

关于进程,已经讲过进程概念、进程控制,还差进程间通信,关于进程间通信,今天主要讲管道(分为匿名管道、命名管道)、共享内存。我们知道进程是具有独立性的,那它们又如何做到相互联系,达到通信的目的呢?今天就让我们来探索吧~
进程间通信介绍
进程间通信的目的
数据传输:一个进程需要将它的数据发送给另一个进程。
资源共享:多个进程之间共享同样的资源。
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
进程间通信方式不同的原因

由上面的关系,进程之间要想进行通信,首先让不同的进程看到一份公共的资源,这个资源只能由OS提供。
通信方式
以文件的方式提供:管道通信
以队列的方式提供:消息队列
以原始内存块方式提供:共享内存
进程间通信分类
管道
匿名管道pipe
命名管道
System V
System V 消息队列
System V 共享内存
System V 信号量
管道
匿名管道
原理

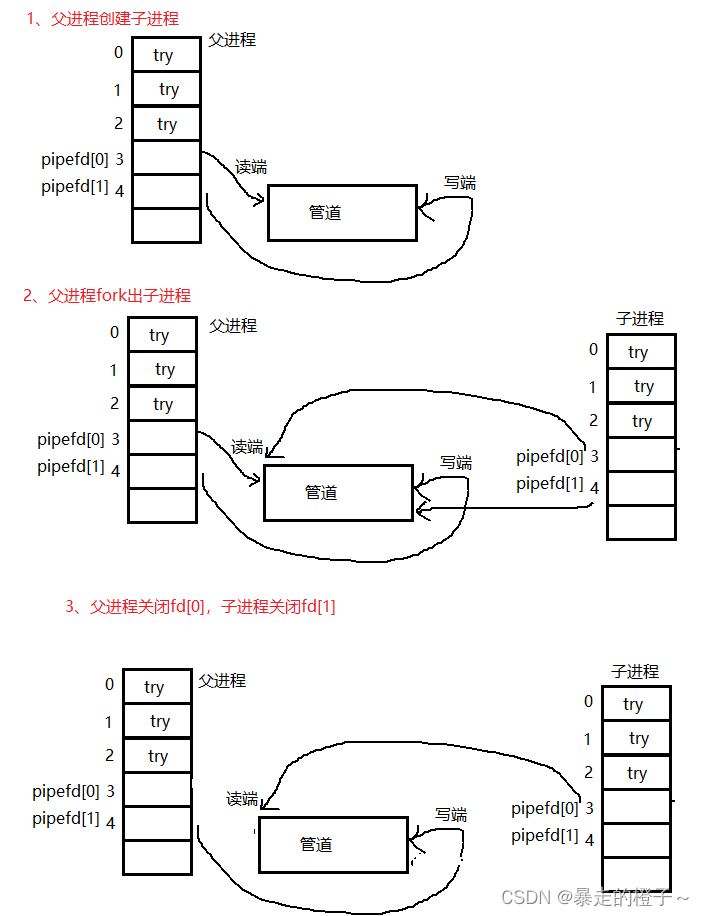
上面的过程是通过子进程是以父进程为模板创建,这时候子进程可以通过父进程继承的文件描述符表,找到相同的struct file,然后使用系统调用接口(read、write)进行读写,这样可以把数据直接写到文件的内核缓冲区里面,只要我们不刷新数据到磁盘上,这时候,父子进程就都可以看到一块公共的资源了。
注意
1、这个公共的资源既不属于父进程,也不属于子进程。如果要属于它们其中一个的话,那样就和进程之间具有独立性的话冲突了。
2、struct files_struct属于进程部分,子进程被创建后,是会拷贝父进程一份的。因为进程之间具有独立性,所以它是不会共享父进程的文件描述符表的。
匿名管道实现模型
调用接口
pipe

