
1.前言:
最近看Stable Diffusion开源了,据说比Disco Diffusion更快,于是从git上拉取了项目尝试本地部署了,记录分享一下过程~
这里是官网介绍:https://stability.ai/blog/stable-diffusion-public-release
2.必要前提:
- 科学上网。很多链接都需要用到。
- 显卡的显存需要足够大,至于多大没看到哪有说,反正3g绝对不行
3.部署前准备:
本地化部署运行虽然很好,但是也有一些基本要求
(1)需要拥有NVIDIA显卡,GT1060起,显存4G以上。(已经不需要3080起,亲民不少)
(2)操作系统需要win10或者win11的系统。
MacOS平台本地化请见《如何在mac电脑上运行stable diffusion来做AI绘画》
(3)电脑内存16G或者以上。
(4)最好会魔法上网,否则网络波动,有些网页打不开,有时下载很慢。
(5)耐心,多尝试,多搜索。这个教程我已经重复过2次,因此很多问题基本上都踩坑并写出来了。所以请放心,能跑通的。
我的电脑配置供大家参考,Win10,I7,NVIDIA GT1050 4G,16G
生成一张20step的图大概20-30s(若使用更高性能的电脑,生成速度更快。)
4.使用的项目Stable diffusion WebUI项目
Stable diffusion大家都知道了,是当前最多人使用且效果最好的开源AI绘图软件之一,属于当红炸子鸡了。
