
一、摘 要
在信息技术不断推陈出新的背景下, 针对传统人工管理学生信息方式效率低, 提出一种基于前后端分离设计的学生信息管理系统。
本设计前端部分采用基于 Bootstrap 框架设计,采用 Jquery 进行前后端数据的交互和传递,后端功能逻辑的实现采用 Python 的 Flask 框架实现,数据库采用较为轻量的 sqlite3。
本系统设计主要为对学生信息管理的增删改查,同时实现了数据合法性验证功能,操作结果提示功能,批量删除功能,数据显示分页,为登录页面添加验证码验证等相关功能,且进行了响应性设计,支持在不同设备下使用,本程序设计是在 B/S 架构下的较为简单的学生信息管理系统。
1.1 关 键 词: 学生信息管理系统,flask,前后端分离,B/S 架构
二、ABSTRACT
In the context of the continuous innovation of information technology, in view of the low efficiency of traditional manual management of student information, a student information management system based on the design of front-end and back-end separation is proposed.
The front-end part of this design is designed based on Bootstrap framework, and Jquery is used for the interaction and transmission of front-end and back-end data, the realization of back-end functional logic is realized by Python’s Flask framework, and the database uses sqlite3,which is a relatively lightweight database.
The system design is mainly for the addition, deletion, modification, and checking of student information management. At the same time, it realizes the data legality verification function, the operation result prompt function, the batch deletion function, the data display paging, and the verification code verification for the login page and other related functions.Responsive design is carried out to support the use of different devices. This program design is a relatively simple student information management system under the B/S architecture. Key words: student information management system,flask,front-end and back-end separation,the B/S architecture
目录
基于 B/S 架构的管理信息系统 1
一、摘 要 1
1.1 关 键 词: 学生信息管理系统,flask,前后端分离,B/S 架构 1
二、ABSTRACT 1
2.1 实验目的 2
2.2 实验系统分析 2
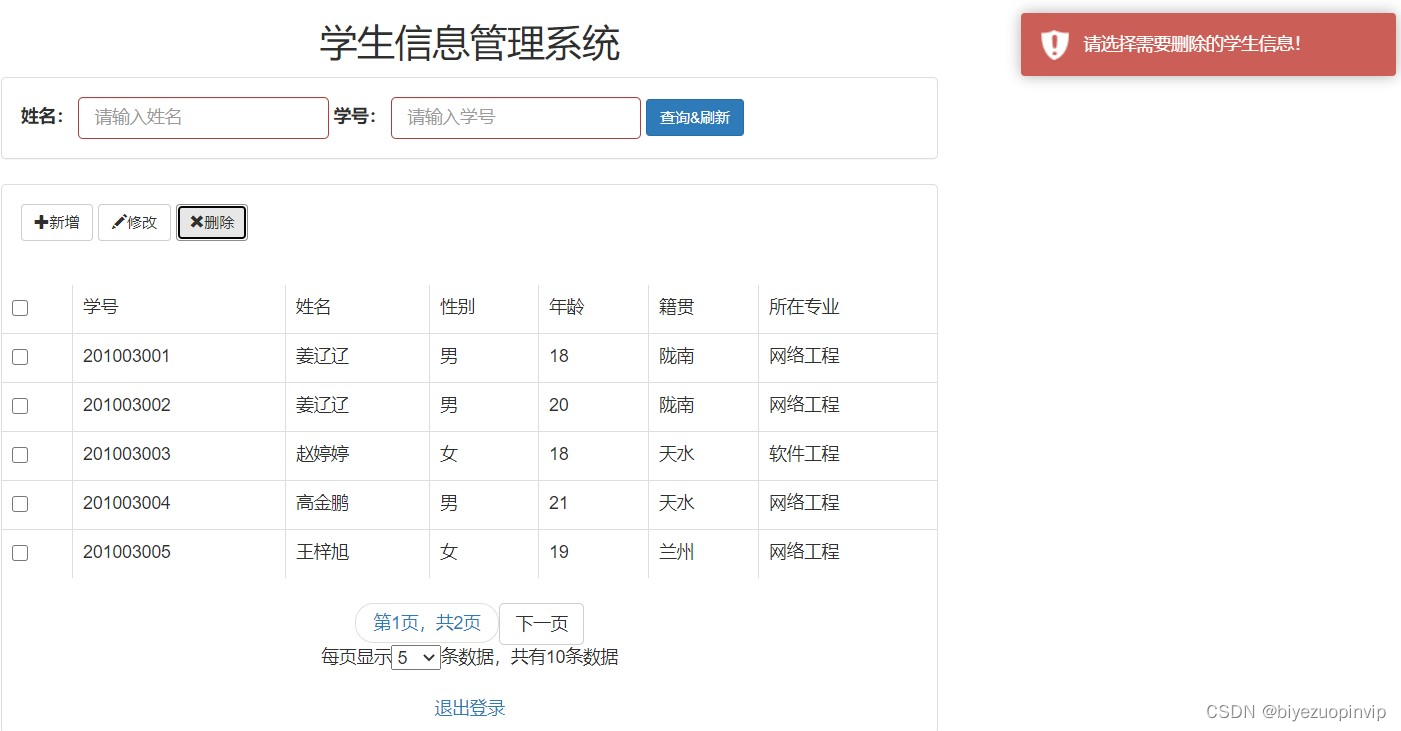
删除单个或多个学生信息 3
2.3 实验系统设计环境 4
2.3.1 系统环境配置 4
2.3.2 系统设计简介 4
2.3.3 登录界面 5
2.3.4 系统界面 7
2.3.5 新增学生界面 7
2.3.6 修改信息界面 11
2.3.7 删除学生界面 13
2.4 功能点展示及代码分析 13
2.4.1 悬浮表单(模态框) 13
2.4.2 数据完整性验证 16
2.4.3 操作结果提示 21
2.4.4 显示分页 26
2.4.5 批量删除 34
2.4.6 登录验证码 44
2.5 系统安全性及异常处理 46
2.5.1 更改 URL 绕过登录 47
2.5.2 登陆页面输入不合法 49
2.5.3 输入数据不合法 50
2.5.4 修改、删除信息时违规操作 54
三、总结与不足 57
四、项目分工情况 58
五、参考文献 58
from flask importFlask, render_template, request, url_for, redirect, session, jsonify
from dbSqlite3 import*importuuidimportloggingimportjsonimportre
from flask importFlask, request, render_template
from flask_sessionstore importSession
from flask_session_captcha importFlaskSessionCaptcha
from flask_sqlalchemy importSQLAlchemy
app =Flask(__name__)#captcha
app.config["SECRET_KEY"]= uuid.uuid4()
app.config['CAPTCHA_ENABLE']= True
app.config['CAPTCHA_NUMERIC_DIGITS']=5
