
前沿
最近在多模态有两篇非常惊艳的工作:一篇是Facebook母公司META在9月30号放出来的Text-to-Video、一篇是Google的Text-to-3D;今天我们来看看第一篇即根据文本直接生成视频,注意不是生成图像而是生成视频!!!这个跨越可以说是非常巨大的。
论文链接:
https://makeavideo.studio/Make-A-Video.pdf
demo
大家可以去如下链接先感受一波生成的demo,非常有趣,看完后说不定更有动力学习了,哈哈哈:
https://make-a-video.github.io

动机
当前已经有大量预处理好的text-image pair 数据集,而且Text-to-Image (T2I) modeling也取得了很好的成绩,但是Text-to-Video却不是那么如意,因为text-video pair(T2V)数据集比较难收集,尤其是想要收集类似text-image pair 那么大size的数据集。
但是目前已经有很多训练好的T2I模型,如果不加以利用就太可惜了,于是作者就想到能不能在T2I模型的基础上搞一搞T2V模型,而且不需要利用text-video pair的训练数据。
哈哈,如果是自己,可以想一下此时该怎么搞呢?
方法
作者给该模型取名字也是非常的自逼主题:Make-A-Video,其主要由三个部分组成,下面我们一个一个来看
TEXT-TO-IMAGE MODEL
这里就是训练一个T2I模型,也可以用当前已有的一些好的T2I模型,具体的包含三个模块:一个是prior network P,其主要是在inference的时候生成图片的embedding;其次是一个decoder network D,其主要是根据上述图片的embedding解码生产一个低分辨率的即64 × 64 RGB的图片;最后是一个super-resolution networks SRl,SRh,这是两个超分辨率网络,分别将图片分辨率增强到256 × 256和768 × 768,最后通过插值将采样率降至512获得一张更加清晰的图片。
可以看到这里本质上就是一个文本到图片的模型,只不过第三部分的提高分辨率操作可能比较陌生,但本质就是为了提高图片的质量,这部分其实也是一个研究方向,感兴趣的小伙伴可以调研调研。
SPATIOTEMPORAL LAYERS
“时空层”,相信大家看到这个名字也可以猜到这小节的目的是要做什么?
