
文章目录
前言
微服务间相互调用的基础上,服务间的调用更多是以调用某多实例服务下的某个实例的形式。而这就需要用到负载均衡技术。对于开发者而言,只要通过@LoadBalance注解就开启了负载均衡。如此简单的操作底层究竟是什么样的,我想你也很想知道。
1.调用形式
在《SpringCloud集成Eureka并实现负载均衡》的基础之上,我们可以进行一个小小的实验,debug运行程序,通过postman发起一个请求,A服务会去远程调用B服务,debug发现发送的url为:http://user-service/user/1,毫无疑问的是,这就是A调用B的途径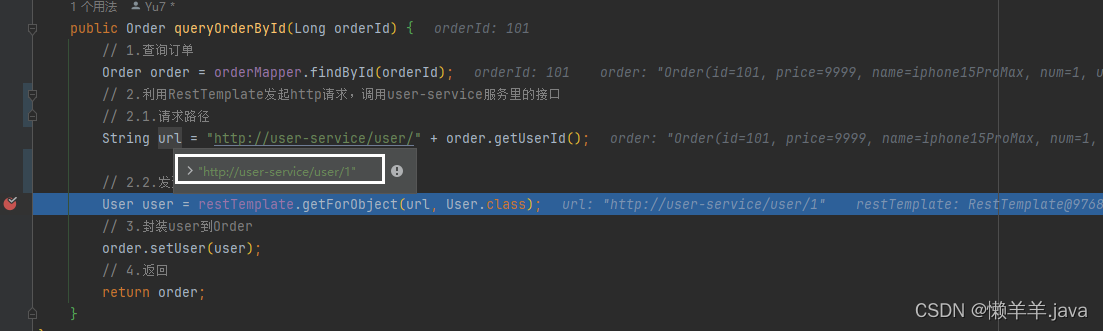
同样地,拿到这个url我们去postman里发送请求: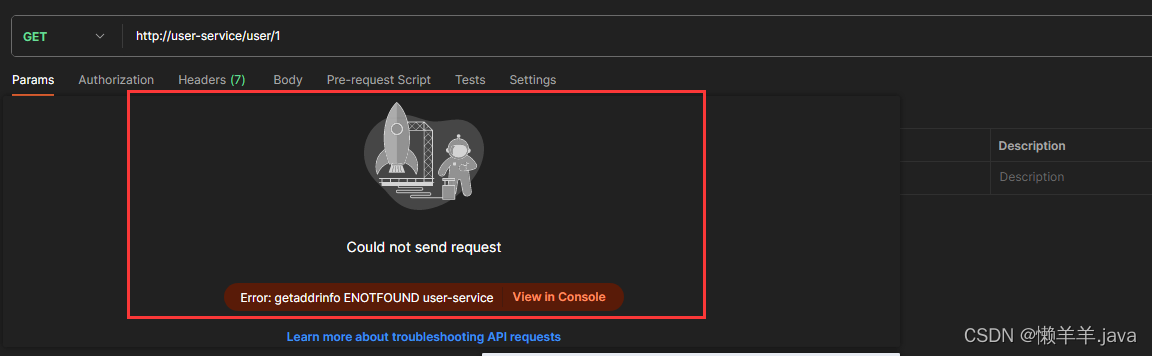
发现请求无法发送出去,路径出了问题。观察路径中的参数user-service发现他是B服务的服务名称,那为什么在A服务里向B服务发送“服务名称-接口路径-参数”形式的请求就能够正常响应?
结合集成负载均衡的过程,这一定是Ribbon在发挥作用
2.LoadBalancerInterceptor
负载均衡的前提不是传递一个具体的url,肯定是Ribbon做了某种解析,通过服务名称得到了服务下的实例列表,从而拉取Eureka-Server中的服务注册表来将请求映射到指定的某个实例上。
结合曾经前后端分离的web开发经验,后端经常会在拦截器中拦截前端发来的请求来对请求做一些操作,比如校验、拼接、鉴权…调用方发送请求和接收方收到的请求并不一致,这其中会不会也是有一个类似于拦截器的东西拦截了请求,并且转换了请求呢?