不过,stable diffusion项目本地化的部署,是纯代码界面,使用起来对于非程序员没那么友好。
而stable diffusion webui,是基于stable diffusion 项目的可视化操作项目。
通过可视化的网页操作,更方便调试prompt,及各种参数。
同时也附加了很多功能,比如img2img功能,extra放大图片功能等等。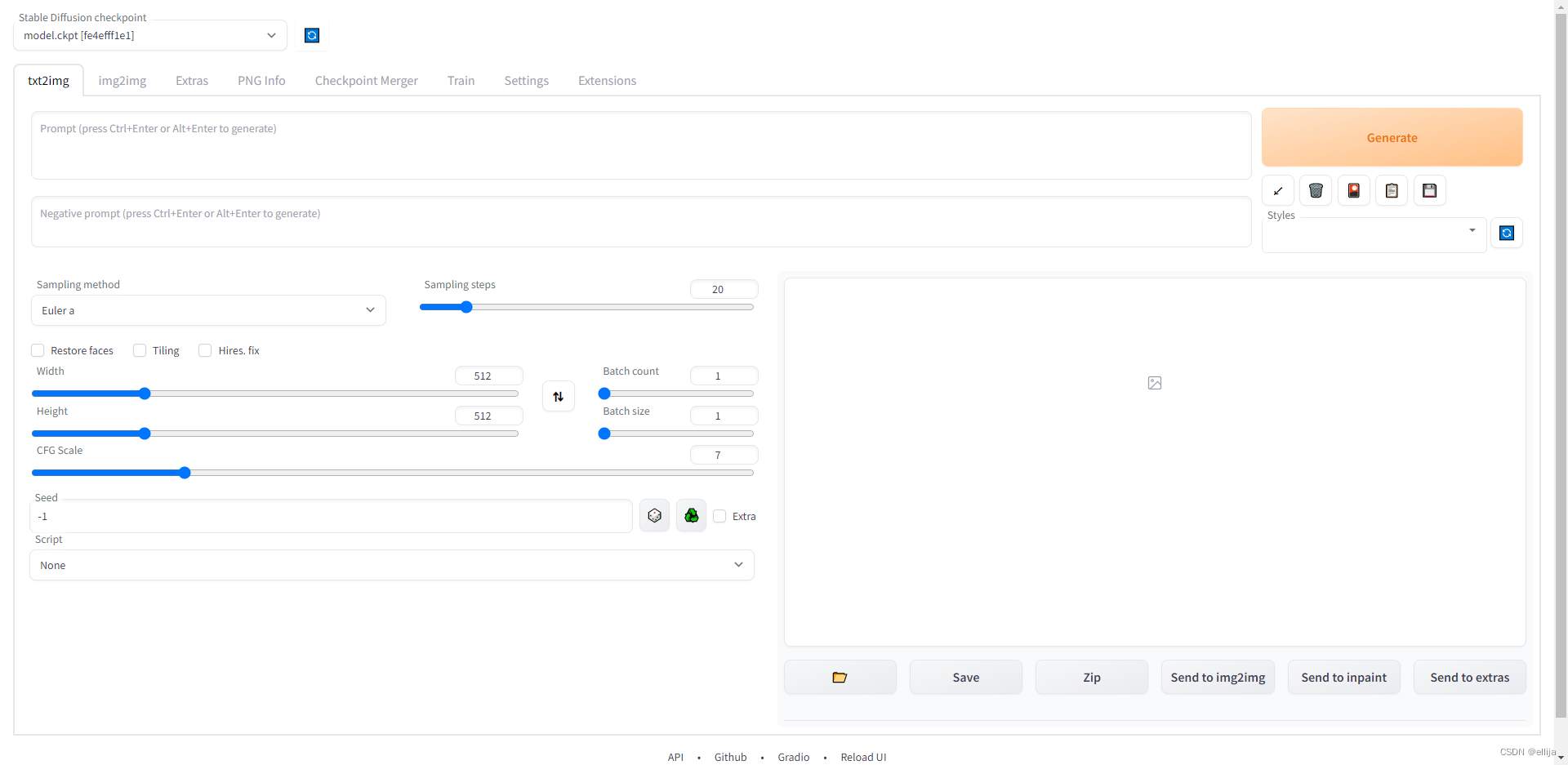
因此stable diffusion webui项目是很多人部署到本地的首选。
我们本教程就是以stable diffusion webui项目为例来操作的。
二、电脑环境配置
1.安装miniconda
这个是用来管理python版本的,他可以实现python的多版本切换。
下载地址:https://docs.conda.io/en/latest/miniconda.html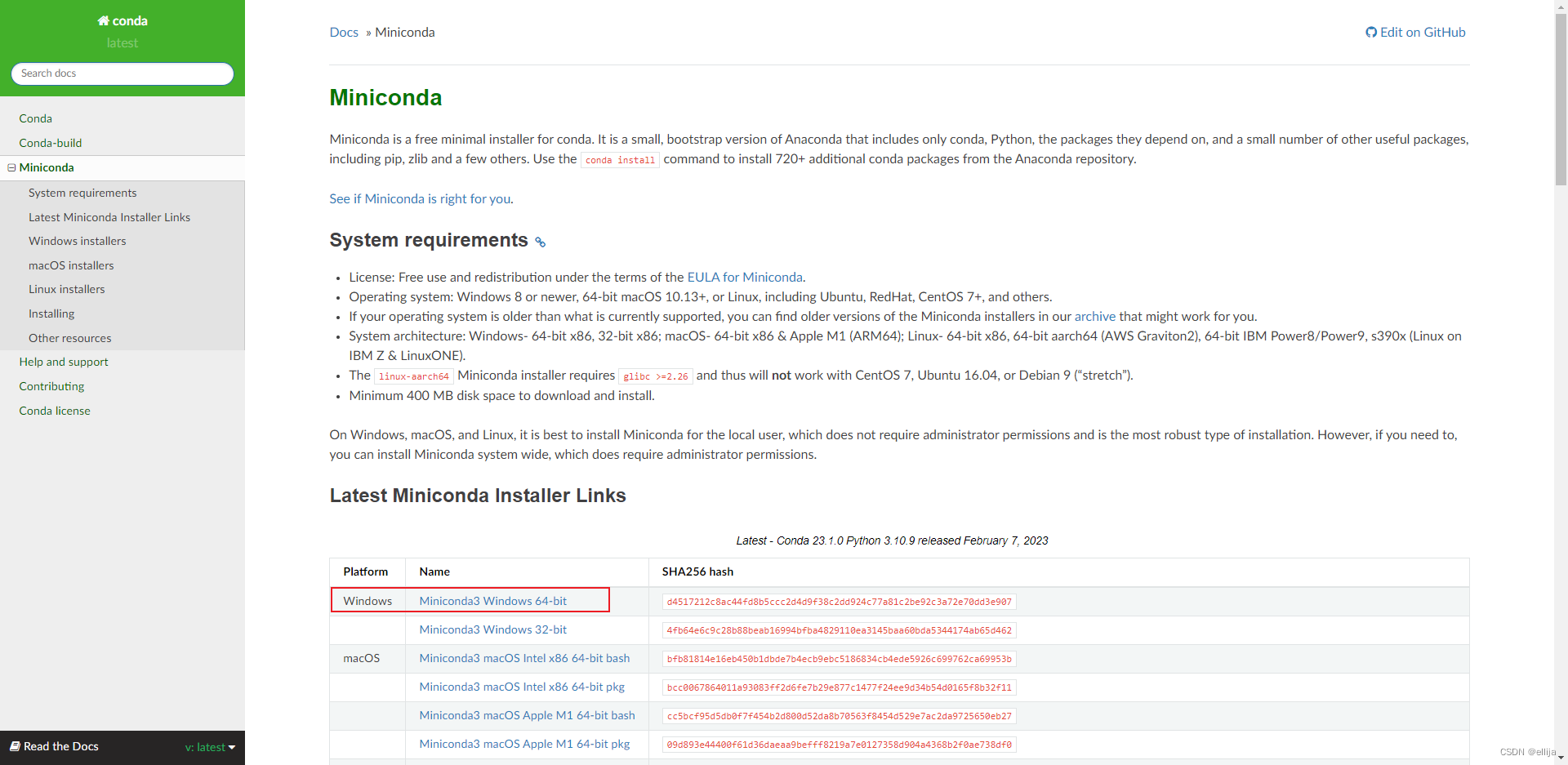
安装时按默认的一路next就行。
2.用管理员权限打开miniconda,输入conda -V 弹出版本号即为正确安装

3.配置库包下载环境,加快网络速度(替换下载库包地址为国内的清华镜像站)
执行下面
conda config --set show_channel_urls yes
生成.condarc 文件
