
很多小伙伴会有一个疑问,为什么要学习Hive呢?
大家可以这样想,虽然 Java,Python 可以直接操作 MapReduce ,也可以做分析,可是开发难度稍大, 但是 SQL 做分析,简单易上手,而 Apache Hive 就是让我们写类 SQL 语法,然后 Hive底层将会将其解析成 MR 任务来执行,Hive 是依赖 Hadoop 的,想要使用 Hive ,必须先搭建并启动 Hadoop 集群.
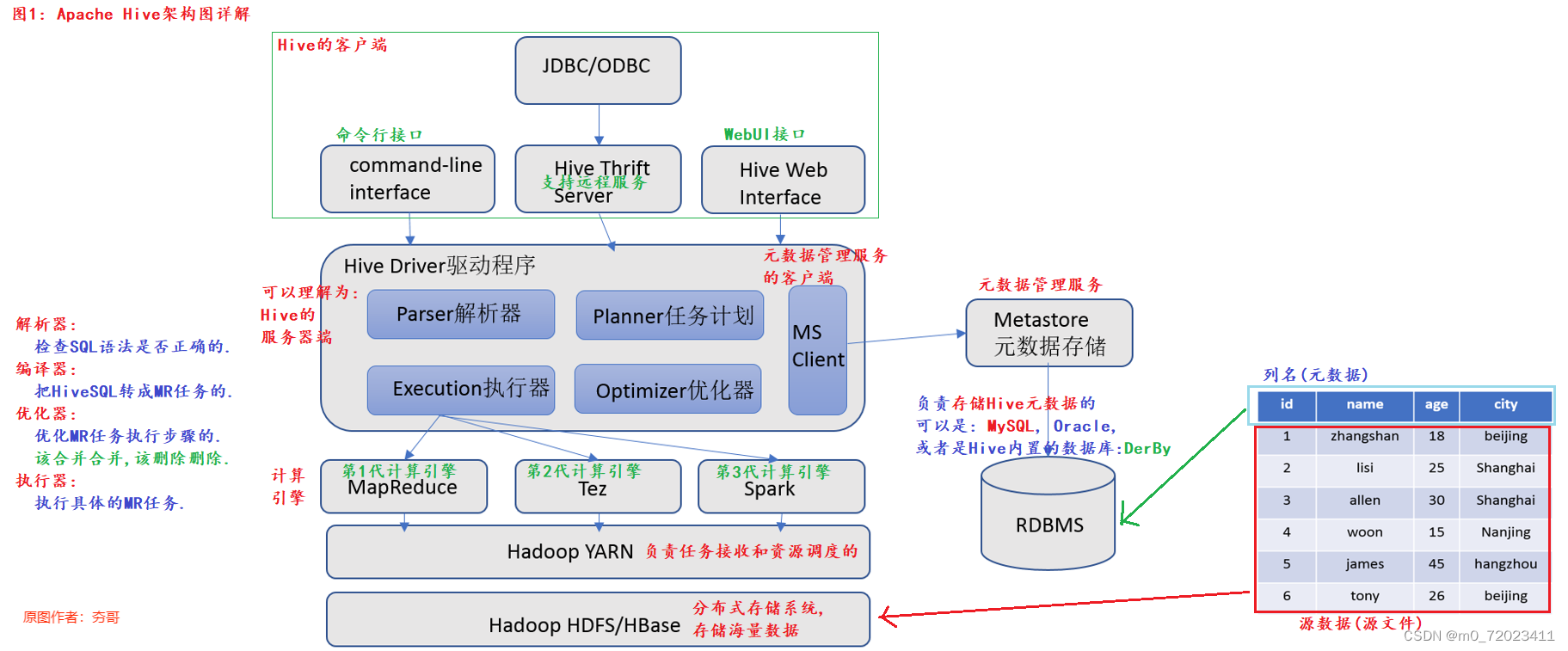
一、 Apache Hive 架构图
(一) Hive 的本质
** Hive 的本质就是将 HDFS 文件映射成一张 Hive 表.**

(二) Hive 架构图
首先我们要知道一款 Hive 引擎至少需要客户端、服务器端(解析器,编译器,优化器,执行器)、计算引擎、元数据管理器等.
