
Hadoop作为大数据的分布式计算框架,发展到今天已经建立起了很完善的生态,本文将一一介绍基于Hadoop生态的一系列框架和组件。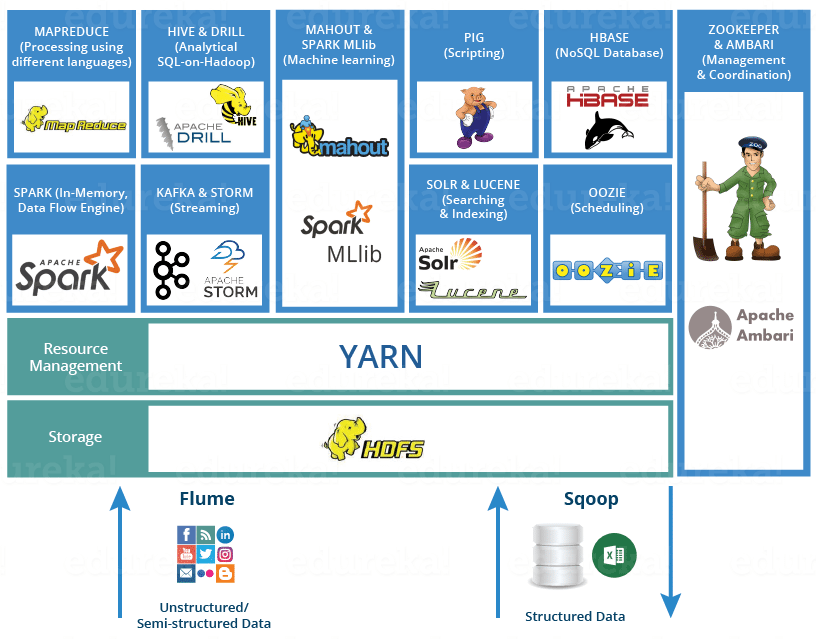
Flume
- 简介: Flume 是一个分布式、高可用的服务,用于高效收集、聚合和移动大量日志数据。
- 作用: Flume 主要承载的作用是收集各个数据源的事件或日志数据,然后将其Sink到数据库

- 架构
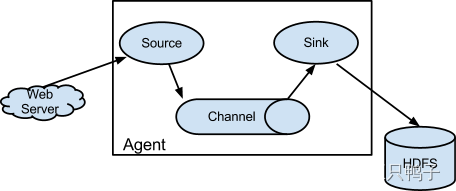 Flume的实现架构原理也非常简单,通过Agent代理来实现数据的收集,一个Agent包含了Source,channel,Sink三个组件。 - Source:采集的数据来源,不同的数据源对应不同的格式,flume支持的source类型有很多,比如avro、thrift、twitter、exec、jms等 所有的Source类型可参考flume的官方文档: https://flume.apache.org/FlumeUserGuide.html#flume-sources- Channel:缓冲区,将接收到的source数据缓存起来,供下游的sink消费,只有当数据被sink消费或者进入下一个channel的时候才会被删除。为了保证channel的可用性,flume也提供了多种channel类型,有memory、JDBC、File、Spillable Memory(当内存队列满了会存储到磁盘上) 、还支持自定义channel- Sink:消费channel里的数据,将数据发送到目的地,比如hive、hbase等。
Flume的实现架构原理也非常简单,通过Agent代理来实现数据的收集,一个Agent包含了Source,channel,Sink三个组件。 - Source:采集的数据来源,不同的数据源对应不同的格式,flume支持的source类型有很多,比如avro、thrift、twitter、exec、jms等 所有的Source类型可参考flume的官方文档: https://flume.apache.org/FlumeUserGuide.html#flume-sources- Channel:缓冲区,将接收到的source数据缓存起来,供下游的sink消费,只有当数据被sink消费或者进入下一个channel的时候才会被删除。为了保证channel的可用性,flume也提供了多种channel类型,有memory、JDBC、File、Spillable Memory(当内存队列满了会存储到磁盘上) 、还支持自定义channel- Sink:消费channel里的数据,将数据发送到目的地,比如hive、hbase等。