在我的电脑/此电脑-C盘-users-你的账号名下用记事本打开并修改.condarc文件。(如我的路径是C:\Users\Administrator。)
把下面的内容全部复制进去,全部覆盖原内容,ctrl+s保存,关闭文件。
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
运行conda clean -i 清除索引缓存,以确保使用的是镜像站的地址。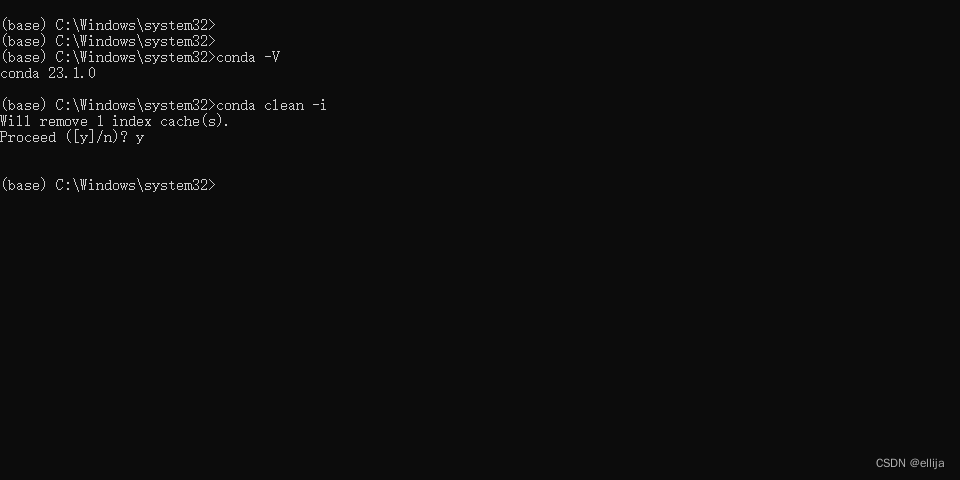
4.创建python 3.10.6版本的环境
运行下面语句,创建环境
conda create --name lmd python=3.10.6
系统可能会提示y/n, 输入y,按回车即可。
显示done,那就完成了。
在你的C:\ProgramData\Miniconda3\envs\lmd已经创建了一个新的项目。
5.激活环境
输入conda activate lmd 回车。
6.升级pip,并设置pip的默认库包下载地址为清华镜像。
每一行输入后回车,等执行完再输入下一行,再回车。
python -m pip install --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
不报错就是完成了。
7.安装git,用来克隆下载github的项目,比如本作中的stable diffusion webui