顺序为
客户端 --> 解析器 --> 编译器 --> 优化器 --> 执行器 --> 计算引擎 --> Yarn --> HDFS/ HBase;
客户端 --> 解析器 --> MsClient --> Metastore --> RDBMS;
解释:
解析器 : 检查 SQL 语法是否正确;
编译器 :把 HiveSQL 转为 MR 任务;
优化器 : 优化 MR 任务执行步骤;
执行器 : 执行具体的 MR 任务;
Yarn : 负责任务接收和资源管理调度;
HDFS : 分布式存储,存储海量数据;
MsClient : 元数据管理服务的客户端;
Metastore : 元数据管理服务;
RDBMS : 在这里负责存储 Hive 的元数据的,可以是 MySQL、 Oracle 等,或者是 Hive 内置的数据库 Derby;
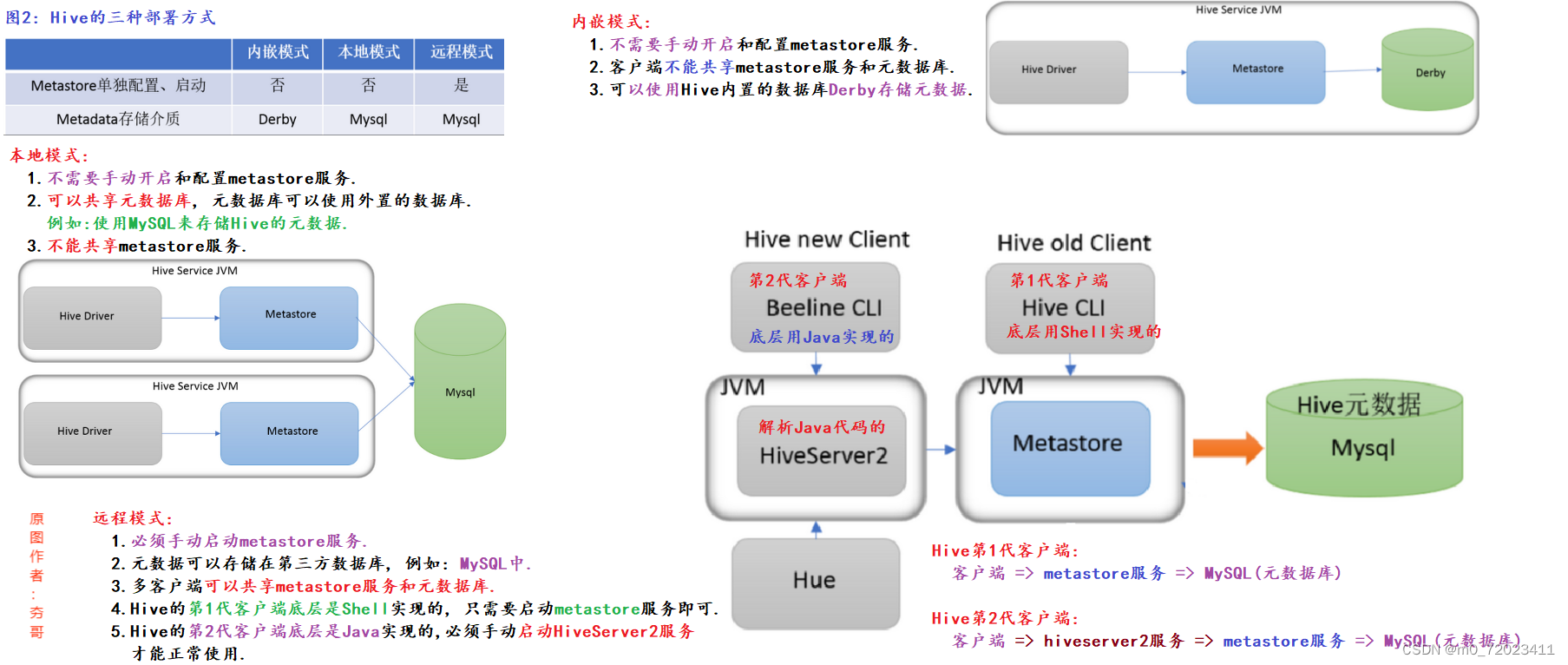
二、 Hive 的三种部署方式
** Hive 的三种部署方式分别为:内嵌模式、本地模式、远程模式.**
内嵌模式:
1、 不需要手动开启和配置 metastore 服务.
2、 客户端不能共享 Metastore 服务和元数据库 .
3、 可以使用 Hive 内置的数据库 Derby 存储元数据.
本地模式:
1、 不需要手动开启和配置 metastore 服务.
2、 可以共享源数据库,元数据库可以使用外置数据库.
3、 不能共享 Metastore 服务.
远程模式:
1、 必须手动开启 Metastore 服务.
2、 元数据可以存储在第三方数据库.
3、 Hive 的第一代客户端底层是 Shell 实现的,只需要手动启动 Metastore 即可.
4、 Hive 的第二代客户端底层是 Java 实现的,必须手动启动 HiveServer2 服务才可以正常使用.
三、 数据仓库和数据库的区别
数据库:
OLTP : 联机事务处理,主要面向事务(业务),操作在线数据,主要是 增删改查操作,数据量相对较小,事务性(安全性)要求较高,时效性要求也较高;
OLAP : 联机分析处理,主要面向主题,操作离线数据(历史数据),主要是 查询操作,数据量相对较大,事务性(安全性)要求较低,时效性要求也相对较低;
注:数据库是为了采集数据为生,数据仓库是为了分析数据而生,数据仓库的存在绝不是为了替代数据库.
四、 数仓经典分层 - 三层架构
数仓最经典分为3层:ODS 层 、DW 层 、DA 层.
ODS 层:
1、 ODS 层又称元数据层、贴源层.
2、 该层用于临时存储数据,数据结构会和源数据保持一致.
3、 数据会被存储到一张或多张表中.
ETL 动作 进行数据清洗.
DW 层:
1、 DW 层又称数据仓库层,简称数仓层.
2、 面向主题,对数据进行各种分析,获取分析结果.
DA 层:
1、 DA 层又称 数仓应用层,展现层.
2、 基于分析结果,通过可视化框架或者 BI 工具进行报表展示.
3、 还可以对接数据挖掘工程师,算法工程师,进一步提取商业的数据价值.
五、总结
以上就是Hive的简介!
下期预告~ HiveSQL 的DQL 操作
版权归原作者 m0_72023411 所有, 如有侵权,请联系我们删除。