Sqoop
Sqoop 用户在Hadoop和各种关系型数据库直接高效的同步传输数据。
一图解释完。ps: 实现同样功能的还有阿里开源的datax
HDFS
Hadoop 分布式文件系统,是Hadoop上层组件的核心存储系统,HBASE,Hive等都是基于HDFS的存储来构建的。
HDFS 也是Master/Slave的主/从架构模式。HDFS 集群由单个 NameNode 和多个DataNode组成,NameNode就是Master,DataNode就是Slave。
- NameNode:负责管理metadata元数据,记录了文件所对应的块信息。
- DataNode,通常集群中每个节点都有一个DataNode,里面存储了具体的数据。
YARN
YARN是一个hadoop的资源管理器,负责管理资源和任务调度。
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。这里的应用程序是指传统的MapReduce作业或作业的DAG(有向无环图)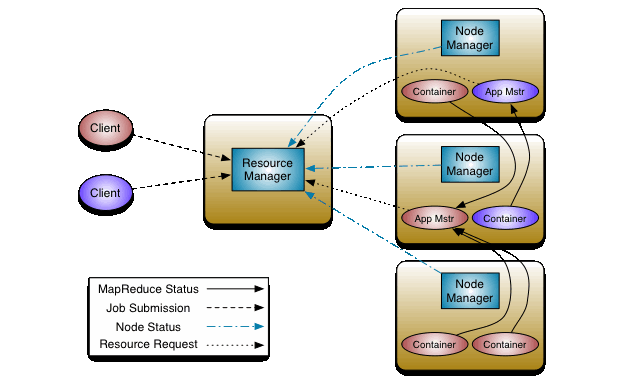
- ResourceManager :负责系统内所有应用的资源调度
- NodeManager 是每台机器的框架客户端/代理,负责容器管理,监控他们的资源使用情况,例如 cpu、memory、 disk、network,并汇报给ResourceManager/Scheduler
Spark
Spark是一个大规模计算引擎,在大数据领域的地位举足轻重。支持Scala、Java、R、Python、Sql 多种语言。
主要的组件有SparkCore、SparkSQL、Spark MLlib、Spark Streaming、GraphX
- SparkCore:实现了 Spark 的基本功能,包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块
- SparkSQL:通过SQL的方式连接数据库的数据,并将数据转化成DataFrame。SparkSQL支持多种数据源,包括 Hive、Avro、Parquet、ORC、JSON 和 JDBC。