前往git官网https://git-scm.com/download/win
下载好后,一路默认安装,next即可。
开始菜单找到git cmd。
打开并输入下面指令。
git --version
查看git的版本,显示了版本号即安装成功。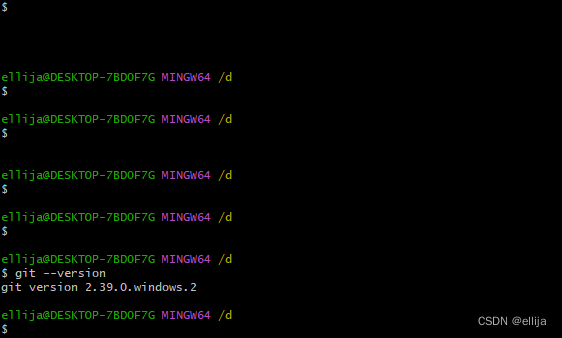
8.安装cuda
cuda是NVIDIA显卡用来跑算法的依赖程序,所以我们需要它。
打开NVIDIA cuda官网,https://developer.nvidia.com/cuda-toolkit-archive
(这里有人可能会打不开网页,如果打不开,请用魔法上网。)
你会发现有很多版本,下载哪个版本呢?
回到一开始的miniconda的小窗,输入nvidia-smi,查看你的cuda版本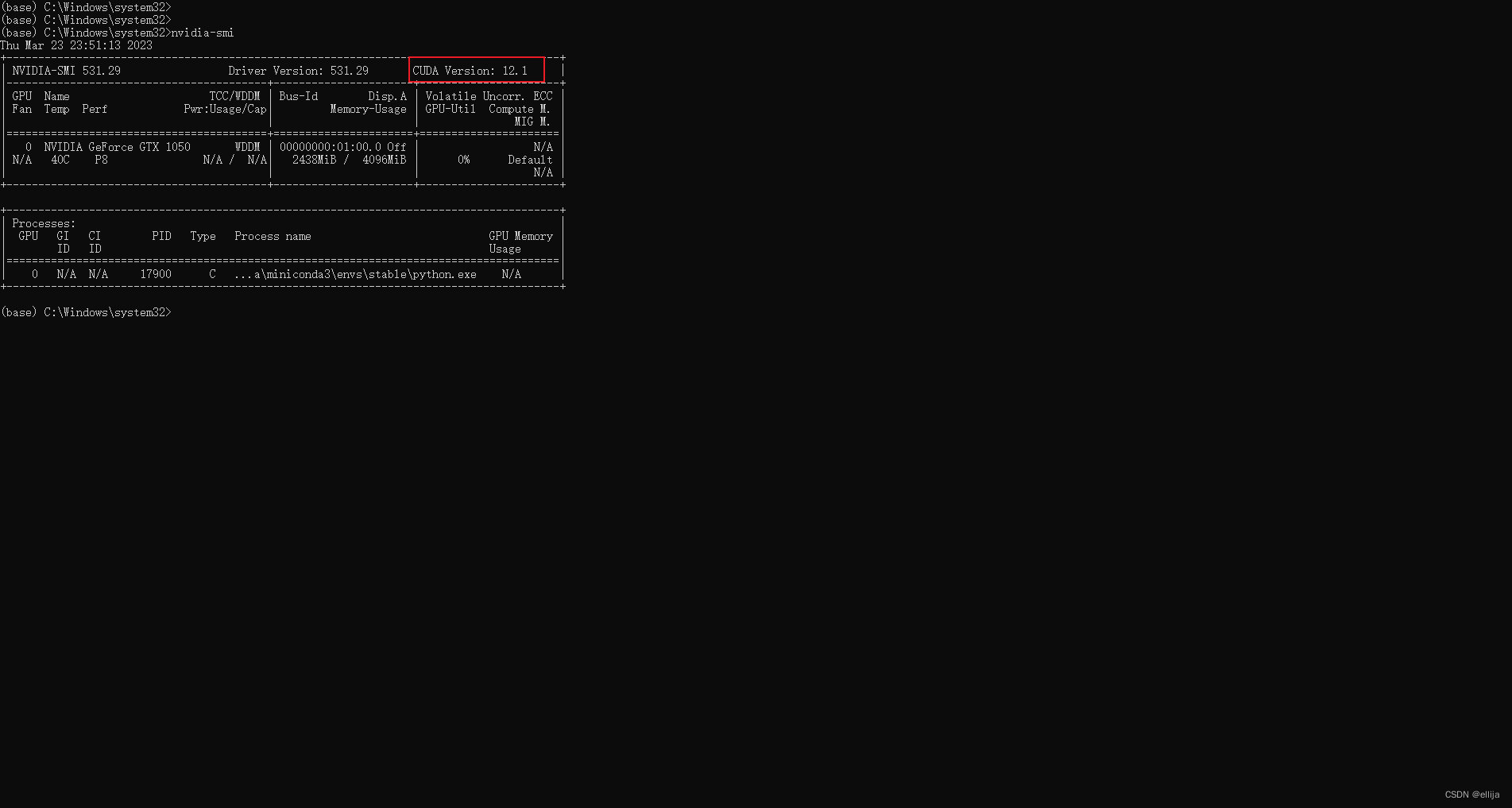
比如我的是12.1的版本,我就下载12.1.0的链接
下载完后安装,这个软件2个G,可以安装在c盘以外的地方。比如D盘。
好了,完成这步,电脑的基础环境设置终于完事了。
下面开始正式折腾stable diffusion了。
注意:如果提示此命令nvidia-smi,非内部命令时,按以下操作
把此路径:C:\Program Files\NVIDIA Corporation\NVIDIA NvDLISR,放入到环境变量中
