
⭐️写在前面
- 这里是温文艾尔的学习之路
- 👍如果对你有帮助,给博主一个免费的点赞以示鼓励把QAQ
- 👋博客主页🎉 温文艾尔的学习小屋
- ⭐️更多文章👨🎓请关注温文艾尔主页📝
- 🍅文章发布日期:2022.02.22
- 👋java学习之路!
- 欢迎各位🔎点赞👍评论收藏⭐️
- 🎄冲冲冲🎄
- ⭐️上一篇内容:【java语言每日一练】线索二叉树专题精选
文章目录

⭐️1.java类加载器有哪些
JDK自带有三个类加载器:
BootStrapClassLoader
、
ExtClassLoader
、
AppClassLoader
- BootStrapClassLoader是ExtClassLoader的父类加载器,负责加载%JAVA_HOME%lib下的jar包和class文件。
- ExtClassLoader是AppClassLoader的父类加载器,负责加载%JAVA_HOME%/lib/ext文件夹下的jar包和class类。
- AppClassLoader是自定义类加载器的父类,也是默认的类加载器,负责加载classpath(我们自己写的代码以及引入的一些jar包)下的类文件,它不仅是系统类加载器,也是线程上下文加载器
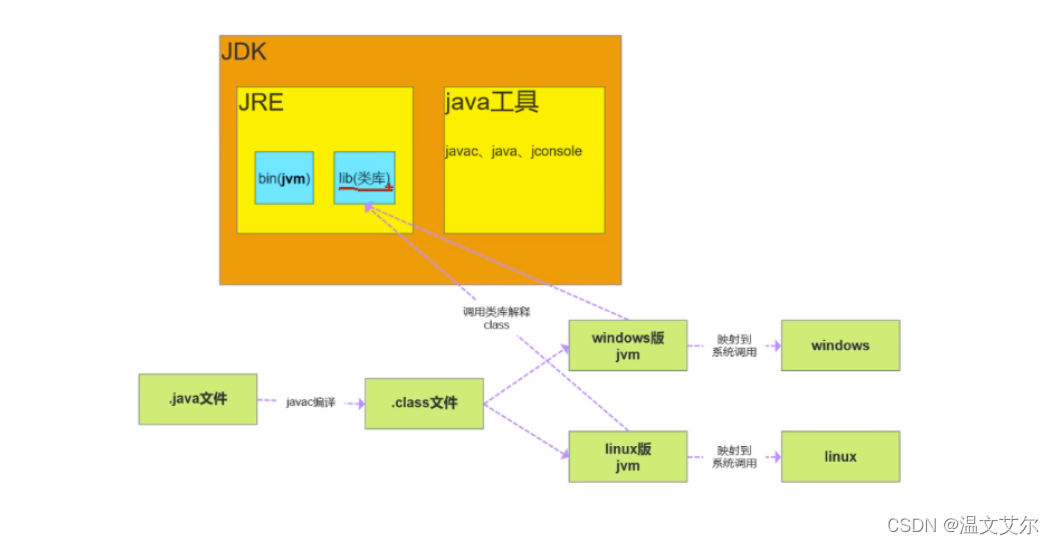
⭐️2.JDK、JRE、JVM三者区别和联系
JDK:java 开发工具,提供给开发人员
java Develpment Kit
JRE:java运行时环境,提供给运行程序的用户
java Runtime Environment
JVM:java虚拟机,解释class文件为机器码,使操作系统能够顺利执行
java Virtual Machine
- JVM = Java虚拟机
- JRE = JVM + 基础类库
- JDK = JVM + 基础类库 + 编译工具
⭐️三者关系图
⭐️3.==和equals的区别
==:对比的是栈中的值,对于基本数据类型比较变量值,对于引用数据类型比较堆中内存对象的地址
equals:在Object中默认也是采用==比较,通常会重写

我们可以看看在String中对equals的处理
publicbooleanequals(Object anObject){if(this== anObject){returntrue;}if(anObject instanceofString){String anotherString =(String)anObject;int n = value.length;if(n == anotherString.value.length){char v1[]= value;char v2[]= anotherString.value;int i =0;while(n--!=0){if(v1[i]!= v2[i])returnfalse;
i++;}returntrue;}}returnfalse;}
上述代码可以看出,String类中被重写的equals()方法其实是比较两个字符串的内容
publicclassTest01{publicstaticvoidmain(String[] args){String str1 ="Hello";String str2 =newString("Hello");String str3 = str2;//引用传递System.out.println(str1 == str2);//falseSystem.out.println(str1 == str3);//falseSystem.out.println(str2 == str3);//trueSystem.out.println(str1.equals(str2));//trueSystem.out.println(str1.equals(str3));//trueSystem.out.println(str2.equals(str3));//true}}
⭐️4.final
4.1简述final作用
修饰类:表示类不可被继承
修饰方法:表示方法不可被子类覆盖,但是可以重载
修饰变量:表示变量一旦被赋值就不可以更改它的值
修饰成员变量
1.如果final修饰的是类变量,只能在静态初始化块中指定初始值或者声明该类变量时指定初始值
finalstaticint a =0;//在声明的时候就需要赋值,或者静态代码块赋值// static {// a = 0;// }
2.如果final修饰的是成员变量,可以在非静态初始化块、声明该变量或者构造器中执行初始值
finalint b =0;//在声明的时候就需要赋值,或者代码块中赋值或者构造器中赋值// {// b = 0;// }
修饰局部变量