app.config['CAPTCHA_WIDTH']=250
app.config['CAPTCHA_HEIGHT']=50
app.config['SQLALCHEMY_DATABASE_URI']='sqlite:///db/student_083_2.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS']= True
app.config['SESSION_TYPE']='sqlalchemy'Session(app)
captcha =FlaskSessionCaptcha(app)#captchaend#SQLAlchemy对象创建
db =SQLAlchemy(app)
# 学生专业类
classstu_profession(db.Model):
stu_profession_id = db.Column(db.Integer, primary_key=True)
stu_profession = db.Column(db.String(50))
# 学生信息类
classstudent_info(db.Model):
__tablename__ ="student_info"
stu_id = db.Column(db.Integer, primary_key=True)
stu_name = db.Column(db.String(50))
stu_sex = db.Column(db.String(2))
stu_age = db.Column(db.Integer)
stu_origin = db.Column(db.String(50))
stu_profession_id = db.Column(db.Integer, db.ForeignKey("stu_profession.stu_profession_id"))
stu_profession = db.relationship("stu_profession")
# 将学生信息类信息转换为dict输出
def student_to_dict(student_info):returndict(
stu_id=student_info.stu_id,
stu_name=student_info.stu_name,
stu_sex=student_info.stu_sex,
stu_age=student_info.stu_age,
stu_origin=student_info.stu_origin,
stu_profession=student_info.stu_profession.stu_profession,)
# 检查是否登录
def CheckLogin():if'username'not in session:return False
else:return True
@app.route('/login', methods=['POST','GET'])
def login():if request.method =="GET": # 初始情况下直接加载模板
ret ={'username':'','pwd':'','hidden':'none'}returnrender_template('login.html', ret=ret)
# 如果是post请求,说明用户尝试登录
# 从数据库获取查询结果
result, _ =GetSql2("select * from users where username='%s'"% request.form['username'])print(result)
# 用户名、密码、验证码全部验证成功,方可登录,否则登陆失败
iflen(result)>0and result[0][1]== request.form['pwd']and captcha.validate(): # 登陆成功
session["username"]= request.form['username'] # 使用session保存用户名
returnredirect(url_for('index')) # 重定向到路由"/"else: # 登陆成功,用户名和密码不清除
ret ={'username': request.form['username'],'pwd': request.form['pwd'],'hidden':'block'}returnrender_template('login.html', ret=ret)
# 清除session 登出操作
@app.route('/logout')
def logout():
session.clear()returnredirect(url_for('login'))
# 加载首页
@app.route('/', methods=['GET'])
def index():ifnotCheckLogin(): # 判断是否登录
returnredirect(url_for('login'))returnrender_template('show.html')
# 获取学生信息
@app.route('/showinfo', methods=['GET'])
def showinfo():ifnotCheckLogin(): # 检查是否登录
returnredirect(url_for('login'))
page =int(request.args.get('page',1)) # 当前页面编号
per_page =int(request.args.get('per_page',5)) # 当前页面显示几条信息
name =str(request.args.get('name',"")) # 用户查询所用的姓名
stuno =str(request.args.get('stuno',"")) # 用户查询所用的学号
'''
通过SQLAlchemy查询,query表示所查询的对象表,join表示所连接的表名称,filter相当于sql中where语句对查询进行筛选,