答案是必然的,那是谁——LoadBalancerInterceptor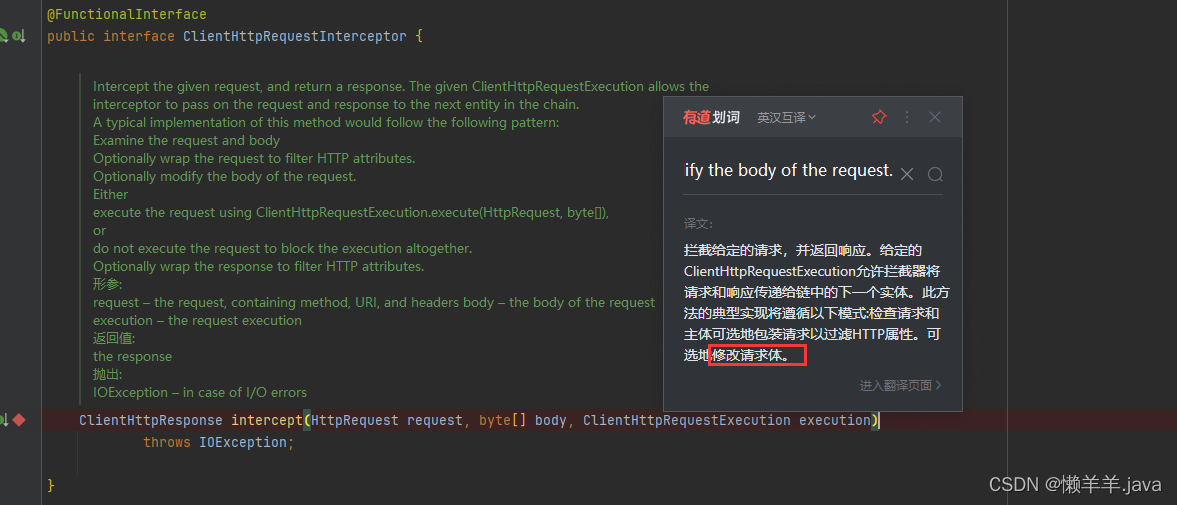
可以看到的是,他实现了ClientHttpRequestInterceptor接口,具体用法细节直接去看接口中声明的方法
直观的看出接口中声明了一个intercept()方法并且接受了HttpRequest参数来拦截了客户端的http请求,并且修改的请求体!这么一看URL更改的谜底就在此处揭晓了,那么方法底层具体是怎么实现的呢:
3.负载均衡流程分析
3.1 调用流程图
Debug源码之前先来看一下源码中的调用链路总体流程图(手图):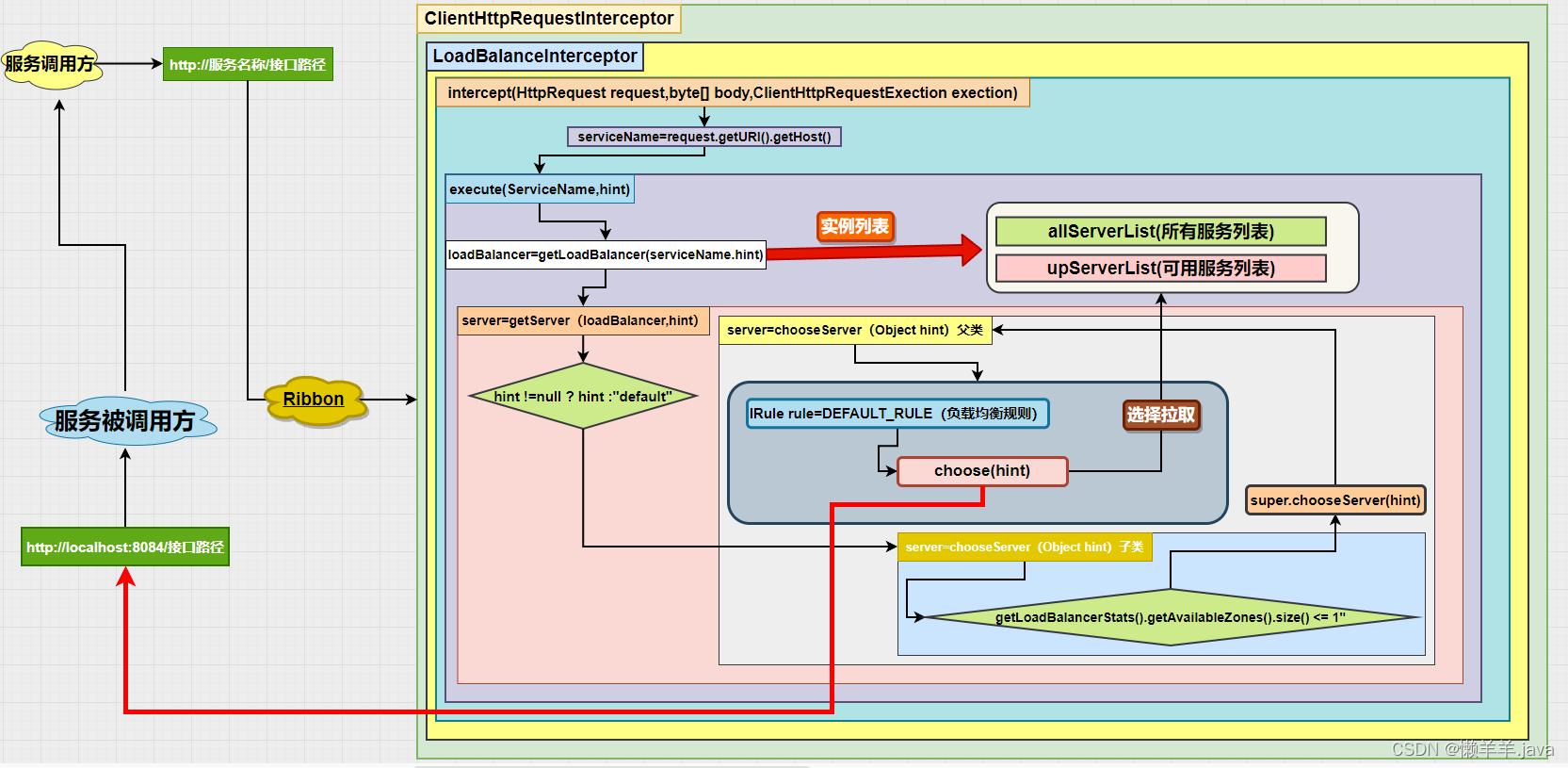
概括来看则是:拦截请求—读取服务—拉取服务列表—选择规则—返回服务实例
3.2 intercept()方法
下面我们开始Debug:
1.当发送请求使得服务间发生调用关系,调用请求会先传递到拦截器中的intercept方法,可以看到的是目前还和发送是保持一致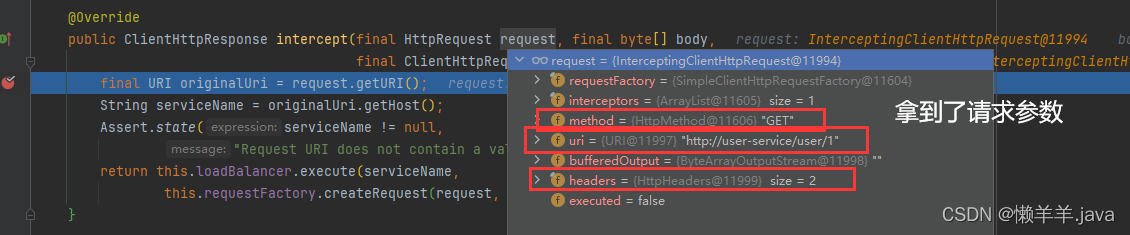
