
第一部分** **研究对象及结果
1.1** 股票及网站选取**
本文选取了保利发展、碧桂园、富力地产、华润置地、金科股份、龙湖集团、绿地控股、融创中国、万科A、中海地产十只股票,对同花顺官网的股价信息和东方财富网资讯、股吧进行了爬取,并生成词云。
1.2爬虫结果
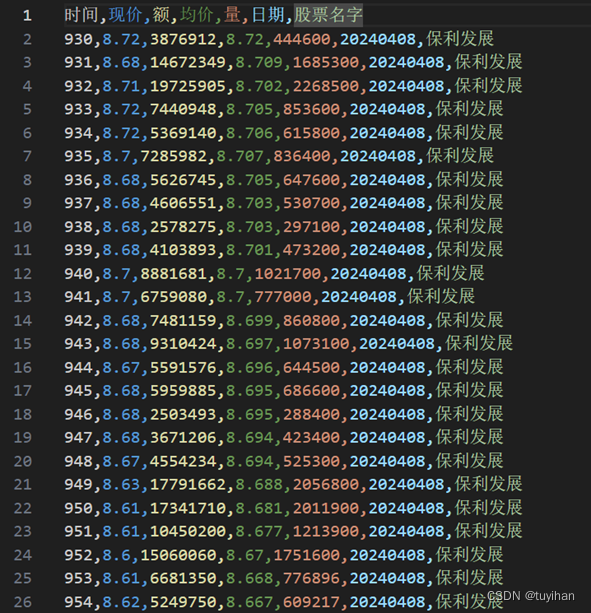
图1.1同花顺股价爬取结果

图1.2东方财富网股吧爬取结果
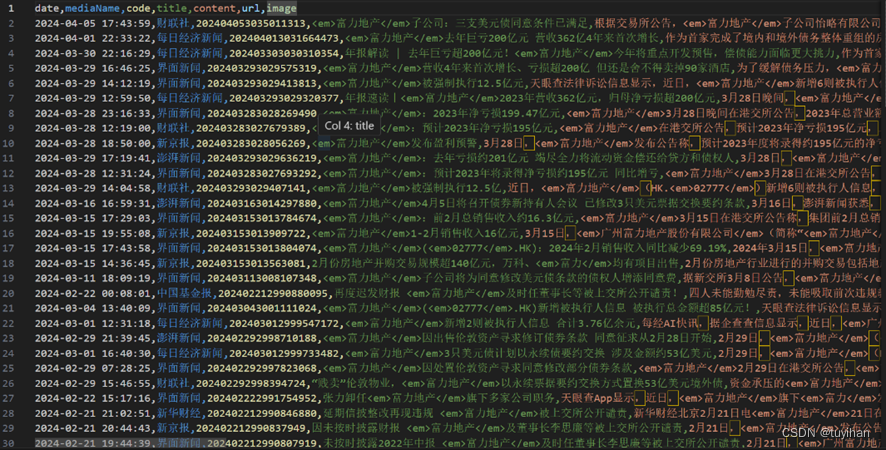
图1.3东方财富网资讯爬取结果

图1.4生成词云
第二部分** **程序演示
运用Python的request库,模拟浏览器请求,解析网站返回的响应。
**2.1同花顺网站股价爬取 **
图2.1股价爬取(一)

