
spark是什么?
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
spark的发展史
2009年,Spark诞生于伯克利大学的AMPLab实验室。最出Spark只是一个实验性的项目,代码量非常少,属于轻量级的框架。
2010年,伯克利大学正式开源了Spark项目。
2013年,Spark成为了Apache基金会下的项目,进入高速发展期。第三方开发者贡献了大量的代码,活跃度非常高。
2014年,Spark以飞快的速度称为了Apache的顶级项目。
2015年~,Spark在国内IT行业变得愈发火爆,大量的公司开始重点部署或者使用Spark来替代MapReduce、Hive、Storm等传统的大数据计算框架。

spark特点:
快速:
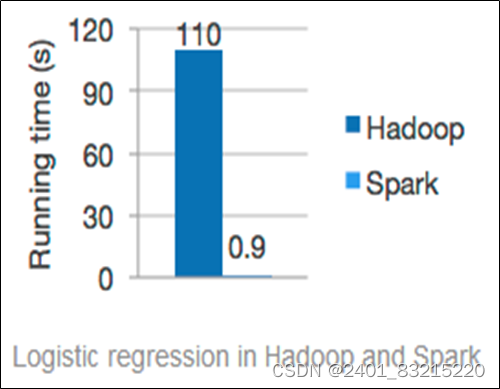
一般情况下,对于迭代次数较多的应用程序,Spark程序在内存中的运行速度是Hadoop MapReduce运行速度的100多倍,在磁盘上的运行速度是Hadoop MapReduce运行速度的10多倍。
易用性:Spark支持使用Scala、Python、Java及R语言快速编写应用。同时Spark提供超过80个高阶算子,使得编写并行应用程序变得容易,并且可以在Scala、Python或R的交互模式下使用Spark。
通用性:Spark可以与SQL、Streaming及复杂的分析良好结合。Spark还有一系列的高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX(图计算)和Spark Streaming(流计算),并且支持在一个应用中同时使用这些组件。

随处运行:用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。
兼容性
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
spark最大的特点:基于内存。
spark集群的体系结构
(1)结构
(a)Master:接收任务请求,分发任务
(b)Worker:本节点任务调度,资源管理。默认占用该节点所有资源
- Spark对内存没有很好管理,容易出现OOM。Spark把内存管理交给应用程序。
- Spark架构出现单点故障问题,通过HA解决。
(c )Driver:客户端
(2)启动方式
(a)Spark-submit:
用于提交Spark 任务。每个任务是一个jar。
(b)spark-shell:
类似于 REPL
spark的生态圈
(1)Spark Core
Spark的核心,提供底层框架及核心支持。
(2)BlinkDB
一个用于在海量数据上进行交互式SQL查询的大规模并行查询引擎,允许用户通过权衡数据精度缩短查询响应时间,数据的精度将被控制在允许的误差范围内。
(3)Spark SQL
可以执行SQL查询,支持基本的SQL语法和HiveQL语法,可读取的数据源包括Hive、HDFS、关系数据库(如MySQL)等。
(4)SparkStreaming
可以进行实时数据流式计算。
(5)MLBase
是Spark生态圈的一部分,专注于机器学习领域,学习门槛较低。
MLBase由4部分组成:MLlib、MLI、ML Optimizer和MLRuntime。