2.继续向下执行,开始解析请求,拿到了请求中的URI——通过getHost()方法拿到了主机地址(服务的名称)
3.3 execute()方法
3.Ribbon开始做负载均衡处理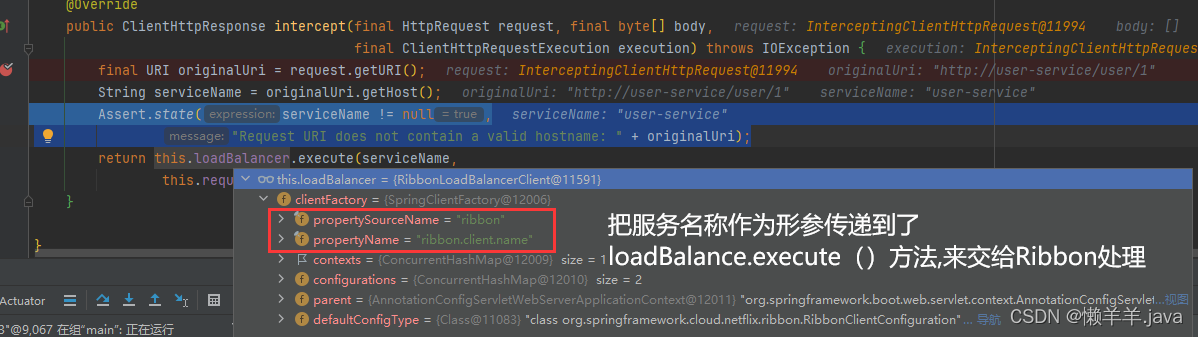
4.两次步入之后进入到execute()方法内部,发现传递进来的服务名称作为服务Id进入到了getLoadBalance()方法,并且得到了一个ILoadbalance接口对象,而在该对象中封装了很多的信息: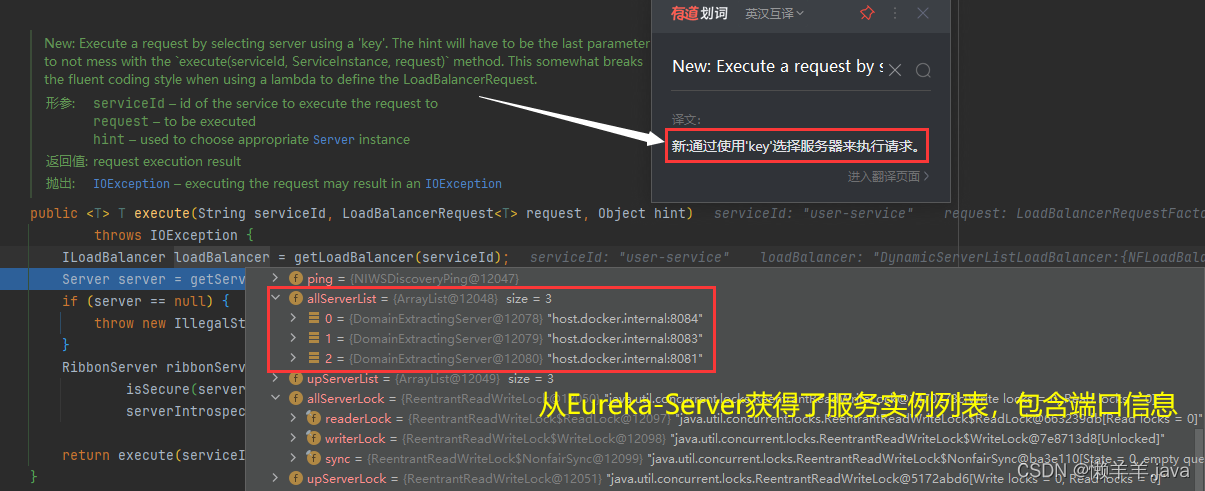
这里记住服务实例id的值:host.docker.internal:8084,这就是Eureka客户端接收到的实例信息
3.4 getServer()方法
5.接口对象作为参数传递到了getServer()方法,得到了一个server对象进入到方法内部。