
虚拟机 安装jdk
对jdk安装包进行解压
使用xftp连接虚拟机,将jdk和hadoop的安装包放到opt目录下
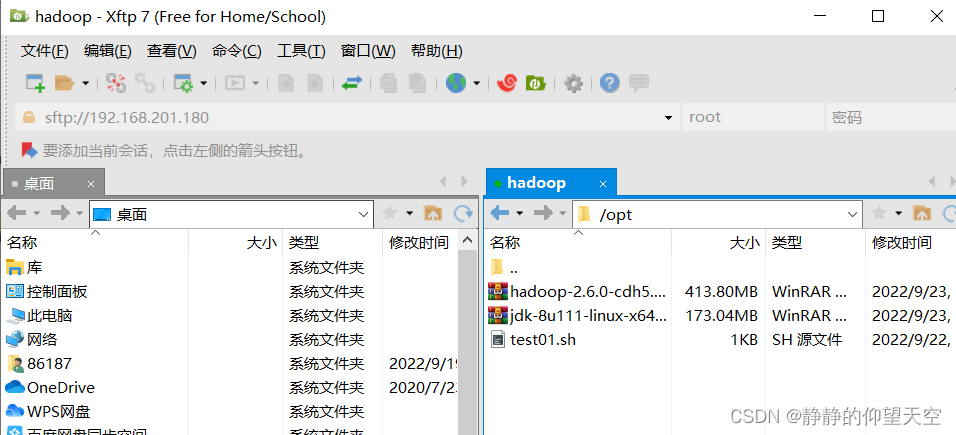
连接虚拟机
cd /opt/ 切换到opt目录下
tar -zxf jdk-8u111-linux-x64.tar.gz
对jdk-8u111-linux-x64.tar.gz 这个压缩包进行解压
解压完之后 文件名:jdk1.8.0_111
mkdir soft
在opt目录下创建soft文件夹
mv jdk1.8.0_111/ soft/jdk180
将jdk1.8.0_111文件移动到soft文件夹下并改名为jdk180
cd soft/
切换到soft文件夹下
此时jdk已经安装完,可以用了,但是此时为绿色解压版,使用java虚拟机的话需要先进入它的目录才可以。
配置环境变量
vim /etc/profile
更改配置文件,profile就是linux的环境变量
进入文件后,移动到最后,进入编辑模式,在最后加上以下代码,将JAVA_HOME后面的路径改成自己配置的常规路径(在上面配置的),在上面加个注释java,以便于跟别的软件进行区分。
#javaexportJAVA_HOME=/opt/soft/jdk180
exportCLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
exportPATH=$PATH:${JAVA_HOME}/bin
改完之后退出编辑模式,:wq保存退出。
source /etc/profile
激活此文件(让修改后的配置信息立即生效)
java -version
输入上述命令,若出现以下信息,表示jdk已成功安装在你的虚拟机上了。
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
安装hadoop-2.6.0-cdh5.14.2单机版
解压hadoop
cd /opt/
切换到opt目录下
tar -zxf hadoop-2.6.0-cdh5.14.2.tar.gz
对hadoop-2.6.0-cdh5.14.2.tar.gz进行解压,解压完之后为hadoop-2.6.0-cdh5.14.2文件夹
mv hadoop-2.6.0-cdh5.14.2 soft/hadoop260
将hadoop-2.6.0-cdh5.14.2文件夹移动到soft下面并改名为hadoop260
cd soft/hadoop260
切换到hadoop260目录下
此时已经解压完成,不过还不能用,因为hadoop需要大量的配置。hadoop的配置在hadoop260目录下的etc文件夹下
cd etc/hadoop
切换到hadoop的etc下的hadoop文件夹下
修改5个文件
第一个文件
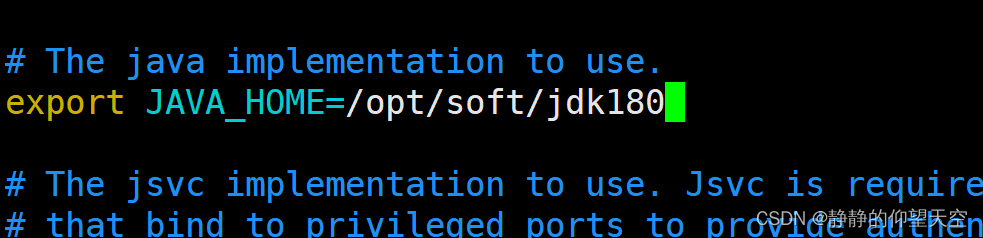
vim hadoop-env.sh
将下面图片中的JAVA_HOME后的路径改为自己配置的jdk的路径
exportJAVA_HOME=/opt/soft/jdk180
第二个文件
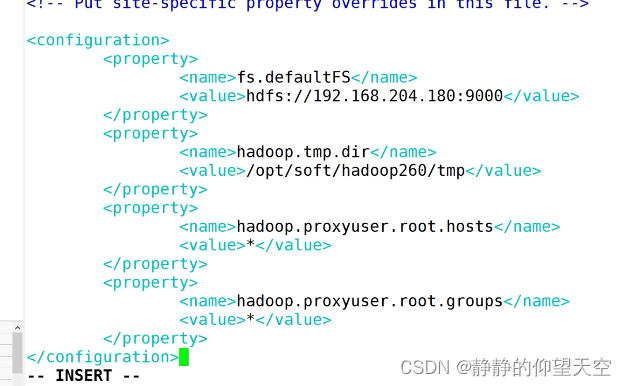
vim core-site.xml
进入文件后进入编辑模式,此时 中间为空白,加上下方代码(注释可以直接删掉),linux的存储格式为ext3、ext4