MLlib部分算法如下。
(6)Spark GraphX
图计算的应用在很多情况下处理的数据量都是很庞大的。如果用户需要自行编写相关的图计算算法,并且在集群中应用,难度是非常大的。而使用GraphX即可解决这个问题,因为它内置了许多与图相关的算法,如在移动社交关系分析中可使用图计算相关算法进行处理和分析。
(7)SparkR
AMPLab发布的一个R语言开发包,使得R语言编写的程序不只可以在单机运行,也可以作为Spark的作业运行在集群上,极大地提升了R语言的数据处理能力。
spark的部署模式:Spark独立服务器模式、基于YARN的Spark、基于Mesos的Spark。
1.Spark独立服务器模式
独立服务器模式使用内置的调度器,因而不需要任何外部调度器,如YARN或Mesos。要以独立服务器模式安装Spark,需要将Spark的二进制安装文件复制到集群的所有机器上。
独立服务器模式下,客户端可通过spark-submit或Spark shell与集群通信。无论那种情况,driver都会与Spark主节点进行通信,以便获取worker节点的信息,此后executor将在worker节点上启动来执行应用。多个客户端可同时与集群通信,然后再worker节点上创建各自的executor,每个客户端都有自己的driver组件。
2.基于YARN的Spark
在YARN模式下,客户段与YARN的资源管理器进行通信,从而获得容器来运行Spark应用。可将其视为一个小型Spark集群。在使用YARN运行Spark应用时,可使用YARN客户端模式或YARN集群模式。
2.1 YARN客户端模式
在YARN客户端模式下,driver在集群之外的节点(一般都是客户端节点)上运行。driver首先需要与资源管理器通信,从而请求资源并运行Spark作业。资源管理器会分配容器(0号容器)并响应driver。driver在0号容器中启动Spark应用主节点。Spark应用主节点在资源管理器分配的容器中创建executor。
YARN容器可位于集群中由节点管理器控制的任一节点,因此所有的资源分配都由资源管理器负责。
Spark应用主节点与资源管理器进行沟通,以获取其他容器来启动executor。
2.2 YARN集群模式
在集群模式下,driver在集群中的某个节点(一般是应用程序的主节点)上运行。客户端首先与资源管理器通信,请求资源并运行Spark作业。资源管理器会分配容器(0号容器)并响应客户端。然后客户端向集群提交代码,并在0号容器内启动driver和Spark应用主节点。driver与Spark应用主节点协同工作,然后在由资源管理器分配的容器上创建executor。
YARN容器可位于由节管理器控制的任何容器上。因此所有的资源分配都由资源管理器负责。
Spark应用主节点与资源管理器进行沟通,以获取其他容器来启动executor。
在YARN集群模式下,没有shell,因为driver本身在YARN内部。
3. 基于Mesos的Spark
基于Mesos的部署模式与Spark的独立服务器模式蕾丝。driver与Mesos的主节点通信,然后该主节点分配用于运行executor的资源。然后driver会与executor通信。
Mesos中的driver会先与主节点通信,然后从Mesos所有的从节点上处理请求。