显卡所在路径: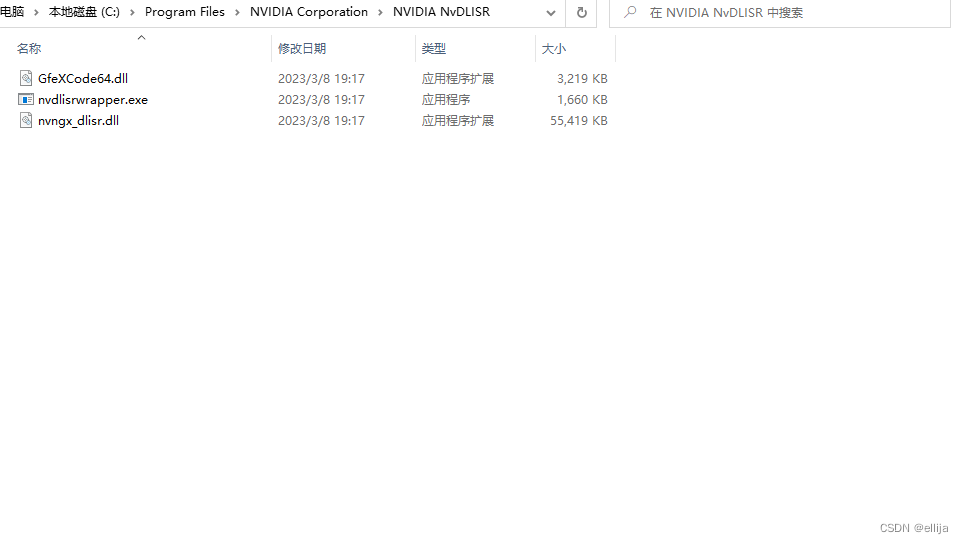
环境变量位置: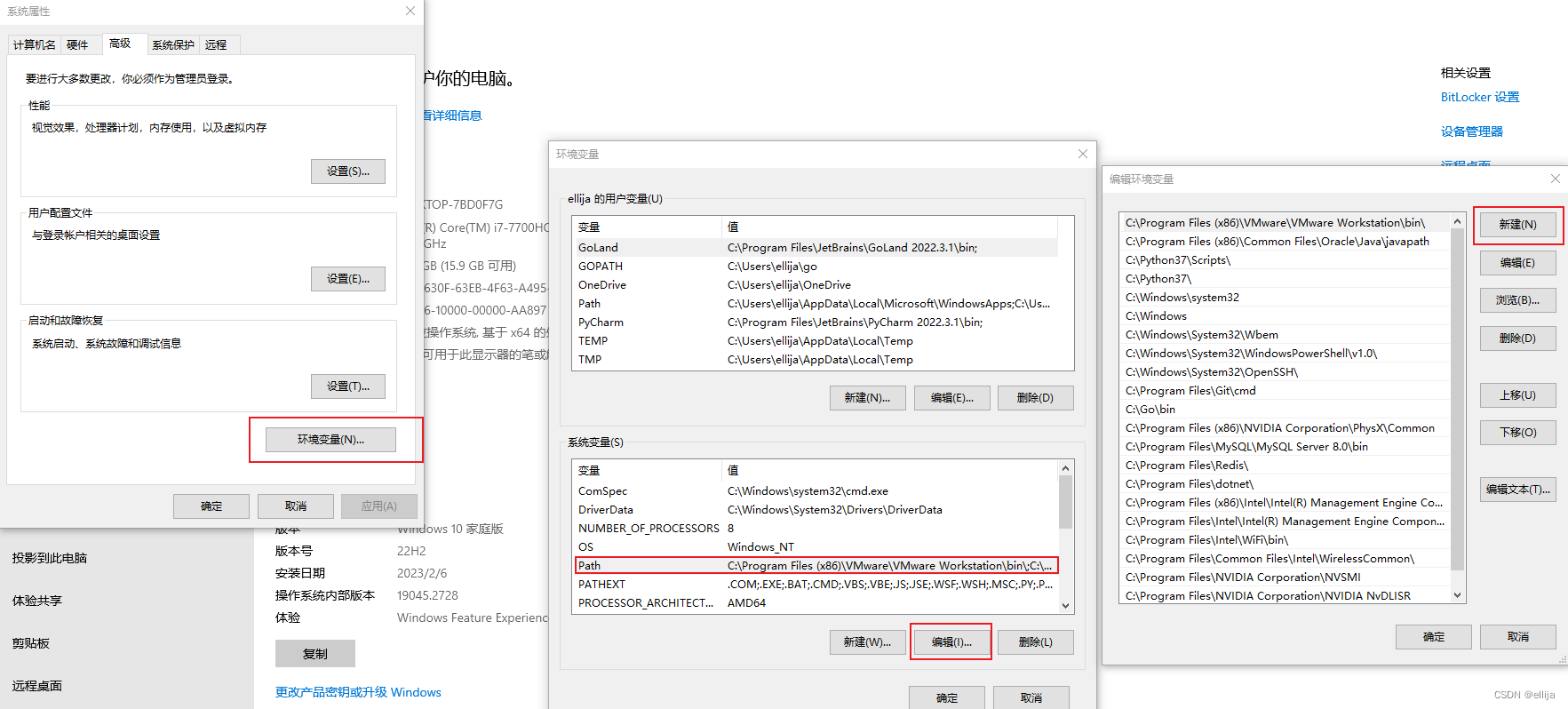
三、stable diffusion环境配置
1.下载stable diffusion源码
确认你的miniconda黑色小窗显示的是(把stable看成是lmd就行)
如果不是,则输入D: 按回车。
当然你也可以放在其他你想放的盘的根目录里面。
不建议放在c盘,因为这个项目里面有一些模型包,都是几个G几个G的,很容易你的C盘就满了,其他盘容量在10G以上的就都行。
再来克隆stable diffusion webui项目(下面简称sd-webui)
接着执行
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
注意,现在克隆的本地地址,就是下面经常提到的“项目根目录”。比如,我的项目根目录是D:\stable-diffusion-webui
2.下载stable diffusion的训练模型
地址:https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/tree/main
点击file and versions选项卡,下载sd-v1-4.ckpt训练模型。
(需要注册且同意协议,注册并同意协议之后即可下载)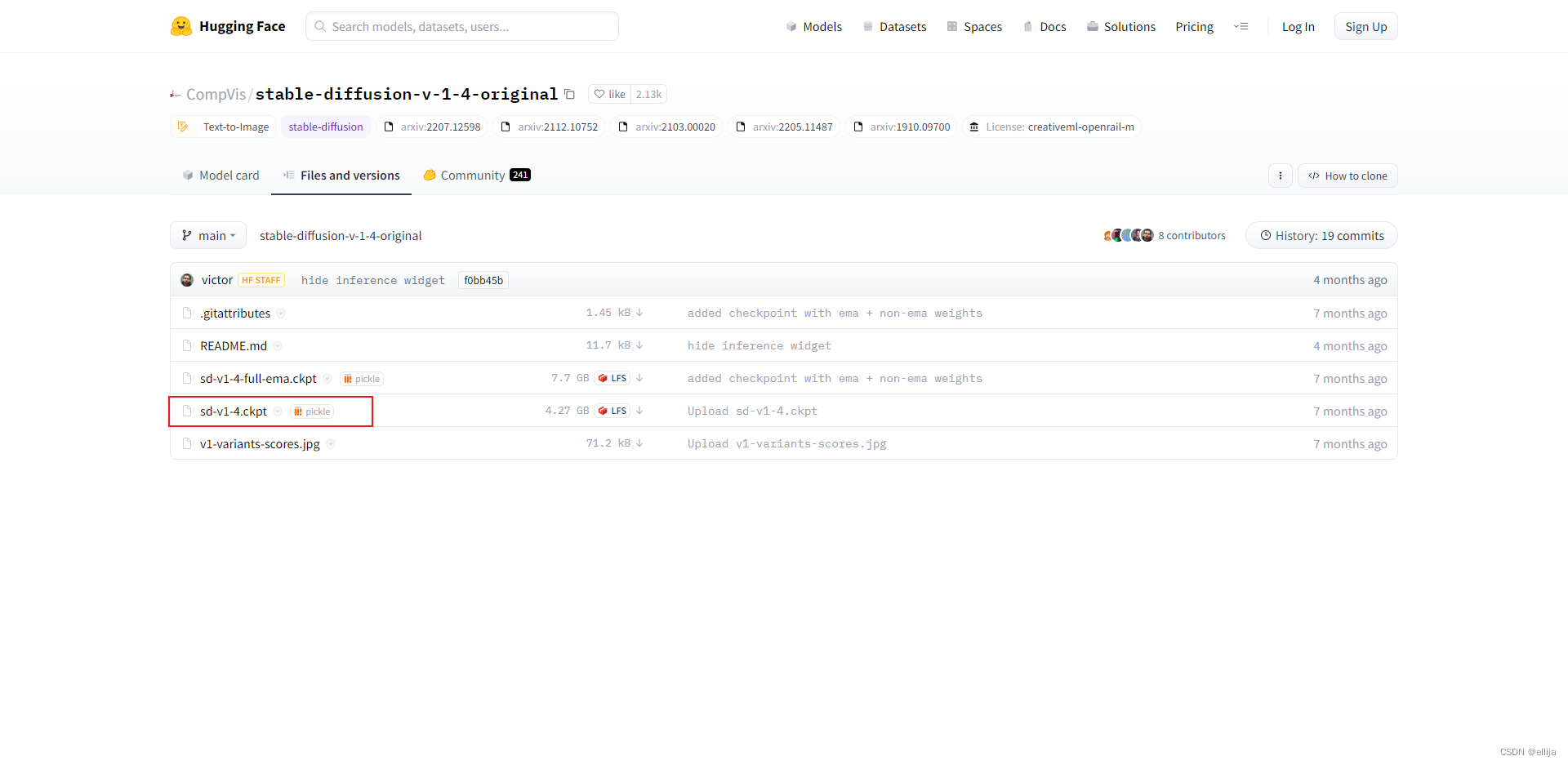