发现与此同时传递了一个Object类型的对象用于指定服务器的规则或条件,不过到目前为止,这个参数一直都是null作为传递,即loadBalancer.chooseServer()方法采用的是‘default’的方式进行选择
3.4 子类的chooseServer()方法
6.再次步入到chooseServer()方法,发现是在一个名为BaseLoadBalancer类(这个类是负载均衡器的具体实现后面会具体分析)下重写的父类方法
此时:可以判断的是getLoadBalancerStats().getAvailableZones().size() <= 1为TRUE
3.5 getLoadBalancerStats().getAvailableZones().size() <= 1
对于表达式:getLoadBalancerStats().getAvailableZones().size() <= 1进行分析
发现在BaseLoadBalancer类中通过继承抽象类AbstractLoadBalancer并重写getLoadBalancerStats()抽象方法,获取到了一个loadbalancer统计信息集合LoadBalancerStats
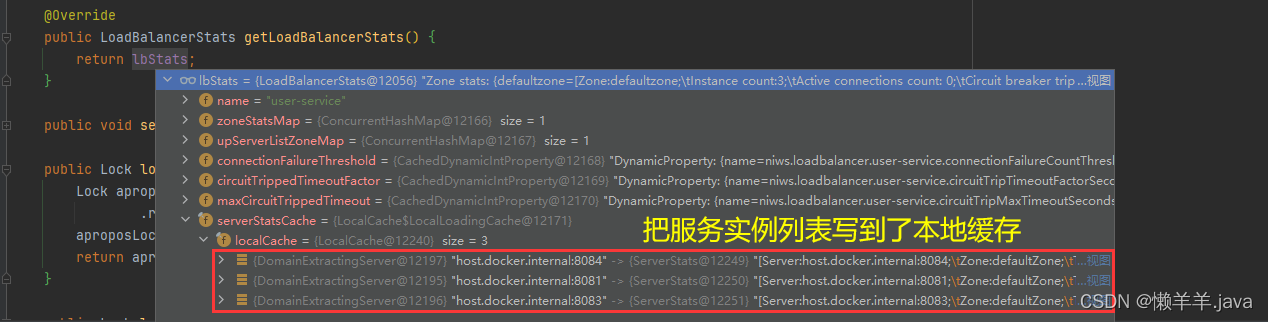
而封装在LoadBalancerStats中的信息里有一个ConcurrentHashMap类型的集合属性,即
volatileMap<String,List<?extendsServer>> upServerListZoneMap =newConcurrentHashMap<String,List<?extendsServer>>();
用于存储可用的服务列表,这个集合中的每个条目都代表一个区域,键是区域名称,值是该区域下可用服务器的列表。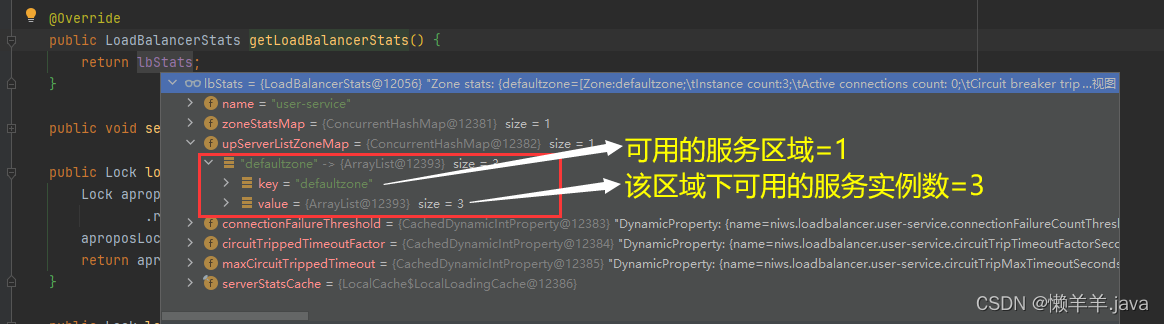
后续的.getAvailableZones()方法则是获取这一属性值中所有的键,也就是可用的服务区域,并作为Set集合返回来进行判断
很显然,这里进一步论证getLoadBalancerStats().getAvailableZones().size() <= 1是为true的,后续就会去调用父类的chooseServer()方法