图2.2股价爬取(二)
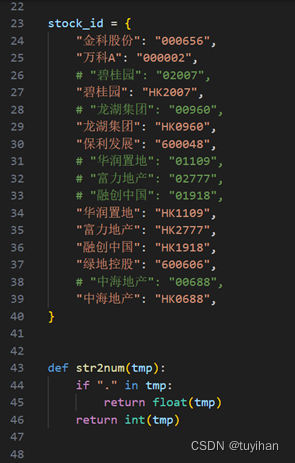
图2.3股价爬取(三)
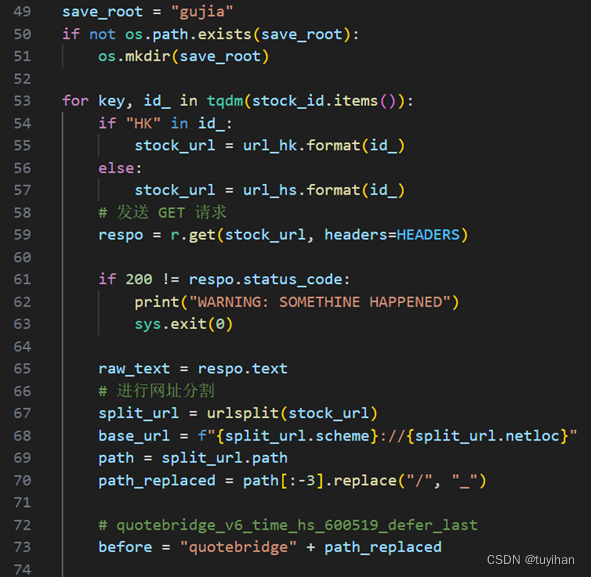
图2.4股价爬取(四)
首先,安装用于网络请求、数据处理、格式化输出的库。
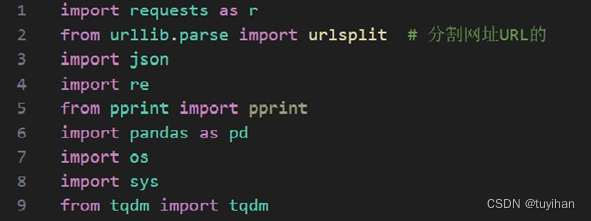
- requests as r: 用于发送HTTP请求。
- urlsplit: 从urllib.parse中导入,用于解析URL。
- json: 用于处理JSON数据。
- re: 用于正则表达式匹配。
- pprint: 用于打印数据结构。
- pandas as pd: 一个数据处理库。
- os: 用于与操作系统交互。
- sys: 提供对Python解释器的一些变量和函数的访问。
- tqdm: 一个快速、可扩展的Python进度条库。
其次,处理一个URL发送网络请求,从响应中提取数据。
先解析URL,构建一个新的字符串,从而构建正则表达式模式。然后发送一个网络请求,获取响应内容,并使用正则表达式来匹配并提取所需的信息。
由于部分网站设有反爬机制,需要根据网站相关信息进行伪装,所以本文用HEADERS模拟浏览器行为的头部。若只保留"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",则会显示因python发出请求而被网站禁止,故保留整段头部信息。
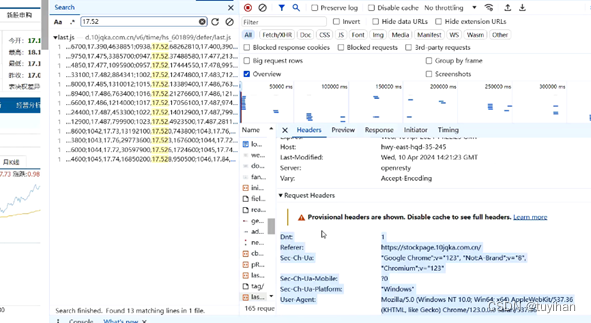
图2.5同花顺HEADERS

具体来看,HTTP请求头部 (HEADERS)是一个字典,包含了在发送HTTP请求时可能会用到的头部信息。这些头部信息用于模拟浏览器的行为,及遵守某些网站的请求规则(robots协议)。
- "Dnt": "1": 表示“Do Not Track”,用于告诉网站不要追踪用户的浏览行为。
- "Referer": 表示请求的来源URL。
- "Sec-Ch-Ua"、"Sec-Ch-Ua-Mobile"、"Sec-Ch-Ua-Platform": 这些头部与浏览器的用户代理字符串相关,用于描述发起请求的浏览器类型、版本和平台。
- "User-Agent": 标准的HTTP头部,用于标识发出请求的浏览器或其他客户端的类型和版本。
url_hs 和 url_hk是两个字符串模板,用于构建获取股票信息的URL。它们分别用于获取上海证券交易所(HS沪市)和香港证券交易所(HK港市)的股票信息。其中 {} 是一个占位符,可被替换为具体的股票代码。