注:这个模型是用于后续生成AI绘图的绘图元素基础模型库。
后面如果要用waifuai或者novelai,其实更换模型放进去sd-webui项目的模型文件夹即可。
我们现在先用stable diffusion 1.4的模型来继续往下走。
3.更改训练模型名称
下载好之后,请把模型更名成model.ckpt,然后放置在sd-webui的models/stable-diffusion目录下。比如我的路径是D:\stable-diffusion-webui\models\Stable-diffusion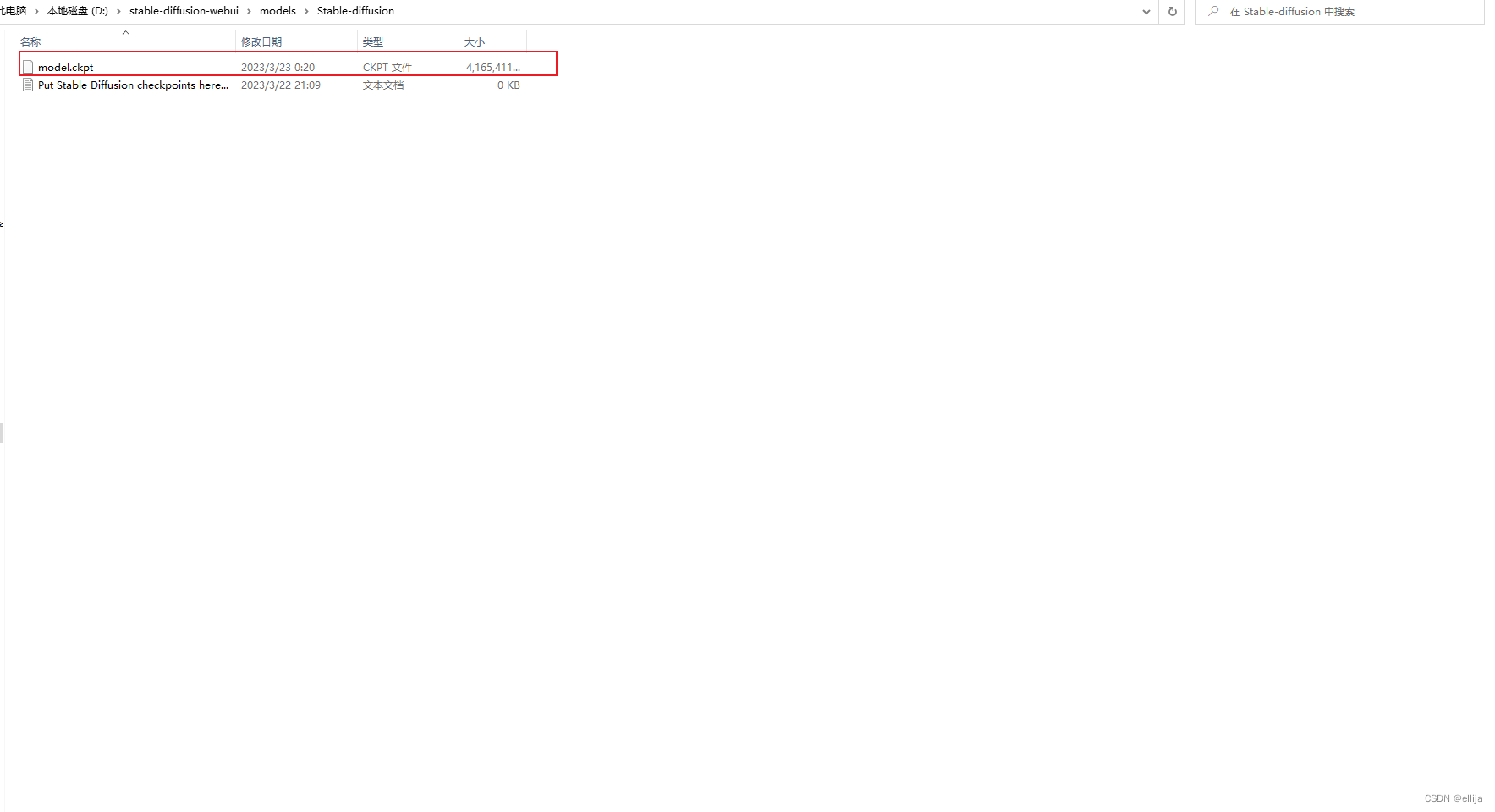
4. 安装GFPGAN
这是腾讯旗下的一个开源项目,可以用于修复和绘制人脸,减少stable diffusion人脸的绘制扭曲变形问题
地址:https://github.com/TencentARC/GFPGAN
把网页往下拉,拉到readme.md部分,找到V1.4 model,点击蓝色的1.4就可以下载。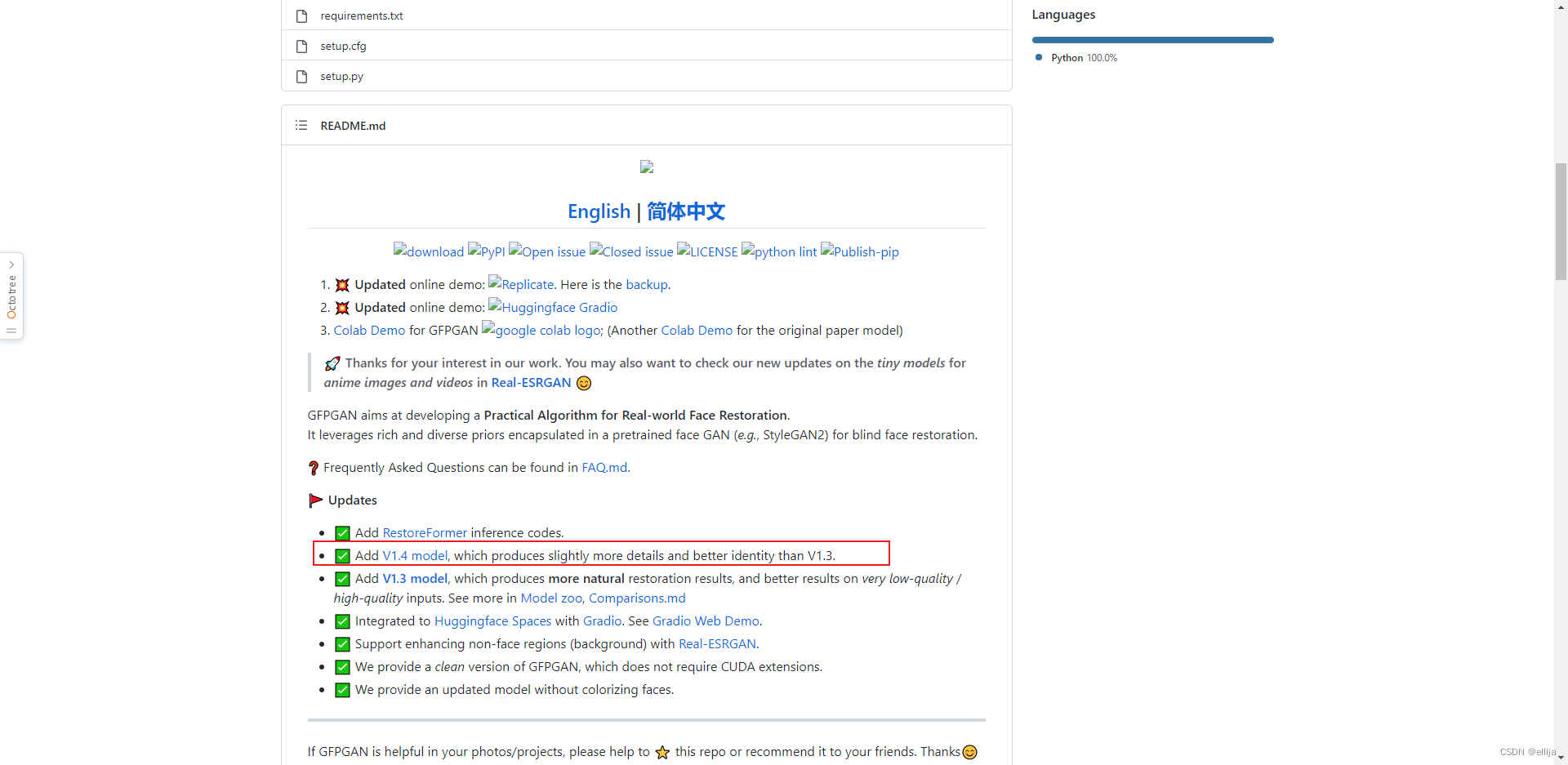
下载好之后,放在sd-webui项目的根目录下面即可,比如我的根目录是D:\stable-diffusion-webui
4.在miniconda的黑色小窗,准备开启运行ai绘图程序sd-webui
输入
cd stable-diffusion-webui
进入项目的根目录。