- Spark Mllib:是Spark的机器学习库,高质量的算法比MapReduce快100倍。MIlib 提供了丰富和算法和统计方法 - 分类:逻辑回归、朴素贝叶斯、…- 回归:广义线性回归,生存回归,…- 决策树、随机森林和梯度提升树- 建议:交替最小二乘法 (ALS)- 聚类:K-means、高斯混合(GMM)、…- 主题建模:潜在狄利克雷分配(LDA)- 频繁项集、关联规则和序列模式挖掘- 统计:线性代数、假设检验
- Spark Streaming:Spark的流式计算框架,实际上是基于时间的微批处理。通常Apache Flink可取而代之。
- GraphX:是 Apache Spark 用于图形计算的API
Kafka
分布式消息队列,是目前消息队列里面的最强王者。
高吞吐量、高扩展性、高可用性,也支持数据持久化
主要流程:producer生产者发送消息到topic,topic被存放在不同的partition中,由消费组去消费topic里面的消息,一个消费组又由多个消费者组成,一条消息只能由消费组中中的一个消费者消费,避免了重复消费。
Mahout
Mahout是Apache的机器学习库,目标是构建一个用于快速创建可扩展、高性能机器学习应用程序的环境。
主要提供了聚类,分类,协同过滤等开箱即用的算法库,也能方便快速实现自己的算法。
Lucene / Solr / ElasticSearch
Apache Lucene 是完全用 Java 编写的高性能、功能齐全的全文检索引擎架构,提供了完整的查询引擎和索引引擎、部分文本分析引擎。目的是为软件开发人员提供一个简单易用的工具包,以方便地在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Solr 和 ElasticSearch 都架构在 Lucene 之上,能让Lucene更方便的被调用。其倒排索引的设置,在快速检索上比传统的正排索引更加高效。
Oozie
Oozie 是一个用于管理 Apache Hadoop 作业的工作流调度系统。
Oozie Workflow jobs 是由 actions 组成的有向无环图 (DAG)。
Oozie 协调器作业是由时间(频率)和数据可用性触发的周期性 Oozie 工作流作业。
Oozie 与 Hadoop 堆栈的其余部分集成,支持开箱即用的多种 Hadoop 作业(例如 Java map-reduce、Streaming map-reduce、Pig、Hive、Sqoop 和 Distcp)以及系统特定作业(例如Java 程序和 shell 脚本)。
