式往往不被人眼注意到。
在本教程中,我们将使用
K-Means
聚类对之前下载的电子商务数据集进行客户细分。
在本教程结束时,你将熟悉以下概念:
- 使用 PySpark 读取 csv 文件
- 使用 PySpark 进行探索性数据分析
- 对数据进行分组和排序
- 执行算术运算
- 聚合数据集
- 使用PySpark 进行数据预处理
- 使用日期时间值
- 类型转换
- 联接两个数据帧
- rank() 函数
- PySpark 机器学习
- 创建特征向量
- 标准化数据
- 构建 K-Means 聚类分析模型
- 解释模型
步骤 1:创建
SparkSession
SparkSession
是
Spark
中所有功能的入口点,如果要在
PySpark
中生成数据帧,则需要
SparkSession
。运行以下代码行以初始化
SparkSession
:
spark = SparkSession.builder.appName("Datacamp Pyspark Tutorial").config("spark.memory.offHeap.enabled","true").config("spark.memory.offHeap.size","10g").getOrCreate()
使用上面的代码,我们构建了一个 spark 会话并为应用程序设置了一个名称。然后,将数据缓存在堆外内存中,以避免将其直接存储在磁盘上,并手动指定内存量。
步骤 2:创建 DataFrame
我们现在可以读取刚刚下载的数据集:
df = spark.read.csv('datacamp_ecommerce.csv',header=True,escape="\"")
请注意,我们定义了一个转义字符,以避免在解析时在 .csv 文件中使用逗号。
让我们使用
show()
函数看一下 dataframe 的前几行数据:
df.show(5,0)

数据由 8 个变量组成:
InvoiceNo
:每个客户发票的唯一标识符。
StockCode
:库存中每件商品的唯一标识符。
Description
:客户购买的商品。
Quantity
:客户在单张发票中购买的每件商品的编号。
InvoiceDate
:购买日期。
UnitPrice
:每件商品一个单位的价格。
CustomerID
:分配给每个用户的唯一标识符。
Country
:购买地的国家/地区
第 3 步:探索性数据分析
现在我们已经看到了此数据集中存在的变量,让我们进行一些探索性数据分析以进一步了解这些数据点:
- 让我们先计算数据帧中的行数:
df.count()# Answer: 2,500
- 数据帧中有多少个唯一客户?
df.select('CustomerID').distinct().count()# Answer: 95
- 大多数购买来自哪个国家? 要查找大多数购买的国家/地区,我们需要在
PySpark中使用groupBy()子句:
from pyspark.sql.functions import*from pyspark.sql.types import*
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).show()
运行上述代码后,将呈现下表: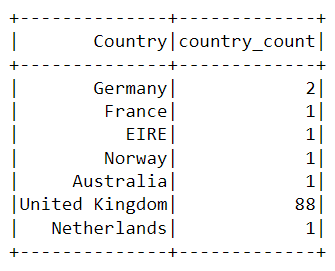
平台上几乎所有的购买都是从英国购买的,只有少数是从德国、澳大利亚和法国等国家购买的。
- 请注意,上表中的数据不是按购买顺序显示的。为了对这个表进行排序,我们可以包括
orderBy()子句:
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).orderBy(desc('country_count')).show()
显示的输出现在按降序排序:
- 客户最近一次在电子商务平台上购买是什么时候? 要查找在平台上进行的最新购买时间,我们需要将
InvoiceDate列转换为时间戳格式,并使用Pyspark中的max()函数:
spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY")
df = df.withColumn('date',to_timestamp("InvoiceDate",'yy/MM/dd HH:mm'))
df.select(max("date")).show()
运行上述代码后,应会看到下表显示:
- 客户最早在电商平台上购买是什么时候? 与我们上面所做的类似,
min()函数可用于查找最早的购买日期和时间:
df.select(min("date")).show()

请注意,最近和最早的购买是在同一天进行的,相隔仅几个小时。这意味着我们下载的数据集仅包含一天内购买的信息。
第 4 步:数据预处理
现在我们已经分析了数据集并更好地了解了每个数据点,我们需要准备数据以输入机器学习算法。
让我们再次看一下数据帧的前几行数据,以了解如何进行预处理:
df.show(5,0)