以下是本文选取的十只股票

如果正则表达式匹配成功,它会进一步处理提取到的内容,比如将其转换为JSON格式并提取关键数据。如果匹配失败,则警告并退出程序。

接下来,从网站获取股票信息并将以CSV文件的形式保存到本地。
save_root 是一个字符串,定义了保存CSV文件的根目录名。使用 os.path.exists 检查该目录是否存在,如果不存在,则使用 os.mkdir 创建该目录

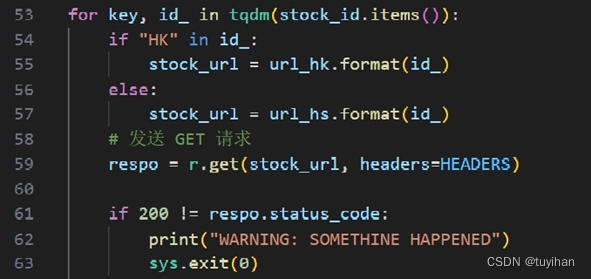
使用 tqdm 库提供的进度条来跟踪股票信息的获取进度。遍历 stock_id 字典,key 是股票名称,id_ 是股票代码。根据股票代码(是否包含 "HK")确定使用哪个URL模板来构建股票信息的URL。
使用 requests 库发送GET请求到 stock_url,并带上之前定义的HTTP请求头部 HEADERS。
检查响应的状态码是否成功。如果不是,警告并退出程序。
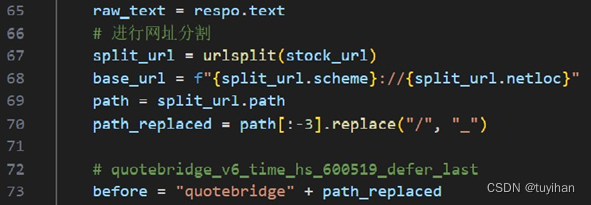
从响应中获取文本内容。对URL进行分割,并对其进行处理,生成后续正则表达式匹配所需的字符串。构建正则表达式模式,并在响应文本中搜索匹配的内容。
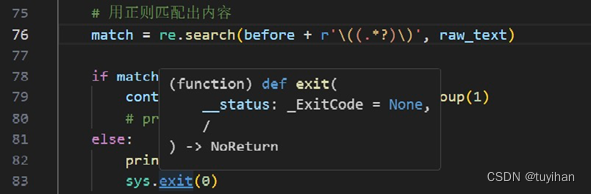
如果匹配成功,则获取括号内的内容;否则打印警告并退出程序。
将匹配到的内容解析为JSON格式。
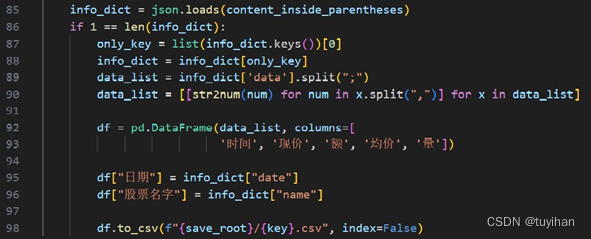
检查 info_dict 字典的长度,并获取其唯一的键对应的值。
提取数据并处理,使用之前定义的 str2num 函数将字符串转换为数字。
将处理后的数据转换为Pandas DataFrame,并指定列名。
为DataFrame添加额外的列:日期和股票名字。
将DataFrame保存为CSV文件,文件名以股票名称命名,并保存到之前创建的目录中。
**2.2东方财富网舆情及情绪爬取 **
以资讯和股吧作为对象,按时间顺序提取日期、作者、标题、来源等信息。由于两者的爬取具有较高的相似性,故下文仅以资讯类为例进行解释说明。