pipefd[2]:是输出型参数,当创建管道成功之后,返回两个文件描述符,其中pipefd[0]是读端,pipefd[1]是写端。
代码实现
情况一
写端不写或写得慢,读端要等写端
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
int main()
{
int pipefd[2] = {0};
if(pipe(pipefd) != 0) //匿名管道,返回0就创建成功,-1表示创建失败
{
perror("pipe error!");
return 1;
}
//我们规定父进程进行读取,子进程进行写入
if(fork() == 0)
{
//子进程
close(pipefd[0]);
const char* str = "hello wmm";
while(1)
{
sleep(1);
//pipe里面只要有缓冲区,就一直写入
write(pipefd[1], str, strlen(str)); //这里strlen不用+1,\0不用写入到管道里面
}
return 0;
}
//父进程
close(pipefd[1]);
while(1)
{
char buff[64] = {0};
ssize_t s = read(pipefd[0], buff, sizeof(buff));
if(s == 0)
{
//此时意味着子进程关闭文件描述符了
printf("child quit...\n");
break;
}
else if(s > 0)
{
buff[s] = 0;
printf("child say to parent: %s\n", buff);
}
else
{
printf("read error...\n");
break;
}
}
return 0;
}
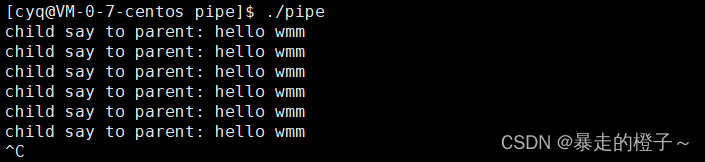
上面的代码是父进程读得快,子进程写得慢,父进程是一直在等子进程的。
演示结果:
情况二
读端不读或读得慢,写端要等待读端。
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
int main()
{
int pipefd[2] = {0};
if(pipe(pipefd) != 0) //匿名管道,返回0就创建成功,-1表示创建失败
{
perror("pipe error!");
return 1;
}
//我们规定父进程进行读取,子进程进行写入
if(fork() == 0)
{
//子进程
close(pipefd[0]);
const char* str = "hello wmm";
while(1)
{
//pipe里面只要有缓冲区,就一直写入
write(pipefd[1], str, strlen(str)); //这里strlen不用+1,\0不用写入到管道里面
}
return 0;
}
//父进程
close(pipefd[1]);
while(1)
{
sleep(1);
char buff[64] = {0};
ssize_t s = read(pipefd[0], buff, sizeof(buff)-1); //-1是为了防止越界
if(s == 0)
{
//此时意味着子进程关闭文件描述符了
printf("child quit...\n");
break;
}
else if(s > 0)
{
buff[s] = 0;
printf("child say to parent: %s\n", buff);
}
else
{
printf("read error...\n");
break;
}
}
return 0;
}
这时候我们让写端不休眠,读端每次读之前休眠1s。
运行代码:

这时候我们发现读到的数据并不是我们期望的字符串("hello wmm"),而是每次读到的是写端1s内往管道里写的全部数据。
这说明了什么?
管道是面向字节流的! 一次读到的数据多少,是读端控制的。ssize_t s = read(pipefd[0], buff, sizeof(buff)-1);
另外,管道是有大小的,在Linux下是64KB。如果写端写满了,写端就不再写了,这时候要让读端来读。一般linux下读端读走4KB后写端将接着写,针对情况二有兴趣的老铁们可以下去测试哦~
情况三
读端关闭,写端收到SIGPIPE信号直接终止
还是之前的代码,我们在父进程最后改一下:
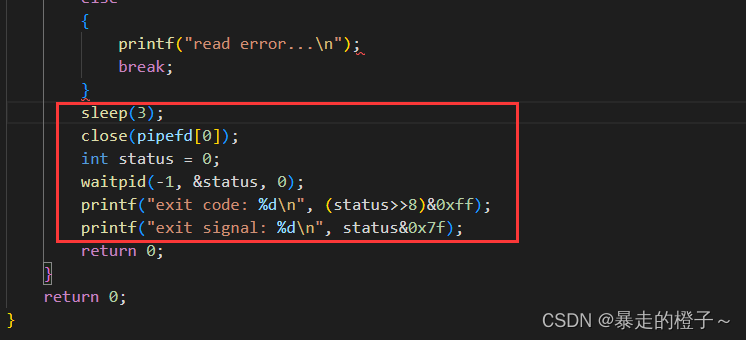
让父进程关闭读端,退出前查看子进程的退出信号。
运行结果:

父进程关闭读端,子进程会立马收到13号信号,然后被终止掉。
至于13号信号:
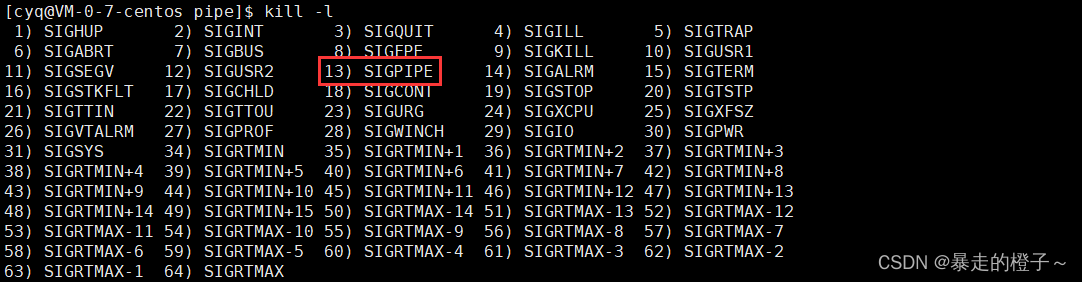
实际上这是一种特殊情况,因为读端已经关闭的话,写端一直在写,那么OS认为写端的进程就是在浪费OS的资源,于是OS就发给写端13号信号终止掉它!
情况四
写端关闭,读端读完pipe内部的数据然后再读,会读到0,表明读到文件结尾
我们对子进程代码略微修改:

运行结果:

这时候我们发现,读端把写端写入到pipe里面的内容读完之后,然后就会读到0,也就是ssize_t s的返回值为0,此时表明读到文件结尾。
匿名管道总结
4种情况
a、读端不读或者读得慢,写端要等待读端
b、写端不写或者写得慢,读端要等待写端
c、读端关闭,写端收到SIGPIPE信号直接终止
d、写端关闭,读端读完pipe内部的所有数据然后再读,会读到0,表示读到文件结束
5个特点
a、管道是一个只能单向通信的通信管道
b、管道是面向字节流的
c、仅限于具有血缘关系的进程之间进行通信(因为匿名管道没有名字)
d、管道自带同步机制,原子性写入
补充
管道是文件吗?是的!
如果一个文件只被当前进程打开,相关进程退出了(会自动递减struct file的ref引用计数),那么被打开的文件呢?会被OS自动关闭!
总结:管道的生命周期是随进程的!
命名管道
为什么要有命名管道?
如果想让两个不相关的进程之间进行通信,这时候匿名管道就做不到了,这时候就要用命名管道!
命名管道原理
我们通常标识一个磁盘文件,我们用什么方案呢?
答案是:路径+文件名(具有唯一性!)
A,B两个进程是如何看到同一份资源的呢?
上面的问题意思是:A,B两个进程是如何看到并打开同一个文件呢?
通过命名管道,因为为通过搜索路径,就可以找到一个同一个文件。
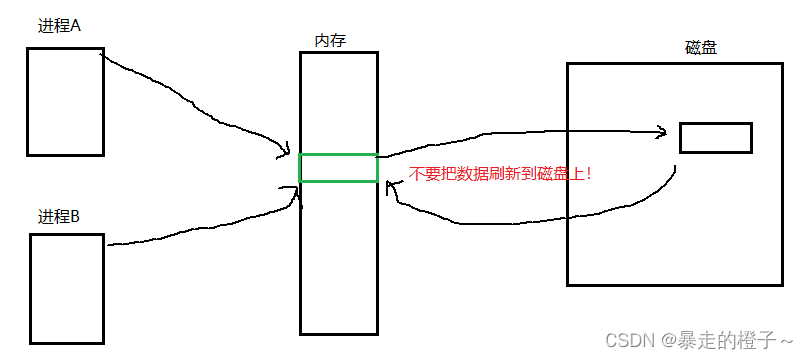
一旦我们有了命名管道,此时我们只需要让通信双方按照文件操作即可。
因为通信双方也是基于字节流的,所以实际上,信息传递的时候,是需要通信双方定制"协议"的,在这里先不考虑。
命令行创建命名管道
mkfifo

我们就在这里简单演示一下:
创建一个叫fifo的命名管道:
[cyq@VM-0-7-centos fifo]$ mkfifo fifo
我们然后让一个终端往fifo里面写数据,另一个终端从fifo中读数据:

在这里就不多介绍这个了,我们的重点在于代码创建。
调用接口
mkfifo

const char pathname:*路径名/文件名,在指定的目录下创建指定文件的命名管道。
mode:管道权限
创建成功返回0,创建失败返回-1。
代码练习
comm.h
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<sys/wait.h>
#include<string.h>
#define MY_PATH "./fifo" //文件路径
client.c
#include"comm.h"
int main()
{
//这里不用再创建fifo了,只需要获取即可
int fd = open(MY_PATH, O_WRONLY);
if(fd < 0)
{
perror("open");
return 1;
}
//业务逻辑s
while(1)
{
printf("请输入: ");
fflush(stdout); //printf会有缓冲区,这里要提前刷新一下
//先把数据从标准输入拿到我们的client进程内部
char buff[64] = {0};
ssize_t s = read(0 ,buff, sizeof(buff)-1);
if(s > 0)
{
buff[s-1] = 0; //\n不进行写入
write(fd, buff, strlen(buff));
}
}
return 0;
}
server.c
#include "comm.h"
int main()
{
if(mkfifo(MY_PATH, 0666) < 0) //创建失败
{
perror("mkfifo");
return 1;
}
//只需要读文件操作即可
int fd = open(MY_PATH, O_RDONLY);
if(fd < 0)
{
perror("open");
return 2;
}
//业务逻辑,可以进行对应的读写及控制了
while(1)
{
char buff[64] = {0};
ssize_t s = read(fd, buff, sizeof(buff)-1);
if(s > 0)
{
//success
buff[s] = 0;//相当于设置\0,保证读到有效字符串
if(strcmp(buff, "show") == 0)
{
if(fork() == 0)
{
execl("/usr/bin/ls", "ls", "-l", NULL);
break;
}
waitpid(-1, NULL, 0);
}
else if(strcmp(buff, "run") == 0)
{
if(fork() == 0)
{
execl("/usr/bin/sl", "sl", NULL);
break;
}
waitpid(-1, NULL, 0);
}
else
{
printf("client say: %s\n", buff);
}
}
else if(s == 0) //没有client方的数据了
{
printf("client quit...\n");
break;
}
else
{
perror("read");
break;
}
}
close(fd);
return 0;
}
Makefile
.PHONY:all
all:client server
client:client.c
gcc -o $@ $^ -std=c99
server:server.c
gcc -o $@ $^ -std=c99
.PHONY:clean
clean:
rm -f client server fifo
代码结果演示:

现象
我们让client写一部分数据到管道中,但是我们让server端休眠30s,这时候写的数据一直在管道文件里面,这时候我们看看管道的大小有什么变化。
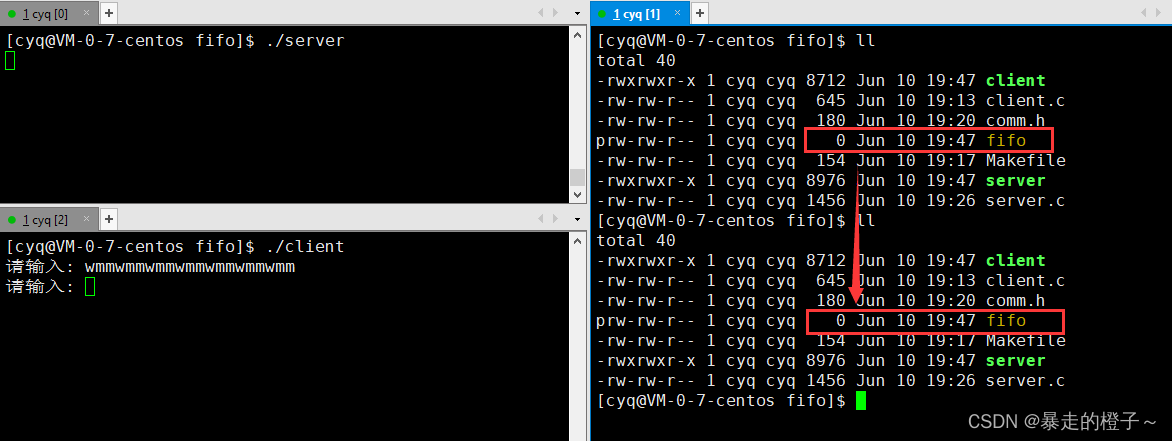
我们发现管道文件大小前后一直是0!
**因为fifo文件里面的数据不会刷新到磁盘上,是为了保证效率。 **
思考
为什么我们之前的pipe叫做匿名管道?
因为文件没有名字,它是通过父子继承的方式,看到同一份资源,不需要名字来标识同一个资源。
为什么现在的fifo叫做命名管道呢?
一定要有名字,为了保证不同的进程看到同一个文件,必须有名字!
共享内存
共享内存原理
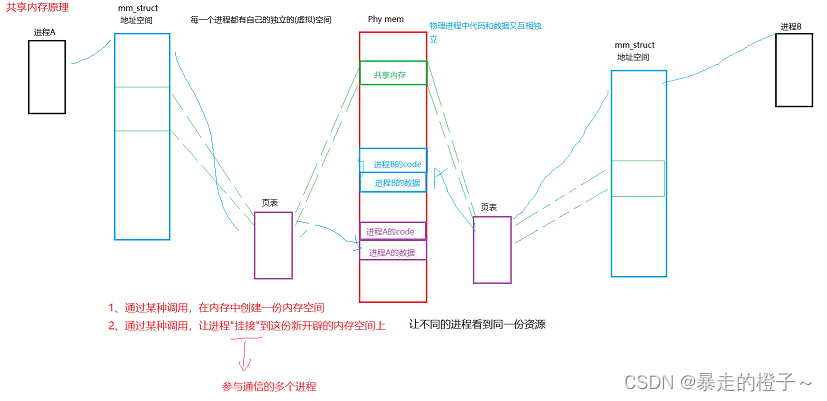
上面的意思就是在物理内存中开辟好一块空间,让不同的进程通过页表映射可以找到这块空间,这样就达到了不同的进程能够看到同一块空间资源的目的。
进一步理解
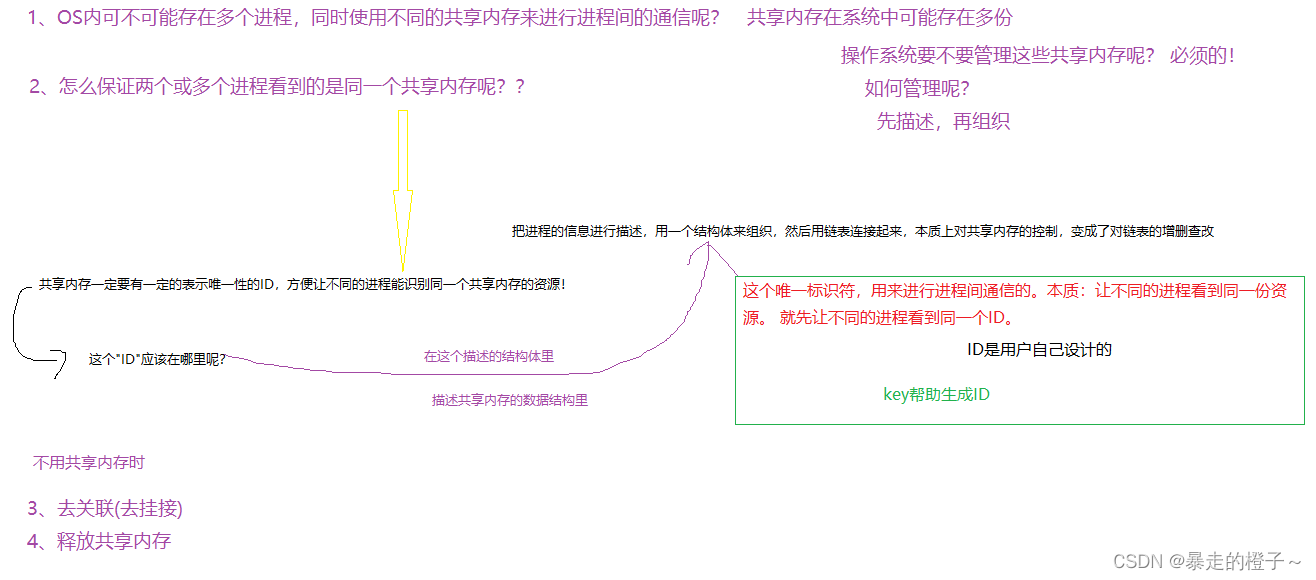
既然OS要管理很多个共享内存,那么为了保证不同的进程找到对应的内存块,就需要用一个标示性的"ID",方便让不同的进程识别对应的共享内存的资源!
共享内存调用接口
shmget