Oozie 是一个可扩展、可靠和可扩展的系统。
还有另外一个优秀的调度框架 Azkaban
Zookeeper
ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。
ZooKeeper 的架构通过冗余服务实现高可用性。
Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。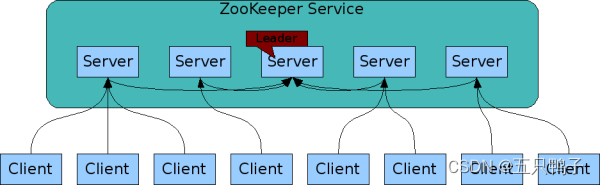
ZooKeeper service 之间互相通信,保证服务的高可用性和一致性。
客户端连接到单个 ZooKeeper 服务器。客户端维护一个 TCP 连接,通过它发送请求、获取响应、获取监视事件并发送心跳。如果与服务器的 TCP 连接中断,客户端将连接到其他的服务器。
zookeeper 数据结构
zookeeper 提供的名称空间非常类似于标准文件系统,key-value 的形式存储。名称 key 由斜线 / 分割的一系列路径元素,zookeeper 名称空间中的每个节点都是由一个路径标识。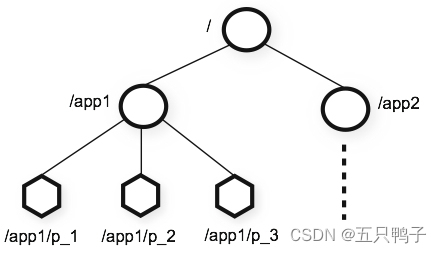
Ambari
Apache Ambari 是一个用于配置、管理和监控 Apache Hadoop 集群的工具。由一组 RESTful API 和一个web界面组成。
MapReduce
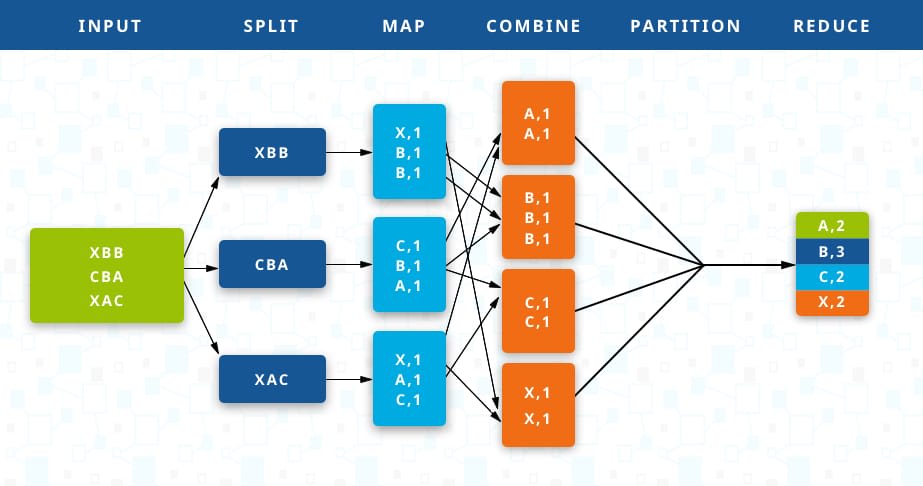
MapReduce是一种分布式计算模型,由Map和Reduce组成。 Map()负责把一个大的block块进行切片并计算。 Reduce() 负责把Map()切片的数据进行汇总、计算。
执行的核心思想: 相同key的键值对为一组调用一次Reduce方法,方法内迭代这组数据进行计算。
MapReduce在大数据计算领域的地位举足轻重,可以使用很多廉价的机器达到惊人的算力。
图中是整个MapReduce的大致计算过程,详细介绍可看官网,后续我也会写一篇详细的介绍。
Hive
架构于Hadoop之上,可以将结构化的HDFS文件映射成一张表,并提供了类似于SQL语法的HQL查询功能。毫不夸张的说正是因为有了Hive的诞生,Hadoop才会被大面积推广和使用,并且经久不息。
核心本质:将HQL语句转换成MapReduce任务
Hive的主要优缺点