图2.6资讯爬取(一)
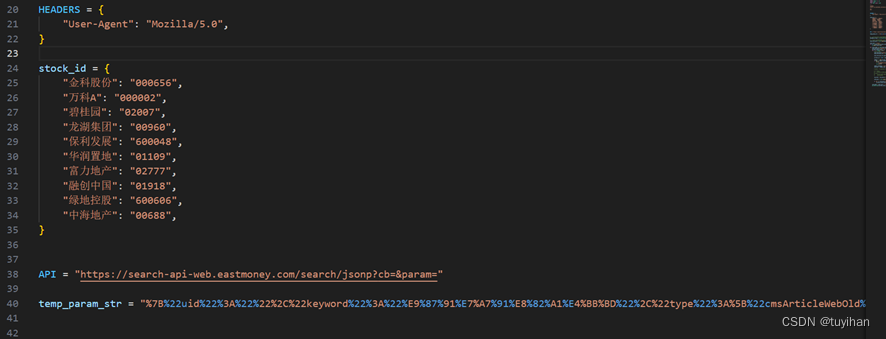
图2.7资讯爬取(二)
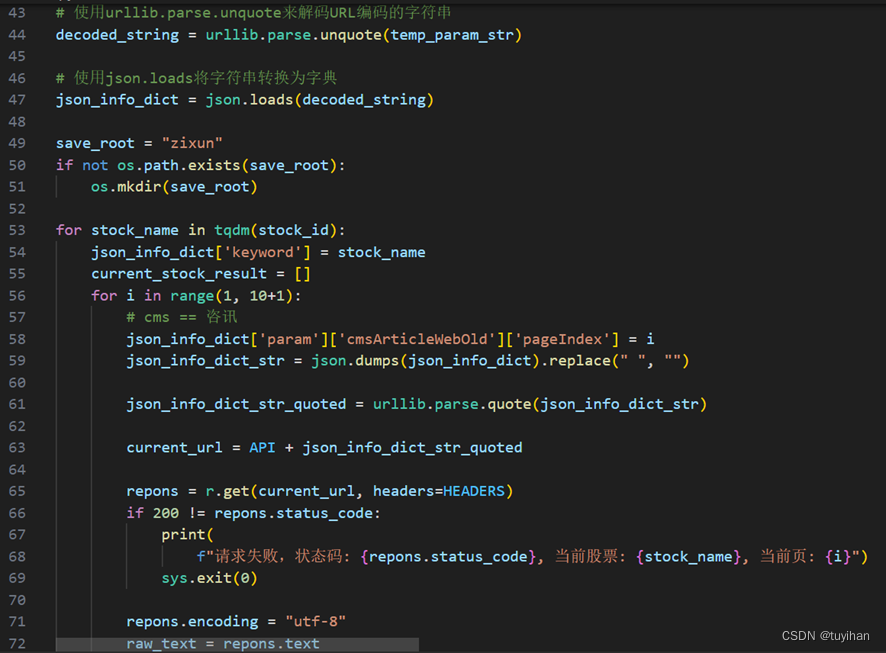
图2.8资讯爬取(三)

图2.9资讯爬取(四)
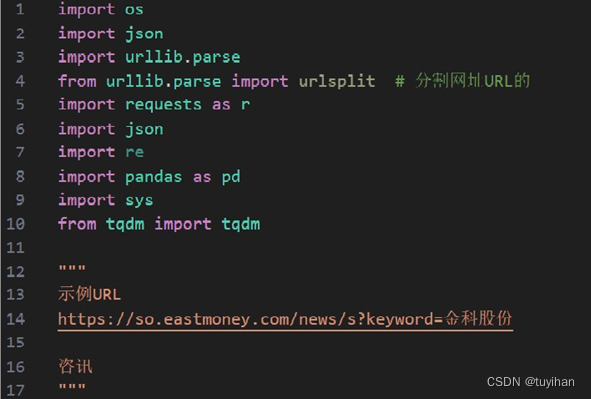
首先,导入所需的库,定义示例URL,HEADERS头部。
- os: 用于与操作系统交互。
- json: 用于处理JSON数据。
- urllib.parse 和 from urllib.parse import urlsplit: 用于处理URL。
- requests as r: 一个流行的HTTP库,用于发送网络请求。
- re: 用于对返回的文本内容进行正则表达式匹配,提取所需信息。
- pandas as pd: 一个数据处理和分析库。
- sys: 提供对Python解释器使用或维护的一些变量的访问,以及与解释器强烈交互的功能。
- from tqdm import tqdm: 用于显示数据提取或处理的进度