<configuration><property><!--fs是文件系统的意思,为hadoop的入口,入口路径格式为hdfs,后面跟自己的虚拟机的IP地址,后面端口为hadoop默认端口为9000--><name>fs.defaultFS</name><value>hdfs://192.168.201.180:9000</value></property><property><!--hadoop临时存储文件的目录位置,放到下方的目录中,此时tmp目录还没有,会自动建一个,默认目录在linux的临时文件夹下,可能会被别人删除--><name>hadoop.tmp.dir</name><value>/opt/soft/hadoop260/tmp</value></property><property><!--登陆权限问题--><!--表示只要是root用户都可以登陆,不管是本地还是远程--><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><!--表示不管是哪个组的root用户都可以登陆--><name>hadoop.proxyuser.root.groups</name><value>*</value></property></configuration>
第三个文件
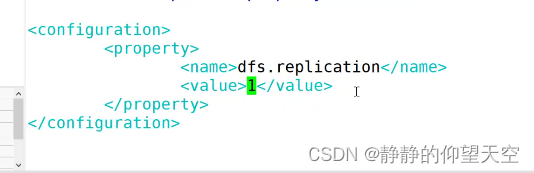
vim hdfs-site.xml
在 中间加入下方代码
<configuration><property><!--文件备份默认为3份,此时改为1份--><name>dfs.replication</name><value>1</value></property></configuration>
第四个文件,这个文件是用来启动计算引擎的
cp mapred-site.xml.template mapred-site.xml
拷贝一下mapred-site.xml.template文件,将template去掉
vim mapred-site.xml
在 中间加入下方代码
<configuration><property><!--计算引擎的名字叫做yarn,这个是资源调度器--><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
第五个文件
vim yarn-site.xml
在 中间加入下方代码
<configuration><property><!--因为装的是单机版,所有写localhost本地,装集群的时候会大幅变化,这是yarn资源调度器的两个重要配置--><name>yarn.resourcemanager.localhost</name><value>localhost</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
设置无密登陆
配置SSH
目的是使用脚本进行远程服务器的启动,必须使用shell登陆远程服务,但每个登陆都需要输入密码就非常麻烦,所有需要配置无密配置,需要在NameNode上生成私钥,把公钥发给DataNode
生成密钥对
ssh-keygen -t rsa -P ‘’
注意p为大写的P,写两个单引号表示不需要密码,然后回车,再回车
此时会生成两个文件,文件位置在哪呢
cd ~
进入账号的根目录
cd .ssh/
切换到这个目录,然后输入ls命令,就可以看到下方这两个文件
id_rsa id_rsa.pub
拷贝一份公钥给自身
会形成一个文件,输入下方命令,拷贝给自己,就在@后加自己虚拟机的ip(给远程就加远程虚拟机的ip)
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.201.180
然后回车,输入yes,输入自己虚拟机的密码
验证无密登陆是否设置成功
ssh root
之后会问是否登陆,输入yes
exit
退出一下
ssh root
在登陆,此时yes也不用输入了
格式化NameNode
首先进入hadoop的环境变量