video和image的最大区别就是:前者是由一连串连贯的image组成的,所以为了生成video,作者在增加T2I模型的基础上额外加了一个维度:时空层。
具体的是设计了两个模块:卷积层和注意力机制层,分别如下: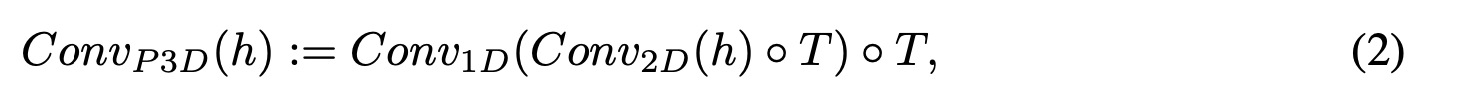
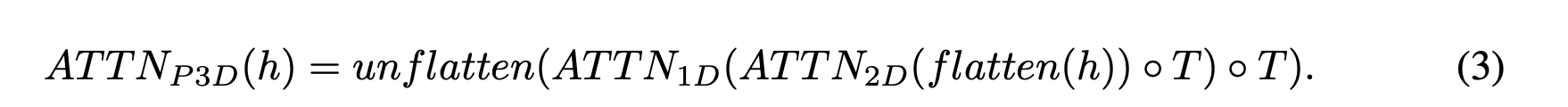
可视化结构框图如下: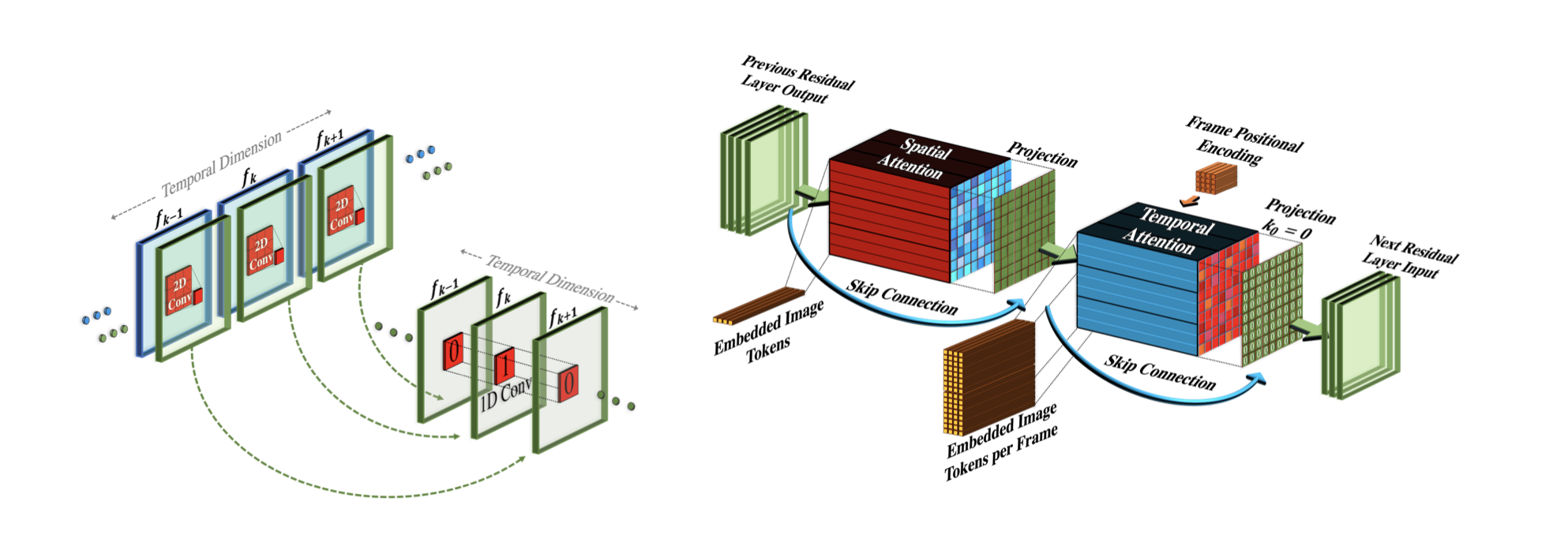
可以看到不论是卷积层还是注意力机制层,都是在2D的基础上增加了1D(时空)形成了最终的3D,其中2D的部分都还是可以直接使用T2I模型训练好的权重进行初始化,而新增加的1D(时空)该怎么训练呢?
我们知道要生成视频其实就是生成一连串的多张图片,但是这些图片要在时空上保证连贯性,于是该部分一切训练的目标就是连贯性,于是就可以使用视频来训练了,注意只使用视频就可以进行无监督训练了哦,不需要text-video pair训练数据。
再强调一遍:这里解决的是多张图片的连贯性,而不解决文本和图片(视频)的相关性,作者把这两部分进行了解耦,这也是这篇paper开头自豪的说:我们不需要text-video pair训练数据的关键原因。
FRAME INTERPOLATION NETWORK
这部分又是一个插值网络,只不过对应到video的话,是一个帧插值网络,本质上和生成图片一样,目的是提高生成视频的质量。
TRAINING
其实最重要的三部分已经讲完了,总结一下就是先要有一个T2I模型、然后再在其基础上再增加一个时空维度,最后再过一个插值网络增强视频质量。
各个模块在训练的时候,都可以各自单独进行,也就是各自训练各种的。如果我们非要拆解一下来看看的话:第一个模块训练要解决的问题是文本和生成视频的相关性,这里直接用了目前很好的T2I模型;第二个模块要解决的问题是多张图片的连贯性,或者说生成视频的连贯性,这里是新增加了一个时空维度,然后只使用视频就可以单独进行无监督训练了;最后一部分就是一个插值网络,进一步来增强生成视频的质量。
总结
(1)虽然现在模型还存在很多缺点,但是也是一个非常大的突破,这个头开的很好,相信会有越来越多的惊艳工作,很期待。
(2)如果感兴趣,确实有很多知识需要静下心来好好学习,比如插值网络等等,它的原理、实现等等。
关注
欢迎关注,下期再见啦~
知乎,csdn,github,微信公众号
本文由 mdnice 多平台发布
版权归原作者 weixin_42001089 所有, 如有侵权,请联系我们删除。