API变量存储了一个API的URL,这个URL用于搜索或获取某种数据。URL中的cb=和param=是查询参数,其中cb通常用于JSONP回调,而param则用于传递搜索或请求的参数。
因该程序需要循环发送请求,要保留最简形式。通过对比发现,不同的股票的cb是变化的,删除后结果不变。故可写为以下形式:

temp_param_str定义一个经过URL编码的字符串。这个字符串是为了构建完整的API请求URL而准备的,它与API变量拼接,并通过requests库发送请求来获取数据。其具体展开如下:

其次,解码并转换为python可识别的形式。

解码temp_param_str中的URL编码字符,将其转换为原始字符串。再将解码后的字符串转换为Python字典
其中,JSONP是一种跨域解决方案,它允许网页从另一个域请求数据。JSONP通过在请求的URL中指定一个回调函数名,然后将返回的JSON数据作为该函数的参数来执行,从而实现了跨域。
接下来,对实例网址进行拆分、修改,合成新网址。发送新请求并保存结果。

定义保存资讯的根目录,如果该目录不存在则创建它。

为循环添加进度条,遍历字典中的股票名称。更新请求字典中的keyword为当前股票名称,并设置请求的页码。构建请求URL:将更新后的请求字典转换为JSON字符串,并去除其中的空格,然后对该字符串进行URL编码,最后将其附加到API基础URL上,形成完整的请求URL。

发送请求并处理响应: 使用requests库发送GET请求,并检查响应的状态码。

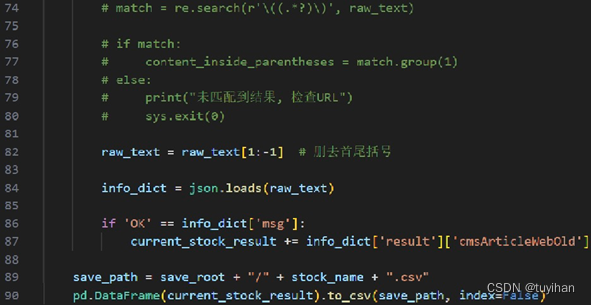
处理响应文本并保存数据为CSV文件:如果JSON字典中的msg字段值为'OK',则认为请求成功,并将结果添加到current_stock_result列表中。最后,将current_stock_result列表中的数据保存为以股票名称命名的CSV文件。
**2.3词云生成 **
本部分参考自https://zhuanlan.zhihu.com/p/138356932

导入所需的库和模块:
- WordCloud, ImageColorGenerator, STOPWORDS:用于生成词云、颜色生成器以及定义停止词。
- jieba:一个中文分词库。
- Image:从PIL库中导入,用于图像处理。
- numpy as np:用于数值计算。
- pyplot as plt:用于绘图。

定义两个根目录路径。使用列表推导式生成两个文件夹中所有文件的路径列表
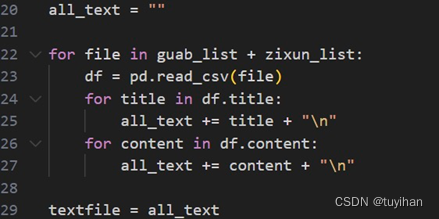
- 初始化一个空字符串 all_text,用于存储从CSV文件中提取的所有文本。
- 遍历 guab_list 和 zixun_list 中的所有文件路径。
- 对于每个文件,使用 pd.read_csv(file) 读取CSV文件到一个DataFrame对象 df。
- 遍历 df 的 title 列,将每个标题添加到 all_text 字符串中,每个标题后面加上换行符 "\n"。
- 遍历 df 的 content 列,将每个内容添加到 all_text 字符串中,每个内容后面也加上换行符 "\n"。
- 最后,all_text 字符串将包含从所有CSV文件中提取的所有标题和内容。




版权归原作者 tuyihan 所有, 如有侵权,请联系我们删除。