切记,一定要进入sd-webui的项目根目录后,才能执行下面的指令,否则会报错。
接着执行
webui-user.bat
然后回车,等待系统自动开始执行。
直到系统提示,running on local URL: http://127.0.0.1:7860
这就代表,你可以开始正式使用AI画画啦~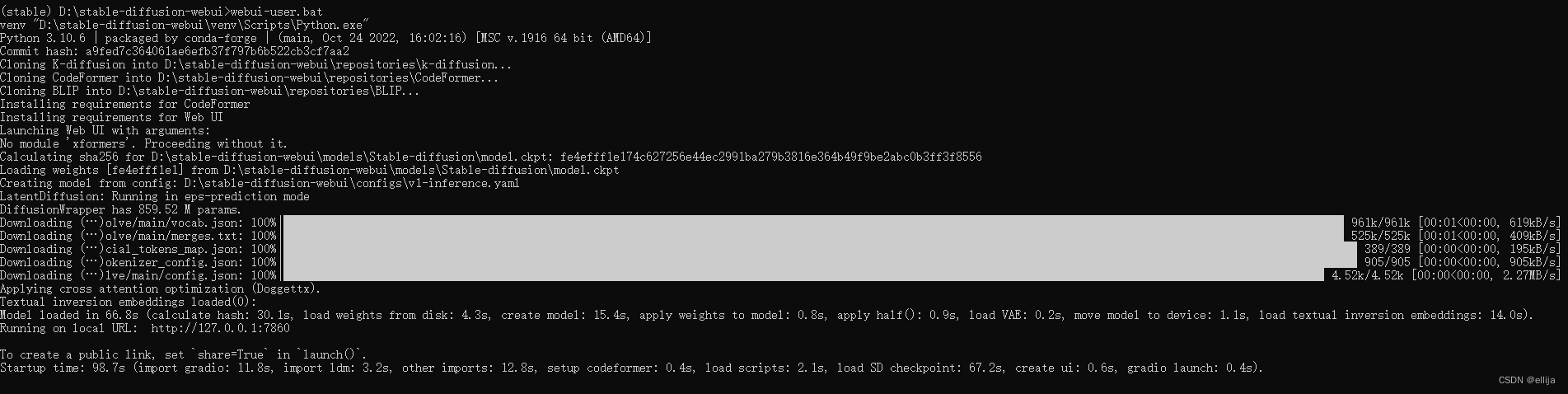
注意:
这一步可能经常各种报错,需要耐心和时间多次尝试。
不要关闭黑色小窗,哪怕它几分钟没有任何变化。
如果提示连接错误,可能需要开启或者关闭魔法上网,再重新执行webui-user.bat命令。
如果不小心退出了黑色窗口,则重新点击:开始菜单-程序-打开miniconda窗口,输入
conda activate lmd
并进入sd-webui项目根目录再执行
webui-user.bat
四、开始作画和调试
1.在浏览器,(比如谷歌浏览器),打开http://127.0.0.1:7860(注意,不要关闭miniconda的黑色窗口)
2.在prompt区域输入相关指令,比如beautiful landscape,然后点击右边的generate,即可生成第一张图片啦。
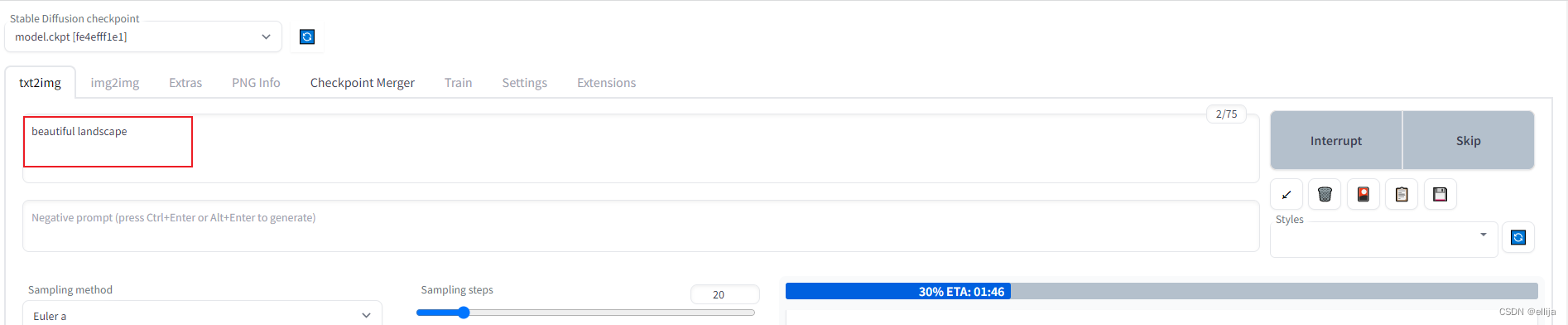
3.生成的状态和操作
网页会显示进度条,miniconda的黑色小窗也会显示进度条。
等进度条跑满,就能看到你生成的图啦。