key_t key:这里的key值就是会被设置进内核的,关于shm在内核中的数据结构。 关于key值,我们就有专门的接口帮助我们生成keykey值。
size_t size:创建共享内存的大小,建议是4KB的整数。
int shmflag:和open的第二个参数场景类似。参数选择如下:
IPC_CREAT:如果单独使用IPC_CREAT,或者shmflg为0,创建一个共享内存,如果创建的共享内存已经存在,则直接返回当前已经存在的共享内存。(基本不会空手而归)
IPC_EXCL(单独使用没有意义):这些大写的变量实际上就是定义的宏,和IO一样,只有一个位为1,且比特位不冲突。
IPC_CREAT | IPC_EXCL:如果不存在共享内存,则创建;如果有了共享内存,则返回出错!意义:如果调用成功,得到的一定是最新的,没有被别人使用的共享内存!
返回值:调用成功就返回对应的shmid编号(提供shmctl使用); 返回-1就表示调用失败。

ftok

const char pathname:*自定义路径
int proj_id:自定义ID
这个函数会根据传的路径名和id值,通过算法形成一个key值,然后作为返回值返回。如果返回-1就表示出错。
shmctl

int shmid:指定哪个共享内存。
int cmd:在这里我们只了解删除删除的接口,IPC_RMID
** struct sgmid_ds* buf:**OS提供给用户的"简易版"的内核数据结构。在这里我们不需要关心,只需要传NULL就可以了。

shmat

** int shmid:**共享内存的"id"编号,在shmget创建成功的返回值就可以获取。
const void shmaddr:*关联共享内存挂接到指定的位置。我们不用关心,传NULL,交给OS处理就可以了。
int shmflg:这里我们给他传0就行。
返回值:返回共享内存的起始地址。(这个和malloc开辟空间返回开辟好空间的起始地址类似。)这里的地址,指的是虚拟地址!
这个接口就是让该进程与创建的共享内存块关联起来,也就是可以通过页表映射,该进程能找到对应内存块。
shmdt