1.系统不会为局部变量进行初始化,局部变量必须由程序员显示初始化,因此使用final修饰局部变量时,既可以在定义时指定默认值(后面的代码不能对变量再赋值),也可以不指定默认值,而在后面的代码中对final变量赋初值(仅一次)
finalint localA;//局部变量只声明没有初始化,不会报错,与final无关
localA =0;//在使用前一定要赋值// localA = 1;//不允许第二次赋值
修饰基本类型数据和引用类型数据
- 如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;
- 如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象,但是引用的值是可变的
publicclassTest03{publicstaticvoidmain(String[] args){finalint[] iArr={1,2,3,4};
iArr[2]=-3;//合法// iArr=null;//非法,对iArr不能重新赋值finalPerson p =newPerson();
p.setAge(24);//合法// p=null;//非法}}
4.2为什么局部内部类和匿名内部类只能访问局部final变量
packageday01;/**
* Description
* User:
* Date:
* Time:
*/publicclassTest04{publicstaticvoidmain(String[] args){}publicvoidtest(finalint b){finalint a =10;//匿名内部类newThread(){@Overridepublicvoidrun(){System.out.println(a);System.out.println(b);};}.start();}}classOutClass{privateint age =12;publicvoidoutPrint(finalint x){//局部内部类classInClass{publicvoidInPrint(){System.out.println(x);System.out.println(age);}}newInClass().InPrint();}}
首先需要知道的一点是:内部类和外部类是处于同一个级别的,内部类不会因为定义在方法中就会随着方法的执行完毕就被销毁。
这里就会产生问题:当外部类的方法结束时,局部变量就会被销毁了,但是内部类对象可能还存在(只是没有人再引用它时,才会死亡)。这里就出现了一个矛盾:内部类对象访问了一个不存在的变量,为了解决这个问题,就将局部变量复制了一份作为成员变量,这样当局部变量死亡后,内部类仍可以访问它,实际访问的是局部变量的copy,这样就好像延长了局部变量的生命周期
将局部变量复制为内部类的成员变量时,必须保证这两个变量是一样的,也就是如果我们在内部类中修改了成员变量,方法中的局部变量也要跟着改变
为了解决这个问题,我们就将局部变量设置为final,对它初始化后,就不再允许修改这个变量,就保证了内部类的成员变量和方法的局部变量的一致性。这实际上也是一种妥协。使局部变量与内部类内建立的拷贝保持一致
⭐️5.String、StringBuffer、StringBuilder区别及使用场景
String是final修饰的,不可变,每次操作都会产生新的String对象
StringBuffer和StringBuilder都是在原对象上操作
StringBuffer是线程安全的,StringBuilder是线程不安全的,因为StringBuffer方法都是synchronized修饰的
性能比较
StringBuilder>StringBuffer>String
应用场景
经常需要改变字符串内容时使用StringBuffer或StringBuilder,因为String改变字符串内容会创建新对象,StringBuffer和StringBuilder中优先使用StringBuilder,多线程使用共享变量时使用StringBuffer
⭐️6.重载和重写的区别
重载:发生在同一个类中,方法名必须相同,参数类型不同,个数不同,顺序不同(前面三点有一点满足即为重载),方法返回值和访问修饰符可以不痛,方法的重载发生在编译时
重写:发生在父子类中,方法名,参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为private则子类就不能重写该方法
请问下面的方法是重载吗?
publicintadd(int a,String b)publicStringadd(int a,String b)
上述方法不是重载,并且编译器会报错,是不是重载和返回值没有关系
⭐️7.接口和抽象类的区别
关于抽象类我在翻看文章博客的时候发现,这里有一篇好文章,生动形象的揭示了抽象类的作用
为什么使用抽象类?有什么好处?