如果不想生成了,可以点击interrupt停止生成,就会返回你目前为止已经生成的图片。(比如你要生成10张,已经生成了3张,点击interrupt,就会返回3张图片)
如果点击skip,就会跳过本张图片的生成,比如你想生成10张图,现在生成第3张,点击skip,第三张就不生成了,直接开始生成第四张,最后返回9张图片。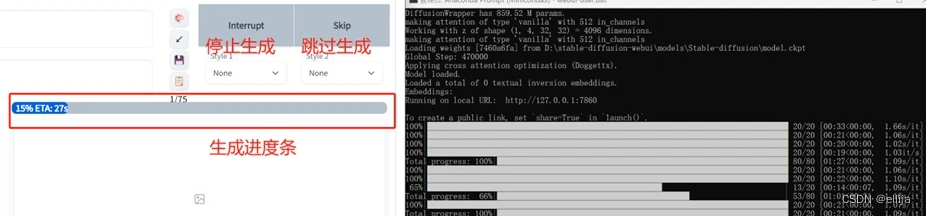
4.修改batch count数值,一次性生成多张图片
默认是1,一次性生成1张。
建议一次性生成4张或者以上,这样获得满意的图片概率会大一些,可以最多一次性生成最多100张。
但写得越大,一次性生成花费的时间越长,假设一张图30秒,设置10张就是300s,5分钟,100张则是3000s,50分钟。
5.好了,那现在就本地化部署完毕了,可以开始愉快地玩耍啦,祝你玩得开心~
五、安装过程中的错误处理
1、新版SD WebUI卡安装Open_Clip解决方法
https://www.bilibili.com/read/cv21253533
2、Stable Diffusion V2-Stability-AI处理
https://gitee.com/jerrylinkun/stable-diffusion-v2-stability-ai?_from=gitee_search
版权归原作者 ellija 所有, 如有侵权,请联系我们删除。