从上面的数据集中,我们需要根据每个用户的购买行为创建多个客户细分。
此数据集中的变量采用的格式不容易引入客户细分模型。这些功能单独并不能告诉我们太多关于客户购买行为的信息。
因此,我们将使用现有变量来推导出三个新的信息特征——最近购买(Recency)、购买频率(Frequency)和货币价值 (RFM)。
RFM通常用于营销中,根据客户的价值来评估客户的价值:
最近购买:每个客户最近购买过什么?
购买频率:他们多久买一次东西?
货币价值:他们在购物时平均花多少钱?
现在,我们将对数据帧进行预处理以创建上述变量。
最近购买
首先,让我们计算新近度的值 - 在平台上进行购买的最新日期和时间。这可以通过两个步骤实现:
i) 为每个客户分配一个新近度分数
我们将从最早的日期中减去数据框中的每个日期。这将告诉我们最近在数据帧中看到客户的时间。值 0 表示最低新近度,因为它将分配给在最早日期看到进行购买的人。
df = df.withColumn("from_date", lit("12/1/10 08:26"))
df = df.withColumn('from_date',to_timestamp("from_date",'yy/MM/dd HH:mm'))
df2=df.withColumn('from_date',to_timestamp(col('from_date'))).withColumn('recency',col("date").cast("long")- col('from_date').cast("long"))
ii) 选择最近购买的产品
一个客户可以在不同的时间进行多次购买。我们只需要选择他们最后一次购买产品的时间,因为这表示最近一次购买的时间:
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')
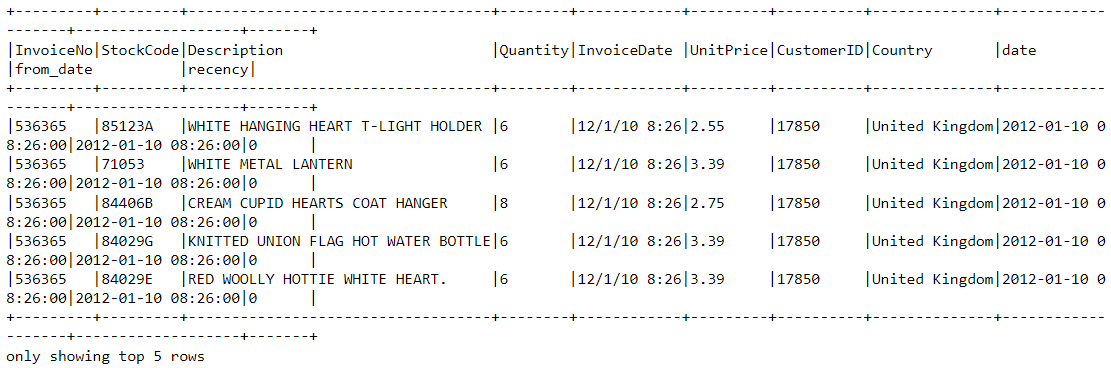
让我们看一下新数据帧的头部。它现在附加了一个名为
recency
的变量:
df2.show(5,0)
查看
PySpark
数据帧中存在的所有变量的更简单方法是使用其
printSchema()
函数。这相当于
Pandas
中的
info()
函数:
df2.printSchema()
呈现的输出应如下所示:
购买频率
现在让我们计算一下频率的价值——客户在平台上购买东西的频率。为此,我们只需要按每个客户 ID 进行分组,并计算他们购买的商品数量:
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceDate').alias('frequency'))
看看我们刚刚创建的这个新数据帧的前几行:
df_freq.show(5,0)
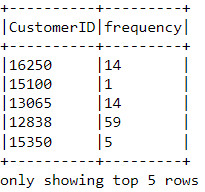
在数据帧中,每个客户都会追加一个频率值。这个新的数据帧只有两列,我们需要将它与前一列连接起来:
df3 = df2.join(df_freq,on='CustomerID',how='inner')
让我们打印此数据帧的架构:
df3.printSchema()

货币价值
最后,让我们计算货币价值 - 每个客户在数据帧中花费的总金额。实现此目的有两个步骤:
i) 查找每次购买的总花费金额:
对于单次购买,每个
customerID
都带有名为
Quantity
和
UnitPrice
的变量:

要获得每个客户在一次购买中花费的总金额,我们需要将
Quantity
乘以
UnitPrice
:
m_val = df3.withColumn('TotalAmount',col("Quantity")* col("UnitPrice"))
ii) 查找每个客户的总消费金额:
要找到每个客户总体花费的总金额,我们只需要按
CustomerID
列分组并汇总花费的金额:
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))
将此数据帧与所有其他变量合并:
finaldf = m_val.join(df3,on='CustomerID',how='inner')
现在,我们已经创建了构建模型所需的所有变量,请运行以下代码行以仅选择所需的列并从数据帧中删除重复的行:
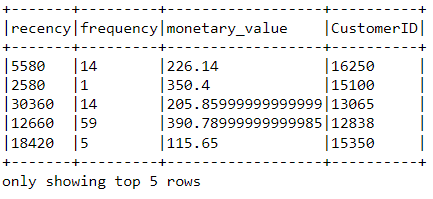
finaldf = finaldf.select(['recency','frequency','monetary_value','CustomerID']).distinct()
查看最终数据帧,以确保预处理已准确完成:
标准化
在构建客户细分模型之前,让我们对数据帧进行标准化,以确保所有变量的规模都差不多:
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.feature import StandardScaler
assemble=VectorAssembler(inputCols=['recency','frequency','monetary_value'], outputCol='features')
assembled_data=assemble.transform(finaldf)
scale=StandardScaler(inputCol='features',outputCol='standardized')
data_scale=scale.fit(assembled_data)
data_scale_output=data_scale.transform(assembled_data)
运行以下代码行,查看标准化特征向量的样子:
data_scale_output.select('standardized').show(2,truncate=False)