优点:
避免了开发人员去实现Map和Reduce的接口,大大降低了学习成本
HQL语法类似于SQL语法,简单、容易上手
缺点:
执行效率比较低 Hive生成的MapReduce任务,不够智能化,容易造成数据倾斜
Hive的架构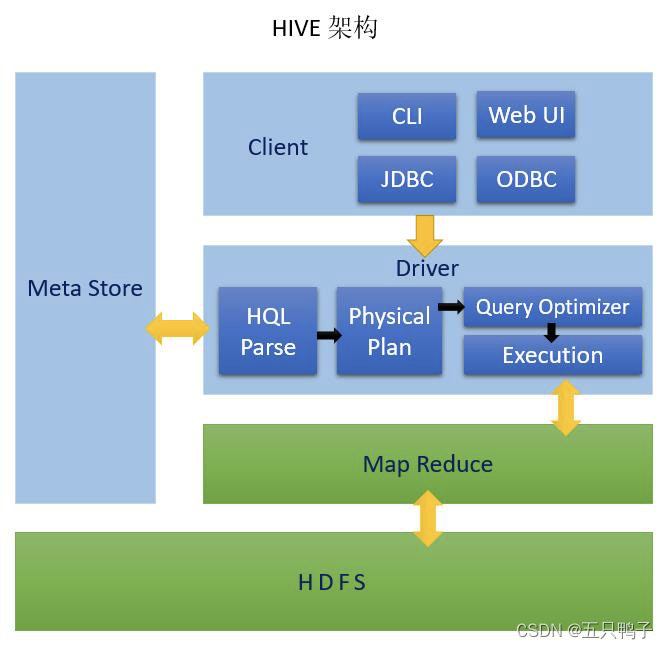
- HIVE: Meta Store: 元数据,一般存储在mysql Client: 客户端 Driver:驱动器 HQL Parse: 解析器,HQL解析和语法分析 Physical Plan: 编译生成逻辑执行计划 Query Optimizer: 对逻辑执行计划进行优化 Execution: 把逻辑执行计划转换成物理执行计划
- Hadoop Map Reduce: 执行计算 HDFS: 文件存储
Pig
Pig和Hive类似,也是基于hadoop的封装计算,核心也是为了简化MapReduce的编程。不同的是Pig提供的语法更加类似于shell,所以导致两者的使用人群不一致。Hive更多的面向开发人员,而Pig更多的面向与运维人员。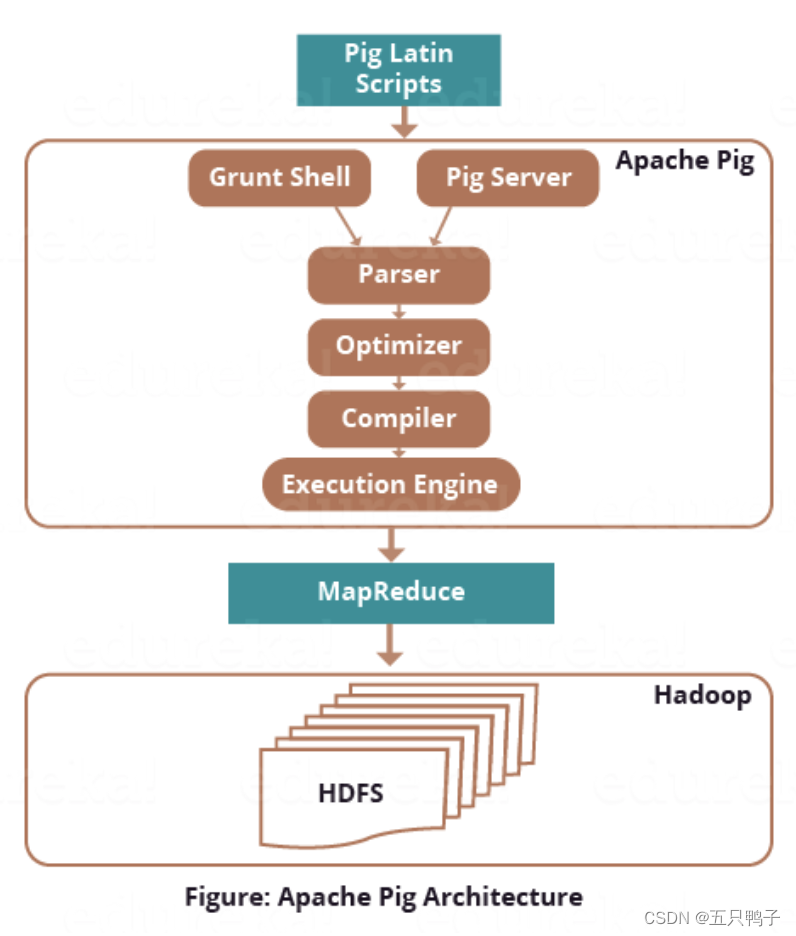
HBase
HBase是一个分布式、可扩展的、列式存储的、支持大数据量的实时开源数据库。
HBase基于面列式存储,其中RowKey的设计,使得他能够提供快速的点查和范围查询,但是不支持复杂的SQL查询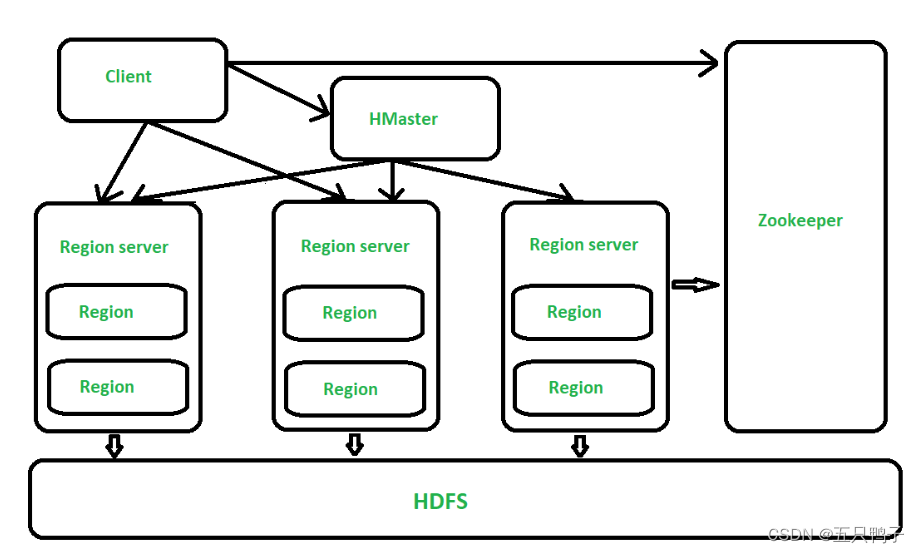
上图是HBASE的基础架构图。
HBASE的数据存储在HDFS上
Client:客户端,它提供了访问HBase的接口,并且维护了对应的cache来加速HBase的访问。
Zookeeper:存储HBase的元数据(meta表),无论是读还是写数据,都是去Zookeeper里边拿到meta元数据告诉给客户端去哪台机器读写数据
HRegionServer:它是处理客户端的读写请求,负责与HDFS底层交互,是真正干活的节点。
总结大致的流程就是:client请求到Zookeeper,然后Zookeeper返回HRegionServer地址给client,client得到Zookeeper返回的地址去请求HRegionServer,HRegionServer读写数据后返回给client。
届于大数据技术革新太快,本文会不定时更新,如果感兴趣的话,可以关注下。
版权归原作者 五只鸭子 所有, 如有侵权,请联系我们删除。