3.6 父类的chooseServer()方法
7.步入到父类的chooseServer()方法中,发现最后返回了一个Server类型的对象,这肯定就是具体的服务实例信息了。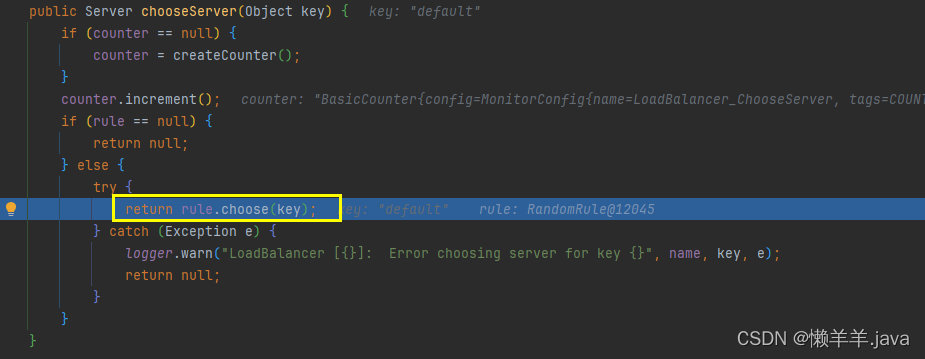
3.7 IRule接口下的实例
去追踪rule变量,发现是一个IRule接口的实例,即为负载均衡提供规则的接口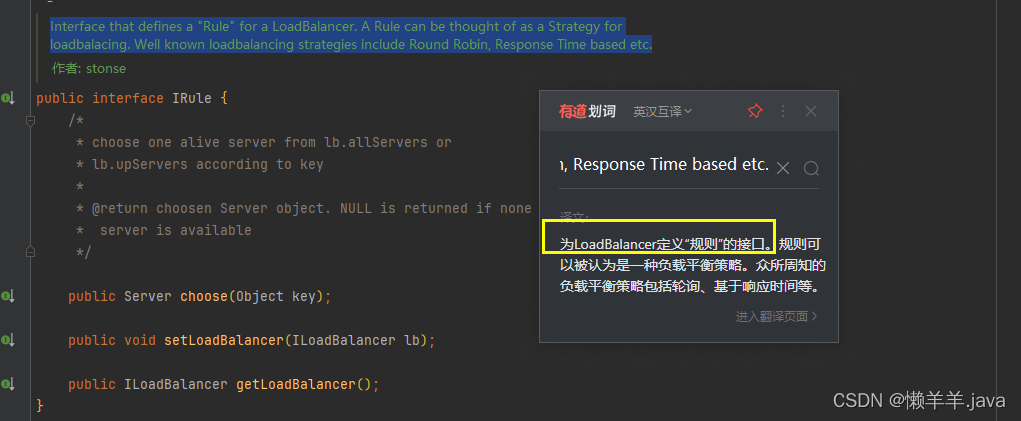
并且此接口下有大量的规则实现,而默认的规则方式则为轮询调度: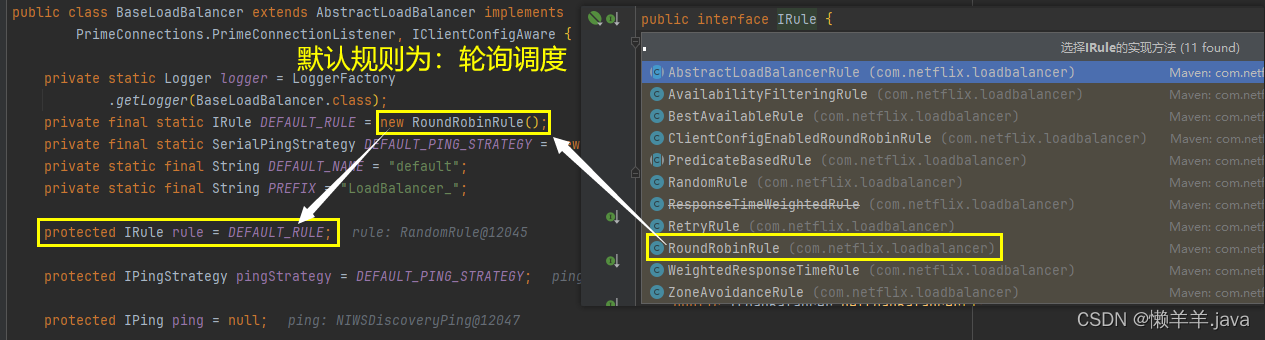
可是看到上图在debug时,rule变量右侧灰色显示的是
rule:RandomRule@12045
这是因为我通过配置IRule类型的Bean指定了负载均衡的规则:
@BeanpublicIRulerandomRule(){returnnewRandomRule();}
只要把他注释掉,程序就会继续去采用默认的规则即RoundRobinRule