vim /etc/profile
#hadoopexportHADOOP_HOME=/opt/soft/hadoop260
exportHADOOP_MAPRED_HOME=$HADOOP_HOMEexportHADOOP_COMMON_HOME=$HADOOP_HOMEexportHADOOP_HDFS_HOME=$HADOOP_HOMEexportYARN_HOME=$HADOOP_HOMEexportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
exportPATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
exportHADOOP_INSTALL=$HADOOP_HOME
在最后加上上方代码,#hadoop注释表示这个是hadoop的环境变量配置,便于跟其他软件进行区分,HADOOP_HOME后面的路径改成自己hadoop所在的路径,然后:wq保存退出。
source /etc/profile
激活此文件(让修改后的配置信息立即生效)
hdfs namenode -format
格式化,格式化完了hadoop才可以 启动,注意格式化不能多做,多做的话可能会出现bug。命令输入完回车,如果都是INFO,没有出现错误警告,则代表格式化成功。
启动hadoop
[root@root .ssh]# start-all.sh
回车,输入yes,yes(只有第一次启动的时候需要输)
启动完之后输入
jps
此时会看到下方除jps外的五个进程(前边的数字可能不同),看到这五个进程,代表hadoop已经运行成功了。
11569 DataNode
11721 SecondaryNameNode
11865 ResourceManager
11452 NameNode
11980 NodeManager
12268 Jps
上述步骤出现错误怎么查看(谁错找谁)
cd /opt/soft/hadoop260/logs/
切换到hadoop的日志文件夹,这是记录服务器运行信息的
ls
可以看到里边有好多文件,凡是以log作为后缀的,都是日志文件,看上面哪个进程没有,就找那个进程相关的日志文件,例:若是没有NameNode进程,就找namenode-hadoop.log
vim hadoop-root-namenode-hadoop.log
进入后就可以查看自己的错误信息,找到错误位置后退出
cd…
目录后退一层
cd etc/hadoop
切换到hadoop的etc的hadoop目录下
vim core-site.xml
哪个文件存在错误就编辑哪个,进去寻找错误,修改完之后保存退出
stop-all.sh
把hadoop停下来
start-all.sh
再启动hadoop
jps
查看进程,若五个进程全部出现,则错误修改成功
五个进程都代表什么
NameNode 名节点:存放索引,可以通过索引找到数据
DataNode 数据节点:数据存放在这里
SecondaryNameNode 第二名节点:整理名节点中的索引,会定时将名节点中的索引目录合并成一个更大的文件,方便数据量增大之后的查找,在合并前叫做edit logs文件,合并完之后叫做fsimage镜像文件,此节点起到秘书的作用,对目录进行归档合并
ResourceManager 资源管理器,监控所有节点,接收NodeManager传过来的信息,对节点进行调度
NodeManager 节点管理器,定时向ResourceManager传递信息,告诉它哪个节点忙,哪个节点闲
ResourceManager和NodeManager合并起来叫做资源调度器
版权归原作者 静静的仰望天空 所有, 如有侵权,请联系我们删除。