*const void shmaddr: **传共享内存的起始地址,这样就可以让该进程和共享内存取消关系。注意:和共享内存去关联,并不是释放共享内存,而是取消进程和共享内存的关系。
代码练习
client.c
#include "comm.h"
#include<unistd.h>
int main()
{
key_t key = ftok(PATH_NAME,PROJ_ID);
if(key < 0)
{
perror("ftok");
return 1;
}
printf("%u\n",key);
//client只需要进行获取即可 SIZE表示共享内存大小
int shmid = shmget(key,SIZE,IPC_CREAT);//第三个参数是获得方式,存在即获取,在这里只能获取
if(shmid < 0)
{
perror("shmget");
return 1;
}
char* mem = (char*)shmat(shmid,NULL,0);
//sleep(5); --> 测试nattch用
printf("client process assaches success!\n");
//这个地方就是我们要通信的区域
char c = 'A';
while(c <= 'Z')
{
mem[c-'A'] = c;
c++;
mem[c-'A'] = 0;//保证字符串最后有\0
sleep(2);
}
shmdt(mem);
//sleep(5); --> 测试nattch用
printf("client process detaches success\n");
//client要不要删除呢?不需要!
return 0;
}
server.c
#include "comm.h"
#include<unistd.h>
int main()
{
key_t key = ftok(PATH_NAME,PROJ_ID);
if(key < 0)
{
perror("ftok");
return 1;
}
printf("%u\n",key);
//client这里只需要进行获取即可
int shmid = shmget(key,SIZE,IPC_CREAT|IPC_EXCL|0666);//设置全新的shm,如果和系统已经存在的ID冲突,我们出错返回
if(shmid < 0)
{
perror("shmget");
return 2;
}
printf("key: %u, shmid, %d\n",key,shmid);
//sleep(3); --> 测试nattch用
//加关联,shmid是共享内存的起始地址
const char* mem =(char*) shmat(shmid,NULL,0);
printf("attach shm success\n");
//sleep(15);//server多休息几秒,横穿整个client。 ->测试nattch用
//这里就是我后面要进行通信逻辑
while(1)
{
sleep(1);
//这里我有没有调用类似pipe或fifo的read这样类似的接口呢?
printf("%s\n",mem);//server 认为共享内存里面放的是一个常字符串
}
shmdt(mem);//去关联
printf("detaches shm success\n");
//sleep(5); // --> 测试nattch用
shmctl(shmid,IPC_RMID,NULL);
printf("key:0x%x, shmid:%d -> shm delete sucess\n",key, shmid);
sleep(10); //->测试nattch用
return 0;
}
Makefile
.PHONY:all
all:client server
#all是一个伪目标,在自顶向下扫描时,all后面的两个文件没有,
#那么就会自动向下找对应的生成方法生成文件
client:client.c
gcc -o $@ $^
server:server.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -f client server
运行效果:
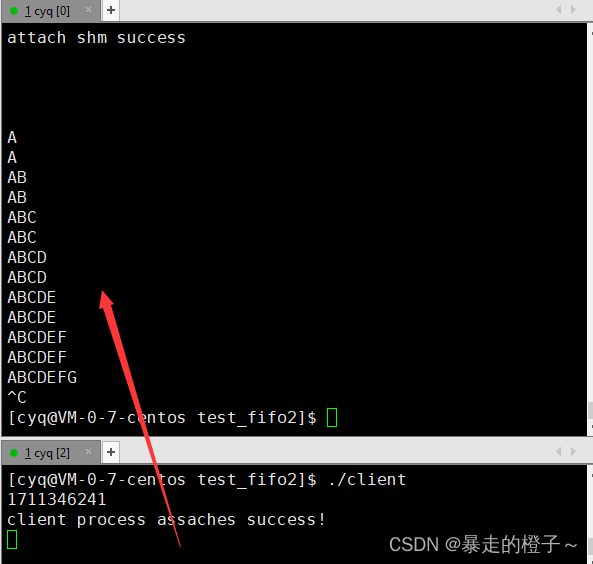
查看共享内存
我们创建共享内存后,如果要查看其中情况使用ipcs -m就可以。
[cyq@VM-0-7-centos test_fifo2]$ ipcs

** ipcs:**用来查看所有内存块的情况。
Message Queues:表示消息队列
Shared Memory Segments:共享内存
Semaphore Arrays:信号量
ipcs选项
ipcs -m 查看共享内存

shmid:表示共享内存块的"ID",用户层使用
key:key值,在内核层使用的
owner:用户名
bytes:内存块的空间大小
nattch:与该内存块关联的进程数目
status:内存块的状态
ipcs -q 查看消息队列

ipcs -s 查看信号量
 命令行删除共享内存
命令行删除共享内存
我们运行上面的./serer程序,然后终止掉,看看共享内存的情况:

我们通过ipcs -m发现,我们把程序终止了,但是共享内存块还在!这可是还在占用内存空间!浪费OS资源!所以我们要释放它!
释放共享内存有两种方式:
1、OS重启
2、程序员手动释放
命令行方式释放共享内存
[cyq@VM-0-7-centos test_fifo2]$ ipcrm -m shmid编号

ipcs -m 后面只能跟对应的shmid编号,删除对应共享内存块,不能使用key。为什么呢?
key:只是用来在OS层面上唯一标识的,不能用来管理shm
shmid:是OS给用户的id,用来在用户层进行shm管理
代码接口释放共享内存
实际上我们在上面的代码已经展现出来了,shmctl就可以删除共享内存。在这里我们就截图看一下:

总结
说明System V的PC资源,生命周期是随内核的!(就算创建System V资源的进程退出了,但是它申请的资源还存在!)只能通过OS重启,或者程序员显示释放来清理资源。
总结
1、共享内存一旦建立好并映射到自己的进程地址空间后,该进程就可以直接看到共享内存,就如同malloc的空间一样,不需要任何系统调用!
2、共享内存是所有进程间通信中最快的,因为他中间拷贝次数极少。
3、当client没有写入,甚至没有启动的时候,server端不会等待client端写入!因为共享内存不提供任何同步或互斥机制,需要程序员自行保证数据的安全!
看到这里,支持博主一下吧~

版权归原作者 暴走的橙子~ 所有, 如有侵权,请联系我们删除。