这些是将馈送到聚类分析算法中的缩放特征。
步骤 5:构建机器学习模型
现在我们已经完成了所有的数据分析和准备工作,让我们构建
K-Means
聚类模型。
该算法将使用
PySpark
的机器学习 API 创建。
i) 查找要使用的集群数量
在构建
K-Means
聚类模型时,我们首先需要确定我们希望算法返回的聚类或组的数量。例如,如果我们决定三个集群,那么我们将有三个客户群。
用于决定在 K-Means 中使用多少个聚类的最流行的技术称为“肘部方法”。
只需对各种聚类运行 K-Means 算法并可视化每个聚类的模型结果即可。该图将有一个看起来像肘部的拐点,我们此时只需选择聚类的数量。
让我们运行以下代码行来构建一个从 2 到 10 个聚类的
K-Means
聚类算法:
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import numpy as np
cost = np.zeros(10)
evaluator = ClusteringEvaluator(predictionCol='prediction', featuresCol='standardized',metricName='silhouette', distanceMeasure='squaredEuclidean')for i inrange(2,10):
KMeans_algo=KMeans(featuresCol='standardized', k=i)
KMeans_fit=KMeans_algo.fit(data_scale_output)
output=KMeans_fit.transform(data_scale_output)
cost[i]= KMeans_fit.summary.trainingCost
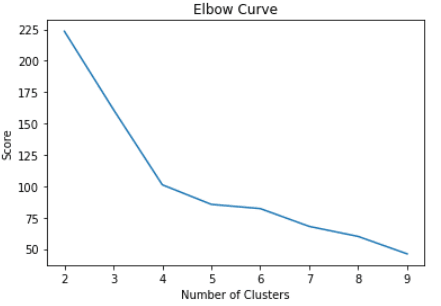
通过上述代码,我们成功地构建并评估了具有 2 到 10 个聚类的 K-Means 聚类模型。结果已放置在一个数组中,现在可以在折线图中可视化:
import pandas as pd
import pylab as pl
df_cost = pd.DataFrame(cost[2:])
df_cost.columns =["cost"]
new_col =range(2,10)
df_cost.insert(0,'cluster', new_col)
pl.plot(df_cost.cluster, df_cost.cost)
pl.xlabel('Number of Clusters')
pl.ylabel('Score')
pl.title('Elbow Curve')
pl.show()
上面的代码将呈现以下图表:
ii) 构建 K-Means 聚类模型
从上图中,我们可以看到有一个拐点,看起来像四点处的肘部。因此,我们将继续构建具有四个聚类的 K-Means 算法:
KMeans_algo=KMeans(featuresCol='standardized', k=4)
KMeans_fit=KMeans_algo.fit(data_scale_output)
iii) 做出预测
让我们使用我们创建的模型将集群分配给数据集中的每个客户:
preds=KMeans_fit.transform(data_scale_output)
preds.show(5,0)
请注意,此数据帧中有一个“预测”列,它告诉我们每个 CustomerID 属于哪个集群:
步骤 6:聚类分析
整个教程的最后一步是分析我们刚刚构建的客户群。
运行以下代码行以可视化数据帧中每个 customerID 的新近度、频率和货币值:
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select('recency','frequency','monetary_value','prediction')
df_viz = df_viz.toPandas()
avg_df = df_viz.groupby(['prediction'], as_index=False).mean()
list1 =['recency','frequency','monetary_value']for i in list1:
sns.barplot(x='prediction',y=str(i),data=avg_df)
plt.show()
上面的代码将呈现以下图:
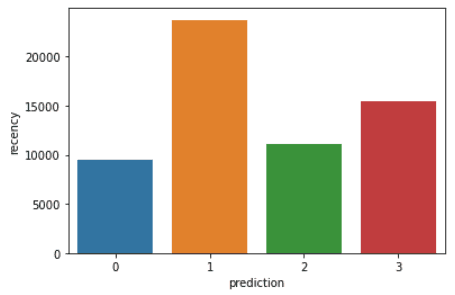
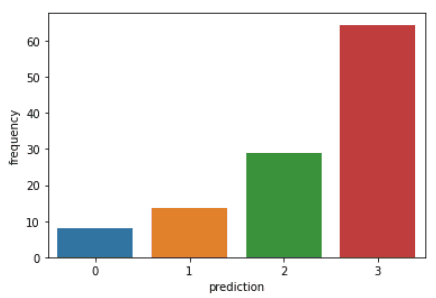
以下是客户在每个集群中显示的特征的概述:
类别0: 此细分市场中的客户显示新近度、频率和货币价值较低。他们很少在平台上购物,并且是低潜在客户,他们可能会停止与电子商务公司开展业务。
类别1: 此集群中的用户表现出较高的新近度,但尚未看到在平台上花费太多。他们也不经常访问该网站。这表明他们可能是刚刚开始与该公司开展业务的新客户。
类别2: 该细分市场的客户表现出中等的新近度和频率,并在平台上花费大量资金。这表明他们倾向于购买高价值物品或进行批量购买。
类别33: 最后一个细分市场包括在平台上表现出高新近度并频繁购买的用户。但是,他们在平台上花费不多,这可能意味着他们倾向于在每次购买中选择更便宜的商品。
版权归原作者 sssugarr 所有, 如有侵权,请联系我们删除。