orderby表示按列进行排序,这里以学号为顺序。paginate用来分页,page表示当前所在页,per_page表示每页展示的数据个数
error_out表示是否对错误信息进行输出 like和sql中一样
'''
if name ==""and stuno =="": # 没有查询关键字
paginate = db.session.query(student_info).join(stu_profession). \
filter(student_info.stu_profession_id == stu_profession.stu_profession_id). \
order_by(student_info.stu_id).paginate(page, per_page, error_out=False)
elif name !=""and stuno =="":
paginate = db.session.query(student_info).join(stu_profession). \
filter(student_info.stu_profession_id == stu_profession.stu_profession_id). \
filter(student_info.stu_name.like('%%%s%%'% name)). \
order_by(student_info.stu_id).paginate(page, per_page, error_out=False)
elif name ==""and stuno !="":
paginate = db.session.query(student_info).join(stu_profession). \
filter(student_info.stu_profession_id == stu_profession.stu_profession_id). \
filter(student_info.stu_id.like('%%%s%%'% stuno)). \
order_by(student_info.stu_id).paginate(page, per_page, error_out=False)else:
paginate = db.session.query(student_info).join(stu_profession). \
filter(student_info.stu_profession_id == stu_profession.stu_profession_id). \
filter(student_info.stu_name.like('%%%s%%'% name)). \
filter(student_info.stu_id.like('%%%s%%'% stuno)). \
order_by(student_info.stu_id).paginate(page, per_page, error_out=False)
stus = paginate.items # 获取分页得到的学生信息
ret =[] # 存储格式化后的学生信息结果
for stu in stus: # 对获取到的所有学生信息遍历,以对单个学生信息类进行处理
ret.append(student_to_dict(stu)) # 将处理后的结果存储到返回信息中
'''
向前端返回有关分页的信息,has_prev:是否为第一页,prev_num为前一页,pages为共有多少页,next_num为后一页
total为总共的数据量,per_page为每页的数据量,page为当前页数
'''
ret_paginate ={'has_prev':('yes'if paginate.has_prev else'no'),'prev_num': paginate.prev_num,'pages': paginate.pages,'next_num': paginate.next_num,'total': paginate.total,'per_page': per_page,'page': paginate.page}returnjsonify({'stuinfo': json.dumps(ret, ensure_ascii=False),'paginate': ret_paginate}) # 返回学生信息和有关分页信息
# 添加学生信息操作
@app.route('/add', methods=['GET','post'])
def add():ifnotCheckLogin():returnredirect(url_for('login'))if request.method =="GET": # 通过get方法返回学生的专业信息
datas, _ =GetSql2("select * from stu_profession")returndict(datas)else: # post 请求方法
# 从前端Ajax获取到的拟新增的学生信息并字典化
data =dict(
stu_id=request.form['stu_id'],
stu_name=request.form['stu_name'],
stu_sex=request.form['stu_sex'],
stu_age=request.form['stu_age'],
stu_origin=request.form['stu_origin'],
stu_profession_id=request.form['stu_profession'])
res ={'code':500,'message':'添加失败!'} # 初始化返回结果为错误
# 正则表达式判断获取的信息是否符合规范
matchid = re.search(r'^\d{9,12}$', data['stu_id'])
matchname = re.search(r'^[\u4e00-\u9fa5]{2,6}$', data['stu_name'])