将容器分配给Spark作业后,driver会让executor启动,然后再executor中运行代码。如果Spark作业运行完成,而driver还存在,就会通知Mesos主节点,然后Mesos从属节点中所有以容器形式存在的资源都会被释放。
多个客户端与集群交互,从而在从属节点上创建格子的executor。每个客户端由自己的driver组件。
spark的架构
基本组件:
(1)客户端
用户提交作业的客户端。
(2)Driver
运行Application的main()函数并创建SparkContext。
(3)SparkContext
整个应用的上下文,控制应用的生命周期。
(4)ClusterManager
资源管理器,即在集群上获取资源的外部服务,目前主要有Standalone(Spark原生的资源管理器)和YARN(Hadoop集群的资源管理器)。
(5)SparkWorker
集群中任何可以运行应用程序的节点,运行一个或多个Executor进程。
(6)Executor
执行器,在Spark Worker上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executor。
(7)Task
被发送到某个Executor的具体任务。
**Spark作业运行流程
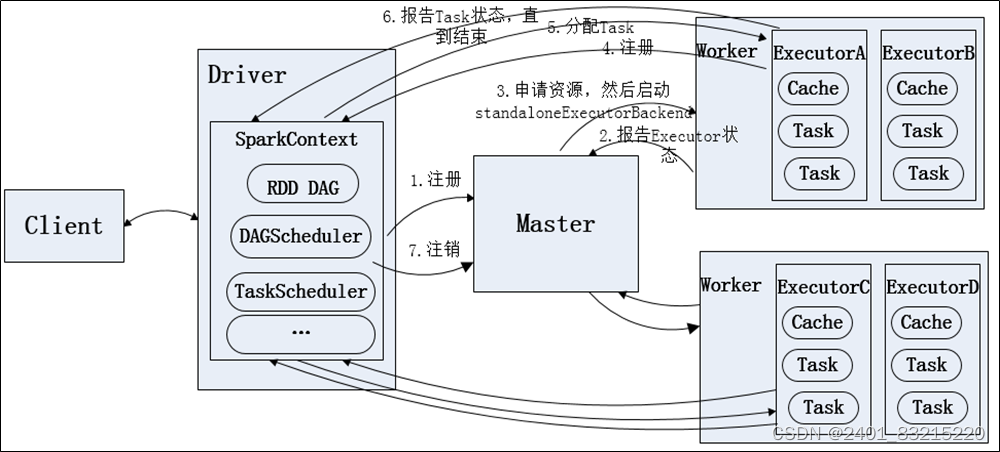
**Standalone模式运行流程
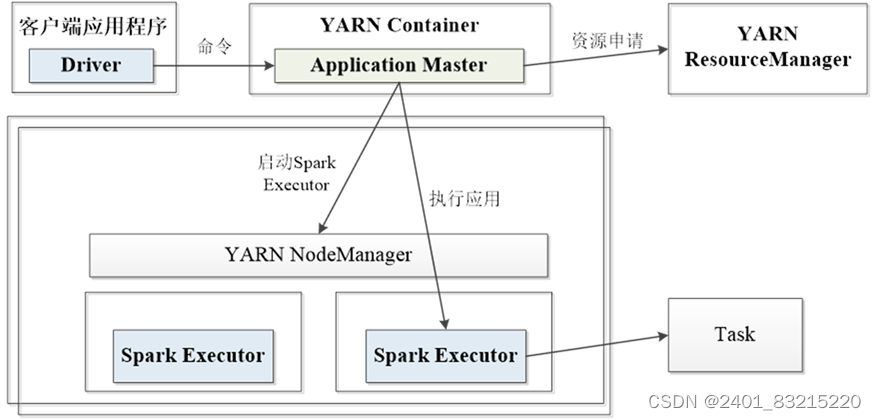
yarn-cluster运行流程

yarn-client运行流程
Spark核心数据集RDD
RDD(ResilientDistributedDatasets弹性分布式数据集),可以简单的把RDD理解成一个提供了许多操作接口的数据集合,和一般数据集不同的是,其实际数据分布存储于一批机器中(内存或磁盘中)。
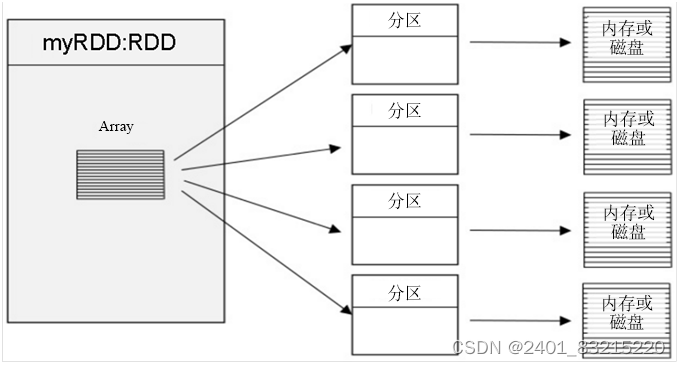
Spark RDD转换和操作示例
宽依赖与窄依赖
窄依赖:表现为一个父RDD的分区对应于一个子RDD的分区或者多个父RDD的分区对应于一个子RDD的分区。
宽依赖:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区

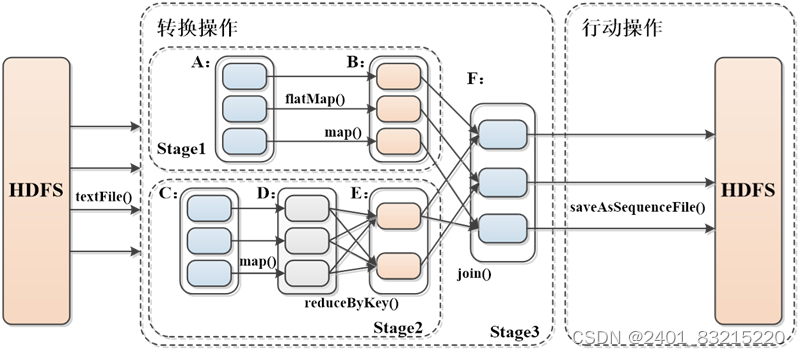
RDD Stage划分
stage的划分依据主要是基于Shuffle

mapreduce和spark的区别
都是可以用来处理海量的数据,但是在处理方式和处理速度上存在着差异
spark处理数据是基于内存的,而MapReduce是基于磁盘处理数据的。
MapReduce是将中间结果保存到磁盘中,减少了内存占用,牺牲了计算性能。 Spark是将计算的中间结果保存到内存中,可以反复利用,提高了处理数据的性能。Spark 计算比 MapReduce 快的根本原因在于 DAG 计算模型,
如果计算过程中涉及数据交换,Spark 也是会把 shuffle 的数据写磁盘的!有一个误区,Spark 是基于内存的计算,所以快,这不是主要原因,要对数据做计算,必然得加载到内存,Hadoop 也是如此,只不过 Spark 支持将需要反复用到的数据给 Cache 到内存中,减少数据加载耗时,所以 Spark 跑机器学习算法比较在行(需要对数据进行反复迭代)。
