
CAP定理下:Zookeeper、Eureka、Nacos简单分析
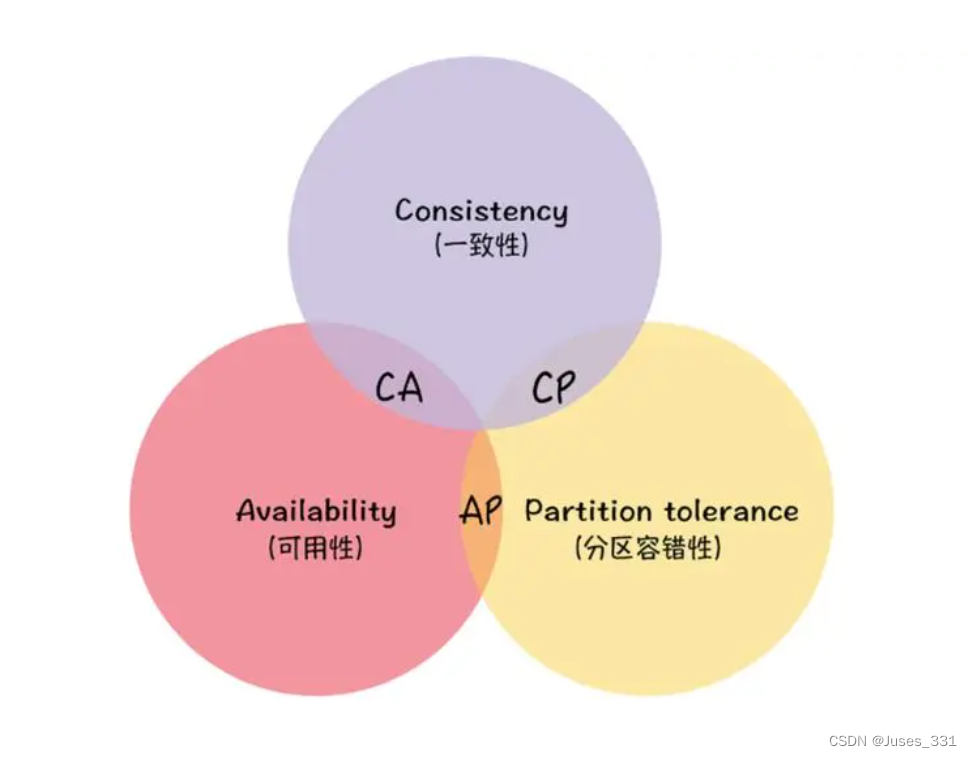
CAP定理
C: 一致性(Consistency):写操作之后的读操作也需要读到之前的
A: 可用性(Availability):收到用户请求,服务器就必须给出响应
P: 分区容错性(Partition tolerance):系统中任意信息的丢失或失败不会影响系统的继续运作
CAP定理指的是在一个分布式系统中,C、A、P三者不可兼得
由于P是无法避免的,P总是成立的,故剩下的C和A无法同时做到,因为CA场景下通信可能会失败(即出现分区容错),类似于加锁不加锁。
火车票场景:放弃一致性实现AP
银行转账:放弃分区容错性实现CA
Zookeeper
实现:CP(一致性+分区容错性)
ZK选择放弃了高可用性,为达到了强一致性,采用了ZAB(Zookeeper Atomic Broadcast)协议,即原子广播协议来保证分布式事务的一致性(C),大概内容如下:
1)发现:必须选举出一个Leader进城,维护一个Follower客户端列表
2)同步:Leader负责与Followers同步数据,多副本保存(高可用、分区容错)
3)广播:Leader可接受客户端新的proposal请求,并广播给Followers
- 所有的事务必须由一个全局唯一的服务器来协调处理
- Leader将客户端请求转换为一个事务proposal广播给所有的Followers,然后等待所有Follower的ACK确认反馈,有一半Follower反馈就会向所有Follower下发commit请求,让他们将上一个事务proposal提交执行(二阶段提交)
所以,ZK集群在进行消息同步的时候,必须由一半以上的节点完成了同步才会生效返回,当Leader或过半节点不可用时,会重新进行Leader选举(选举模式),过程中就无法对外提供服务(无A)。但是对于服务发现注册组件来说,就算无法及时获得最新的服务列表,一般也不会导致系统整体的崩溃。
Eureka
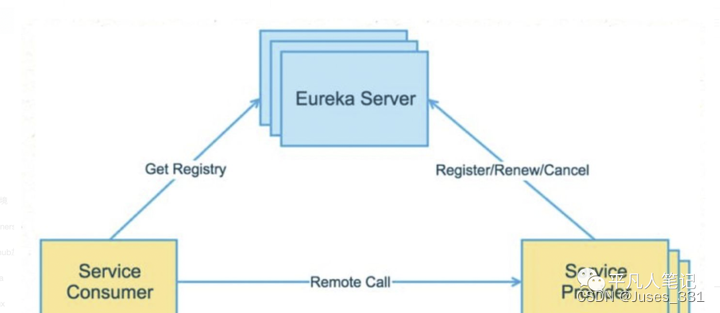
实现:AP(可用性+分区容错性)
从Eureka的架构可知,他使用的是去中心化的模式,各个节点是平等的且没有主从概念,通过互相通讯注册的方式来实现消息的同步,自然保证了高可用性(A)。在消息同步时,Eureka并不对消息的抵达进行保证,
Nacos
实现:CP/AP均支持
1)AP:注册时临时存在于注册中心,即临时节点模式,会在服务下线或不可用时,或是心跳检测无响应时,更新其健康状态,过一段时间进行列表节点删除。(放弃一致性)在此模式下,Nacos集群中的节点之间通过Distro协议同步实例注册消息(Distro协议保证的是最终一致性)
2)CP:注册永久节点,通过注册中心主动探活,去探测永久实例的状态,在Nacos集群中通过Raft协议更新实例列表(类似zk的ZAB协议,选举过程中nacos集群不可用)
版权归原作者 Juses_331 所有, 如有侵权,请联系我们删除。