matchsex = re.search(r'^男$|^女$', data['stu_sex'])
matchage = re.search(r'^\d{1,3}$', data['stu_age'])
matchorigin = re.search(r'^[\u4e00-\u9fa5]{2,10}$', data['stu_origin'])
matchprofession = re.search(r'^\d{1,3}$', data['stu_profession_id'])
# 后台终端输出判断的测试以便调试
print(matchid)print(matchname)print(matchsex)print(matchage)print(matchorigin)print(matchprofession)
# 判断是否符合
if matchid and matchname and matchsex and matchage and matchorigin and matchprofession:InsertData(data,"student_info") # 符合则进行插入数据库操作
res ={'code':200,'message':'成功添加!'}else:
res ={'code':500,'message':'添加失败!'}
# 返回结果
return json.dumps(res, ensure_ascii=False)
# 修改学生信息操作
@app.route('/update', methods=['GET','post'])
def update():ifnotCheckLogin():returnredirect(url_for('login'))if request.method =="GET": # get请求用来进行从数据库获取要修改的学生的原始数据
stuid = request.args['id'] # 从前端获取的学生学号
result, _ =GetSql2("select * from student_info where stu_id='%s'"% stuid) # 进行查询
# 将通过sql查询的结果字典化 并作为返回值传给前端
ret ={'stu_id': result[0][0],'stu_name': result[0][1],'stu_sex': result[0][2],'stu_age': result[0][3],'stu_origin': result[0][4],'stu_profession_id': result[0][5]}print(ret)return ret
else: # post请求用来进行修改 以下代码和上面add()的post请求方法一样
data =dict(
stu_id=request.form['stu_id'],
stu_name=request.form['stu_name'],
stu_sex=request.form['stu_sex'],
stu_age=request.form['stu_age'],
stu_origin=request.form['stu_origin'],
stu_profession_id=request.form['stu_profession'])
res ={'code':500,'message':'添加失败!'}
matchid = re.search(r'^\d{9,12}$', data['stu_id'])
matchname = re.search(r'^[\u4e00-\u9fa5]{2,6}$', data['stu_name'])
matchsex = re.search(r'^男$|^女$', data['stu_sex'])
matchage = re.search(r'^\d{1,3}$', data['stu_age'])
matchorigin = re.search(r'^[\u4e00-\u9fa5]{2,10}$', data['stu_origin'])
matchprofession = re.search(r'^\d{1,3}$', data['stu_profession_id'])print(matchid)print(matchname)print(matchsex)print(matchage)print(matchorigin)print(matchprofession)if matchid and matchname and matchsex and matchage and matchorigin and matchprofession:UpdateData(data,"student_info")
res ={'code':200,'message':'成功添加!'}else:
res ={'code':500,'message':'添加失败!'}#InsertData(data,"student_info")#res={'code':200,'message':'成功添加!'}return json.dumps(res, ensure_ascii=False)
# 删除学生信息,根据单个id直接删除
@app.route('/del/<id>', methods=['GET'])
def delete(id):ifnotCheckLogin():returnredirect(url_for('login'))DelDataById("stu_id", id,"student_info") # 如果能正常执行则能正常删除,否则直接报错。
res ={'code':200,'message':'成功添加!'}return res
# 主函数调用
if __name__ =='__main__':
app.run(debug=True)
































版权归原作者 biyezuopinvip 所有, 如有侵权,请联系我们删除。