区别
- 抽象类可以存在普通成员函数,而接口中只能存在public abstract方法
- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的
- 抽象类只能继承一个,接口可以实现多个
- JDK 1.8以前,抽象类的方法默认访问权限为protected
- JDK 1.8时,抽象类的方法默认访问权限变为default
7.1接口的设计目的
对类的行为进行约束(更准确的说是一种“有”约束,因为接口不能规定类不可以有什么行为),也就是提供一种极致,可以强制要求不同的类具有相同的行为。他只约束行为的有无,但不对如何实现行为进行限制。
7.2抽象类的设计目的
代码复用。当不同的类具有某些相同的行为(记为集合A),但其中一部分行为的实现方式一致时(A的非真子集,记为B),可以让这些类派生于一个抽象类,在这个抽象类中实现了B,避免让所有的子类来实现B,这就达到了代码复用的目的。而A-B的部分,留给各个子类自己实现,正式因为A-B在这里没有实现,所以抽象类不允许实例化出来(因为有些方法是没有实现的)
所以抽象类是对类本质的抽象,表达的是is a的关系,比如BMW is a Car,抽象类包含并实现子类的通用特性,将子类存在差异化的特性进行抽象,交由子类去实现
而接口是对行为的抽象,接口的核心是定义行为,即实现类可以做什么,至于实现类主体是谁,如何实现,接口并不关心
使用场景:当你关注一个事物的本质的时候,用抽象类;当你关注一个操作的时候,用接口
抽象类的功能要远超过接口,但是定义抽象类的代价高。因为每个类只能继承一个类。在这个类中,你必须继承或编写出其所有子类的所有共性,虽然接口在功能上会弱化许多,但是它只是针对一个动物的描述,而且你可以在一个类中同时实现多个接口,在设计阶段会降低难度
⭐️8.List和Set的区别
- List:
有序,按对象进入的顺序保存对象,可重复,允许多个Null元素对象,可以使用Iterator取出所有元素,再逐一遍历,还可以使用get(int index)获取指定下表的元素 - Set:
无序,不可重复,最多允许有一个Null元素对象,取元素时只能用Iterator接口取得所有元素,再逐一遍历各个元素
⭐️9.hashCode
9.1hashCode介绍
hashCode()的作用是获取哈希码,也称为散列码;他实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode()定义在JDK的Object.java中,java中的任何类都包含有hashCode()函数。
散列表存储的是键值对(key-value),它的特点是:能根据"键"快速的检索出对应的"值"。这其中就利用到了散列码!(可以快速找到所需要的对象)
散列表这里可以参考以前的HashMap文章
HashMap底层源码解析上(超详细图解+面试题)
HashMap底层源码解析下(超详细图解)
9.2hashCode作用
以“HashSet如何重复检查重复"为例子来说明为什么要有hashCode
当对象加入HashSet时,HashSet会先计算对象的hashCode值来判断对象加入的位置,看该位置是否有值,如果没有,HashSet会假设对象没有重复出现。但是如果发现有值(出现hash冲突),这是会调用equals()方法来检查两个对象是否真的相同。如果两者相同,HashSet就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。因为hashCode让键顺利的找到值,这样大大减少了equals的次数,相应就大大提高了执行速度。
- 如果两个对象相等,
则hashcode一定也是相同的 - 两个对象相等,对两个对象分别调用equals方法都返回
true - 两个对象有相同的hashcode值,
他们也不一定是相等的(hash冲突问题) - 因此,equals方法被覆盖过,则
hashCode方法也必须被覆盖 - hashCode()的默认行为是对堆上的对象产生独特值,如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
⭐️10.ArrayList和LinkedList的区别
关于ArrayList和LinkedList可以参考我以前的文章
【源码那些事】超详细的ArrayList底层源码+经典面试题
【源码那些事】【源码那些事】LinkedList底层源码有那么难吗,一文让你学会它
ArrayList:
- 基于
动态数组,连续内存存储 - 查询快,增删慢,适合下标访问(随机访问)
ArrayList扩容机制:
第一次扩容容量为10 以后每次都是原容量的1.5倍
因为数组长度固定,超出长度存数据时需要新建数组,然后将老数组的数据拷贝到新数组,如果不是尾部插入数据还会涉及到元素的移动(往后复制一份,插入新元素),使用尾插法并制定初始容量可以极大提升性能,甚至超过linkedList(需要创建大量的node对象)
LinkedList:
- 基于
链表,可以存储在分散的内存中 - 增删快,查询慢
遍历LinkedList尽量使用iterator而不是for循环,因为for循环体内通过get(i)取得某一元素时都需要对list重新进行遍历,性能消耗极大
不要试图用indexOf等返回元素索引,并利用其锦星便利,使用indexOf对list进行了遍历,当结果为空时会遍历整个列表
如果感觉有用请三连支持一下博主,你的支持是我继续更新的动力
版权归原作者 温文艾尔 所有, 如有侵权,请联系我们删除。