结构化数据:结构化数据是指按照一定的规则和格式进行组织和存储的数据。它具有明确的数据类型和关系,可以通过预定义的模式或模型进行描述和解释。常见的结构化数据包括关系型数据库中的表格数据、电子表格中的数据、XML文件中的数据等。结构化数据通常可以通过查询和分析工具进行处理和分析,从中提取有用的信息和洞察。与结构化数据相对的是非结构化数据,如文本、图像、音频和视频等,它们没有明确的结构和格式,处理和分析起来更加困难。
非结构化数据:
非结构化数据是指没有明确的结构和格式的数据,它不符合传统的表格、行列或关系型数据库的组织形式。非结构化数据的特点是多样性、复杂性和不规则性,常见的非结构化数据包括文本文档、电子邮件、社交媒体帖子、音频和视频文件、图像、日志文件等。
与结构化数据不同,非结构化数据没有明确的数据模型或模式,因此处理和分析非结构化数据更具挑战性。传统的关系型数据库和查询语言无法直接处理非结构化数据,需要使用特定的技术和工具进行处理,如自然语言处理、文本挖掘、图像识别、语音识别等。
非结构化数据在现实生活中广泛存在,例如社交媒体上的用户评论、新闻文章、音频和视频文件中的内容、传感器数据等。对非结构化数据的分析和挖掘可以帮助企业和组织发现隐藏的信息、洞察用户需求、进行情感分析、进行风险评估等。
区别:
(1)数据组织形式:结构化数据按照预定义的模式和格式进行组织,具有明确的数据类型和关系,通常以表格、行列或关系型数据库的形式存储。非结构化数据没有明确的结构和格式,多样性、复杂性和不规则性较高,以文本、图像、音频、视频等形式存在。
(2)数据处理方式:结构化数据可以通过传统的查询语言(如SQL)进行处理和分析,可以进行数据的筛选、排序、聚合等操作。非结构化数据的处理需要使用特定的技术和工具,如自然语言处理、图像识别、语音识别等,以提取有用的信息和洞察。
(3)数据分析能力:结构化数据由于有明确的结构和格式,可以进行较为精确的数据分析和建模,可以进行统计分析、预测建模等。非结构化数据的分析相对更具挑战性,需要使用更复杂的技术和算法,如文本挖掘、情感分析、图像识别等。
(4)数据应用领域:结构化数据常用于企业的业务数据管理、报表生成、决策支持等方面。非结构化数据常用于社交媒体分析、舆情监测、情感分析、图像识别、语音识别等领域。
结构化数据和非结构化数据的应用
结构化数据的应用:
企业数据管理:结构化数据常用于企业的业务数据管理,包括客户信息、销售数据、财务数据等。它们可以通过关系型数据库进行存储和管理,用于业务流程的支持和决策制定。
报表生成和分析:结构化数据可以通过查询和分析工具进行数据提取、筛选、排序和统计,用于生成各种报表和数据分析,支持业务决策和业绩评估。
数据挖掘和预测建模:结构化数据可以用于数据挖掘和预测建模,通过分析历史数据,发现隐藏的模式和关联,进行趋势预测、市场分析、客户行为分析等。
非结构化数据的应用:
社交媒体分析:非结构化数据在社交媒体分析中起着重要的作用,可以通过文本挖掘和情感分析技术,了解用户的观点、情感和需求,进行舆情监测、品牌声誉管理等。
图像和视频处理:非结构化数据中的图像和视频可以通过图像识别、目标检测、视频分析等技术进行处理,用于人脸识别、智能监控、图像搜索等应用。
自然语言处理:非结构化数据中的文本可以通过自然语言处理技术进行处理,包括文本分类、实体识别、关系抽取、机器翻译等,用于智能客服、智能助手、文本分析等应用。
版权归原作者 2401_83215220 所有, 如有侵权,请联系我们删除。