3.8 最终的choose()方法—return server
8.了解了IRule接口的rule实例,再去看他最终调用的choose()方法。同样地步入进去,由于是默认规则,则按照流程进入到了RoundRobinRule规则实现中的choose方法(其实IRule接口下的每一个规则实现类都有choose方法)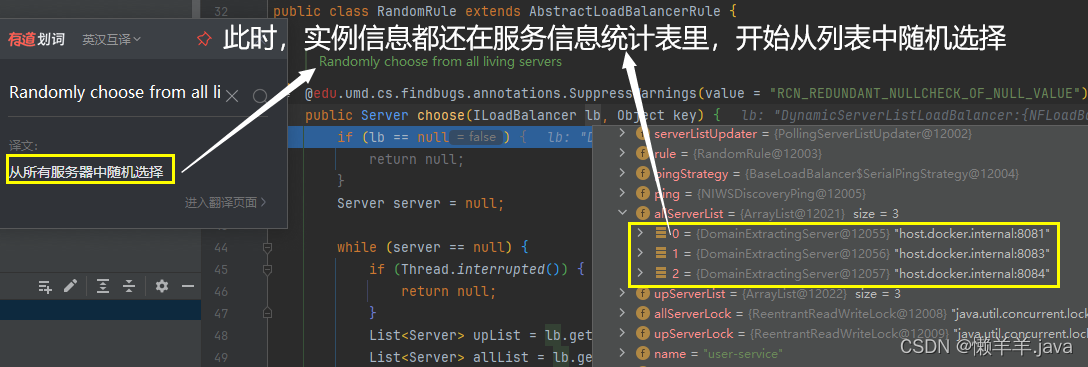
实现了
ILoadBalancer
接口的负载均衡器对象作为参数传递到了方法中,与此同时key为default。开始为随机选择预热。
3.9 choose()方法内部分析
9.进入到while循环中,不断选择服务器,直到找到一个可用的服务器。随后会判断线程是否中断,如果中断了,则直接返回null。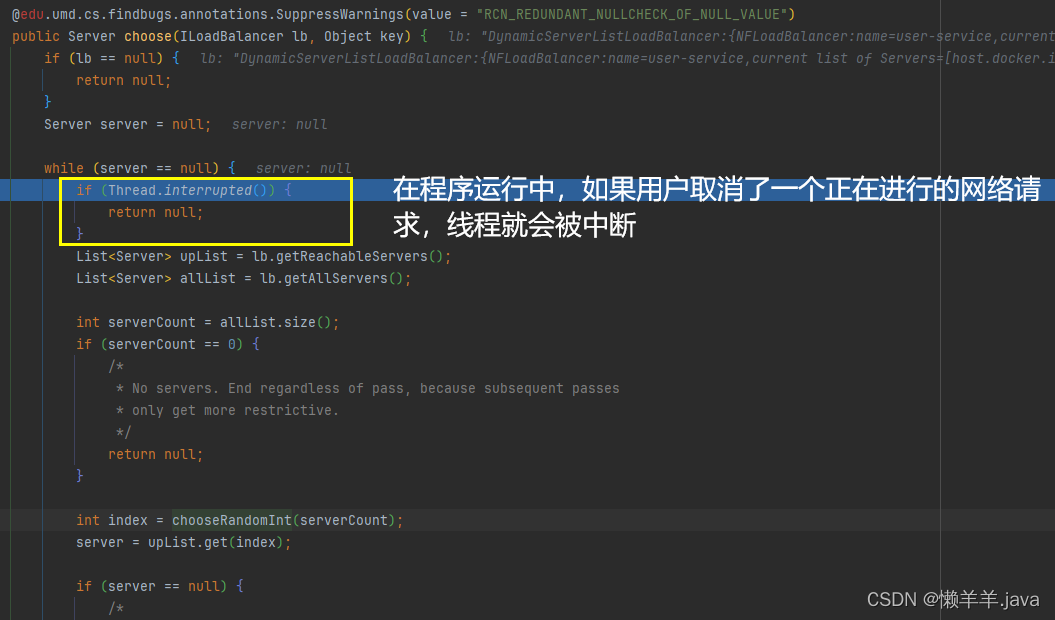
这样的情况出现频率还是很高,由此可见,这个小设计会减少很多不必要计算,提升了程序运行的效率。
而后这是分别获取两个服务列表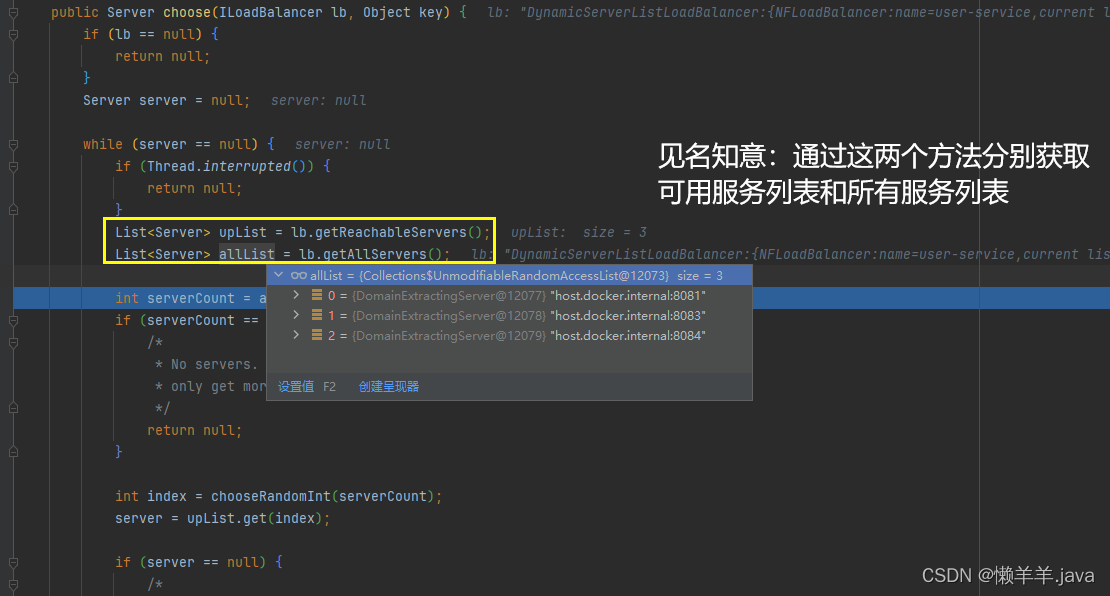
从列表中选择一个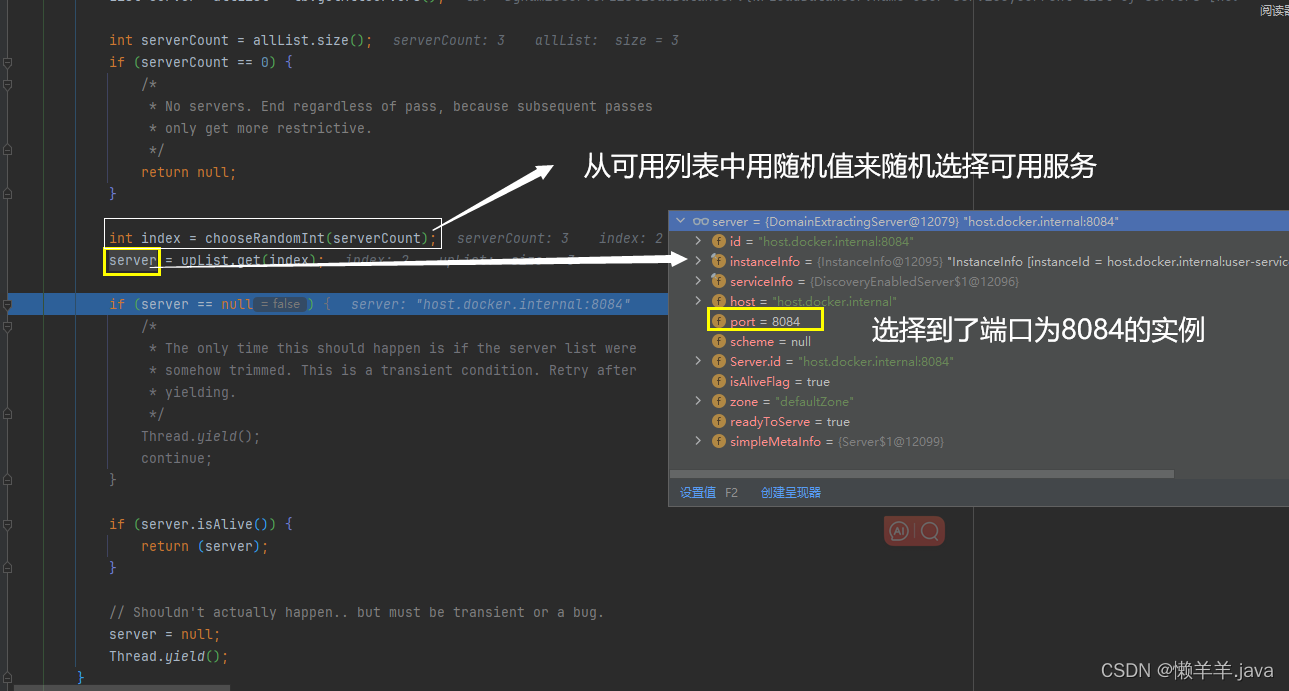
兜底操作,对选择的做判断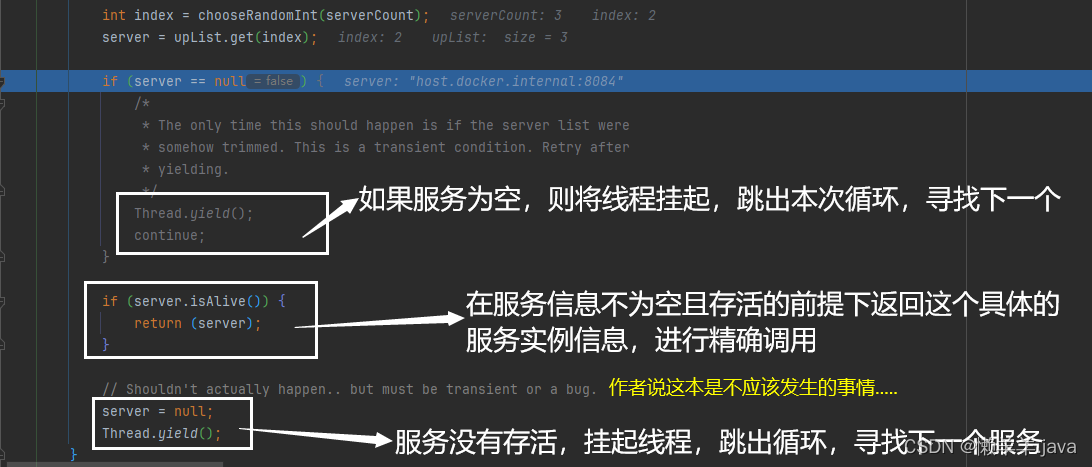
最后成功返回Server实例给chooseServer()方法,服务发起者发送http://user-service/user请求通过Ribbon最后轮询到了localhost:8084服务实例上
4. 彩蛋
现在有很多公司都在用Nacos替换Eureka,因为感知服务列表的变化不够敏感,感知下线服务太过迟钝,就像下面这种情况: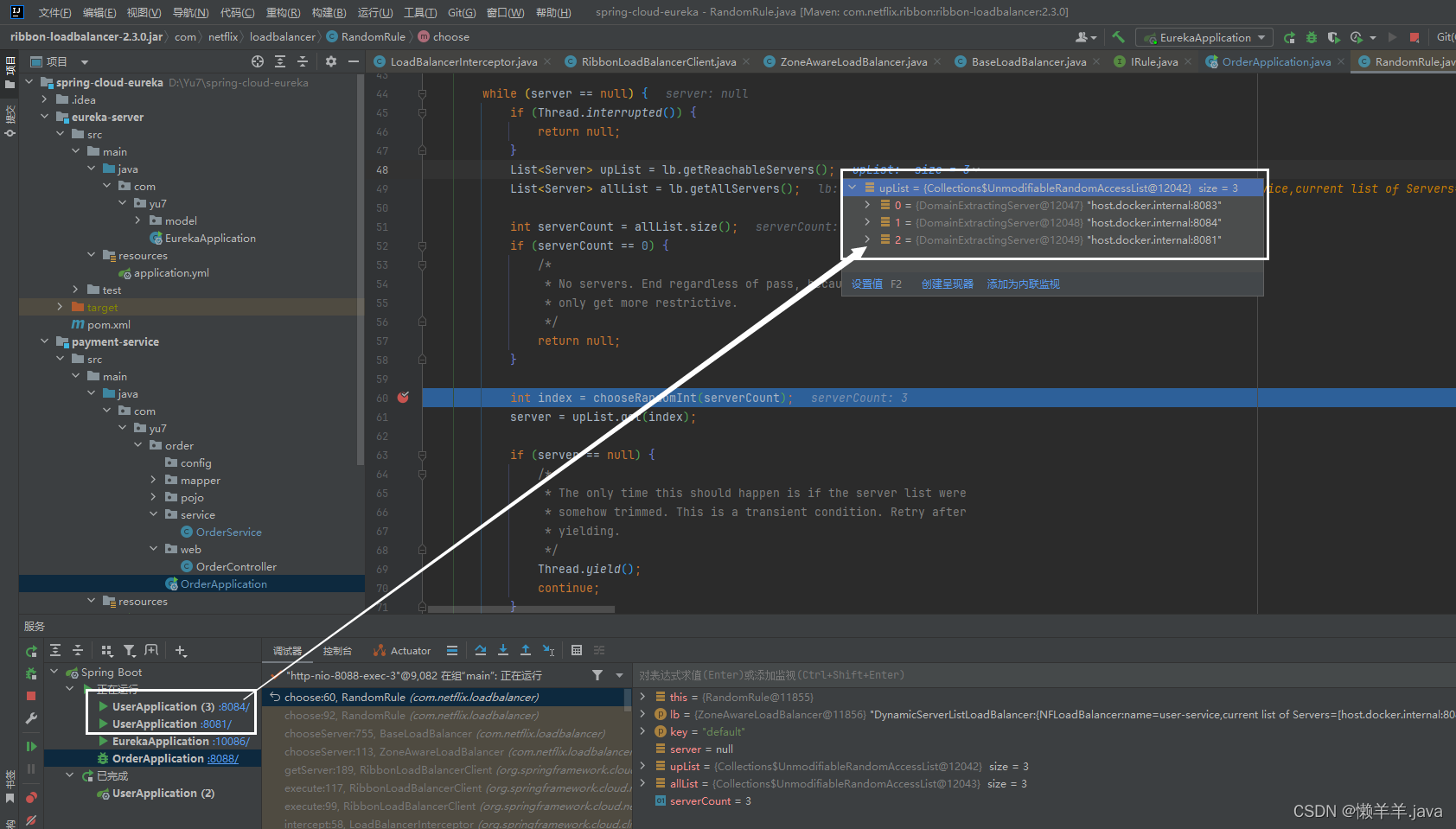
服务实例已经下线,时间大约过了一分钟,却还是把下线的服务加载到了可用服务列表里(upList),其实这并不怪Ribbon,都是Eureka的错
针对这种情况我们留个彩蛋,下次再来talk about~
版权归原作者 懒羊羊.java 所有, 如有侵权,请联系我们删除。